
导读: 随着营销 3.0 时代的到来,企业愈发需要依托强大 CDP 能力解决其严重的数据孤岛问题,帮助企业加温线索、促活客户。但什么是 CDP 、好的 CDP 应该具备哪些关键特征?本文在回答此问题的同时,详细讲述了爱番番租户级实时 CDP 建设实践,既有先进架构目标下的组件选择,也有平台架构、核心模块关键实现的介绍。
全文 19135 字,预计阅读时间 26 分钟
一、CDP是什么
1.1 CDP由来
C DP(Customer Data Platform)是近些年时兴的一个概念。随着时代发展、大环境变化,企业在自有媒体增多的同时,客户管理、营销变难,数据孤岛问题也愈发严重,为了更好的营销客户 CDP 诞生了。纵向来看,CDP 出现之前主要经历了两个阶段 :
- CRM 时代,企业通过电话、短信、E-mail 与现有客户和潜在客户的互动,以及执行数据分析,从而帮助推动保留和销售;
- DMP 阶段,企业通过管理各大互联网平台进行广告投放和执行媒体宣传活动。
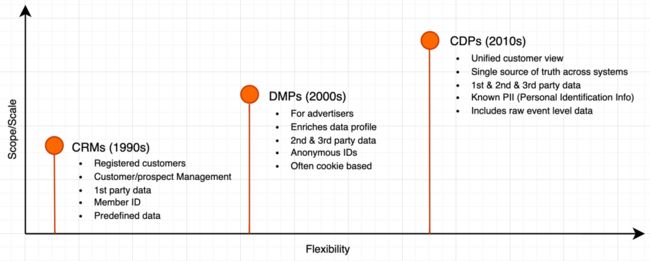
CRM、DMP、CDP 三个平台核心作用不同,但纵向来对比,更容易理解 CDP。三者之间在数据属性、数据存储、数据用途等方面都较大差异。有几个关键区别如下: 1.CRM vs CDP
- 客户管理:CRM 侧重于销售跟单,CDP 更加侧重于营销。
- 触点:CRM 的客户主要是电话、QQ、邮箱等,CDP 还包含租户的自有媒体关联的用户账号(例如企业自己的网站、App、公众号、小程序)。
-
数据类型:DMP是匿名数据为主,CDP 以实名数据为主。
-
数据存储:DMP数据只是短期存储,CDP 数据长期存储。
1.2 CDP定义
2013 年 MarTech 分析师 David Raab 首次提出 CDP 这个概念,后来其发起的 CDP Institute 给出权威定义:packaged software that creates a persistent, unified customer database that is accessible to other systems。 这里面主要包含三个层面:- Packaged Software :基于企业自身资源部署,使用统一软件包部署、升级平台,不做定制开发。
- Persistent , Unified Customer Database :抽取企业多类业务系统数据,基于数据某些标识形成客户的统一视图,长期存储,并且可以基于客户行为进行个性化营销。
- Accessible to Other Systems :企业可以使用 CDP 数据分析、管理客户,并且可以通过多种形式取走重组、加工的客户数据。
1.3 CDP分类
CDP 本身的 C(Customer)是指 all customer-related functions, not just marketing 。面向不同场景也对应不同类型的 CDP ,不同类别的 CDP 主要是功能范围不同,但是类别之间是递进关系。
主要分为四类:
- Data CDPs: 主要是客户数据管理,包括多源数据采集、身份识别,以及统一的客户存储、访问控制等。
- Analytics CDPs: 在包含 Data CDPs 相关功能的同时,还包括客户细分,有时也扩展到机器学习、预测建模、收入归因分析等。
- Campaign CDPs: 在包含 Analytics CDPs 相关功能的同时,还包括跨渠道的客户策略(Customer Treatments),比如个性化营销、内容推荐等实时交互动作。
- Delivery CDPs: 在包括 Campaign CDPs 相关功能的同时,还包括信息触达(Message Delivery),比如邮件、站点、APP、广告等。
二、挑战与目标
2.1 面临挑战
