并查集与图
并查集与图
- 一、并查集
-
- 概念
- 实现原理
- 代码实现
-
- 查找根节点
- 合并两颗树
- 判断是否是同一棵树
- 树的数量
- 二、图的基本概念
-
- 定义
- 分类
- 完全图
- 顶点的度
- 连通图
- 三、图的存储结构
-
- 分类
- 邻接表
-
- 邻接表的结构
- 代码实现
- 邻接矩阵
-
- 代码实现
- 四、图的遍历
-
- 方式
- 广度优先
- 深度优先
- 五、最小生成树
-
- 概念
- Kruskal算法
-
- 原理
- 代码实现
- Prim算法
-
- 原理
- 代码实现
- 六、单源最短路径
-
- 概念
- Dijkstra
-
- 原理
- 代码实现
- 缺陷
- BellmanFord
-
- 原理
- 代码实现
- 七、多源最短路径
-
- 概念
- 原理
- 代码实现
一、并查集
概念
并查集是由多棵树组成的,本质上一个森林,常用于解决图的判环问题,两个集合是否有交集等等。
实现原理
并查集采用双亲表示法,和堆类似,都采用数组来实现,如下图,以10个元素为例,初始时,值都是-1,表示10棵树,元素值的绝对值表示树中的节点个数
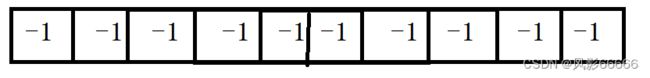
如下图,将下标为9的元素合并到下标为5的树上,将下标为5的值加上下标为9的值,然后将下标为9的值改为5,便于找到它的双亲

代码实现
查找根节点
要合并两个树,就得先分别找到这两颗树的根节点,然后才能进行合并,如下图

合并两颗树
首先先找到两颗树的根节点,根据根节点是否相同,来判断是不是已经是同一颗树了,如果是就返回,不是再进行合并,同时,将节点少的树往节点多的树上合并
判断是否是同一棵树
只要判断是不是同一个根节点即可

树的数量
只要元素的值为-1的,就表示它是一棵树,统计计数即可

二、图的基本概念
定义
图是由顶点和边组成的一种数据结构,用G = (V, E)表示,G表示图(graph),V(vertex)表示顶点,E(edge)表示边
分类
图分为有向图和无向图两种,有向图常用于表示单向关系,比如B站关注了某个up主,就是单向的,而无向图常用于表示像微信、QQ这样双向的好友关系
有向图,如下图
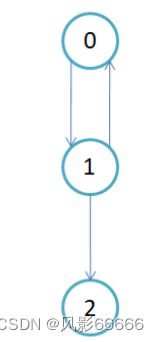
无向图,如下图

完全图
完全图是一种任意两个顶点都直接相连的图,无向图中的完全图有n*(n-1)/2条边,有向图中的完全图有n*(n-1)条边,即任意两个顶点都有两条边
顶点的度
无向图中,顶点的度=出度=入度,因为无向图的边没有方向,所以都相等,而在有向图中,顶点的度=出度+入度
连通图
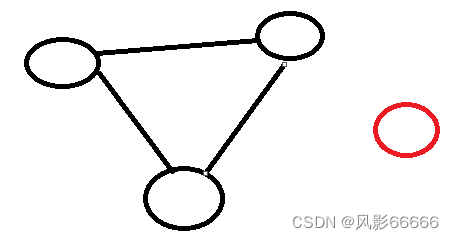
图和树不同,图不一定是连通的,可能存在孤岛,即没有前往某个节点的路径,它与其它节点是脱离开的,如下图,红色顶点就是一个孤岛
三、图的存储结构
分类
图的存储结构分为两种,一种是邻接矩阵
邻接表
邻接表的结构
邻接表采用类似于哈希表的方式,先用一个数组,数组的每个元素都代表一个顶点,顶点下面都挂着的一个链表,链表的每个节点都是一条边,对于有向图,这里这考虑出边,不考虑入边,如果要考虑入边,就得再加一个邻接表
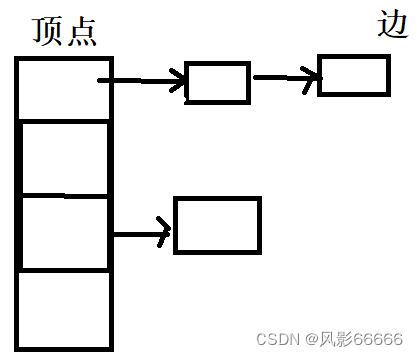
代码实现
首先,定义出边的结构,用模板类型W,来表示权值类型,因为是挂在对应的顶点下面,所以可以不存储顶点的下标

