阿里2面:万亿级消息,如何做存储设计?
尼恩说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如阿里、滴滴、极兔、有赞、shein 希音、百度、网易的面试资格,小伙伴在面阿里时,遇到了一个存储设计相关的面试题:
存储架构,万亿条消息怎么设计?
小伙伴 没有回答好,导致面试挂了。来求助尼恩:该如何回答?
这里,尼恩借助一个著名的案例,Discord blog 的存储架构,帮助大家系统化、体系化的梳理。
按照此套路做答,向面试官展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。
然后实现”offer直提”、“offer自由”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典》V157版本PDF集群,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
特别提示:尼恩的3高架构宇宙,持续升级。
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请到文末公号【技术自由圈】取
文章目录
-
- 尼恩说在前面
- 系统有万亿条消息怎么存储?
- 什么是 Discord blog?
- Discord blog 万亿消息存储架构的技术演进
- Discord 第一阶段存储架构:MongoDB
-
- 来看看,什么是MongoDB?
- 存储引擎的底层数据结构
-
- 首先,看看存储引擎用到的常见数据结构
- LSM树基础知识
- LSM树与B树的差异
- 万亿级数据存储中间件的技术选型
-
- 一、HBase
- 二、Cassandra
- Cassandra vs HBase
- Discord 第二阶段存储架构:Cassandra
- Discord 第三阶段存储架构: C++ 版本的 Cassandra
- 万亿条消息怎么存储总结
- 说在最后
- 尼恩技术圣经系列PDF
系统有万亿条消息怎么存储?
本文参考 Discord blog,看看一个万亿条的存储架构,如何设计和演进。
本文的方案比较复杂,大家可以收藏起来,多看几遍。
什么是 Discord blog?
Discord 的消息存储演进给我们提供了真实案例参考。 Discord是一种广受欢迎的聊天和语音通信软件,主要用于游戏社区的交流。
Discord 提供了一系列功能,使用户能够创建服务器、加入频道、发送消息、进行语音通话以及分享多媒体内容。本文将详细介绍Discord的功能和编程相关的应用。
Discord的核心概念:Discord的核心概念包括服务器、频道、消息和用户。
-
服务器(Server):服务器是Discord的顶层组织单位,类似于一个虚拟社区或组织。用户可以创建自己的服务器,并邀请其他人加入。每个服务器都有自己的成员列表、频道和权限设置。
-
频道(Channel):频道是服务器内部的子单位,用于组织和分类不同类型的交流内容。服务器可以拥有多个频道,如文本频道(用于文字聊天)和语音频道(用于语音通话)等。
-
消息(Message):消息是在频道中发布的内容,可以是文字、链接、表情符号和多媒体文件等。用户可以发送消息、回复消息、引用消息以及分享其他内容。
-
用户(User):用户是Discord的注册成员,每个用户都有一个唯一的用户名和标识符。用户可以加入不同的服务器,并在这些服务器中加入频道、发送消息和进行语音通话。
本质上,Discord是一个 基于兴趣的、细分领域的 im 平台
Discord最初是为游戏玩家在群聊和交流而创建的。但自疫情爆发以来,许多企业、公司和初创公司发现,居家办公时使用Discord进行日常沟通非常便捷。
Discord不再是仅限于游戏玩家,平台建立了不同于其他任何社交空间的新空间,封闭又开放的传播方式,
Discord重点放在交流和兴趣,圈住了目标人群,是连接品牌和消费者的沃土,Discord 在国内是没办法自由注册的,所以我们还是得先准备好科技上网工具,要有稳定的浏览器环境,才可以成功注册。

Discord blog 万亿消息存储架构的技术演进