随着营销 3.0 时代的到来,以爱番番私域产品来说,主要是借助强大的 CDP 为企业提供线上、线下数据的打通管理的同时,企业可以使用精细化的客户分群,进行多场景的增育活动(比如自动化营销的手段,节假日促销通知,生日祝福短信,直播活动等等)。更重要的是,企业可以基于纯实时的用户行为进行更加个性、准确、及时的二次实时营销,帮助企业加温线索、促活客户,提升私域营销转化效果。那如何做好实时 CDP(Real-Time CDP,缩写为 RT-CDP )驱动上层营销业务,面临诸多挑战。 业务层面
爱番番的客户涉及多类行业,有的B2C的也有B2B2C的。相对与B2C,B2B2C的业务场景复杂度是指数级上升。在管理好B、C画像的同时,还要兼顾上层服务的逻辑里,比如身份融合策略、基于行为的圈选等。另外,在许多业务场景也存在很多业务边界不清晰的问题。
技术层面 1.全渠道实时精准识别要求高 当今时代一个客户行为跨源跨设备跨媒体,行为轨迹碎片化严重。如果企业想营销效果好,精准、实时识别客户、串联客户行为轨迹是重要前提。那如何在多源多身份中做到高性能的实时识别也是个很大挑战。 2.需要具有实时、低延迟处理海量数据的能力 现在客户可选择性多,意向度不明确,基于客户行为实时营销,以及基于客户反馈的实时二次交互是提高营销效果的关键,比如企业营销部门群发一个活动短信,客户点没点,点了有什么样进一步的动作,代表着客户不同的意向程度,企业营销、销售人员需要根据客户动作进行及时进一步的跟进。只有实时把握这些变化,才能更高效地促进营销活动的转化。如何实时处理海量数据驱动业务? 3.需要可扩展的架构 在多租户背景下,爱番番管理数千、万中小企业的海量数据。随着服务企业数量的不断增加,如何快速不断提升平台的服务能力,需要设计一个先进的技术架构。另外,如何做到高性能、低延迟、可伸缩、高容错,也是很大的技术挑战。 4.多租户特性、性能如何兼顾 爱番番私域产品是以 SaaS 服务形式服务于中小企业,那一个具备多租户特性的 CDP 是一个基本能力。虽然中小企业客户一般十万、百万量级不等,但随着企业进行的营销活动的累增,企业的数据体量也会线性增长。对于中大企业来说,其客户量级决定了其数据体量增长速度更快。另外,不同企业对于数据查询的维度各异很难做模型预热。在此前提下,如何兼顾可扩展性、服务性能是个难题。 5.多样部署扩展性CDP 目前主要以 SaaS 服务服务于中小企业,但不排除后续支持大客户 OP 部署 (On-Premise,本地化部署)的 需求,如何做好组件选型支持两类服务方式?
2.2 RT-CDP建设目标
2.2.1 关键业务能力
经过分析和业务抽象,我们觉得,一个真正好的RT-CDP需要做到如下几个关键特征:-
灵活的数据对接能力: 可以对接客户各种数据结构多类数据源的客户系统。另外,数据可以被随时访问。
-
同时支持 B2C和B2B两类数据模型: 面向不同的行业客户,用一套服务支撑。
-
统一的用户、企业画像: 包含属性、行为、标签(静态、动态(规则)标签、预测标签)、智能评分、偏好模型等等。
-
实时的全渠道身份识别、管理: 为了打破数据孤岛,打通多渠道身份,是提供统一用户的关键,也是为了进行跨渠道用户营销的前提。
-
强大的用户细分能力(用户分群): 企业可以根据用户属性特征、行为、身份、标签等进行多维度多窗口组合的用户划分,进行精准的用户营销。
-
用户的实时交互、激活: 面对用户习惯变化快,实时感知用户行为进行实时自动化营销能力尤为重要。
- 安全的用户数据管理: 数据长期、安全存储是数据管理平台的基本要求。
2.2.2 先进技术架构
明确平台业务目标的同时,一个先进的技术架构也是平台建设的目标。如何做到平台架构,我们有如下几个核心目标:
1.流数据驱动在传统数据库、数据处理上,还主要是『数据被动,查询主动』。数据在数据库中处于静止状态,直到用户发出查询请求。即使数据发生变化,也必须用户主动重新发出相同的查询以获得更新的结果。但现在数据量越来越大、数据变化及时感知要求越来越高,这种方法已无法满足我们与数据交互的整个范式。
现在系统架构设计如下图,更倾向于主动驱动其他系统的架构,比如领域事件驱动业务。数据处理亦是需要如此:『 数据主动、查询被动 』。
举个例子,企业想找到访问过企业小程序的用户进行发短信时,两种分别如何做?
