各种中文分词工具的使用方法
诸神缄默不语-个人CSDN博文目录
本文将介绍jieba、HanLP、LAC、THULAC、NLPIR、spacy、stanfordcorenlp、pkuseg等多种中文分词工具的简单使用方法。
对于可以在多种语言上使用的工具,本文仅介绍其在Python语言上的使用。
文章目录
- 1. jieba
- 2. HanLP
- 3. LAC
- 4. THULAC
- 5. NLPIR
- 6. spacy
- 7. Stanford Word Segmenter
- 8. stanfordcorenlp
- 9. pkuseg
- 10. 哈工大语言云
- 11. Lucene中文分词“庖丁解牛” Paoding Analysis
- 12. ik-analyzer
- 13. fnlp
- 14. ansj分词
- 15. kcws
- 16. MMSEG
- 17. 已确定不能用的分词工具
- 18. 本文撰写过程中使用的其他参考资料
1. jieba
官方GitHub项目:fxsjy/jieba: 结巴中文分词
基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG);采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法。
安装方式:pip install jieba
精确模式:jieba.cut(text)返回一个迭代器,每个元素是一个词语。(lcut()直接返回list)
import jieba
print(' '.join(jieba.cut('行动才是果实,言辞不过是枝叶。')))
输出:
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.455 seconds.
Prefix dict has been built successfully.
行动 才 是 果实 , 言辞 不过 是 枝叶 。
cut()函数的参数:
HMM:发现新词功能,自动计算的词频(下文自定义词典部分)可能无效。use_paddle:paddle模式:使用后无法自定义词典,据我猜测应该跟LAC包一样,所以不如直接用LAC包。
使用jieba.enable_parallel()可以开启并行分词模式(按行分隔文本),不支持Windows。入参是并行进程数,如无入参默认为CPU个数。
jieba.disable_parallel() 关闭并行分词模式
①添加自定义词典:jieba.load_userdict(file_name) file_name 为文件类对象或自定义词典的路径。
词典格式和 https://github.com/fxsjy/jieba/blob/master/jieba/dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name 若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。
词频省略时使用自动计算的能保证分出该词的词频。
②调整词典:add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。
使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
使用自定义词典的示例:https://github.com/fxsjy/jieba/blob/master/test/test_userdict.py
使用jieba.posseg替换jieba,还能返回词性标注。
使用jieba.tokenize()还能返回词语在原文中的起止位置,入参只接受Unicode。
如果只有用户文件夹的权限而没有/tmp的权限,则会报警告信息,可以改变分词器(默认为jieb.dt)的tmp_dir或cache_file属性来解决这一问题。
2. HanLP
官方GitHub项目:hankcs/HanLP: 中文分词 词性标注 命名实体识别 依存句法分析 成分句法分析 语义依存分析 语义角色标注 指代消解 风格转换 语义相似度 新词发现 关键词短语提取 自动摘要 文本分类聚类 拼音简繁转换 自然语言处理
官网:HanLP在线演示 多语种自然语言处理
我本来用的是pip install hanlp[full],但是这个下载太慢了,我就直接用pip install hanlp_restful了(https://hanlp.hankcs.com/install.html)
分词部分演示:https://hanlp.hankcs.com/demos/tok.html
懒得申请更多调用次数了,就直接尝试一下:
from hanlp_restful import HanLPClient
# auth不填则匿名,zh中文,mul多语种
HanLP = HanLPClient('https://www.hanlp.com/api', auth=None, language='zh')
print(HanLP.tokenize('商品和服务。晓美焰来到北京立方庭参观自然语义科技公司。', coarse=True))
输出:[['商品', '和', '服务', '。'], ['晓美焰', '来到', '北京立方庭', '参观', '自然语义科技公司', '。']]
求解的是最短路径
3. LAC
官方GitHub项目:baidu/lac: 百度NLP:分词,词性标注,命名实体识别,词重要性
论文引用:
@article{jiao2018LAC,
title={Chinese Lexical Analysis with Deep Bi-GRU-CRF Network},
author={Jiao, Zhenyu and Sun, Shuqi and Sun, Ke},
journal={arXiv preprint arXiv:1807.01882},
year={2018},
url={https://arxiv.org/abs/1807.01882}
}
安装方式 :pip install lac 或 pip install lac -i https://mirror.baidu.com/pypi/simple
extracted_sentences="随着企业持续产生的商品销量,其数据对于自身营销规划、市场分析、物流规划都有重要意义。但是销量预测的影响因素繁多,传统的基于统计的计量模型,比如时间序列模型等由于对现实的假设情况过多,导致预测结果较差。因此需要更加优秀的智能AI算法,以提高预测的准确性,从而助力企业降低库存成本、缩短交货周期、提高企业抗风险能力。"
from LAC import LAC
lac=LAC(mode='seg') #默认值mode='lac'会附带词性标注功能,对应的标签见后文
seg_result=lac.run(extracted_sentences) #以Unicode字符串为入参
print(seg_result)
seg_result=lac.run(extracted_sentences.split(',')) #以字符串列表为入参,平均速率会更快
print(seg_result)
输出:
W0625 20:03:29.850801 32781 init.cc:157] AVX is available, Please re-compile on local machine
W0625 20:03:29.868482 32781 analysis_predictor.cc:518] - GLOG's LOG(INFO) is disabled.