Discord 消万亿消息存储架构的演变过程:
MongoDB -> Cassandra -> ScyllaDB
2015 初用的单个副本集的 MongoDB,
2015 年底迁移到 Cassandra,
2022 年消息量达到了万亿的级别,他们将存储迁移到 ScyllaDB。
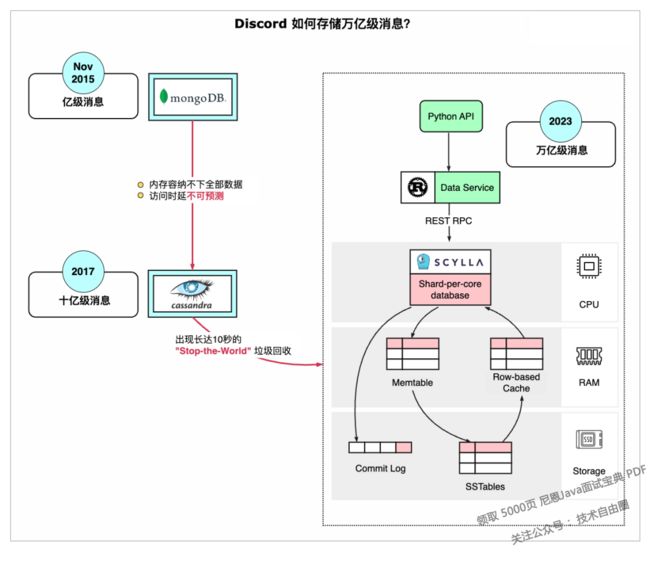
Discord 第一阶段存储架构:MongoDB
2015 年,Discord 的初始版本仅依赖于单一的 MongoDB。
消息规模在亿级别,MongoDB 已经存储了 1 亿条消息。
Discord 在早期版本中依赖单一 MongoDB 数据库存储消息,但随着消息量的迅速增长,内存空间不足和延迟问题日益凸显。
这促使 Discord 必须寻找一个新的数据库解决方案,以应对日益增长的数据量和性能挑战。
内存无法再容纳更多的数据和索引,导致延迟变得不可预测。
来看看,什么是MongoDB?
MongoDB是一个文档数据库,适用于处理半结构化和非结构化数据。它具有灵活的数据模型和易于使用的API,支持复杂的查询和分布式事务。MongoDB可以在多个节点上水平扩展,以处理大量的数据请求。
优点:
-
灵活的数据模型:MongoDB的文档模型支持灵活的数据结构,可以方便地处理半结构化和非结构化数据。
-
易于使用:MongoDB提供了易于使用的API和查询语言,开发人员可以快速上手。
-
可扩展性好:MongoDB可以在多个节点上水平扩展,以处理大量的数据请求。
缺点:
-
不适合处理关系型数据:MongoDB不适合处理关系型数据,例如传统的表格数据。
-
一致性难以保证:MongoDB在分布式环境下难以保证强一致性。
-
存储空间浪费:MongoDB存储数据时需要较多的空间,因为每个文档都需要包含其键和值。
大家都知道,mongdb是可以分布式水平扩展的,是支持万亿级的消息存储的。
那么,为啥,在Discord IM消息的存储场景,又不适合了呢?
Discord使用mongdb的问题: 内存空间不足,延迟太高。
本质上,这个和数据存储中间件的底层存储设施有关。
所以,作为架构师, 又得回到底层原理去啦。
存储引擎的底层数据结构
接下来,40岁老架构师尼恩,带大家梳理一下存储引擎的底层数据结构。
首先,看看存储引擎用到的常见数据结构
存储引擎要做的事情无外乎是将磁盘上的数据读到内存并返回给应用,或者将应用修改的数据由内存写到磁盘上。
目前大多数流行的存储引擎是基于B-Tree或LSM(Log Structured Merge) Tree这两种数据结构来设计的。
- B-Tree
像Oracle、SQL Server、DB2、MySQL (InnoDB)和PostgreSQL这些传统的关系数据库依赖的底层存储引擎是基于B-Tree开发的;
- LSM Tree
像Clickhouse、Cassandra、Elasticsearch (Lucene)、Google Bigtable、Apache HBase、LevelDB和RocksDB这些当前比较流行的NoSQL数据库存储引擎是基于LSM开发的。
两种结构,使用与不同场景,当写读比例很大的时候(写比读多),LSM树相比于B树有更好的性能
- 插件式替换模式:
大部分中间件,想办法兼容两个场景,所以,会采用了插件式的存储引擎架构,Server层和存储层进行解耦。
所以,大部分中间件,同时支持多种存储引擎。
比如,MySQL既可以支持B-Tree结构的InnoDB存储引擎,还可以支持LSM结构的RocksDB存储引擎。
比如,MongoDB采用了插件式存储引擎架构,底层的WiredTiger存储引擎还可以支持B-Tree和LSM两种结构组织数据,但MongoDB在使用WiredTiger作为存储引擎时,目前默认配置是使用了B-Tree结构。
LSM树基础知识
LSM树(Log-Structured MergeTree),日志结构合并树。
LSM树(Log-Structured MergeTree)存储引擎和B+树存储引擎一样,同样支持增、删、读、改、顺序扫描操作。而且通过批量存储技术规避磁盘随机写入问题。当然凡事有利有弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