-
传统方式:先将用户数据存入存储引擎,在企业发短信之前再将查询条件转换成sql,然后去海量数据中筛选符合条件的用户。
-
现代方式:在用户数据流入数据系统时,进行用户画像丰富,然后基于此用户画像进行符不符合企业查询条件的判断。它只是对单个用户数据的规则判断,而不是从海量数据筛选。
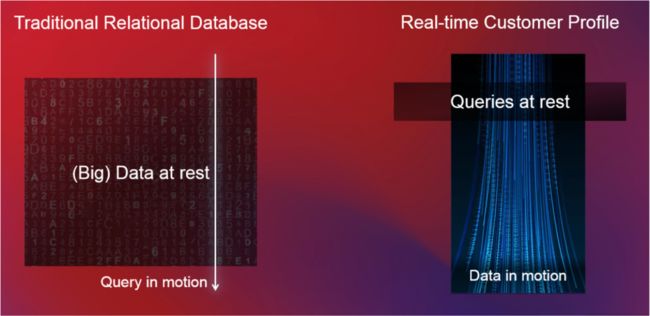 2.流计算处理 传统的数据处理更多是离线计算、批量计算。离线计算就是Data at rest,Query in motion;批量计算是将数据积累到一定程度,再基于特定逻辑进行加工处理。虽然两者在数据处理数据方式也有所不同,但是从根本上来说都是批量处理,天然也就有了延迟了。 流式计算则是彻底去掉批的概念,对流数据实时处理。也就是针对无界的、动态的数据进行持续计算,可以做到毫秒级延迟。在海量数据时代竞争激烈的今天,对企业洞察来说尤为如此,越快挖掘的数据业务价值越高。 3.一体化实践 【批流一体】 在大数据处理领域,存在两个典型的架构(Lamda、Kappa、Kappa+)。Lamda架构就是批计算、实时计算走两套计算架构,导致有时候有的相同逻辑开发两套代码,容易出现数据指标不一致,也带来了维护困难。Kappa、Kappa+架构是旨在简化分布式计算架构,以实时事件处理架构为核心兼顾批流两种场景。在大多数企业实际生产架构中还是两者混合较多,因为彻底的实时架构存在很多难点,比如数据存储、某些批计算更易处理的大窗口聚合计算等。 【统一编程】 在实际业务场景中,批、流处理依然是同时存在的。考虑到随着分布式数据处理计算发展,分布式处理框架也会推陈出新,虽然Apache Flink在批流一体支持上很活跃,但还不太成熟。另外,在各个公司多个计算框架并用的情况还是普遍存在。所以统一数据处理编程范式是一个重要的编程选择,可以提高编程灵活性,做到支持批、流场景数据处理作业开发,做到一套处理程序可以执行在任意的计算框架上,这样也利于后续平台切换更优秀的计算引擎。 4.可扩展为前提 这里主要是指架构的扩展性,一个具有扩展性的架构可以在稳定服务业务的同时合理控制资源成本,才能可持续支撑业务的快速发展。 【算存分离】 在如今海量数据的大数据时代,在不同场景下有时仅需要高处理能力,有时仅需要海量数据存储。传统存算一体架构,如果要满足两种场景,就需要高配置(多核、多内存、高性能本地盘等)服务节点,显然存在资源利用不合理,也会引发集群稳定性问题,比如节点过多导致数据分散,引发数据一致性降低等。算存分离的架构才符合分布式架构的思想,针对业务场景进行计算资源、存储资源的分别控制,实现资源合理分配。也利于集群数据一致性、可靠性、扩展性、稳定性等方面的能力保证。 【动态伸缩】 动态伸缩主要为了提高资源利用率,降低企业成本。实际业务中,有时候平台需要应对在业务平稳期短时间段内的流量(实时消息量)波峰波谷需要短期扩容,比如在各个重要节日大量企业同时需要做很多营销活动,导致消息量陡升;有时候随着爱番番服务的企业量不断增长,也会导致消息量线性增加,进而需要长期扩容。针对前者,一方面不好预见,另一方面也存在很高的运维成本。所以一个可以基于时间、负载等组合规则动态扩缩容的集群资源管理能力也是架构建设的重要考虑。
