智能音频能力移动端落地实践


编者按
端上智能音频能力包括语音识别和声音事件检测等技术,此技术对互联网社交、游戏直播等场景非常重要。但端上智能音频技术也存在效果、性能、数据等方面问题。LiveVideoStack2023深圳站邀请到趣丸科技的马金龙老师讲解智能音频能力移动端落地实践,对这几个问题一一进行回答。
文/马金龙
整理/LiveVideoStack
大家好,我是马金龙,在多媒体算法开发方面有10年的经验,涉及音视频图像文本,音频前后端处理,弱网优化,音视频质量提升以及内容审核等。今天,跟大家分享智能音频能力移动端落地实践。

接下来,从四个方面进行介绍。第一部分介绍端上智能音频能力,第二部分介绍应用背景及面临问题,第三部分介绍端上智能音频实践之路,第四部分进行总结和展望。

接下来介绍端上智能音频能力,本节包含两项音频核心能力。

第一项是语音识别,即语音转化为文本,语音是万物互联的入口之一,如上右图清晰地展示了语音的重要性,此图也是通过AIGC用“语音是万物互联入口”prompt生成。

第二项是声音事件检测。大家可能从事SED方面可能比较少,更多的是从事音频前后端处理或者RTC等音频质量提升工作,在音频事件检测方面接触较少。在语聊房中,音频事件检测是很重要的一环,识别音频信号中正在发生的事情以及发生时间。

第二部分介绍应用背景及面临的问题。

上图展示的是我们公司的一些核心业务,包括游戏组局,音乐弹唱以及扩列交友等。左边是我们在生态中所要解决的问题,包括语音审核,语音内容理解,字幕生成以及主播行为检测等。
分别展开讲述这几个方面。
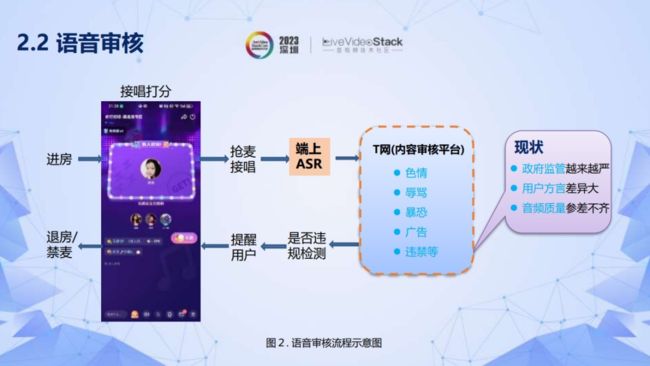
第一是语音审核方面,用户进房之后进行抢麦接唱,有些用户唱歌的内容需要进行审核。原来使用T网后端拉流进行审核,现在先用端上ASR,然后再进行T网审核。T网审核的标签再回溯到用户端,如有违规内容则提醒用户。这样就形成了端云结合方案,主要将拉流和高算力的服务移到端上,将NLP等留在后端,降低成本。这样需要考虑的问题或者面临的现状是:政府监管越来越严、用户方言差异大以及音频质量参差不齐。

第二是语音内容理解方面。以房间里多人聊天场景为例,此场景需内容理解,需要端上ASR。上图左边展示的理解用户画像,右边理解用户意图,例如打游戏组团开黑、唱歌打PK等等,得到相应标签后进行整合,做用户智能运营和房间精准推荐。

第三是字幕生成。保证多人聊天时,音转字的准确率。

第四是主播行为检测,目前也是端上形式。SED会对挂播、娇喘、炸麦、怒骂等进行检测,为了更好用户体验,进行了统计策略,聚合检测结果,再提醒用户,同时需要保证用户体验和检测准确率。

场景面临的问题有以下六个方面:一是业务场景多样,二是麦上环境复杂,三是地域差异带来的口音问题,四是有些场景需要高识别准确率,五是参差不齐的硬件设备,六是有些场景中用户要求响应时间短。