LSM树,log-structured,日志结构的,日志是软件系统打出来的,就跟人写日记一样,一页一页往下写,而且系统写日志不会写错,所以不需要更改,只需要在后边追加就好了。各种数据库的写前日志也是追加型的,因此日志结构的基本就指代追加。注意他还是个 “Merge-tree”,也就是**“合并-树”,合并就是把多个合成一个**。
传统关系型数据库使用btree或一些变体作为存储结构,能高效进行查找。
但保存在磁盘中时它也有一个明显的缺陷,那就是逻辑上相离很近但物理却可能相隔很远,这就可能造成大量的磁盘随机读写。
随机读写比顺序读写慢很多,为了提升IO性能,我们需要一种能将随机操作变为顺序操作的机制,于是便有了LSM树。LSM树能让我们进行顺序写磁盘,从而大幅提升写操作,作为代价的是牺牲了一些读性能。
LSM树核心思想的核心就是放弃部分读能力,换取写入的最大化能力。
LSM Tree ,这个概念就是结构化合并树的意思,它的核心思路其实非常简单,就是假定内存足够大,因此不需要每次有数据更新就必须将数据写入到磁盘中,而可以先将最新的数据驻留在内存中,等到积累到足够多之后,再使用归并排序的方式将内存内的数据合并追加到磁盘队尾(因为所有待排序的树都是有序的,可以通过合并排序的方式快速合并到一起)。
日志结构的合并树(LSM-tree)是一种基于硬盘的数据结构,与B+tree相比,能显著地减少硬盘磁盘臂的开销,并能在较长的时间提供对文件的高速插入(删除)。
然而LSM-tree在某些情况下,特别是在查询需要快速响应时性能不佳。通常LSM-tree适用于索引插入比检索更频繁的应用系统。
LSM树与B树的差异
LSM树和B+树的差异主要在于读性能和写性能进行权衡。
在牺牲的同时寻找其余补救方案:
(a)LSM具有批量特性,存储延迟。当写读比例很大的时候(写比读多),LSM树相比于B树有更好的性能。因为随着insert操作,为了维护B+树结构,节点分裂。读磁盘的随机读写概率会变大,性能会逐渐减弱。
(b)B树的写入过程:对B树的写入过程是一次原位写入的过程,主要分为两个部分,首先是查找到对应的块的位置,然后将新数据写入到刚才查找到的数据块中,然后再查找到块所对应的磁盘物理位置,将数据写入去。当然,在内存比较充足的时候,因为B树的一部分可以被缓存在内存中,所以查找块的过程有一定概率可以在内存内完成,不过为了表述清晰,我们就假定内存很小,只够存一个B树块大小的数据吧。可以看到,在上面的模式中,需要两次随机寻道(一次查找,一次原位写),才能够完成一次数据的写入,代价还是很高的。
万亿级数据存储中间件的技术选型
了解了底层原理之后,尼恩给大家梳理一下,万亿级数据存储中间件的技术选型。
一、HBase
HBase是一个基于Hadoop的列存储数据库。它被广泛用于大数据环境下的实时读写操作。HBase使用Hadoop分布式文件系统(HDFS)作为存储后端,可以处理PB级别的数据。HBase使用Java编写,支持复杂的查询和分布式事务。HBase还提供了Hadoop生态系统中的许多工具和技术的集成,如Hive、Pig和Spark。
Hbase中有多个RegionServer的概念,RegionServer是 调度者,管理Regions。在Hbase中,RegionServer对应于集群中的一个节点,一个RegionServer负责管理多个Region。
一个Region代 表一张表的一部分数据,所以在Hbase中的一张表可能会需要很多个Region来存储其数据,
每个Region中的数据并不是杂乱无章 的,Hbase在管理Region的时候会给每个Region定义一个Rowkey的范围,落在特定范围内的数据将交给特定的Region,从而将负载分 摊到多个节点上,充分利用分布式的优点。
另外,Hbase会自动的调节Region处在的位置,如果一个RegionServer变得Hot(大量的请求落在这个Server管理的Region上),Hbase就会把Region移动到相对空闲的节点,依次保证集群环境被充分利用。
Region数据怎么持久化呢?