2.流计算处理 传统的数据处理更多是离线计算、批量计算。离线计算就是Data at rest,Query in motion;批量计算是将数据积累到一定程度,再基于特定逻辑进行加工处理。虽然两者在数据处理数据方式也有所不同,但是从根本上来说都是批量处理,天然也就有了延迟了。 流式计算则是彻底去掉批的概念,对流数据实时处理。也就是针对无界的、动态的数据进行持续计算,可以做到毫秒级延迟。在海量数据时代竞争激烈的今天,对企业洞察来说尤为如此,越快挖掘的数据业务价值越高。 3.一体化实践 【批流一体】 在大数据处理领域,存在两个典型的架构(Lamda、Kappa、Kappa+)。Lamda架构就是批计算、实时计算走两套计算架构,导致有时候有的相同逻辑开发两套代码,容易出现数据指标不一致,也带来了维护困难。Kappa、Kappa+架构是旨在简化分布式计算架构,以实时事件处理架构为核心兼顾批流两种场景。在大多数企业实际生产架构中还是两者混合较多,因为彻底的实时架构存在很多难点,比如数据存储、某些批计算更易处理的大窗口聚合计算等。 【统一编程】 在实际业务场景中,批、流处理依然是同时存在的。考虑到随着分布式数据处理计算发展,分布式处理框架也会推陈出新,虽然Apache Flink在批流一体支持上很活跃,但还不太成熟。另外,在各个公司多个计算框架并用的情况还是普遍存在。所以统一数据处理编程范式是一个重要的编程选择,可以提高编程灵活性,做到支持批、流场景数据处理作业开发,做到一套处理程序可以执行在任意的计算框架上,这样也利于后续平台切换更优秀的计算引擎。 4.可扩展为前提 这里主要是指架构的扩展性,一个具有扩展性的架构可以在稳定服务业务的同时合理控制资源成本,才能可持续支撑业务的快速发展。 【算存分离】 在如今海量数据的大数据时代,在不同场景下有时仅需要高处理能力,有时仅需要海量数据存储。传统存算一体架构,如果要满足两种场景,就需要高配置(多核、多内存、高性能本地盘等)服务节点,显然存在资源利用不合理,也会引发集群稳定性问题,比如节点过多导致数据分散,引发数据一致性降低等。算存分离的架构才符合分布式架构的思想,针对业务场景进行计算资源、存储资源的分别控制,实现资源合理分配。也利于集群数据一致性、可靠性、扩展性、稳定性等方面的能力保证。 【动态伸缩】 动态伸缩主要为了提高资源利用率,降低企业成本。实际业务中,有时候平台需要应对在业务平稳期短时间段内的流量(实时消息量)波峰波谷需要短期扩容,比如在各个重要节日大量企业同时需要做很多营销活动,导致消息量陡升;有时候随着爱番番服务的企业量不断增长,也会导致消息量线性增加,进而需要长期扩容。针对前者,一方面不好预见,另一方面也存在很高的运维成本。所以一个可以基于时间、负载等组合规则动态扩缩容的集群资源管理能力也是架构建设的重要考虑。 三、技术选型
没有万能的框架,只有合适的取舍。需要结合自身业务特点和架构目标进行合理选型。结合 RT-CDP 建设目标,我们做了如下几个核心场景的组件调研、确定。3.1 身份关系存储新尝试
在 CDP 中跨渠道身份打通(ID Mapping)是数据流渠道业务的核心,需要做到数据一致、实时、高性能。
传统的 ID Mapping 是怎么做?
1.使用关系型数据库存储身份关系一般是将身份关系存成多表、多行进行管理。该方案存在两个问题:-
数据高并发实时写入能力有限;
-
一般身份识别都需要多跳数据关系查询,关系型数据库要查出来期望数据就需要多次 Join,查询性能很低。
2.使用 Spark GraphX 进行定时计算一般是将用户行为存入 Graph 或者 Hive,使用 Spark 定时将用户行为中身份信息一次性加载到内存,然后使用 GraphX 根据交叉关系进行用户连通性计算。该方案也存在两个问题:
-
不实时。之前更多场景是离线聚合、定时对用户做动作;
- 随着数据量增加计算耗时会越来越高,数据结果延迟也会越来越高。
我们怎么做?
