c++的发展史、缺省参数、命名空间你了解吗?
1.c++的发展历史概述
1.1.什么是c++
C语言是结构化和模块化的语言,适合处理较小规模的程序。对于复杂的问题,规模较大的
程序,需要高度的抽象和建模时,C语言则不合适。为了解决软件危机, 20世纪80年代, 计算机界提出了OOP(object oriented programming:面向对象)思想,支持面向对象的程序设计语言应运而生。
1982年,Bjarne Stroustrup博士在C语言的基础上引入并扩充了面向对象的概念,发明了一
种新的程序语言。为了表达该语言与C语言的渊源关系,命名为C++。因此:C++是基于C语言而产生的,它既可以进行C语言的过程化程序设计,又可以进行以抽象数据类型为特点的基于对象的程序设计,还可以进行面向对象的程序设计。
1.2.c++的发展史
1979年,贝尔实验室的本贾尼等人试图分析unix内核的时候,试图将内核模块化,于是在C
语言的基础上进行扩展,增加了类的机制,完成了一个可以运行的预处理程序,称之为C with
classes。语言的发展就像是练功打怪升级一样,也是逐步递进,由浅入深的过程。我们先来看下C++的历史发展过程:
1979年:C语言的扩展:(本贾尼) Bjarne Stroustrup 在贝尔实验室工作时,开始着手开发一种能够支持面向对象编程的 C 语言扩展。这一过程中,他设计了 C++ 的最早版本。
1983年:正式命名为C++: Bjarne Stroustrup 在正式发布的 C++ 编程语言手册中首次使用了 "C++" 这个名称。这个名字表达了 C++ 是 C 语言的一个进化,并加上了一些面向对象编程的概念。
1985年:C++ 1.0 发布: 发布了 C++ 的第一个正式版本,包括类、继承、函数重载等基本的面向对象特性。
1989年:C++ 2.0 发布: 引入了多重继承、抽象类、静态成员函数等特性。
1990年:ANSI C++ 标准: 美国国家标准协会(ANSI)发布了第一个 C++ 标准,该标准在1998年被国际标准化组织(ISO)接受。
1998年:C++ 98 标准发布: ISO 发布了 C++ 的第一个国际标准,也称为 C++ 98。这个标准包括了许多新特性,如模板、命名空间、bool 类型等。
2003年:C++ 03 标准发布: 对 C++ 进行了一些小的修订,但主要是纠正和澄清了 C++ 98 中的一些问题。
2011年:C++ 11 标准发布: C++ 11 引入了许多新特性,包括自动类型推断、智能指针、lambda 表达式、范围循环等,使 C++ 编程更加现代化。
2014年:C++ 14 标准发布: 作为对 C++ 11 的小规模增强,引入了一些新特性,如二进制文字、泛型 Lambda 表达式等。
2017年:C++ 17 标准发布: 引入了一些新的语言特性和库特性,如结构化绑定、文件系统库、并发库等。
2020年:C++ 20 标准发布: C++ 20 是继 C++ 17 之后的新标准,引入了一系列新特性,如概念、范围语法、协程等。
1.3.c++的重要性
高性能: C++ 是一门编译型语言,直接翻译为机器代码,因此具有高性能。它允许对底层硬件进行更好的优化,使得 C++ 在系统编程、游戏开发等对性能要求较高的领域得到广泛应用。
面向对象编程: C++ 支持面向对象编程(OOP),使得代码能够更好地组织和管理。面向对象的特性,如封装、继承、多态等,使得代码更具可维护性和可扩展性。
跨平台性: C++ 的代码可移植性很强,可以在不同的操作系统和硬件平台上运行。这使得 C++ 成为开发跨平台应用和系统的重要选择。
系统级编程: C++ 被广泛用于系统级编程,如操作系统、驱动程序和嵌入式系统的开发。其直接的内存控制和硬件访问能力使其成为处理底层任务的理想语言。
游戏开发: 许多游戏引擎和游戏开发框架都是使用 C++ 编写的。C++ 提供了对图形和音频硬件的直接控制,以及对性能的高度优化,适合开发需要实时图形和音频处理的游戏应用。
大型软件项目: C++ 适用于大型软件项目的开发。其丰富的功能、模块化的设计和强大的标准模板库(STL)使得开发人员能够更容易地管理复杂的代码库。
嵌入式系统: C++ 被广泛用于嵌入式系统的开发,因为它提供了对硬件的底层访问、高效的代码执行以及对资源的有效管理。
科学计算和图形学: C++ 在科学计算和图形学领域得到广泛应用。它的性能和直接的硬件访问使其成为处理大规模计算和图形处理任务的理想选择。
补充
值得一提的是,c++兼容c语言,换句话来说,在.cpp文件中也可以写纯c语言的代码,这是没有问题的。但是如果想使用c++的一些库函数,就必须加入相应的头文件。
2.c++关键字
C语言32个关键字,而C++总计有63个关键字。

