RMNet: Equivalently Removing Residual Connection from Networks
RMNet: Equivalently Removing Residual Connection from Networks
- 论文链接:https://arxiv.org/pdf/2111.00687.pdf
- 源码链接:https://hub.nuaa.cf//fxmeng/RMNet
简介
自从AlexNet问世以来,SOTA的CNN架构变得越来越深。例如,AlexNet只有5个卷积层,很快被VGG和GoogleNet分别扩展到19和22层。然而由于梯度消失和爆炸问题,简单地堆叠层的深度网络很难训练–当梯度反向传播到更早的层时,重复乘法可能会使梯度无限小或无限大。标准化初始化在很大程度上解决了这个问题。中间标准化层使具有数十层的网络能够聚合。同时另一个退化问题也暴露出来:随着网络深度增加,精度饱和,然后迅速退化。ResNet解决了退化问题,并通过添加从块输入到输出的残差连接来实现1K+层模型。ResNet不希望每个堆叠层直接适合所需的底层映射,而是让这些层适合残差映射。当相等映射是最优的时,将残差推至0币通过一堆非线性层拟合相等映射更容易。随着ResNet越来越受到欢迎,研究人员提出了很多新的架构,基于ResNet,从不同角度解读成功。
然而Residual distillation: Towards portable deep neural networks without
shortcuts指出ResNet残差连接约占特征图上整个内存使用量的40%,这将减缓推理过程。另外,网络中的残差连接对网络剪枝是不友好的。相比之下,类VGG模型,本文称之为Plain模型,只有一条路径且速度快内存经济且易于并行化。RepVGG提出了一种强大的方法,通过推理时的重参数化来去除残差连接。具体地,RepVGG将3x3卷积、1x1卷积和恒等变换相加进行训练。在每个分支末端添加BN层,并在加操作之后添加ReLU。训练过程中RepVGG只需要学习残差映射,而在推理阶段,利用重参数化将RepVGG基本块转换为3x3卷积层加上ReLU运算的堆叠,与ResNet相比,这具有良好的速度-精度折衷。本文实验发现当网络深入时,RepVGG性能会严重下降。
本文呢引入了一种新的方法称为RM操作,它可以去除其他与非线性层的残差连接并保持模型结果保持不变。RM操作通过第一个卷积层、BN层和ReLU层保留输入特征图,然后通过ResBlock中最后一个卷积将其输出特征图合并。基于这种方式,本文可以等效地将预训练ResNet或MobileNetV2转换为RMNet,以增加并行度。
本文方法
重参数化方法回顾
图1描述了ResNet和RepVGG描绘的基本块。在ResBlock中(图1a),两个ReLU分别位于残差连接的内部和外部。而在RepBlock中,由于重参数化是基因乘法的交换律,因此两个ReLU必须都在残差连接外。通过用两个RepBlock替换每个ResBlock,可以从基本的ResNet架构构建RepVGG。接下来,分析为什么RepVGG不能像ResNet一样从前向和后传中进行很深的训练。

前向路径
Residual networks behave like ensembles of relatively shallow networks假定ResNet成功可以归因于模型集成。本文可以将ResNet视为许多不同长度的路径集合。因此n块ResNet有 O ( 2 n ) O(2^{n}) O(2n)条连接输入和输出的隐含路径。然而,与ResNet块中两个分支是可分离的,不能合并不同的是RepVGG多个分支可以用一个分支表示。
x i + 1 = R e L U ( B N ( x i ) + B N ( C o n v 1 × 1 ( x i ) ) + B N ( C o n v 3 × 3 ( x i ) ) ) = R e L U ( B N ( C o n v 3 × 3 ′ ( x i ) ) ) \begin{aligned} x_{i+1}&=ReLU(BN(x_{i})+BN(Conv_{1\times 1}(x_{i}))+BN(Conv_{3\times 3}(x_{i})))\\ &=ReLU(BN(Conv_{3\times 3}^{\prime}(x_{i})))\\ \end{aligned} xi+1=ReLU(BN(xi)+BN(Conv1×1(xi))+BN(Conv3×3(xi)))=ReLU(BN(Conv3×3′(xi)))
C o n v ′ Conv^{\prime} Conv′是分支中每个Conv的融合卷积。因此RepVGG不具有ResNet隐含集成假设,并且RepVGG和ResNet之间表示差距随着块数量增加而增加。
后向路径
The shattered gradients problem: If resnets are the answer, then what is the question?分析了深度神经网络中破碎梯度问题。当反向路径中有更多ReLU时,梯度相关性表现为高斯白噪声。假设ResNet和RepVGG都有n层。如图1a所示,ResNet信息可以通过残差,而无需通过每个块中ReLU内部。但是RepVGG中每个ReLU都位于主路径。因此,反向路径中ResNet的ReLU数量是n/2,而路径中RepVGG的ReLU数量是n。这表明当深度大时,ResNet梯度更耐破碎,从而获得比RepVGG更好的性能。
图2给出了网络深度如何影响ResNet和RepVGG性能的实验结果。可以看出当深度增加时,ResNet可以得到更好的精度,这与先前分析一致。而RepVGG精度将减少,与可以在CIFAR-100获得79.57%精度ResNet-133相比,RepVGG-133只有41.38%精度。

