图模型数据处理的综述

本文约4700字,建议阅读9分钟
本文从以数据为中心的角度对现有的图学习方法进行了系统的回顾和分类。前言
近期,非欧几里得领域的进步引发了人工智能界的关注,图数据在许多领域都有广泛应用。在过去的十年中,图模型的创新推动了相关研究的发展,但很少有研究关注图数据的内在方面。
以数据为中心的新兴人工智能强调利用好合适的数据以提高模型性能,而图的不规则性给图学习带来了问题,因此,我们需要了解如何修改图数据以充分发挥图模型的潜力,以及如何防止图模型受到有问题的图数据的影响。
本文从以数据为中心的角度对现有的图学习方法进行了系统的回顾和分类,旨在回答两个关键问题:(1)何时修改图数据(2)如何修改图数据以发掘各种图模型的潜力。
特别是,为了回答第一个问题,我们将图学习过程分为四个阶段:准备、预处理、训练和推理,如图1所示。我们讨论每个阶段对于图数据的重要性。
接下来,我们从结构角度进一步对现有方法进行分类,以解决第二个问题。具体来说,我们分别考虑如何处理图数据的拓扑、特征和标签。
最后,我们分析了现有图数据中的潜在问题,包括脆弱性、不公平性、选择偏差和异质性。我们进一步讨论如何以数据为中心的方式解决这些问题。

图1 以数据为中心的图学习流程
本文贡献如下:
新型分类法。我们通过图学习管道的各个阶段(包括预处理、训练和推理)对现有的以数据为中心的图学习方法进行分类。对于每个阶段,我们介绍了其目标和对数据为中心的图学习的重视程度。
多元视角。我们强调如何处理图数据中的不同数据结构,包括拓扑、特征和标签,以发掘给定图模型的潜力。
全面讨论。我们分析了有问题的图数据对图模型的潜在影响,并讨论了如何以数据为中心缓解这些问题。此外,我们提出了四个以数据为中心的图学习的未来可能方向,这可能有助于该领域的发展。
1、预处理阶段
在本节中,我们将讨论图数据预处理阶段以数据为中心的方法。具体来说,我们将现有方法分为两类:基于修改和基于分布的方法。第一类旨在通过修改图数据实例来提高图模型的性能。第二类侧重于帮助图模型捕获数据集的分布,同时保持图实例不变。此外,我们还考虑不同的数据结构,包括拓扑、特征和标签。相关方法如表1所示。
表1 以数据为中心的图学习的分类和代表作

1.1 图形简化 (Graph Reduction)
随着图规模的增加,时间和空间的计算消耗也会增加。因此,在不丢失太多有用信息的情况下,减少图的节点或边是一个很有价值的问题。图形简化可以加速模型训练并减少过拟合,并允许模型在更简单的硬件条件下进行训练。图形简化可以分为两类:边简化(Edge reduction)和节点简化(Node reduction)。边简化指的是图稀疏化,而节点简化包括图简化(Graph coarsening)和图凝结(Graph condensation)。
1.2 图形增强 (Graph Augmentation)
数据增强在深度学习中被认为是非常重要的。由于图数据的稀缺性和稀疏性相当严重,因此好的增强方法的重要性更加明显。与其他数据形式相比,图形增强直接操作图结构,是图数据增强中最具特色的类型。
1.3 特征增强 (Feature Augmentation)
特征增强通过修改或创建节点特征来提高模型性能,防止过拟合。对于已有特征的图,可进行特征损坏、洗牌、遮蔽、添加、重写、传播、混合等操作。对于无特征的节点,可通过deepwalk、node2vec、SDNE等方法生成特征。非标记图中,可通过GREET等方法进行无监督学习实现特征增强。特征增强方法多样,可针对具体问题进行定制。
1.4 位置编码 (Position Encoding)
消息传递神经网络(MPNN)受限于1-Weisfeiler-Lehman(WL)测试,无法区分同构图。为解决此问题,通过添加位置信息增强节点特征,称为位置编码,包括绝对位置编码(APE)和相对位置编码(RPE)。APE为每个节点分配一个位置表示,广泛使用的方法是图形拉普拉斯的固有向量。RPE编码两个节点之间的相对信息,分为一维相对位置编码(1D-RPE)和二维相对位置编码(2D-RPE)。1D-RPE将锚点与目标节点之间的距离作为位置表示,2D-RPE通常用作图结构的归纳偏差,广泛应用于图Transformer架构中。
1.5 标签混合 (Label Mixing)