Hbase是基于Hadoop的项目,生产环境使用HDFS文件系统存储,数据是持久化在HDFS上的,对笨重的hadooop集群强依赖。
优点:
-
易于扩展:HBase是基于Hadoop的,它可以很容易地扩展到成百上千个节点。
-
数据可靠性高:HBase将数据复制到多个节点上,确保在节点失效时数据不会丢失。
-
处理大数据量:HBase可以处理大规模数据,它的可伸缩性非常好。
-
写入的性能高: 前面讲了LSM树,是使用写多读少场景。
缺点:
-
配置复杂:HBase需要配置很多参数才能运行,这会增加系统管理员的工作量。
-
查询速度慢:HBase的查询速度较慢,特别是在批量查询时。
-
开发难度大:HBase需要编写Java代码,这增加了开发的难度。
-
模式很重:HBase是基于Hadoop的,hadoop集群是一种重型的大数据离线处理基础设施, 如果没有大数据处理需求, 这个会造成资源的浪费,运维的浪费。
二、Cassandra
Cassandra是由Facebook开发的基于列存储的分布式数据库,基于Java开发。Cassandra是基于LSM架构的分布式数据库。
Cassandra支持水平扩展,可以在多个数据中心之间进行复制,提供高可用性和数据可靠性。它被广泛用于Web应用程序、消息传递、大数据和物联网等领域。
前面讲到,LSM查询性能还是比较慢的,于是需要再做些事情来提升,怎么做才好呢?
LSM Tree优化方式:
a、Bloom filter:就是个带随即概率的bitmap,可以快速的告诉你,某一个小的有序结构里有没有指定的那个数据的。于是就可以不用二分查找,而只需简单的计算几次就能知道数据是否在某个小集合里啦。效率得到了提升,但付出的是空间代价。
b、compact:小树合并为大树:因为小树他性能有问题,所以要有个进程不断地将小树合并到大树上,这样大部分的老数据查询也可以直接使用log2N的方式找到,不需要再进行(N/m)*log2n的查询了
Cassandra 也是做了很多优化,提升了查询的性能。
Cassandra 优点:
-
易于扩展:Cassandra可以很容易地扩展到成百上千个节点。
-
高可用性:Cassandra将数据复制到多个节点上,确保在节点失效时数据不会丢失。
-
查询速度快:Cassandra的查询速度非常快,特别是在大规模数据存储时。
-
写入的性能高: 前面讲了LSM树,是使用写多读少场景。
Cassandra 缺点:
-
数据一致性难以保证:Cassandra的数据一致性需要在读写之间进行权衡,难以保证强一致性。
-
复杂的数据模型:Cassandra的数据模型相对复杂,需要较长时间的学习和开发。
-
配置复杂:Cassandra需要配置很多参数才能运行,这会增加系统管理员的工作量。
Cassandra vs HBase
HBase是基于google bigtable的开源版本,而Cassandra是 Amazon Dynamo + Google BigTable的开源版本。
对比如下:
| HBase | Cassandra | |
|---|---|---|
| 语言 | Java | Java |
| 出发点 | BigTable | BigTable and Dynamo |
| License | Apache | Apache |
| Protocol | HTTP/REST (also Thrift) | Custom, binary (Thrift) |
| 数据分布 | 表划分为多个region存在不同region server上 | 改进的一致性哈希(虚拟节点) |
| 存储目标 | 大文件 | 小文件 |
| 一致性 | 强一致性 | 最终一致性,Quorum NRW策略 |
| 架构 | master/slave | p2p |
| 高可用性 | NameNode是HDFS的单点故障点 | P2P和去中心化设计,不会出现单点故障 |