3.命名空间
命名空间(Namespace)是 C++ 中一种用于组织代码和防止命名冲突的机制。它允许开发者将代码元素(如变量、函数、类等)放置在一个特定的命名空间中,以避免与其他部分的代码发生冲突。通过使用命名空间,可以提高代码的可维护性和可读性。
观察以下代码:
#include
#include
int a = 10;
int a = 10;
// 当我们定义两个同名变量的时候,如果这两个变量在同一域中,c语言就会报错
int main()
{
printf("%d\n", a);
return 0;
} 现实中,由于一个项目往往是由多个人一起完成的,如果两个人没有沟通好命名规则,那么很容易使用到同名的变量或者是同名的函数,这样对于多人合作完成一个项目来说是不利地。所以呢,c++就引入了命名空间这一概念。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
使用命名空间就可以解决同名冲突问题:
int a = 10;
namespace myname {
int a = 10;
}
int main()
{
printf("%d\n", myname::a);//命名空间的使用规则,在"::"右边声明空间域,表明该变量在哪里去找
return 0;
}
3.1c/c++的变量搜索规则
一、对于c:
1、在局部域中搜索
2、局部域中没有就再去全局域中搜索
二、对于c++:
1、看变量左边有没有"::"。如果有,就去"::"左边的命名空间中去找,默认是全局域
例如 std::a,就是去名为std的空间里去找a。如果是::a,也就是"::"左边什么都不加,那就是去全局域中找a。
2、去局部域中搜索
3、去全局域中搜索
3.2命名空间定义
定义命名空间,需要使用到namespace关键字 ,后面加命名空间的名字,然后用一对{}括起来。{}中所有的变量或者函数都是该命名空间的成员。
namespace myname
{
// 命名空间中可以定义变量/函数/类型
int rand = 10;
int Add(int left, int right)
{
return left + right;
}
//注意:一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中
struct Node
{
struct Node* next;
int val;
};
}观察以下代码:
#include
#include
#include
namespace s1 {
int A(int a, int b)
{
return a + b;
}
}
namespace s2 {
int A(int a, int b) {
return a * b;
}
}
int main()
{
printf("%d\n", s1::A(1 , 2));
printf("%d\n", s2::A(2, 3));
return 0;
} 
我们可以看到,虽然s1和s2命名空间里面都有一个A(int,int)函数,但是各自实现的功能不一样,在s1命名空间里实现两数相加,在s2命名空间里面实现两数相乘。

3.3命名空间使用
命名空间的使用有三种方式:
1、加命名空间名称及作用域限定符
int main()
{
printf("%d\n", N::a);
return 0;
}2、使用using将命名空间中某个成员引入

