详解SpringCloud微服务技术栈:深入ElasticSearch(2)——自动补全、拼音搜索
作者简介:一位大四、研0学生,正在努力准备大四暑假的实习
上期文章:详解SpringCloud微服务技术栈:深入ElasticSearch(1)——数据聚合
订阅专栏:微服务技术全家桶
希望文章对你们有所帮助
自动补全的功能其实在很多平台都有,包括了对拼音内容进行补全,例如输入“sj”可能会弹出“手机”。
实现这种功能需要安装拼音分词器,同时我们需要对其进行自定义,然后开始在之前的旅游类项目中增加搜索框自动补全的功能。
同样的,先把DSL语句掌握,再根据DSL语句去写java代码,去做实战,就会很容易。
深入ElasticSearch(2)——自动补全
- 安装拼音分词器
- 自定义分词器
- DSL实现自动补全查询
- 修改酒店索引库数据结构
- restAPI实现自动补全查询
- 实现搜索框自动补全
安装拼音分词器
安装方式和之前安装IK分词器是一样的,解压完上传到虚拟机中elasticsearch的plugin目录,再重启elasticsearch。
拼音分词器的压缩包可以从百度网盘中下载:
链接:https://pan.baidu.com/s/1qEwp3StkW7IJuhow-yAunA?pwd=fc9r
提取码:fc9r

终端输入docker restart es即可。
在dev tools中测试一下:
POST /_analyze
{
"text": ["如家酒店还不错"],
"analyzer": "pinyin"
}

自定义分词器
现在的拼音分词器还没有办法应用到生产环境中,上图中拼音分词器中分出了“rjjdhbc”这样的结果,同时它们还对全部单独的字进行了拼音,说明它根本不会分词。
还有一个问题,这里的分词器分出了拼音,这在真实应用场景下是锦上添花,但是偏偏没有了汉字,这显然是不行的。
elasticsearch中分词器的组成包含三部分:
character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword、ik_smart
tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等

所以,既然拼音分词器本身不会分词,那就先把文本交给ik分词器,分词后再转换为拼音。
要想自定义分词器,可以在创建索引库时,通过setting来配置自定义的analyzer(分词器):
PUT /test
{
"settings": {
"analysis": {
"analyzer": { # 自定义分词器
"tokenizer": "ik_max_word",
"filter": "pinyin"
}
}
}
}
虽然分好词了,但是拼音分词器对每个词,还是分成一个字一个字的来设置拼音,因此需要做进一步处理,即对拼音分词器进行自定义,不再使用默认的"pinyin":
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": { # 自定义tokenizer filter
"py": { # 过滤器名称
"type": "pinyin", # 类型是拼音分词器
"keep_full_pinyin": false, # 不再分为单个字
"keep_joined_full_pinyin": true, # 开启全拼
"keep_original": true # 保留中文
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
}
}
最终语句如下:

现在就可以进行测试,用自定义的分词器my_analyzer来做分词,注意需要指定索引库为/test,因为这个自定义分词器是在/test索引库下创建的,也只能在这里使用:
POST /test/_analyze
{
"text": ["如家酒店还不错"],
"analyzer": "my_analyzer"
}
但还是有一定的问题的,比如搜索狮子,结果中会包含虱子,也就是说把同音字都给搜进去了。
实际上,创建倒排索引时:

这时候再搜索的时候,就会因为拼音分词器的存在,shizi的词条对应了1和2的文档编号,就会产生混乱。
也就是说,拼音分词器适合在创建倒排索引的时候使用,但不能在搜索的时候使用。
因此,字段在创建倒排索引时应该用my_analyzer分词器,在搜索时应该用ik_smart分词器:
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}

总结:创建索引时用拼音分词器,搜索时用IK分词器。
DSL实现自动补全查询
elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
参与补全查询的字段必须是completion类型。
字段的内容一般是用来补全的多个词条形成的数组。