随着近几年图技术的发展,基于图解决业务问题的案例越来越多,开源图框架的产品能力、生态集成越来越完善,社区活跃度也越来越高。所以我们尝鲜基于图进行身份关系建模,借助图自然的多度查询能力进行实时身份判断、融合。图框架对比
大家也可以结合最新的图数据库的排名走势,进行重点调研。另外,关于主流图库对比案例也越来越多,可以自行参考。在分布式、开源图数据库中主要是 HugeGraph、DGraph 和 Nebula 。我们在生产环境主要使用了 DGraph 和 Nebula 。因为爱番番服务都是基于云原生建设,平台建设前期选择了 DGraph ,但后来发现水平扩展受限,不得不从 DGraph 迁移到 Nebula (关于DGraph到Nebula的迁移,坑还是挺多的,后续会有专门文章介绍,敬请期待)。
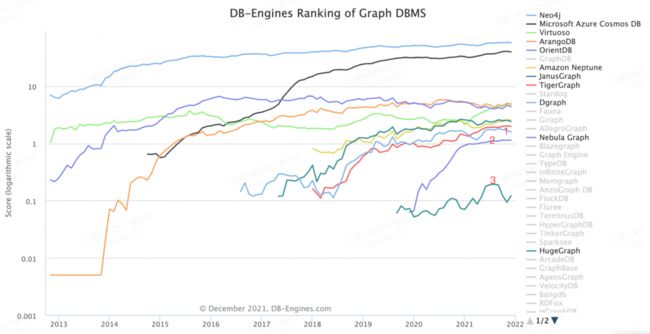
网上对 DGraph 和 Nebula 对比很少,这里简单说一下区别:
-
集群架构: DGraph 是算存一体的,其存储是 BadgerDB , go 实现的对外透明;Nebula 读写分离,但默认是 RocksDB存储 (除非基于源码更换存储引擎,也有公司在这么搞),存在读写放大问题;
- 数据切分: DGraph 是基于谓词切分(可以理解为点类型),容易出现数据热点,想支持多租户场景,就需要动态创建租户粒度谓词来让数据分布尽量均匀( DGraph 企业版也支持了多租户特性,但收费且依然没考虑热点问题);Nebula 基于边切分,基于 vid 进行 Parti tion ,不存在 热点问题,但图空间创建时需要预算好分区个数,不然不好修改分区数。
- 全文检索: DGraph支持;Nebula提供 listener 可以对接 ES。
- Query语法: DGraph 是自己的一个查询语法;Nebula 有自身查询语法之外,还支持了 Cypher 语法( Neo4j 的图形查询语言),更符合图逻辑表达。
- 事务支持: DGraph 基于 MVCC 支持事务;Nebula 不支持,其边的写事务也是最新版才支持的(2.6.1)。
- 同步写: DGraph、Nebula 均支持异步、同步写。
- 集群稳定性: DGraph 集群更稳定;Nebula 的稳定性还有待提升,存在特定运算下偶发 Crash 的情况。
- 生态集群: DGraph 在生态集成更成熟,比如与云原生的集成;Nebula 在生态集成范围上更多样一些,比如 nebula-flink-connector、nebula-spark-connector 等,但在各类集成的成熟度上还有待提升。
3.2 流式计算引擎选择
对于主流计算框架的对比,比如 Apache Flink、Blink、Spark Streaming、Storm,网上有很多资料,大家也请自行调研就好 ,比如如下,详见链接:https://blog.csdn.net/weixin_39478115/article/details/111316120
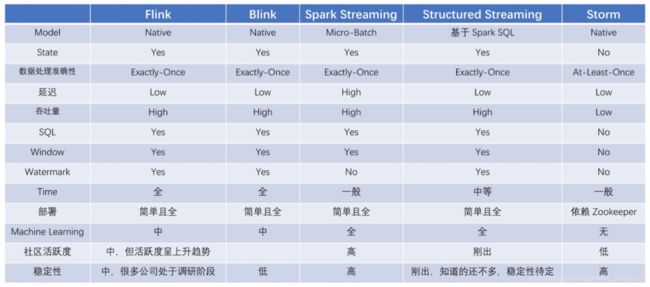
选择 Apache Flink 做为流批计算引擎 使用广泛的 Spark 还是以微批的方式进行流计算,而 Flink 是流的方式。Apache Flink 是近几年发展很快的一个用于分布式流、批处理数据处理的开源平台,它是最贴合 DataFlow 模型实现的分布式计算框架。基于流计算进行高性能计算,具有良好的容错、状态管理机制和高可用能力;其他组件与 Flink 的集成也越来越多、也日趋成熟,所以选择我们 Apache Flink 做为我们的流批计算引擎。 选择 Apache Beam 做为编程框架 分布式数据处理技术不断发展,优秀的分布式数据处理框架也会层出不穷。Apache Beam 是 Google 在 2016 年贡献给 Apache 基金会的孵化项目,它的目标是统一批处理和流处理的编程范式,做到企业开发的数据处理程序可以执行在任意的分布式计算引擎上。Beam 在统一编程范式的同时也提供了强大的扩展能力,对新版本计算框架的支持也很及时。所以我们选择 Apache Beam 做为我们的编程框架。