W0625 20:03:29.868522 32781 init.cc:157] AVX is available, Please re-compile on local machine
--- Running analysis [ir_graph_build_pass]
--- Running analysis [ir_graph_clean_pass]
--- Running analysis [ir_analysis_pass]
--- Running IR pass [simplify_with_basic_ops_pass]
--- Running IR pass [attention_lstm_fuse_pass]
--- Running IR pass [seqconv_eltadd_relu_fuse_pass]
--- Running IR pass [seqpool_cvm_concat_fuse_pass]
--- Running IR pass [fc_lstm_fuse_pass]
--- Running IR pass [mul_lstm_fuse_pass]
--- Running IR pass [fc_gru_fuse_pass]
--- Running IR pass [mul_gru_fuse_pass]
--- Running IR pass [seq_concat_fc_fuse_pass]
--- Running IR pass [fc_fuse_pass]
--- Running IR pass [repeated_fc_relu_fuse_pass]
--- Running IR pass [squared_mat_sub_fuse_pass]
--- Running IR pass [conv_bn_fuse_pass]
--- Running IR pass [conv_eltwiseadd_bn_fuse_pass]
--- Running IR pass [is_test_pass]
--- Running IR pass [runtime_context_cache_pass]
--- Running analysis [ir_params_sync_among_devices_pass]
--- Running analysis [adjust_cudnn_workspace_size_pass]
--- Running analysis [inference_op_replace_pass]
--- Running analysis [ir_graph_to_program_pass]
['随着', '企业', '持续', '产生', '的', '商品', '销量', ',', '其', '数据', '对于', '自身', '营销', '规划', '、', '市场分析', '、', '物流', '规划', '都', '有', '重要', '意义', '。', '但是', '销量', '预测', '的', '影响', '因素', '繁多', ',', '传统', '的', '基于', '统计', '的', '计量', '模型', ',', '比如', '时间', '序列', '模型', '等', '由于', '对', '现实', '的', '假设', '情况', '过多', ',', '导致', '预测', '结果', '较差', '。', '因此', '需要', '更加', '优秀', '的', '智能', 'AI', '算法', ',', '以', '提高', '预测', '的', '准确性', ',', '从而', '助力', '企业', '降低', '库存', '成本', '、', '缩短', '交货', '周期', '、', '提高', '企业', '抗', '风险', '能力', '。']
[['随着', '企业', '持续', '产生', '的', '商品', '销量'], ['其', '数据', '对于', '自身', '营销', '规划', '、', '市场分析', '、', '物流', '规划', '都', '有', '重要', '意义', '。', '但是', '销量', '预测', '的', '影响', '因素', '繁多'], ['传统', '的', '基于', '统计', '的', '计量', '模型'], ['比如', '时间', '序列', '模型', '等', '由于', '对', '现实', '的', '假设', '情况', '过多'], ['导致', '预测', '结果', '较差', '。', '因此', '需要', '更加', '优秀', '的', '智能', 'AI', '算法'], ['以', '提高', '预测', '的', '准确性'], ['从而', '助力', '企业', '降低', '库存', '成本', '、', '缩短', '交货', '周期', '、', '提高', '企业', '抗', '风险', '能力', '。']]
很诡异,我之前以为需要Python 3.7就可以正常安装并运行LAC包,但现在我不管用Python3.7还是3.8都会打印这个警告:W0510 18:52:02.578514 4883 analysis_predictor.cc:2166] Deprecated. Please use CreatePredictor instead.
感觉下次可以考虑不用这个包了,怎么会出现这种奇怪的问题还好久没有改进呢,是不是不维护了啊
词性标注功能的标签:
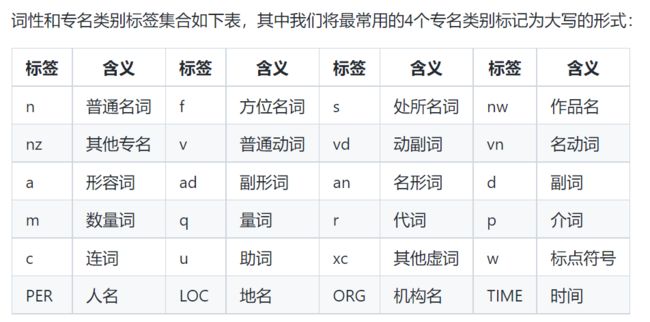
使用自定义词典:item将不会被分割。
词典文件每行表示一个定制化的item,由一个单词或多个连续的单词组成,每个单词后使用’/‘表示标签,如果没有’/'标签则会使用模型默认的标签。每个item单词数越多,干预效果会越精准。
词典文件示例:
春天/SEASON
花/n 开/v
秋天的风
落 阳
在run()之前就使用代码:
# 装载干预词典, sep参数表示词典文件采用的分隔符,为None时默认使用空格或制表符'\t'
lac.load_customization('custom.txt', sep=None)
4. THULAC
官网:THULAC:一个高效的中文词法分析工具包
这个文档真的是这篇博文里面最难用的。
在线演示网址:THULAC:一个高效的中文词法分析工具包
安装方式:pip install thulac(注意不支持Python3.8及以后的版本,毕竟会报这个错:AttributeError: module 'time' has no attribute 'clock')
import thulac
extracted_sentences="随着企业持续产生的商品销量,其数据对于自身营销规划、市场分析、物流规划都有重要意义。但是销量预测的影响因素繁多,传统的基于统计的计量模型,比如时间序列模型等由于对现实的假设情况过多,导致预测结果较差。因此需要更加优秀的智能AI算法,以提高预测的准确性,从而助力企业降低库存成本、缩短交货周期、提高企业抗风险能力。"
model=thulac.thulac()
print(model.cut(extracted_sentences))
输出:
Model loaded succeed