图1显示了RepVGG和ResNet在ImageNet数据集性能比较。在相同网络结构中,ResNet-18比RepVGG-18高0.5%,而ResNet-34比ResVGG高0.8%。因此,RepVGG是在损失表示能力的代价下提升速度。

RM操作与RMNet
RM操作
图3给出了RM操作等效地移除残差连接的过程。为了简洁起见,没有在图中显示BN层,并且输入通道、中间通道和输出通道数量相同。

保留
首先在Conv1插入几个Dirac初始化的滤波器(输出通道)。Dirac初始化滤波器数量与卷积层中输入通道数量相同。Dirc初始化滤波器定义为四维矩阵:
I c , n , i , j = { 1 if c = n and i = j = 0 , 0 otherwise I_{c, n, i, j}=\left\{\begin{array}{ll} 1 & \text { if } c=n \text { and } i=j=0, \\ 0 & \text { otherwise } \end{array}\right. Ic,n,i,j={10 if c=n and i=j=0, otherwise
图3b给出了这些滤波器。每个滤波器只有一个元素为1。其可以通过卷积来保留输入特征图的相应通道信息。
对于BN层,为了保留输入特征图,需要调整BN中权重 w w w和偏差 b b b,以使BN层表现得像一个相等函数。假设特征图的运行平均值和运行方差分别为 μ \mu μ和 σ 2 \sigma^{2} σ2,设置 w = σ 2 + ϵ w=\sqrt{\sigma^{2}+\epsilon} w=σ2+ϵ, b = μ b=\mu b=μ。然后对于通过BN的任何输入 x x x,输出为:
y = w × ( x − μ ) σ 2 + ϵ + b = x y=w\times \frac{(x-\mu)}{\sqrt{\sigma^{2}+\epsilon}}+b=x y=w×σ2+ϵ(x−μ)+b=x
对于ReLU层,有两种需要考虑的情况:
- 当通过残差连接的输入值为非负时(在ResNet中,每个ResBlock都有一个下面的ReLU层,该层保持输入值均为非负),模型可以直接使用ReLU来保留信息。因为ReLU不改变非负值。
- 当通过残差连接的输入值可能为负时(例如在MobileNetV2中,ReLU仅位于ResBlock中间),模型使用PReLU而不是ReLU保留信息。关于附加通道的参数被设置为1。通过这种方式,PReLU行为就像一个相等函数。
从以上的分析,输入特征图可以通过ResBlock块中的Conv 1,BN,ReLU良好保留。 - 合并:扩展Conv 2输入通道,dirac初始化这些通道。z的第i通道值为原始第i滤波输出 x i R 2 x_{i}^{R2} xiR2和第i输入特征图 x i + x_{i}^{+} xi+的和。这与原始ResBlock与 y i y^{i} yi相等。整个合并过程可以描述为:
z c , h , w = ∑ n 2 C ∑ i K ∑ j K ( [ W R 2 , I ] c , n , i , j × [ x R 1 + , x + ] n , h + i , w + j + [ B R 2 , 0 ] c ) = ∑ n C ∑ i K ∑ j K ( W c , n , i , j R 2 × x n , h + i , w + j R 1 + + B c R 2 ) + ∑ n = C + 1 2 C ∑ i K ∑ j K ( I c , n , i , j × x n , h + i , w + j + + 0 ) = ∑ n C ∑ i K ∑ j K ( W c , n , i , j R 2 × x n , h + i , w + j R 1 + + B c R 2 ) + x c , h , w + = y c , h , w \begin{aligned} z_{c, h, w} & =\sum_{n}^{2 C} \sum_{i}^{K} \sum_{j}^{K}\left(\left[W^{R 2}, I\right]_{c, n, i, j} \times\left[x^{R 1+}, x^{+}\right]_{n, h+i, w+j}+\left[B^{R 2}, 0\right]_{c}\right) \\ & =\sum_{n}^{C} \sum_{i}^{K} \sum_{j}^{K}\left(W_{c, n, i, j}^{R 2} \times x_{n, h+i, w+j}^{R 1+}+B_{c}^{R 2}\right)+\sum_{n=C+1}^{2 