3.3 海量存储引擎取舍
在 Hadoop 生态系统存储组件中,一般用 HDFS 支持高吞吐的批处理场景、用 HBase 支持低延迟,有随机读写需求的场景,但很难只使用一种组件来做到这两方面能力。另外,如何做到流式计算下的数据实时更新,也影响存储组件的选择。Apache Kudu 是 Cloudera 开源的列式存储引擎,是一种典型的 HTAP (在线事务处理/在线分析处理混合模式)。在探索 HTAP 的方向上,TiDB、Oceanbase 均在此行列,只是大家起初侧重的场景不同而已,大家也可以对比一下。Apache Kudu 的愿景 是 fast analytics on fast and changing data 。 从 Apache Kudu 的定位,如下图可见一斑: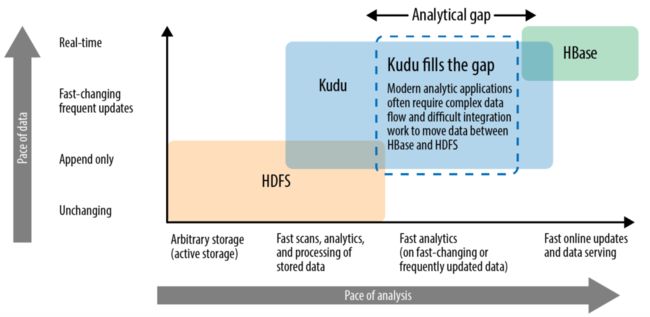
结合我们的平台建设理念,实时、高吞吐的数据存储、更新是核心目标,在数据复杂查询、数据应用的 QPS 上不高(因为核心的业务场景是基于实时流的实时客户处理),再加上 Cloudera Impala 无缝集成Kudu ,我们最终确定 Impala+Kudu 做为平台的数据存储、查询引擎。
分析增强:Apache Doris基于 Impala+Kudu 的选型,在支持 OP 部署时是完全没有问题的,因为各个企业的数据体量、数据查询 QPS 都有限,这样企业只需要很简单的架构就可以支持其数据管理需求,提高了平台稳定性、可靠性,同时也可以降低企业运维、资源成本。但由于 Impala并发能力有限(当然在 Impala 4.0 开始引入多线程,并发处理能力提升不少),爱番番的私域服务目前还是以 Saas 服务为重,想在 Saas 场景下做到高并发下的毫秒级数据分析,这种架构性能很难达标,所以我们在分析场景引入了分析引擎 Apache Doris。Apache Doris 是基于 MPP 架构的 OLAP 引擎,相对于 Druid、ClickHouse 等开源分析引擎,Apache Doris 具有如下特点:
-
支持多种数据模型,包括聚合模型、Uniq 模型、Duplicate 模型;
-
支持 Rollup、物化视图;
-
在单表、多表上的查询性能都表现很好;
-
支持 MySQL 协议接入、学习成本低;
- 无需集成 Hadoop 生态,集群运维成本也低很多。
3.4 规则引擎调研
实时规则引擎主要用于客户分群,结合美团的规则对比,几个引擎(当然还有一些其他的 URule、Easy Rules 等)特点如下:

四、平台架构
4.1 整体架构
在爱番番私域产品中,主要分为两部分:RT-CDP 和 MA,两者叠加近似等同于 Deliver CDP 所包含的功能范围。本文所讲的 RT-CDP 所包含的功能范围等同于 Analytics CDPs ,简单来讲,主要就是客户数据管理、数据分析洞察。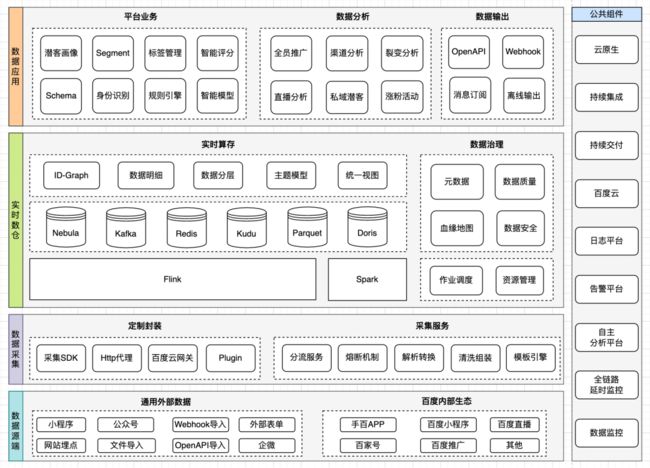
RT-CDP 也是就两部分功能进行拆分,主要包含五部分:数据源、数据采集、实时数仓,数据应用和公共组件,除公共组件部分是横向支撑外,其他四部分就是标准的数据对接到数据应用的四个阶段:
- 数据源: 这里的数据源不仅包含客户私有数据,也包括在各个生态上的自有媒体数据,比如微信公众号、微信小程序、企微线索、百度小程序、抖音企业号、第三方生态行为数据等。
- 数据采集: 大多中小企业没有研发能力或者很薄弱,如何帮助快速将自有系统对接到爱番番 RT-CDP 是这层需要重点考虑的,为此我们封装了通用的采集 SDK 来简化企业的数据采集成本,并且兼容 uni-app 等优秀前端开发框架。另外,由于数据源多种多样、数据结构不一,为了简化不断接入的新数据源,我们建设了统一的采集服务,负责管理不断新增的数据通道,以及数据加解密、清洗、数据转换等数据加工,这个服务主要是为了提供灵活的数据接入能力,来降低数据对接成本。
- 实时算存: 在采集到数据后就是进行跨渠道数据身份识别,然后转换成结构化的客户统一画像。就数据管理来说,这层也包含企业接入到 CDP 中的碎片客户数据,为了后续企业客户分析。经过这层处理,会形成跨渠道的客户身份关系图、统一画像,然后再通过统一视图为上层数据接口。另外,就是数仓常规的数据质量、资源管理、作业管理、数据安全等功能。
- 数据应用: 这层主要是为企业提供客户管理、分析洞察等产品功能,比如丰富的潜客画像、规则自由组合的客户分群和灵活的客户分析等。也提供了多种数据输出方式,方便各个其他系统使用。
- 公共组件: RT-CDP 服务依托爱番番先进的基础设施,基于云原生理念管理服务,也借助爱番番强大的日志平台、链路追踪进行服务运维、监控。另外,也基于完备的 CICD 能力进行 CDP 能力的快速迭代,从开发到部署都是在敏捷机制下,持续集成、持续交付。
4.2 核心模块
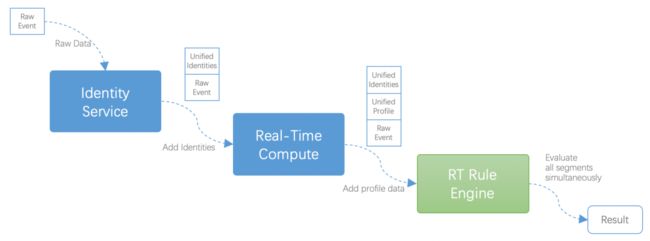
简单来说,RT-CDP 实现的功能就是多渠道数据的实时、定时采集,然后经过数据中身份的识别 Identity 服务,再进行数据处理、数据进行数据映射、加工(比如维度 Join、数据聚合、数据分层等),然后进行结构化持久化,最后对外实时输出。
RT-CDP 主要划分为六大模块:采集服务、Connectors、Identity Service、实时计算、统一画像和实时规则引擎。上图就是从数据交互形式和数据流向的角度描绘了 RT-CDP 核心模块之间的交互。从左到右是数据的主流向,代表了数据进入平台到数据输出到和平台交互的外部系统;中间上侧是实时计算和 Identity Service 、实时规则引擎和统一画像的双向数据交互。 下面结合数据处理阶段进行各个核心模块的功能说明: 1.数据源&采集
从数据源和 RT-CDP 数据交互方式上,主要分为实时流入和批次拉取。针对两种场景,我们抽象了两个模块:实时采集服务和 Connectors。
-
实时采集服务: 该模块主要是对接企业已有的自有媒体数据源,爱番番业务系统领域事件以及爱番番合作的第三方平台。这层主要存在不同媒体平台API协议、场景化行为串联时的业务参数填充、用户事件不断增加等问题,我们在该模块抽象了数据 Processor& 自定义 Processor Plugin 等来减少新场景的人工干预。
-
Connectors : 该模块主要是对接企业的自有业务系统的数据源,比如 MySQL、Oracle、PG 等业务库,这部分不需要实时接入,只需按批次定时调度即可。这里需要解决的主要是多不同数据源类型的支持,为此我们也抽象了 Connector 和扩展能力,以及通用的调度能力来支持。针对两种场景下,存在同一个问题:如何应对多样数据结构的数据快读快速接入?为此,我们抽象了数据定义模型(Schema),后面会详细介绍。
2.数据处理