[['随着', 'p'], ['企业', 'n'], ['持续', 'v'], ['产生', 'v'], ['的', 'u'], ['商品', 'n'], ['销量', 'n'], [',', 'w'], ['其', 'r'], ['数据', 'n'], ['对于', 'p'], ['自身', 'r'], ['营销', 'v'], ['规划', 'n'], ['、', 'w'], ['市场', 'n'], ['分析', 'v'], ['、', 'w'], ['物流', 'n'], ['规划', 'v'], ['都', 'd'], ['有', 'v'], ['重要', 'a'], ['意义', 'n'], ['。', 'w'], ['但是', 'c'], ['销量', 'n'], ['预测', 'v'], ['的', 'u'], ['影响', 'v'], ['因素', 'n'], ['繁多', 'a'], [',', 'w'], ['传统', 'n'], ['的', 'u'], ['基于', 'p'], ['统计', 'v'], ['的', 'u'], ['计量', 'v'], ['模型', 'n'], [',', 'w'], ['比如', 'v'], ['时间', 'n'], ['序列', 'n'], ['模型', 'n'], ['等', 'u'], ['由于', 'c'], ['对', 'p'], ['现实', 'n'], ['的', 'u'], ['假设', 'n'], ['情况', 'n'], ['过', 'd'], ['多', 'a'], [',', 'w'], ['导致', 'v'], ['预测', 'v'], ['结果', 'n'], ['较', 'd'], ['差', 'a'], ['。', 'w'], ['因此', 'c'], ['需要', 'v'], ['更加', 'd'], ['优秀', 'a'], ['的', 'u'], ['智能', 'n'], ['AI算法', 'n'], [',', 'w'], ['以', 'c'], ['提高', 'v'], ['预测', 'v'], ['的', 'u'], ['准确性', 'n'], [',', 'w'], ['从而', 'c'], ['助力', 'v'], ['企业', 'n'], ['降低', 'v'], ['库存', 'v'], ['成本', 'n'], ['、', 'w'], ['缩短', 'v'], ['交货', 'v'], ['周期', 'n'], ['、', 'w'], ['提高', 'v'], ['企业', 'n'], ['抗', 'v'], ['风险', 'n'], ['能力', 'n'], ['。', 'w']]
词性标注的标签:
n/名词 np/人名 ns/地名 ni/机构名 nz/其它专名
m/数词 q/量词 mq/数量词 t/时间词 f/方位词 s/处所词
v/动词 a/形容词 d/副词 h/前接成分 k/后接成分 i/习语
j/简称 r/代词 c/连词 p/介词 u/助词 y/语气助词
e/叹词 o/拟声词 g/语素 w/标点 x/其它
如果想要仅分词,不用词性标注的话,可以在调用thulac.thulac()时置入参seg_only=True
注意这个似乎是简化版本,复杂版本的模型需要申请:

5. NLPIR
官方GitHub项目:NLPIR-team/NLPIR
官网:NLPIR自然语言处理与信息检索共享平台 – NLPIR Natural Language Processing & Information Retrieval Sharing Platform 自然语言处理、大数据实验室、智能语义平台 汉语分词、中文语义分析、中文信息处理、语义分析系统、中文知识图谱、大数据分析工具
NLPIR汉语分词系统官网:NLPIR-ICTCLAS汉语分词系统-首页
看了一下这个还需要下载软件,感觉用起来不方便,如果以后真的需要了再补吧。
6. spacy
spacy模型官网:Trained Models & Pipelines · spaCy Models Documentation
extracted_sentences="随着企业持续产生的商品销量,其数据对于自身营销规划、市场分析、物流规划都有重要意义。但是销量预测的影响因素繁多,传统的基于统计的计量模型,比如时间序列模型等由于对现实的假设情况过多,导致预测结果较差。因此需要更加优秀的智能AI算法,以提高预测的准确性,从而助力企业降低库存成本、缩短交货周期、提高企业抗风险能力。"
import zh_core_web_sm
nlp = zh_core_web_sm.load()
doc = nlp(extracted_sentences)
print([(w.text, w.pos_) for w in doc])
输出:[('随着', 'ADP'), ('企业', 'NOUN'), ('持续', 'ADV'), ('产生', 'VERB'), ('的', 'PART'), ('商品', 'NOUN'), ('销量', 'NOUN'), (',', 'PUNCT'), ('其', 'PRON'), ('数据', 'NOUN'), ('对于', 'ADP'), ('自身', 'PRON'), ('营销', 'NOUN'), ('规划', 'NOUN'), ('、', 'PUNCT'), ('市场', 'NOUN'), ('分析', 'NOUN'), ('、', 'PUNCT'), ('物流', 'NOUN'), ('规划', 'NOUN'), ('都', 'ADV'), ('有', 'VERB'), ('重要', 'ADJ'), ('意义', 'NOUN'), ('。', 'PUNCT'), ('但是', 'ADV'), ('销量', 'VERB'), ('预测', 'NOUN'), ('的', 'PART'), ('影响', 'NOUN'), ('因素', 'NOUN'), ('繁多', 'VERB'), (',', 'PUNCT'), ('传统', 'ADJ'), ('的', 'PART'), ('基于', 'ADP'), ('统计', 'NOUN'), ('的', 'PART'), ('计量', 'NOUN'), ('模型', 'NOUN'), (',', 'PUNCT'), ('比如', 'ADV'), ('时间', 'NOUN'), ('序列', 'NOUN'), ('模型', 'NOUN'), ('等', 'PART'), ('由于', 'ADP'), ('对', 'ADP'), ('现实', 'NOUN'), ('的', 'PART'), ('假设', 'NOUN'), ('情况', 'NOUN'), ('过', 'ADV'), ('多', 'VERB'), (',', 'PUNCT'), ('导致', 'VERB'), ('预测', 'NOUN'), ('结果', 'NOUN'), ('较', 'ADV'), ('差', 'VERB'), ('。', 'PUNCT'), ('因此', 'ADV'), ('需要', 'VERB'), ('更加', 'ADV'), ('优秀', 'VERB'), ('的', 'PART'), ('智能', 'NOUN'), ('AI算法', 'NOUN'), (',', 'PUNCT'), ('以', 'PART'), ('提高', 'VERB'), ('预测', 'NOUN'), ('的', 'PART'), ('准确性', 'NOUN'), (',', 'PUNCT'), ('从而', 'ADV'), ('助力', 'NOUN'), ('企业', 'NOUN'), ('降低', 'VERB'), ('库存', 'NOUN'), ('成本', 'NOUN'), ('、', 'PUNCT'), ('缩短', 'VERB'), ('交货', 'VERB'), ('周期', 'NOUN'), ('、', 'PUNCT'), ('提高', 'VERB'), ('企业', 'NOUN'), ('抗', 'NOUN'), ('风险', 'NOUN'), ('能力', 'NOUN'), ('。', 'PUNCT')]
词性标注的标签可参考:Universal POS tags
7. Stanford Word Segmenter
(严格来说不算是Python工具包,但是也能用来中文分词,所以也放到本博文中)
官网:The Stanford Natural Language Processing Group
教程:Parsing Chinese text with Stanford NLP - Michelle Fullwood
CRF算法
例句来自为什么说《哈姆雷特》是神作? - 一只浪迹天涯的猫的回答 - 知乎:
“默然忍受命运的暴虐的毒箭,或是挺身反抗人世无涯的痛苦,通过斗争把他们清扫,这两种行为,究竟哪一种更高贵?”而在莎翁笔下,这样的挣扎困苦被映射到了极致——是坚持基督徒所信奉的不可充当“上帝的凶器”,还是选择完成挪威狂热异教徒式的传奇复仇?