C} \sum_{i}^{K} \sum_{j}^{K}\left(I_{c, n, i, j} \times x_{n, h+i, w+j}^{+}+0\right) \\ & =\sum_{n}^{C} \sum_{i}^{K} \sum_{j}^{K}\left(W_{c, n, i, j}^{R 2} \times x_{n, h+i, w+j}^{R 1+}+B_{c}^{R 2}\right)+x_{c, h, w}^{+} \\ & =y_{c, h, w} \end{aligned} zc,h,w=n∑2Ci∑Kj∑K([WR2,I]c,n,i,j×[xR1+,x+]n,h+i,w+j+[BR2,0]c)=n∑Ci∑Kj∑K(Wc,n,i,jR2×xn,h+i,w+jR1++BcR2)+n=C+1∑2Ci∑Kj∑K(Ic,n,i,j×xn,h+i,w+j++0)=n∑Ci∑Kj∑K(Wc,n,i,jR2×xn,h+i,w+jR1++BcR2)+xc,h,w+=yc,h,w
因此,通过保留和合并,可以在不改变ResBlock原始输出情况下不删除残差连接。
剪枝RMNet
由于RMNet没有任何残差连接,因此它对滤波器剪枝更友好。本文中采用Network Slimming剪枝RMNet因为它的简单和有效性。因此通过保留和合并,本文可以在不改变ResBlock的原始输出情况下删除残差连接。具体地,首先训练ResNet和稀疏BN层中权重,训练期间应在残差连接中添加额外的BN层,因为还需要确定RM操作后哪些额外的滤波器是重要的。训练后,本文将ResNet转换为RMNet,并根据BN层中的权重对滤波器进行剪枝,这与vanilla network slimming相同。
基于RM操作提升RepVGG
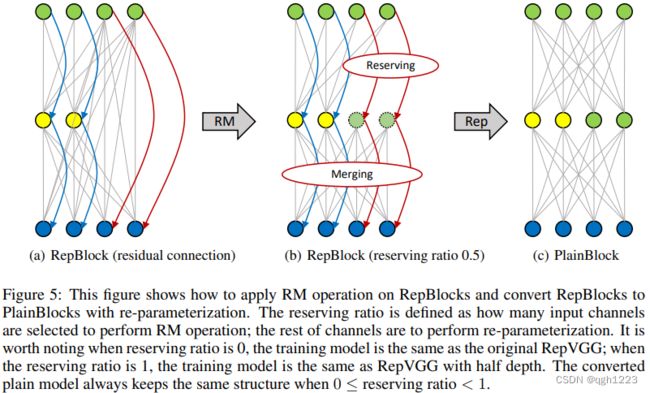
作为一种插件方式,RM操作可以帮助RepVGG在深度较大情况下实现更好的性能。图5中训练了一个具有穿越非线性层的残差连接的网络。输入特征图由通道分割为两部分,并具有预定义的保留率。输入特征图的左侧部分的信息流表现为RepVGG,而右侧部分表现为ResNet。通过RM操作,可以利用第一层中一些通道保留输入的特征图,并且之后的ReLU不会改变其值。然后在第二层,即RepBlock,可以将保留的输入特征图合并到输出特征图中。接下来,可以使用重参数化将RepBlock转换为PlainBlock。这种设计好处是打破了RepVGG深度限制,因为保留的输入通道可以帮助模型更好地学习。
转化MobileNetV2为MobileNetV1
从技术上讲,转换ResNet和通过使用RM操作转换MobileNetV2没有区别。然而,MobileNetV2结构特殊性允许在RM操作后使用参数融合进一步减少推理时间。
图6中,在MobileNetV2上应用RM操作,将移除残差连接,这将留下虚线框中所示的两个Pointwise-ConvBN层。由于卷积和批归一化都可以通过矩阵乘法来表示并且它们之间不存在非线性层,因此这个Pointwise-ConvBN层可以融合。定义 X , Y , W , B X,Y,W,B X,Y,W,B是输入特征图,输出特征图,虚线框第一个Pointwise-ConvBN层的权重偏差。 Z , W ′ , B ′ Z,W^{\prime},B^{\prime} Z,W′,B′是第二个Pointwise-ConvBN层输出特征图,权重和偏差。混合参数的过程可以描述为:
Z = W ′ Y + B ′ = W ′ ( W X + B ) + B ′ = ( W ′ W ) X + W ′ B + B ′ Z=W^{\prime}Y+B^{\prime}=W^{\prime}(WX+B)+B^{\prime}=(W^{\prime}W)X+W^{\prime}B+B^{\prime} Z=W′Y+B′=W′(WX+B)+B′=(W′W)X+W′B+B′

混合权重 W ′ W ∈ R n , c , 1 , 1 W^{\prime}W\in R^{n,c,1,1} W′W∈Rn,c,1,1和混合偏差 W ′ B + B ′ W^{\prime}B+B^{\prime} W′B+B′。因此,RM操作提供了通过融合参数进一步减少推理事件的另一个机会。在参数融合之后,RMNet架构与MobileNetV1相同,这非常有趣,因为MobileNetV2的存在是通过利用残差连接来提高MobileNetV1的泛化能力。然而,本文展示了RM操作可以逆转这一过程,即将MobileNetV2转换为MobileNetV1,这使得MobileNetV1再次伟大。