顶点的类型可能有很多中,所以采用模板类型V,W是权值的类型,Direction是非类型模板参数,false表示无向图,true表示有向图

确定图的成员,分别有顶点集合,邻接表,以及一个顶点与其下标映射的Map,便于后面插入的时候,找到顶点的下标

构造函数用来开辟邻接表的空间,以及初始化成员

定义一个查找顶点下标的接口

添加边,采用链表的头插,如果是无向图,则需要插入两条边,因为i->j,那也一定可以j->i,所以需要插入两条边

邻接矩阵
代码实现
MAX_W这个参数用来初始化二维数组,毕竟一开始的邻接矩阵的每个顶点都是一个孤岛
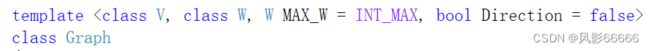
成员和邻接表类似,只是将邻接表改为了二维数组,二维数组的每个元素的值,都是边的权值

构造函数,用来开辟空间,初始化成员

添加边,这里采用两个函数,是因为后面有些地方会直接使用上面的函数,不需要通过函数获取顶点下标

注意:下面的所有算法,都是在邻接矩阵中实现的
四、图的遍历
方式
如图、树这种数据结构,一般都采用深度优先或广度优先的方式来进行遍历,值得注意的是,这里遍历的是顶点,不是边!!!
广度优先
广度优先遍历方式,需要借助队列来实现,队列用来存顶点的下标,srci是起始顶点的下标,visited是一个标记数组,当某个顶点下标入队列后,就将其标记为true,表示访问过了,来防止后续可能会重复入队列,第一个for循环是用来便于一层一层打印的,类似于打印树的每一层

值得注意的是,图不一定是连通的,可能存在孤岛,遍历不到,所以需要循环遍历标记数组,以此来遍历所有顶点

深度优先
深度优先遍历,采用递归的方式实现,同样需要借助标记数组,来标记访问过的节点

同广度优先,需要解决可能出现的孤岛问题

五、最小生成树
概念
最小生成树是一种特殊的连通图,它只有n-1条边,刚刚好可以使图连通,n是顶点个数,最小生成树也是不能成环的,否则也无法使图连通,同时,这n-1条边的权值和是最小的。
注意:最小生成树也可能不唯一!!!
Kruskal算法
原理
Kruskal算法是一种找全局最优解的贪心,它每次都找最权值最小的边,当然,在会构成环的时候,会抛弃构成环的那条边,找另外的边
代码实现
首先,先初始化一下最小生成树
![]()

这是要使用的边结构,重载>,是为了后面建立小堆

这里借助优先级队列,来便于每次找最小的边

选边,需要借助前面讲过的并查集,来判断是不是会成环,成环则抛弃这条边,找另外的边,不成环,将边的起始点和终止点的下标加入并查集,来合并顶点

最后,再判断一下,是否是n-1条边,是就将权值和返回

Prim算法
原理
Prim算法是一种找局部最优解的贪心,它采用了两个集合,集合中的元素是顶点的下标,姑且称为源集合和目标集合,分别用X和Y表示。开始时,X只有一个顶点a的下标,Y有其它顶点的下标,然后找顶点a到Y集合中元素对应的顶点的最小权值,具体步骤如下图
核心思路:每次找X中的某个顶点到Y中的某个顶点直接相连的且是最小权值的边
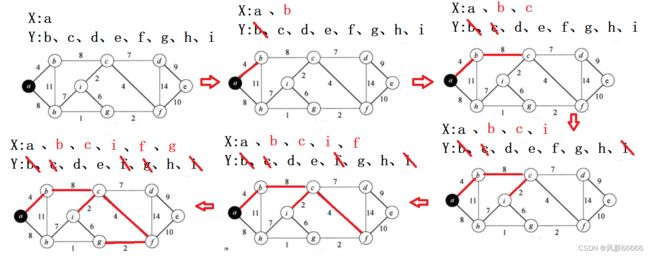
代码实现
初始准备工作