标签混合的目标是创建泛化性更强的模型,防止过拟合。混合方法在图分类和节点分类任务中很重要。通过混合图嵌入或随机替换子图,可以增强模型面对图分类任务的能力。在节点分类任务中,混合邻居节点的标签或嵌入可以提高性能。知识蒸馏可以帮助修改标签,为未标记的节点生成伪标签。图2展示了三种理解图数据分布的方法:图课程学习、图采样和图生成。
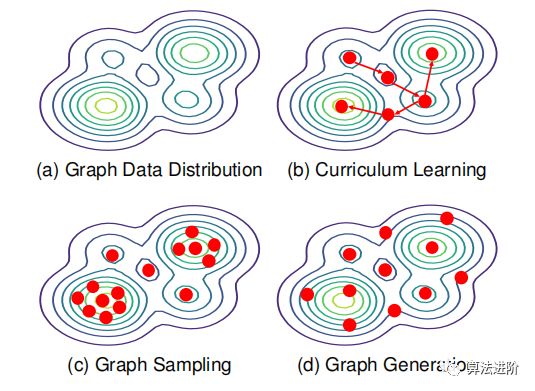
图2 图形数据分布及相关方法,其中红色圆圈表示数据样本
1.5.1 图的课程学习 (Graph Curriculum Learning)
课程学习(CL)是一种模仿人类学习过程的训练策略,通过从简单到复杂的样本进行学习,帮助模型更快收敛并提高泛化能力。图课程学习(Graph CL)是一种基于图的课程学习方法,主要用于图形神经网络的训练和优化。Graph CL方法可分为预定义的和自动的,预定义的Graph CL通过设计难度测量器和训练调度器来实现。设计难度测量器可以从数据或样本属性、数据关系等多个角度进行。训练调度程序可分为连续调度程序和离散调度程序。
1.5.2 图采样 (Graph Sampling)
图采样方法通过不同的策略对节点进行采样,只聚合部分节点的信息,从而加快模型收敛速度并减少内存开销。启发式采样方法可以划分为两个类别:随机采样和重要性采样。随机采样方法根据特定策略随机抽样要采样的子集的节点,如GraphSAGE、Cluster-GCN和Parallelize Graph Sampling。重要性抽样根据抽样策略对节点执行不同的抽样概率,如FastGCN、LADIES、GraphSAINT和PinSage。这些方法有助于克服邻域爆炸和内存溢出问题,提高模型性能。
1.5.3 图生成 (Graph Generation)
图生成器可以帮助解决图数据集太小的问题,通过生成额外的图数据。图生成方法分为自回归 (autoregressive) 和一步法 (one-shot)。自回归方法通过已生成的子图来创建新的节点和边,而一步法通过一次步骤生成整个邻接矩阵。One-shot方法比自回归方法更有效,但如何表示图形数据以更有效地建模仍然是一个挑战。从谱视角出发的方法可以更有效地捕获图的全局信息,而特定图的生成方法可以满足特定的应用场景。
2、训练阶段
这一部分介绍训练阶段中通过数据修改模块和消息传递模块相互协作来提高性能的图数据修改方法。具体介绍了三种模型与数据协作的训练模式,包括联合训练、自训练和双层训练。相关的方法如表1所示。
2.1 图自适应增强
传统的基于规则的增强方法可能不足以在下游任务中实现更强的鲁棒性和性能。相反,图自适应增强方法在训练阶段结合了增强程序。可分为三类:基于边、基于子图、自动增强。基于边的方法在某些损失函数的监督下操作邻接矩阵,基于子图的方法侧重于提取信息丰富的子图,而自动增强框架通过强化学习增强普通方法。
2.2 图自适应采样
自适应和可学习的采样算法,通过模型训练更新采样策略,实现最佳性能。这些算法通常对采样策略施加可学习的权重或概率,以自适应地调整采样。可学习的参数在正向传播中计算,并在反向传播中更新。这些方法分为两类:最小方差采样和最大性能采样。最小方差采样旨在分析或减少采样方差,以近似原始的全邻域聚合。最大性能采样直接优化模型性能,例如PASS使用梯度信息和任务性能损失来训练采样策略。
2.3 特征选择
“维数灾难”是指高维数据导致模型训练成本增加的问题。特征选择(FS)是一种解决“维数灾难”的方法,通过识别与标签高度相关的特征并优先考虑它们,降低计算成本并提高模型性能。在图学习中,通常采用嵌入式和包装器FS方法。嵌入式FS与模型的训练过程集成在一起,而包装器FS利用机器学习算法评估特征的重要性。基于Lasso的正则化方法和修改网络结构的方法都是嵌入式FS的常见策略。包装器FS方法不同于排名方法,引入了自适应邻居结构和更新的特征指示器,以强调自适应邻居结构,然后使用特征指示器对特征进行排序。
2.4 特征补全
数据质量在以数据为中心的学习任务中至关重要,但在训练场景中,数据往往不完整。图学习通过特征补全解决此问题,提取相邻节点属性以获得缺失节点属性的表示。传统方法用其他属性向量的总和或平均值替换缺失属性向量,忽略数据基本图结构。注意力算法、消息传递神经网络和集成方法等新方法被提出,以提高特征补全的准确性和多模态属性完成的能力。