这样做,输入S会弹出Sony,输入W会弹出WH…,把整个成语拆开显然更为人性化。
查询语法如下:
GET /test/_search
{
"suggest": { # 自动补全
"title_suggest": { # 自动补全这个操作的名称
"text": "s", # 查询的前缀
"completion": { # 自动补全的类型,使用完全补全
"field": "title",
"skip_duplicates": true, # 跳过重复的
"size": 10
}
}
}
}
修改酒店索引库数据结构
接下来要实现hotel索引库的自动补全、拼音搜索功能。需要先将酒店的索引库数据结构修改,实现步骤:
1、修改hotel索引库结构,设置自定义拼音分词器
2、修改索引库的name、all字段,使用自定义分词器
3、索引库添加一个新字段suggestion,类型为completion,使用自定义的分词器
记得先删掉之前的hotel索引库,再创建实现上面3步:
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}
4、给HotelDoc类添加suggestion字段,内容包括brand、business

5、重新导入数据到hotel库,之前已经编写了这个测试类了:

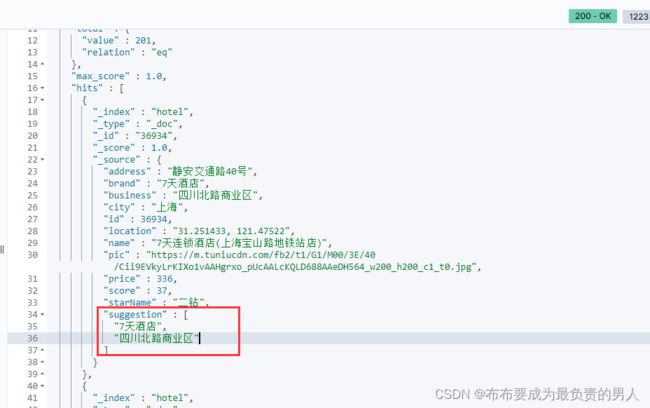
restAPI实现自动补全查询

编写测试类获取response并逐层解析结果:
@Test
void testSuggest() throws IOException {
SearchRequest request = new SearchRequest("hotel");
request.source().suggest(new SuggestBuilder().addSuggestion(
"suggestion",
SuggestBuilders
.completionSuggestion("suggestion")
.prefix("h")
.skipDuplicates(true)
.size(10)
));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
Suggest suggest = response.getSuggest();
CompletionSuggestion suggestion = suggest.getSuggestion("suggestion");
for (CompletionSuggestion.Entry.Option option : suggestion.getOptions()) {
String text = option.getText().toString();
System.out.println("text = " + text);
}
}

实现搜索框自动补全
查看前端页面,可以发现在输入框输入的时候,前端就会发起Ajax请求:


既然已经携带了输入的参数,要实现自动补全,需要在服务端编写接口,接收该请求,返回补全结果的集合,类型为List
HotelController:
@GetMapping("/suggestion")
public List<String> getSuggestion(@RequestParam("key") String prefix) {
return hotelService.getSuggestion(prefix);
}
实现类HotelService:
@Override
public List<String> getSuggestion(String prefix) {
try {
SearchRequest request = new SearchRequest("hotel");
request.source().suggest(new SuggestBuilder().addSuggestion(
"suggestions",
SuggestBuilders.completionSuggestion("suggestion")
.prefix(prefix)
.skipDuplicates(true)
.size(10)
));
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//解析结果
Suggest suggest = response.getSuggest();
CompletionSuggestion suggestion = suggest.getSuggestion("suggestions");
List<CompletionSuggestion.Entry.Option> options = suggestion.getOptions();
List<String> list = new ArrayList<>(options.size()); //准备要渲染回去的集合
for (CompletionSuggestion.Entry.Option option : options) {
String text = option.getText().toString();
list.add(text);
}
return list;
} catch (IOException e) {
throw new RuntimeException(e);
}
}


至此,自动补全功能正式实现。