将例句保存为文本文件。
需要Java 1.8+,可以通过java -version命令行查看是否安装:
openjdk version "1.8.0_342"
OpenJDK Runtime Environment (build 1.8.0_342-8u342-b07-0ubuntu1~18.04-b07)
OpenJDK 64-Bit Server VM (build 25.342-b07, mixed mode)
下载地址:https://nlp.stanford.edu/software/stanford-segmenter-4.2.0.zip
解压缩zip文件:
命令行:解压缩文件中的stanford-segmenter-2020-11-17/segment.sh地址 pku 例句文件地址 UTF-8 0 > 储存分词后文本的文件地址
输出:
(PKU):
File: try1.txt
Encoding: UTF-8
-------------------------------
Invoked on Tue Aug 23 14:45:42 CST 2022 with arguments: -sighanCorporaDict install_packages/stanford-segmenter-2020-11-17/data -textFile try1.txt -inputEncoding UTF-8 -sighanPostProcessing true -keepAllWhitespaces false -loadClassifier install_packages/stanford-segmenter-2020-11-17/data/pku.gz -serDictionary install_packages/stanford-segmenter-2020-11-17/data/dict-chris6.ser.gz
serDictionary=install_packages/stanford-segmenter-2020-11-17/data/dict-chris6.ser.gz
loadClassifier=install_packages/stanford-segmenter-2020-11-17/data/pku.gz
sighanCorporaDict=install_packages/stanford-segmenter-2020-11-17/data
inputEncoding=UTF-8
textFile=try1.txt
sighanPostProcessing=true
keepAllWhitespaces=false
Loading classifier from install_packages/stanford-segmenter-2020-11-17/data/pku.gz ... done [7.3 sec].
Loading Chinese dictionaries from 1 file:
install_packages/stanford-segmenter-2020-11-17/data/dict-chris6.ser.gz
Done. Unique words in ChineseDictionary is: 423200.
Loading unnormalized dictionary from install_packages/stanford-segmenter-2020-11-17/data/dict/pku.non
INFO: flags.usePk=true | building NonDict2 from install_packages/stanford-segmenter-2020-11-17/data/dict/pku.non
Loading character dictionary file from install_packages/stanford-segmenter-2020-11-17/data/dict/pos_open/character_list.pku.utf8 [done].
Loading affix dictionary from install_packages/stanford-segmenter-2020-11-17/data/dict/in.pk [done].
CRFClassifier tagged 119 words in 1 documents at 826.39 words per second.
输出文件中的内容:
“ 默然 忍受 命运 的 暴虐 的 毒箭 , 或是 挺身 反抗 人世 无 涯 的 痛苦 , 通过 斗争 把 他们 清扫 , 这 两 种 行为 , 究竟 哪 一 种 更 高贵 ? ” 而 在 莎翁 笔下 , 这样 的 挣扎 困苦 被 映射 到 了 极致 —— 是 坚持 基督徒 所 信奉 的 不可 充当 “ 上帝 的 凶器 ” , 还是 选择 完成 挪威 狂热 异教徒 式 的 传奇 复仇 ?
8. stanfordcorenlp
(有bug,不知道为什么会这样,已经提issue了:Unable to print word_tokenize Chinese word · Issue #106 · Lynten/stanford-corenlp)
官方GitHub项目:Lynten/stanford-corenlp: Python wrapper for Stanford CoreNLP.
这是一个Stanford CoreNLP的Python包。跟第7节介绍的一样,需要Java 1.8+。
Stanford CoreNLP下载地址:Release History - CoreNLP。我是在Python3.7环境中安装,所以需要安装CoreNLP 3.7.0:http://nlp.stanford.edu/software/stanford-corenlp-full-2016-10-31.zip和http://nlp.stanford.edu/software/stanford-chinese-corenlp-2016-10-31-models.jar
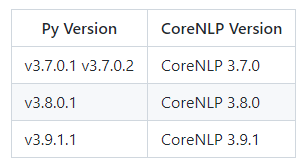
解压缩这个zip文件,然后把jar包放到解压缩文件夹里,然后运行如下Python代码:
from stanfordcorenlp import StanfordCoreNLP
# Other human languages support, e.g. Chinese
sentence = '清华大学位于北京。'
with StanfordCoreNLP(r'install_packages/stanford-corenlp-full-2016-10-31', lang='zh') as nlp:
print(nlp.word_tokenize(sentence))
print(nlp.pos_tag(sentence))
print(nlp.ner(sentence))
print(nlp.parse(sentence))
print(nlp.dependency_parse(sentence))
输出:
['', '', '', '', '']
[('', 'NR'), ('', 'NN'), ('', 'VV'), ('', 'NR'), ('', 'PU')]
[('', 'ORGANIZATION'), ('', 'ORGANIZATION'), ('', 'O'), ('', 'GPE'), ('', 'O')]
(ROOT
(IP
(NP (NR 清华) (NN 大学))
(VP (VV 位于)
(NP (NR 北京)))
(PU 。)))
[('ROOT', 0, 3), ('compound:nn', 2, 1), ('nsubj', 3, 2), ('dobj', 3, 4), ('punct', 3, 5)]
在解压缩文件夹里直接用命令行倒是可以跑(教程:Command Line Usage - CoreNLP):
命令行:java -mx3g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLP -props StanfordCoreNLP-chinese.properties -file try1.txt -outputFormat text
在命令行的输出:
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator tokenize
[main] INFO edu.stanford.nlp.wordseg.ChineseDictionary - Loading Chinese dictionaries from 1 file:
[main] INFO edu.stanford.nlp.wordseg.ChineseDictionary - edu/stanford/nlp/models/segmenter/chinese/dict-chris6.ser.gz
[main] INFO edu.stanford.nlp.wordseg.ChineseDictionary - Done. Unique words in ChineseDictionary is: 423200.