| 伸缩性 | Region Server扩容,通过将自身发布到Master,Master均匀分布Region | 扩容需在Hash Ring上多个节点间调整数据分布 |
| 读写性能 | 数据读写定位可能要通过最多6次的网络RPC,性能较低。 | 数据读写定位非常快 |
| 数据冲突处理 | 乐观并发控制(optimistic concurrency control) | 向量时钟 |
| 临时故障处理 | Region Server宕机,重做HLog | 数据回传机制:某节点宕机,hash到该节点的新数据自动路由到下一节点做 hinted handoff,源节点恢复后,推送回源节点。 |
| 永久故障恢复 | Region Server恢复,master重新给其分配region | Merkle 哈希树,通过Gossip协议同步Merkle Tree,维护集群节点间的数据一致性 |
| 成员通信及错误检测 | Zookeeper | 基于Gossip |
| CAP | 1,强一致性,0数据丢失。2,可用性低。3,扩容方便。 | 1,弱一致性,数据可能丢失。2,可用性高。3,扩容方便。 |
国内很多人对于Cassandra很陌生。 有一句话说得很明白,亚洲用HBase,海外用Cassandra。
基于一个数据库排名我们可以看到,Cassandra在NOSQL数据库中排在第四位,已经远远甩开了HBase。
主要的原因,应该是 hadoop 重资源、重运维。 而 Cassandra 更轻量级,而且读写性能更高。

Discord 第二阶段存储架构:Cassandra
通过尼恩上面的对比分析,Discord是典型的写多读少场景,果断 抛弃了基于B+树的Mongdb,选择了LSM结构的Cassandra。
没有选择hbase,估摸着因为 hbase:
- 太重,依赖hadoop
- 读慢,读的性能没有Cassandra高
因此,Discord 第二阶段存储架构:选择了一个数据库,这时选择了 Cassandra。
2017 年,Discord 拥有 12 个 Cassandra 节点,存储了数十亿条消息。
2022 年初,Discord 拥有 177 个 Cassandra 节点,存储了数万亿条消息。
这一次,到了万亿级规模了
此时,延迟再次变得难以预测,维护的成本也变得过于昂贵。
造成这一问题有几个原因:
-
Cassandra 使用 LSM 树作为内部数据结构,读取操作比写入操作更为昂贵。在一台拥有数百名用户的服务器上,可能会出现很多并发读取,导致热点问题。
-
维护集群(如压缩 SSTables)会影响性能。
-
垃圾回收会导致明显的延迟
随着 Discord 用户基础的扩大和消息量的激增,Cassandra 的性能和维护成本问题变得日益突出。
这一问题促使 Discord 重新审视其存储策略,并最终导致了架构的演进,以适应不断变化的技术和业务需求。
通过不断优化和升级其存储系统,Discord 旨在确保用户能够享受到快速、可靠的消息服务,同时保持系统的可扩展性和成本效益。
Discord 第三阶段存储架构: C++ 版本的 Cassandra
这时,Discord 重新设计了消息存储的架构:采用基于 ScyllaDB 的存储。ScyllaDB 是用 C++ 编写的 Cassandra 兼容数据库。
ScyllaDB是KVM之父Avi Kivity带领团队用C++重写的Cassandra,官方称拥有比Cassandra多10x倍的吞吐量,并降低了延迟,是性能优异的NoSQL列存储数据库。
ScyllaDB可以算得上是数据库界的奇葩,它用c++改写了java版的Cassandra。
为什么奇葩呢?
因为大部分用其它语言改写的,都很难匹敌原系统。而ScyllaDB却相当成功,引起来了片欢呼。它的成功来源于JVM GC的无止尽的噩梦,另一部分来自于大名顶顶的KVM团队开发成员!