2.5 图结构学习
图结构学习(GSL)是一种优化拓扑结构的方法,有助于缓解图模型鲁棒性受噪音影响的问题。联合训练和双层优化通过优化图结构和神经网络参数,提高模型在稀疏图上的去噪能力和对特征和语义之间复杂异构交互的理解。自我训练方法通过训练循环网络产生高质量的网络嵌入,进而训练图卷积网络以获取更好的网络嵌入。
2.6 图的自适应学习
自适应学习是一种半监督学习方法,用于图机器学习,通过调整实例难度和训练进度来更有效地利用图结构信息。具体方法包括DSP-GCN、CGCT和SPCGNN,它们通过调整标签增强策略来控制伪标签质量,减轻伪标签对训练数据增强的负面影响。自适应学习也可被视为一种自动课程学习方法,与其他类型的自动图课程学习方法类似。
2.7 主动学习
在图学习数据集中,存在大量未标记数据,主动学习选择最有价值的样本进行标记,以提高标签率和GNN模型性能。主动学习分为三类:成员查询合成、流式和基于池的。基于池的主动学习经常与GNN结合使用,可按查询方法分为基于不确定性的采样、基于多样性的采样和混合模型。
2.8 伪标签
伪标签是一种解决图神经网络中未标记数据和难以标记问题的方法。与主动学习不同,伪标签使用训练好的模型预测未标记数据,并参考相应指标进行标注。这些指标通常是预测样本标签的置信度。伪标签分为自训练模型和联合训练模型,它们主要在闭环迭代过程中是否依赖自身模型的估计和伪标签的预测。
3、推理阶段
推断阶段是将预训练图模型应用于下游任务的阶段,通过将下游任务重新定义为统一模板,实现高质量的知识转移和多任务适应。推理数据是在预训练模型推理阶段使用的图数据,调整推理数据作为提示有助于获得所需目标而不改变模型参数。提示学习方法在图的上下文中逐渐流行,分为两类:预提示和后提示,取决于任务特定提示是在消息传递模块之前或之后运行,如图1所示。
3.1 预提示
预提示方法通过修改输入图形数据以促进下游任务的适应。AAGOD利用提示学习在不改变GNN主干网络参数的情况下实现适应,通过将可学习的实例特定提示作为参数矩阵叠加在原始输入图的邻接矩阵上来修改拓扑结构。多任务提示方法通过构建诱导图并将节点级和边级任务重新定义为图级别任务,为输入图设计提示令牌并在消息传递之前通过加权所有提示令牌来修改每个节点的特征。
3.2 后提示
后提示方法通过在已传递消息的表示上运行任务特定的提示,以实现下游任务的适应。GraphPrompt和GPPT是图领域中提示学习的早期尝试,它们通过链接预测任务进行预训练,并利用可学习的提示来指导每个下游任务。GraphPrompt采用自监督链接预测任务,通过添加虚拟节点将节点分类任务和图分类任务统一为链接预测形式,消除了预训练任务与下游任务之间的差距。GPPT则主要关注节点分类任务,将特定任务的提示与节点表示拼接起来以指导适应。
4、图数据常见问题
本文讨论了在以数据为中心的方法中处理图数据问题的常见方法。首先,图数据中的脆弱性问题可以通过证书方法提高数据对扰动的鲁棒性。其次,不公平性问题可以通过公平性感知图增强和基于插值和纯化的图增强来解决。再次,选择性偏差可以通过稳定学习来缓解。最后,异构性问题可以通过图结构学习来减轻。
5、未来方向
标准化图形数据处理。现有图结构构建和数据处理方法受限于专家先验知识,导致图数据在不同领域间的可迁移性差。使用大型语言模型(LLMs)处理图数据,将节点特征统一在语言空间中,有助于在不同领域间转移知识。
提高通用图形数据质量。防止图模型受有问题的图数据影响至关重要。一种通用的方法是检测图数据缺陷并提高其质量。AAGOD通过自适应调整分布外图的边权值,将其变换成训练分布,以提高图模型性能。
图数据的持续学习。持续学习使深度学习模型能不断从数据流中学习新知识。图数据也可从图模型的预测中学习知识,优化自身。例如,图压缩方法利用图模型的梯度生成新图数据,可视为数据持续学习的特例。
少样本学习和上下文学习。“图基础模型”有望对图数据挖掘产生重大影响,关键在于赋予图模型在少样本和上下文上的学习能力。GraphPrompt首次尝试将图相关任务统一到链接预测框架中,并设计出任务相关的图提示。
参考资料:《 Data-centric Graph Learning: A Survey》
编辑:于腾凯
校对:林亦霖