[main] INFO edu.stanford.nlp.ie.AbstractSequenceClassifier - Loading classifier from edu/stanford/nlp/models/segmenter/chinese/ctb.gz ... done [8.0 sec].
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator ssplit
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator pos
[main] INFO edu.stanford.nlp.tagger.maxent.MaxentTagger - Loading POS tagger from edu/stanford/nlp/models/pos-tagger/chinese-distsim/chinese-distsim.tagger ... done [0.7 sec].
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator lemma
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator ner
[main] INFO edu.stanford.nlp.ie.AbstractSequenceClassifier - Loading classifier from edu/stanford/nlp/models/ner/chinese.misc.distsim.crf.ser.gz ... done [8.2 sec].
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator parse
[main] INFO edu.stanford.nlp.parser.common.ParserGrammar - Loading parser from serialized file edu/stanford/nlp/models/srparser/chineseSR.ser.gz ... done [14.4 sec].
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator mention
[main] INFO edu.stanford.nlp.pipeline.MentionAnnotator - Using mention detector type: rule
[main] INFO edu.stanford.nlp.pipeline.StanfordCoreNLP - Adding annotator coref
Processing file try1.txt ... writing to install_packages/stanford-corenlp-full-2016-10-31/try1.txt.out
Loading character dictionary file from edu/stanford/nlp/models/segmenter/chinese/dict/character_list [done].
Loading affix dictionary from edu/stanford/nlp/models/segmenter/chinese/dict/in.ctb [done].
Annotating file try1.txt ... done [0.5 sec].
Annotation pipeline timing information:
TokenizerAnnotator: 0.1 sec.
WordsToSentencesAnnotator: 0.0 sec.
POSTaggerAnnotator: 0.0 sec.
MorphaAnnotator: 0.1 sec.
NERCombinerAnnotator: 0.0 sec.
ParserAnnotator: 0.2 sec.
MentionAnnotator: 0.0 sec.
CorefAnnotator: 0.1 sec.
TOTAL: 0.5 sec. for 76 tokens at 141.0 tokens/sec.
Pipeline setup: 62.1 sec.
Total time for StanfordCoreNLP pipeline: 62.7 sec.
install_packages/stanford-corenlp-full-2016-10-31/try1.txt.out:
Sentence #1 (36 tokens):
“默然忍受命运的暴虐的毒箭,或是挺身反抗人世无涯的痛苦,通过斗争把他们清扫,这两种行为,究竟哪一种更高贵?”
[Text=“ CharacterOffsetBegin=0 CharacterOffsetEnd=1 PartOfSpeech=PU Lemma=“ NamedEntityTag=O]
[Text=默然 CharacterOffsetBegin=1 CharacterOffsetEnd=3 PartOfSpeech=AD Lemma=默然 NamedEntityTag=O]
[Text=忍受 CharacterOffsetBegin=3 CharacterOffsetEnd=5 PartOfSpeech=VV Lemma=忍受 NamedEntityTag=O]
[Text=命运 CharacterOffsetBegin=5 CharacterOffsetEnd=7 PartOfSpeech=NN Lemma=命运 NamedEntityTag=O]
[Text=的 CharacterOffsetBegin=7 CharacterOffsetEnd=8 PartOfSpeech=DEC Lemma=的 NamedEntityTag=O]
[Text=暴虐 CharacterOffsetBegin=8 CharacterOffsetEnd=10 PartOfSpeech=NN Lemma=暴虐 NamedEntityTag=O]
[Text=的 CharacterOffsetBegin=10 CharacterOffsetEnd=11 PartOfSpeech=DEG Lemma=的 NamedEntityTag=O]
[Text=毒箭 CharacterOffsetBegin=11 CharacterOffsetEnd=13 PartOfSpeech=NN Lemma=毒箭 NamedEntityTag=O]
[Text=, CharacterOffsetBegin=13 CharacterOffsetEnd=14 PartOfSpeech=PU Lemma=, NamedEntityTag=O]
[Text=或是 CharacterOffsetBegin=14 CharacterOffsetEnd=16 PartOfSpeech=CC Lemma=或是 NamedEntityTag=O]
[Text=挺身 CharacterOffsetBegin=16 CharacterOffsetEnd=18 PartOfSpeech=VV Lemma=挺身 NamedEntityTag=O]
[Text=反抗 CharacterOffsetBegin=18 CharacterOffsetEnd=20 PartOfSpeech=VV Lemma=反抗 NamedEntityTag=O]
[Text=人世 CharacterOffsetBegin=20 CharacterOffsetEnd=22 PartOfSpeech=NN Lemma=人世 NamedEntityTag=O]
[Text=无涯 CharacterOffsetBegin=22 CharacterOffsetEnd=24 PartOfSpeech=VV Lemma=无涯 NamedEntityTag=O]