using s1::a的意思是将命名空间
s1中的名称a引入到当前的作用域,使得在当前作用域中可以直接使用a而不需要通过命名空间限定符。

思考为什么输出a为10.
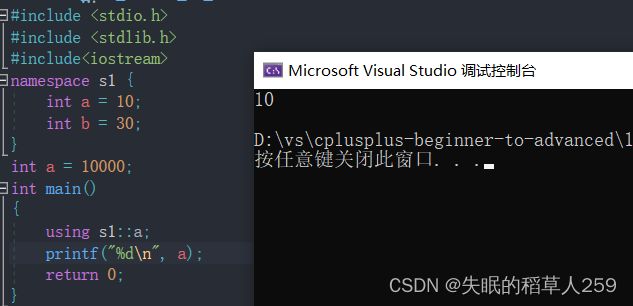
解释:
在这个例子中,
using s1::a;表示在main函数的作用域中引入了s1命名空间中的名称a。因此,我们可以直接使用a,而不需要写成s1::a.又根据变量名的搜索原则,先在局部域搜索,发现局部域有a,那就不用在全局域中去搜索。这也是为什么输出的是10而不是1000.
3、使用using namespace 命名空间名称 引入
 跟第二点差不多,using namespace s1的意思是将命名空间
跟第二点差不多,using namespace s1的意思是将命名空间 s1 中所有变量引入到当前的作用域。
思考:
以下代码为什么会报错
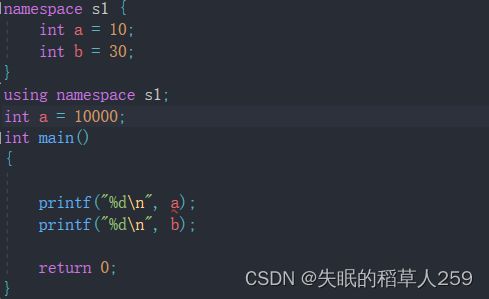
![]()
4.c++输入和输出
认识一门语言首先就要认识它的输入输出的方式。对于c++来说,它也有属于自己的输入输出方式。
#include//c++标准输入输出库
// std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中
using namespace std;
int main()
{
cout<<"Hello world!!!"< 说明:
1. 使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件
以及按命名空间使用方法使用std。
2. cout和cin是全局的流对象,endl是特殊的C++符号,表示换行输出,他们都包含在包含<
iostream >头文件中。
3. <<是流插入运算符,>>是流提取运算符。
4. 使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动控制格式。
C++的输入输出可以自动识别变量类型。
5.std命名空间
std是C++标准库中定义的一个命名空间。标准库是C++提供的一组通用的功能和工具,包括输入输出、容器、算法、字符串处理等。这些功能在std命名空间中组织,以便在用户的程序中使用。1. 在日常练习中,建议直接using namespace std即可,这样就很方便。
2. using namespace std展开,标准库就全部暴露出来了,如果我们定义跟库重名的类型/对
象/函数,就存在冲突问题。该问题在日常练习中很少出现,但是项目开发中代码较多、规模
大,就很容易出现。所以建议在项目开发中使用像std::cout这样使用时指定命名空间 +
using std::cout展开常用的库对象/类型等方式。这也是为什么我们看到有的人用std::cout输出而不是cout
6.缺省参数
6.1缺省参数概念
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。
举例
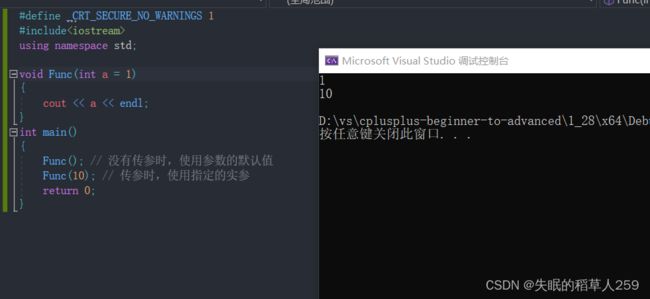
6.2缺省参数分类
缺省参数分为半缺省参数和全缺省参数。半缺省参数就是函数中参数的缺省数目小于参数个数,也就是说,不是所有的参数都有缺省值,我们把这种不完全缺省的函数叫做半缺省。相对应地,所有参数都有缺省值就叫做全缺省参数。
全缺省参数
void Func(int a = 1, int b = 1, int c = 1) {}//所有参数都设置缺省值,全缺省参数半缺省参数
void Func(int a , int b=1 , int c=1) {}//不是所有参数都设置缺省值,半缺省参数6.3注意
1.如果是半缺省参数,缺省值必须从右往左依次来给,不能间隔着给
2.缺省参数不能在函数声明和定义中同时出现
3.缺省值必须是常量或者是全局变量
4.c语言不支持(编译器不支持)
6.3.1为什么不能间隔着给呢?
原因是编译器需要能够准确地解析函数调用中各个参数的位置,而半缺省参数的提供是按照参数列表的最右端开始的。如果允许间隔着给参数赋值,编译器将难以判断参数的具体位置。为了避免这种歧义,C++ 编译器规定了半缺省参数必须按照声明的顺序提供。这样可以确保在函数调用时,参数的位置是明确的,编译器能够正确地解析。
举例

6.3.2 为什么缺省参数不能在定义和声明中同时出现?
避免二义性(Ambiguity): 如果函数的声明和定义中提供了不同的默认参数值,编译器无法确定在函数调用时应该选择哪个默认值。这会导致编译错误。



为了避免这些问题,C++ 编译器规定了默认参数只能在函数的声明或者定义中的其中一个地方提供。一般来说,建议在函数的声明中提供默认参数,而在函数的定义中不提供默认参数,这样可以使得函数的接口更清晰和一致。
6.3.3那么缺省参数应该在函数声明设置还是在函数定义设置呢?
观察以下代码


以上代码将函数定义和函数声明分别放在a.cpp中和test.h中,main函数放在main.cpp文件中调用Func函数。我们发现,函数声明没有给缺省参数,函数定义给了,运行Func()函数却报错了。
报错信息

函数调用参数太少。可是按照我们设置缺省值的目的,虽然没有传参,但不应该使用的是默认值嘛?
也就是说,此时设置的缺省值并没有用。为什么?
原因在于,我们的函数声明放在了.h的头文件里,而在编译器的预编译阶段会将头文件的内容展开。test.h文件展开时只是展开了Func函数的声明,该声明设置了三个整型参数且没有缺省值。当系统在调用Func函数时,发现此时的Func函数需要三个整型参数并且没有缺省,所以就会立即报错并不会调用a.cpp文件里的Func函数。这里关于编译器预编译以及编译的几个阶段有不了解或者是想要了解的同学可以看我之前写的博客。
c语言的程序环境和预处理(一眼丁真)_c语言环境打击那-CSDN博客
所以,缺省参数不能在函数声明和定义中同时出现,并且,应该在声明中设置缺省值而不是在定义中。
虽然可以在main函数中定义Func函数,但是为了更好的维护代码一般我们不会这么做。