定义X与Y集合,开始时,X集合只有一个元素,Y集合有n-1个元素

先把a顶点直接相连的边全部插入到优先级队列中,此后,优先级队列中都是X集合中的顶点连接的边

选出优先级队列中的最小边,判断边的目标顶点是不是已经在X集合中了,在就表示成环了,因为一个顶点不可能被两次加入一个集合
添加边后,再将边的目标点连接的边都加入到优先级队列中,不过需要判断一下目标点连接的边的另一顶点是否已经在X集合中了

最后,判断一下是否是n-1条边

六、单源最短路径
概念
单源最短路径,指的是从某个点到其它点的路径,假设有顶点a、b、c、d、e,以a为源点,从a到b所有路径中,权值和最小的那条路径就是最短路径,而a到c、d、e,也是同理,所以被称为单源最短路径
Dijkstra
原理
这里采用两个一维数组,长度为顶点的个数,一个数组中的每个元素表示源点到该元素顶点的路径的权值的最小值,另一个数组中的每个元素存储的是它的双亲,具体情况,如下图,*表示最大值,以S为源点,先根据S的所有出边,更新对应的最短路径,s到y和t的最短路径被更新,然后以y为起点,找它的出边,更新s到t、x、z的最短路径,因为s到z的路径最短,下次再以z为起点,找它的出边等等,每一步都是贪心

代码实现
先进行初始化操作,数组S用来标记已经找到最短路径的顶点

因为有n个顶点,所以最外层循环n次,第一个内循环,则是找出路径权值最小的起点,第二个内循环则负责更新出最短路径,同时要保证目标顶点没有被确定最短路径

缺陷
Dijkstra算法的效率很高,但是也存在缺陷,就是无法解决带有负权路径的情况,因为此时使用贪心就不准确了,不能每次确定最短路径顶点
BellmanFord
原理
BellmanFord算法采用了暴力思想,通过把一条路径都遍历一遍,来确定源点到其它点的最短路径,虽然效率不如Dijkstra算法,但可以很好地解决负权路径问题
代码实现
初始化工作
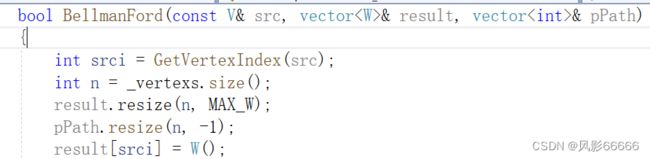
内部的两层循环,把每一条路径都遍历一遍,来找到源点到其它点的最短路径,但可能一轮循环无法更新所有源点到其它顶点的最短路径,所以还需要在最外面套一层循环,循环n-1次,来更新出源点到其它点的所有最短路径,至于为什么是n-1,是因为在一条路径上,你只需要n-1条边来连接n个节点,再多的边就构成了一个环路,这里定义了一个变量,当没有更新的时候,也就说明所有源点到其它顶点的最短路径都已经被找到了

循环完后,还需要判断一下是否存在负权回路,毕竟存在负权回路时,是不可能有最短的路径的

七、多源最短路径
概念
多源最短路径,则是求的任意两个顶点的最短路径
原理
采用的是FloydWarshall算法,核心思想是动态规划,来寻找最优解,比如找i->j的最短路径,则可以找i->k,k->j的和的最短路径,k为i->j路径上的一个中间点,也有可能k就是i
代码实现
初始化操作,这里采用两个矩阵的形式,同上面的两个算法,只不过变为了二维,同时将直接相连的边在矩阵中进行初始化

result[i][j],表示从i对应的顶点到j对应的顶点的最短路径值,pPath[i][j],表示i对应顶点到j对应顶点的最短路径中,j对应顶点的父顶点