[Text=的 CharacterOffsetBegin=24 CharacterOffsetEnd=25 PartOfSpeech=DEC Lemma=的 NamedEntityTag=O]
[Text=痛苦 CharacterOffsetBegin=25 CharacterOffsetEnd=27 PartOfSpeech=NN Lemma=痛苦 NamedEntityTag=O]
[Text=, CharacterOffsetBegin=27 CharacterOffsetEnd=28 PartOfSpeech=PU Lemma=, NamedEntityTag=O]
[Text=通过 CharacterOffsetBegin=28 CharacterOffsetEnd=30 PartOfSpeech=P Lemma=通过 NamedEntityTag=O]
[Text=斗争 CharacterOffsetBegin=30 CharacterOffsetEnd=32 PartOfSpeech=NN Lemma=斗争 NamedEntityTag=O]
[Text=把 CharacterOffsetBegin=32 CharacterOffsetEnd=33 PartOfSpeech=BA Lemma=把 NamedEntityTag=O]
[Text=他们 CharacterOffsetBegin=33 CharacterOffsetEnd=35 PartOfSpeech=PN Lemma=他们 NamedEntityTag=O]
[Text=清扫 CharacterOffsetBegin=35 CharacterOffsetEnd=37 PartOfSpeech=VV Lemma=清扫 NamedEntityTag=O]
[Text=, CharacterOffsetBegin=37 CharacterOffsetEnd=38 PartOfSpeech=PU Lemma=, NamedEntityTag=O]
[Text=这 CharacterOffsetBegin=38 CharacterOffsetEnd=39 PartOfSpeech=DT Lemma=这 NamedEntityTag=O]
[Text=两 CharacterOffsetBegin=39 CharacterOffsetEnd=40 PartOfSpeech=CD Lemma=两 NamedEntityTag=NUMBER NormalizedNamedEntityTag=2]
[Text=种 CharacterOffsetBegin=40 CharacterOffsetEnd=41 PartOfSpeech=M Lemma=种 NamedEntityTag=O]
[Text=行为 CharacterOffsetBegin=41 CharacterOffsetEnd=43 PartOfSpeech=NN Lemma=行为 NamedEntityTag=O]
[Text=, CharacterOffsetBegin=43 CharacterOffsetEnd=44 PartOfSpeech=PU Lemma=, NamedEntityTag=O]
[Text=究竟 CharacterOffsetBegin=44 CharacterOffsetEnd=46 PartOfSpeech=AD Lemma=究竟 NamedEntityTag=O]
[Text=哪 CharacterOffsetBegin=46 CharacterOffsetEnd=47 PartOfSpeech=DT Lemma=哪 NamedEntityTag=O]
[Text=一 CharacterOffsetBegin=47 CharacterOffsetEnd=48 PartOfSpeech=CD Lemma=一 NamedEntityTag=NUMBER NormalizedNamedEntityTag=1]
[Text=种 CharacterOffsetBegin=48 CharacterOffsetEnd=49 PartOfSpeech=M Lemma=种 NamedEntityTag=O]
[Text=更 CharacterOffsetBegin=49 CharacterOffsetEnd=50 PartOfSpeech=AD Lemma=更 NamedEntityTag=O]
[Text=高贵 CharacterOffsetBegin=50 CharacterOffsetEnd=52 PartOfSpeech=JJ Lemma=高贵 NamedEntityTag=O]
[Text=? CharacterOffsetBegin=52 CharacterOffsetEnd=53 PartOfSpeech=PU Lemma=? NamedEntityTag=O]
[Text=” CharacterOffsetBegin=53 CharacterOffsetEnd=54 PartOfSpeech=PU Lemma=” NamedEntityTag=O]
(ROOT
(IP
(IP (PU “)
(NP
(CP
(IP
(VP
(ADVP (AD 默然))
(VP (VV 忍受)
(NP (NN 命运)))))
(DEC 的))
(DNP
(NP (NN 暴虐))
(DEG 的))
(NP (NN 毒箭)))
(PU ,)
(VP (CC 或是)
(VP (VV 挺身)
(NP
(CP
(IP
(VP
(VP (VV 反抗)
(NP (NN 人世)))
(VP (VV 无涯))))
(DEC 的))
(NP (NN 痛苦))))
(PU ,)
(VP
(PP (P 通过)
(NP (NN 斗争)))
(VP (BA 把)
(IP
(NP (PN 他们))
(VP (VV 清扫)))))))
(PU ,)
(IP
(NP
(DP (DT 这)
(QP (CD 两)
(CLP (M 种))))
(NP (NN 行为)))
(PU ,)
(ADVP (AD 究竟))
(DP (DT 哪)
(QP (CD 一)
(CLP (M 种))))
(VP
(ADVP (AD 更))
(VP (JJ 高贵)))
(PU ?) (PU ”))))
root(ROOT-0, 挺身-11)
punct(挺身-11, “-1)
advmod(忍受-3, 默然-2)
acl(毒箭-8, 忍受-3)
dobj(忍受-3, 命运-4)
mark(忍受-3, 的-5)
nmod:assmod(毒箭-8, 暴虐-6)
case(暴虐-6, 的-7)
nsubj(挺身-11, 毒箭-8)
punct(挺身-11, ,-9)
cc(挺身-11, 或是-10)
acl(痛苦-16, 反抗-12)
dobj(反抗-12, 人世-13)
conj(反抗-12, 无涯-14)
mark(反抗-12, 的-15)
dobj(挺身-11, 痛苦-16)
punct(挺身-11, ,-17)
case(斗争-19, 通过-18)
nmod:prep(清扫-22, 斗争-19)
aux:ba(清扫-22, 把-20)
dep(清扫-22, 他们-21)
conj(挺身-11, 清扫-22)
punct(挺身-11, ,-23)
det(行为-27, 这-24)
dep(这-24, 两-25)
mark:clf(两-25, 种-26)
dep(高贵-34, 行为-27)
punct(高贵-34, ,-28)
advmod(高贵-34, 究竟-29)
dep(高贵-34, 哪-30)
dep(哪-30, 一-31)
mark:clf(一-31, 种-32)
advmod(高贵-34, 更-33)
conj(挺身-11, 高贵-34)
punct(高贵-34, ?-35)
punct(高贵-34, ”-36)
Sentence #2 (40 tokens):
而在莎翁笔下,这样的挣扎困苦被映射到了极致——是坚持基督徒所信奉的不可充当“上帝的凶器”,还是选择完成挪威狂热异教徒式的传奇复仇?