ScyllaDB是一个兼容Cassandra的NoSQL系统,它兼容Cassandra的数据模型和客户端协议,可以直接替换Cassandra系统。ScyllaDB实现性能优化到非常极致,它的性能是Cassandra的10多倍(3台ScyllaDB可以提供30台Cassandra集群的吞吐量,而且响应延时更低),非常牛。
ScyllaDB的优势在于:
-
用 C++ 而非 Java 编写,消除了垃圾回收暂停的干扰。
-
按核分片模型(Shard-per-Core model)提供更好的负载隔离,防止热分区在节点间产生级联延迟。
-
优化了反向查询性能,以满足 Discord 的需求。
-
节点减少到 72 个,同时将每个节点的磁盘空间增加到 9 TB。
为了进一步保护 ScyllaDB,Discord 针对数据服务还做了以下优化:
-
在 Rust 中构建中间数据服务,限制并发流量峰值。
-
数据服务位于应用程序接口和数据库之间,可聚合请求。
-
即使多个用户请求相同的数据,也只需查询一次数据库。
-
Rust 提供了快速、安全的并发功能,是这种工作负载的理想选择。
优化后的Discord 系统性能显著提高:
-
ScyllaDB 的 p99 读取延迟为 15 毫秒,而 Cassandra 为 40-125 毫秒。
-
ScyllaDB 的 p99 的写延迟为 5 毫秒,而 Cassandra 为 5-70 毫秒。
该系统可轻松应对世界杯流量高峰。
Discord 通过对消息存储架构的重新设计,成功应对了随着用户数量和消息量增长所带来的性能挑战。
通过采用 Rust 和 ScyllaDB,Discord 不仅提高了系统的性能,还确保了系统的可扩展性和稳定性。
这些优化措施使得 Discord 能够在保证服务质量的同时,有效应对高并发场景,展现了其在技术演进和创新能力上的领先地位。
万亿条消息怎么存储总结
Discord 的消息存储经历了从 MongoDB 到 Cassandra,再到 ScyllaDB 的演变过程。
随着系统规模的不断扩大和性能要求的提高,Discord 不断优化其存储架构,以应对热点问题、维护成本和延迟等挑战。通过采用 ScyllaDB 和 Rust 等技术,Discord 成功构建了一个高性能、可扩展的消息存储系统,能够满足数万亿条消息的存储需求。
通过此文,大家可以看出,如果大家做IM的消息存储架构,建议大家不要用mongdb,二是使用 ScyllaDB
所以,大家如果面试架构/或者大厂,需要回答IM存储架构的时候,参考本文去回答,一定会精彩连连,效果慢慢,offer直来。
当然,如果简历太差,还可以找尼恩来指导简历,尼恩用这种 高大上的技术,指导很多小伙伴拿到年薪100W offer。
说在最后
存储选型相关的面试题,是非常常见的面试题。
以上的内容,如果大家能对答如流,如数家珍,基本上 面试官会被你 震惊到、吸引到。最终,让面试官爱到 “不能自已、口水直流”。offer, 也就来了。
在面试之前,建议大家系统化的刷一波 5000页 《尼恩Java面试宝典PDF》,并且在刷题过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
另外,如果没有面试机会,可以找尼恩来帮扶、领路。尼恩指导了大量的就业困难的小伙伴上岸,前段时间帮助一个40岁+就业困难小伙伴,拿到了一个年薪100W的offer。
尼恩技术圣经系列PDF
- 《NIO圣经:一次穿透NIO、Selector、Epoll底层原理》
- 《Docker圣经:大白话说Docker底层原理,6W字实现Docker自由》
- 《K8S学习圣经:大白话说K8S底层原理,14W字实现K8S自由》
- 《SpringCloud Alibaba 学习圣经,10万字实现SpringCloud 自由》
- 《大数据HBase学习圣经:一本书实现HBase学习自由》
- 《大数据Flink学习圣经:一本书实现大数据Flink自由》
- 《响应式圣经:10W字,实现Spring响应式编程自由》
- 《Go学习圣经:Go语言实现高并发CRUD业务开发》
……完整版尼恩技术圣经PDF集群,请找尼恩领取
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