第三部分讲述智能音频在移动端的相关实践。

首先是端上智能音频的解决思路。我们面对的场景大多是多人麦上语音,面临多种端上采集,智能音频处理包括语音识别和声音事件检测。整个过程中业务要求模型准确、性能优、延时小。
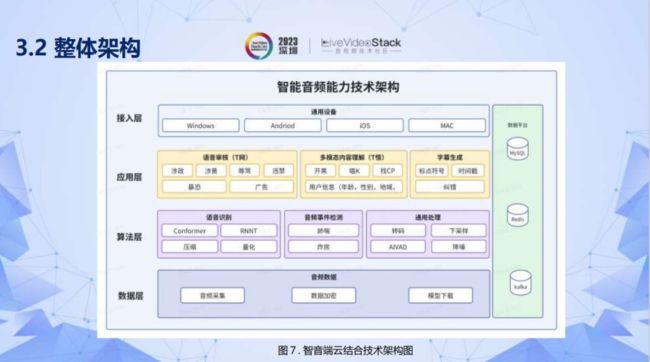
整体架构是一个端云结合的架构。重点讲解算法层内容,底层是数据层,涉及音频采集以及相关数据加密、模型下载。中间层是算法层,包括语音识别,音频事件检测以及通用处理。应用层的T网是语音审核,T悟是多模态内容理解平台,最后是端上字幕生成。右边是数据存储和交互平台。

接下来介绍端上ASR演进之路。随着项目应用先后依次探索Kaldi,Conformer,RNNT框架,目前T网运用Comformer框架,端上考虑解码实时性要求,选择RNNT框架。Kaldi的优点是开源工程完备,示例比较多,训练容易上手,缺点是对CTC支持不友好,端上效果相对较差。Conformer优点是框架轻量,支持流式和非流式解码,支持GPU/CPU部署,方便模型训练,缺点是模型大,端上性能消耗高,端上推理慢。RNNT优点是天然流式处理网络结构,低延迟,端上推理快,缺点是内存占用大,流式识别的准确率低,训练资源需求大。

端上ASR方案目标是实现移动端语音识别,适配不同口音、语速和环境噪声,同时满足实时性、高准确率和高性能要求。

接下来讲解一下ASR数据方面的部分工作。考虑用开源模型或者第三方平台标注数据,加上少量精标数据形成训练数据集,用于模型训练。模型训练完之后通过WER自错误率检核标注情况,一共四轮,结果显示数据量逐渐下降,WER也逐渐下降,说明方法有效,但不是精标结果,因此最终一个步骤需要有维度策略,计算PPL、SDK等文本相似度,剔除有问题部分,形成最终数据集。因此这是一个自回归数据清洗的方案。

模型蒸馏方案,结合模型微调和知识蒸馏方案,同时结合基于模型中间特征和模型结果分布,让Student模型的输出分布尽量接近Teacher模型的输出分布,在降低模型参数量前提下,进一步提升模型的识别效果。

模型蒸馏过程是多级模型蒸馏方案。与传统方案不同之处多了不同Loss,RNNT框架有预测网络和Encoder,在这个过程中特征级别用MSE Loss实现,在结果层面用KL Loss实现。这样构成了多级网络蒸馏方案。

接下来讲述模型优化。在RNNT模型训练中,引入FastEmit机制,抑制BLANK输出,进一步提高模型准确率。上图左边说明语音识别过程是一个时间和标签之间的矩阵,X轴主要是时间,每一帧作为一个节点,理想状态是每一个时间帧移动,对应一个标签输出,在这里做了正则损失优化,尽可能保证每一帧都输出标签结果,高效完成标签输出。

模型量化主要用float32->int8量化过程,量化结果上图所示,效果明显,模型大小从382MB下降到97.3MB。推理引擎方面,业界有很多类似推理引擎,综合考虑后采用NCNN深度学习框架,NCNN对RNNT的支持较好,首先对NCNN进行模型转换,再动态量化,最终形成端上的SDK。