[Text=而 CharacterOffsetBegin=54 CharacterOffsetEnd=55 PartOfSpeech=AD Lemma=而 NamedEntityTag=O]
[Text=在 CharacterOffsetBegin=55 CharacterOffsetEnd=56 PartOfSpeech=P Lemma=在 NamedEntityTag=O]
[Text=莎翁 CharacterOffsetBegin=56 CharacterOffsetEnd=58 PartOfSpeech=NN Lemma=莎翁 NamedEntityTag=O]
[Text=笔下 CharacterOffsetBegin=58 CharacterOffsetEnd=60 PartOfSpeech=NN Lemma=笔下 NamedEntityTag=O]
[Text=, CharacterOffsetBegin=60 CharacterOffsetEnd=61 PartOfSpeech=PU Lemma=, NamedEntityTag=O]
[Text=这样 CharacterOffsetBegin=61 CharacterOffsetEnd=63 PartOfSpeech=JJ Lemma=这样 NamedEntityTag=O]
[Text=的 CharacterOffsetBegin=63 CharacterOffsetEnd=64 PartOfSpeech=DEG Lemma=的 NamedEntityTag=O]
[Text=挣扎 CharacterOffsetBegin=64 CharacterOffsetEnd=66 PartOfSpeech=NN Lemma=挣扎 NamedEntityTag=O]
[Text=困苦 CharacterOffsetBegin=66 CharacterOffsetEnd=68 PartOfSpeech=NN Lemma=困苦 NamedEntityTag=O]
[Text=被 CharacterOffsetBegin=68 CharacterOffsetEnd=69 PartOfSpeech=SB Lemma=被 NamedEntityTag=O]
[Text=映射 CharacterOffsetBegin=69 CharacterOffsetEnd=71 PartOfSpeech=VV Lemma=映射 NamedEntityTag=O]
[Text=到 CharacterOffsetBegin=71 CharacterOffsetEnd=72 PartOfSpeech=VV Lemma=到 NamedEntityTag=O]
[Text=了 CharacterOffsetBegin=72 CharacterOffsetEnd=73 PartOfSpeech=AS Lemma=了 NamedEntityTag=O]
[Text=极致 CharacterOffsetBegin=73 CharacterOffsetEnd=75 PartOfSpeech=VA Lemma=极致 NamedEntityTag=O]
[Text=—— CharacterOffsetBegin=75 CharacterOffsetEnd=77 PartOfSpeech=PU Lemma=—— NamedEntityTag=O]
[Text=是 CharacterOffsetBegin=77 CharacterOffsetEnd=78 PartOfSpeech=VC Lemma=是 NamedEntityTag=O]
[Text=坚持 CharacterOffsetBegin=78 CharacterOffsetEnd=80 PartOfSpeech=VV Lemma=坚持 NamedEntityTag=O]
[Text=基督徒 CharacterOffsetBegin=80 CharacterOffsetEnd=83 PartOfSpeech=NN Lemma=基督徒 NamedEntityTag=DEMONYM]
[Text=所 CharacterOffsetBegin=83 CharacterOffsetEnd=84 PartOfSpeech=MSP Lemma=所 NamedEntityTag=O]
[Text=信奉 CharacterOffsetBegin=84 CharacterOffsetEnd=86 PartOfSpeech=VV Lemma=信奉 NamedEntityTag=O]
[Text=的 CharacterOffsetBegin=86 CharacterOffsetEnd=87 PartOfSpeech=DEC Lemma=的 NamedEntityTag=O]
[Text=不可 CharacterOffsetBegin=87 CharacterOffsetEnd=89 PartOfSpeech=AD Lemma=不可 NamedEntityTag=O]
[Text=充当 CharacterOffsetBegin=89 CharacterOffsetEnd=91 PartOfSpeech=VV Lemma=充当 NamedEntityTag=O]
[Text=“ CharacterOffsetBegin=91 CharacterOffsetEnd=92 PartOfSpeech=PU Lemma=“ NamedEntityTag=O]
[Text=上帝 CharacterOffsetBegin=92 CharacterOffsetEnd=94 PartOfSpeech=NR Lemma=上帝 NamedEntityTag=PERSON]
[Text=的 CharacterOffsetBegin=94 CharacterOffsetEnd=95 PartOfSpeech=DEG Lemma=的 NamedEntityTag=O]
[Text=凶器 CharacterOffsetBegin=95 CharacterOffsetEnd=97 PartOfSpeech=NN Lemma=凶器 NamedEntityTag=O]
[Text=” CharacterOffsetBegin=97 CharacterOffsetEnd=98 PartOfSpeech=PU Lemma=” NamedEntityTag=O]
[Text=, CharacterOffsetBegin=98 CharacterOffsetEnd=99 PartOfSpeech=PU Lemma=, NamedEntityTag=O]
[Text=还是 CharacterOffsetBegin=99 CharacterOffsetEnd=101 PartOfSpeech=CC Lemma=还是 NamedEntityTag=O]
[Text=选择 CharacterOffsetBegin=101 CharacterOffsetEnd=103 PartOfSpeech=VV Lemma=选择 NamedEntityTag=O]
[Text=完成 CharacterOffsetBegin=103 CharacterOffsetEnd=105 PartOfSpeech=VV Lemma=完成 NamedEntityTag=O]
[Text=挪威 CharacterOffsetBegin=105 CharacterOffsetEnd=107 PartOfSpeech=NR Lemma=挪威 NamedEntityTag=GPE]
[Text=狂热 CharacterOffsetBegin=107 CharacterOffsetEnd=109 PartOfSpeech=JJ Lemma=狂热 NamedEntityTag=O]
[Text=异教徒 CharacterOffsetBegin=109 CharacterOffsetEnd=112 PartOfSpeech=NN Lemma=异教徒 NamedEntityTag=O]
[Text=式 CharacterOffsetBegin=112 CharacterOffsetEnd=113 PartOfSpeech=NN Lemma=式 NamedEntityTag=O]
[Text=的 CharacterOffsetBegin=113 CharacterOffsetEnd=114 PartOfSpeech=DEG Lemma=的 NamedEntityTag=O]
[Text=传奇 CharacterOffsetBegin=114 CharacterOffsetEnd=116 PartOfSpeech=NN Lemma=传奇 NamedEntityTag=O]
[Text=复仇 CharacterOffsetBegin=116 CharacterOffsetEnd=118 PartOfSpeech=NN Lemma=复仇 NamedEntityTag=O]
[Text=? CharacterOffsetBegin=118 CharacterOffsetEnd=119 PartOfSpeech=PU Lemma=? NamedEntityTag=O]
(ROOT
(IP
(ADVP (AD 而))
(PP (P 在)
(NP (NN 莎翁) (NN 笔下)))
(PU ,)
(NP
(DNP
(NP (JJ 这样))
(DEG 的))
(NP (NN 挣扎) (NN 困苦)))
(VP (SB 被)
(VP
(VRD (VV 映射) (VV 到))
(AS 了)
(ADVP (VA 极致))))
(PRN (PU ——)
(VP (VC 是)
(VP (VV 坚持)
(IP
(NP
(CP
(IP
(NP (NN 基督徒))
(VP (MSP 所)
(VP (VV 信奉))))
(DEC 的)))
(VP
(ADVP (AD 不可))
(VP (VV 充当) (PU “)
(IP
(NP
(DNP
(NP (NR 上帝))
(DEG 的))
(NP (NN 凶器))
(PU ”))
(PU ,)
(CC 还是)
(VP (VV 选择)
(IP
(VP (VV 完成)
(NP
(DNP
(NP
(NP
(NP (NR 挪威))
(ADJP (JJ 狂热))
(NP (NN 异教徒)))
(NP (NN 式)))
(DEG 的))
(NP (NN 传奇) (NN 复仇)))))))))))))
(PU ?)))
root(ROOT-0, 映射-11)
advmod(映射-11, 而-1)
case(笔下-4, 在-2)
compound:nn(笔下-4, 莎翁-3)
nmod:prep(映射-11, 笔下-4)
punct(映射-11, ,-5)
nmod:assmod(困苦-9, 这样-6)
case(这样-6, 的-7)
compound:nn(困苦-9, 挣扎-8)
nsubjpass(映射-11, 困苦-9)
auxpass(映射-11, 被-10)
advmod:rcomp(映射-11, 到-12)
aux:asp(映射-11, 了-13)
advmod(映射-11, 极致-14)
punct(坚持-17, ——-15)
cop(坚持-17, 是-16)
dep(映射-11, 坚持-17)
nsubj(信奉-20, 基督徒-18)
aux:prtmod(信奉-20, 所-19)
nsubj(充当-23, 信奉-20)
mark(信奉-20, 的-21)
advmod(充当-23, 不可-22)
ccomp(坚持-17, 充当-23)
punct(充当-23, “-24)
nmod:assmod(凶器-27, 上帝-25)
case(上帝-25, 的-26)
dep(选择-31, 凶器-27)
punct(凶器-27, ”-28)
punct(选择-31, ,-29)
cc(选择-31, 还是-30)
ccomp(充当-23, 选择-31)
ccomp(选择-31, 完成-32)
nmod(异教徒-35, 挪威-33)
amod(异教徒-35, 狂热-34)
compound:nn(式-36, 异教徒-35)
nmod:assmod(复仇-39, 式-36)
case(式-36, 的-37)
compound:nn(复仇-39, 传奇-38)
dobj(完成-32, 复仇-39)
punct(映射-11, ?-40)
9. pkuseg
官方GitHub项目:lancopku/pkuseg-python: pkuseg多领域中文分词工具; The pkuseg toolkit for multi-domain Chinese word segmentation
特点是可以选择不同的领域。
安装:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pkuseg
使用默认配置进行分词:
sentence='“默然忍受命运的暴虐的毒箭,或是挺身反抗人世无涯的痛苦,通过斗争把他们清扫,这两种行为,究竟哪一种更高贵?”而在莎翁笔下,这样的挣扎困苦被映射到了极致——是坚持基督徒所信奉的不可充当“上帝的凶器”,还是选择完成挪威狂热异教徒式的传奇复仇?'
import pkuseg
seg = pkuseg.pkuseg() # 以默认配置加载模型
text = seg.cut(sentence) # 进行分词
print(text)
输出:['“', '默然', '忍受', '命运', '的', '暴虐', '的', '毒箭', ',', '或是', '挺身', '反抗', '人世无涯', '的', '痛苦', ',', '通过', '斗争', '把', '他们', '清扫', ',', '这', '两', '种', '行为', ',', '究竟', '哪', '一', '种', '更', '高贵', '?', '”', '而', '在', '莎翁', '笔下', ',', '这样', '的', '挣扎', '困苦', '被', '映射', '到', '了', '极致', '——', '是', '坚持', '基督徒', '所', '信奉', '的', '不可', '充当', '“', '上帝', '的', '凶器', '”', ',', '还是', '选择', '完成', '挪威', '狂热', '异教徒式', '的', '传奇', '复仇', '?']
其他分词、词性标注方式和参考文献可以直接参考官方GitHub项目README文件,不赘。
10. 哈工大语言云
我看还要注册调用API,所以还没试用:语言云(语言技术平台云 LTP-Cloud)
11. Lucene中文分词“庖丁解牛” Paoding Analysis
这其实是个Java工具……我看这是个很老的库了,感觉在性能上估计比不过之前那些比较新、用得比较广泛的包。也还没试过:Google Code Archive - Long-term storage for Google Code Project Hosting.
12. ik-analyzer
Java开源中文分词器,也非常古老,所以没试用过:Google Code Archive - Long-term storage for Google Code Project Hosting.
13. fnlp
FudanNLP/fnlp: 中文自然语言处理工具包 Toolkit for Chinese natural language processing
复旦去搞FastNLP了,不维护这个项目了,所以我也没试。但是FastNLP不支持直接分词……
14. ansj分词
NLPchina/ansj_seg: ansj分词.ict的真正java实现.分词效果速度都超过开源版的ict. 中文分词,人名识别,词性标注,用户自定义词典
这个要用maven,我觉得有些麻烦,还没试。
15. kcws
koth/kcws: Deep Learning Chinese Word Segment
字嵌入+Bi-LSTM+CRF(序列标注)
这个需要用bazel代码构建工具+TensorFlow 1,感觉麻烦,而且上次更新代码也已经有5年了,所以还没试。
16. MMSEG
这个也是2000年的工具了,就没试:MMSEG: A Word Identification System for Mandarin Chinese Text Based on Two Variants of the Maximum Matching Algorithm
17. 已确定不能用的分词工具
盘古分词:官网http://pangusegment.codeplex.com/已无法打开
http://www.coreseek.cn/opensource/网站无法打开
ZPar:官网http://faculty.sutd.edu.sg/~yue_zhang/doc/index.html已无法打开(但是GitHub项目主页frcchang/zpar: ZPar statistical parser. Universal language support (depending on the availability of training data), with language-specific features for Chinese and English. Currently support word segmentation, POS tagging, dependency and phrase-structure parsing.仍然可以打开,软件似乎还可以下载(但是文档都没有,给个软件有什么用啊)
18. 本文撰写过程中使用的其他参考资料
- 有哪些比较好的中文分词方案? - 知乎