这里展示最终模型效果,模型大小方面基本接近业务的需求20MB,内存占用45MB,CPU占用在某些大型游戏场景中还有问题,还需要进一步优化,WER方面尽管目前在一些场景满足预期但还需要进一步优化。

接下来讲述端上SED目标,对用户在房间内的声音行为进行实时检测,及时发现存在的违规行为并给予相应警告或者处罚。

SED算法原理,以上流程图展示比较清楚。对语音数据进行时频转换,对频域信号进行特征提取(CNN),然后用RNN和全连接层做置信度计算,根据置信度聚合结果得出相关片段总体分数,总体分数大于阈值被识别为对应标签。整体框架采用主干加分支形式,尽可能保证主干是重复运用的,主干网络提取总体特征,分支网络计算每个标签得分。

如图所示端上SED实现流程。基于原始模型先经过MNN转化,优化推理和内存分配,尽可能压缩内存,再量化模型,最终模型剪枝,压缩模型参数量,减少内存及计算资源占用,这是完整端上运行方案。

接下来,分别展开具体内容。关于MNN框架,现已开源,支持各种场景。其预推理过程可以通过以上图片展示,左边是日常对内存分配过程,对内存需求进行线性叠加,这样内存消耗会很高。右边是在MNN框架下做了内存预分配,试探一下在哪个阶段需要多少内存,对内存进行优化组合,避免内存不足的现象。右边是转化后对比情况。

端上SED模型量化也是float32->int8量化过程,显著降低了模型大小,在保证精度的前提下减少位宽。

第三步是模型稀疏化。模型剪枝进一步压缩模型内存和模型大小,涉及三点。第一,逐步微调权重稀疏化;第二对得分低的权重置零;第三对置零权重进行稀疏化。模型剪枝流程如图所示,模型训练时对模型进行微调,达成阈值后,微调结束,进行权重稀疏化。

模型稀疏化过程主要分两块。一是随机稀疏化,二是上图展示的快速稀疏化。随机稀疏化可以用6×6矩阵展开,整个矩阵是float32转为int8矩阵,如果随机就是蛇形排列,零不用选,最终有多少有效值就选中多少。快速稀疏化,以块形式进行,运算效率比随机高,又要保证不选中零,如右边图示,i是原来矩阵行,j是列,列不变情况下,将相关块拿出来变成k,这样形成完整矩阵。从原来6×6矩阵变成2×10矩阵,参数量明显下降。

最后为进一步提升算法效果减少对用户误打扰加入了统计策略,SED检测以片段进行,检测多个个片段一致认为是对应标签,那准确率已经很高了,最终业务精度达到99+%,但是CPU占用较高,在一些低端机型还存在计算卡的问题需要持续优化。

接下来简单总结技术分享的内容。

首先聚焦端上音频能力关注的效果、性能、数据问题,对这几个问题一一进行回答。数据方面提出了自回归数据清洗和标注过程,在没有人工精标前提下,减小模型WER值,加速模型训练,此外在不同应用场景选用不同数据集,增强模型泛化能力。效果方面,RNNT可以取得更好的识别效果,WER在端上接近11%,以及10%左右推理速度提升结合int8量化,可以取得30~50%的推理速度提升。性能方面,模型多级压缩蒸馏方案可以提升模型推理能力,降低模型大小,适合端上部署,但还要继续优化CPU和SED的性能。

端上技术展望就是不断做权衡的过程。
第一效果优化要权衡得失,模型效果和大小的权衡,推理速度和识别效果的权衡等。
第二不同业务场景和生态系统,不断提升数据和模型效率之间的权衡,可能以后会专注垂直领域模型。
第三生成式语音大模型可以加速模型迭代数据集的收集。第四结合MNN框架,端上智能音频能力可以加速推理。
本次分享内容到此结束,谢谢!