- Identity Service: 该模块提供跨渠道的客户识别能力,是一种精准化的 ID Mapping,用于实时打通进入 RT-CDP 的客户数据。该服务持久化了客户身份相关关系图放在 Nebula 中,会根据实时数据、身份融合策略进行实时、同步更新Nebula,然后将识别结果填充到实时消息。进入 CDP 数据只有经过 Identity Service 识别后才继续往后走,它决定了营销旅程的客户交互是否符合预期,也决定了 RT-CDP 的吞吐上限。
- 实时计算: 该模块包含了所有数据处理、加工、分发等批流作业。目前抽象了基于 Apache Beam 的作业开发框架,尝试批流都在 Flink 上做,但有些运维 Job 还用了 Spark ,会逐渐去除。
- 统一画像: 该模块主要是持久化海量的潜客画像,对于热数据存储在 Kudu 中,对于温、冷的时序数据定时转存到 Parquet 中。潜客画像包括客户属性、行为、标签、所属客群、以及聚合的客户扩展数据等。虽然标签、客群是单独存在的聚合根,但是在存储层面是一致的存储机制。另外,标准 RT-CDP 还应该管理客户碎片数据,所以统一画像和数据湖数据如何交互是后续建设的重点。
- 统一查询服务: 在 RT-CDP 中,客户数据分散在图数据库、Kudu、增强的分析引擎和数据湖,但对用户来说只有属性、行为、标签、客群等业务对象,如何支持产品上透明使用?我们通过统一视图、跨源查询建设了此统一查询服务,该服务支持了Impala、Doris、MySQL、Presto、ES 等查询存储引擎以及 API 的跨源访问。
- 实时规则引擎: 该模块主要是基于 Flink 提供实时规则判断,来支持圈群、基于规则的静态打标、规则标签等业务场景。
4.3 关键实现
4.3.1 数据定义模型
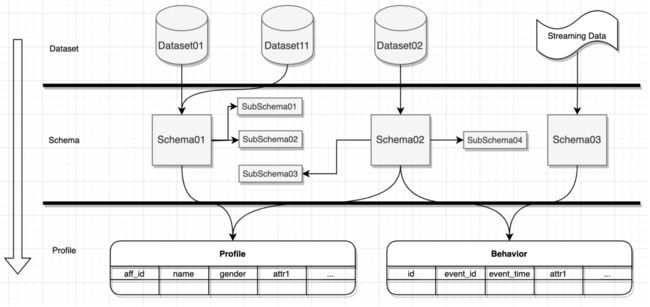
为什么需要Schema? 前面提到企业的多个渠道的数据特征结构各异。再加上不同租户业务特点不同,企业需要数据自定义的扩展性。RT-CDP 为了两类问题需要具备数据结构灵活定义的能力来对接企业数据。 另外,RT-CDP 本身管理两类数据:碎片化客户数据和用户统一画像。对于前者来说,不需要关系数据内容本身,利用数据湖等技术即可为企业提供数据存储、查询、分析能力,是偏 Schemaless 的数据管理;对于后者来说,更多需要按不同维度组合查询、圈群、分析,本身需要结构化的数据管理。后者能否通过 Schemaless 的方式提供服务呢?罗列增删改查的场景,反证一下局限明显。 Schema是什么? Schema 是一个数据结构的描述,Schema 可以相互引用,可以对数据中字段以及字段类型、值进行约束,也可以自定义字段。企业可以用一个统一的规范快速接入、灵活管理自己的数据,比如企业可以根据自己的行业特性,抽象不同的业务实体、属性,再给不同的业务实体定义不同的 Schema 。企业可以对业务实体有交集的信息抽离新 Schema ,然后多个 Schema 引用这个新 Schema ;也可以对每个 Schema 自定义自己的业务字段。企业只需要按相应的 Schema 结构接入数据,就可以按特定的标准使用这些数据。 从这几个实体来说明 Schema 的特点,如下图:
- Field: 字段是最基本的数据单元,是组成 Schema 的最小粒度元素。
- Schema: 是一组字段、Schema 的集合,它本身可以包含多个字段(Field),字段可以自定义,比如字段名、类型、值列表等;也可以引用一个或多个其他 Schema,引用时也可以以数组的形式承载,比如一个 Schema 里面可以包含多个 Identity 结构的数据。
- Behavior : 是潜客或企业的不同行为,本身也是通过 Schema 承载,不同的 Behavior 也可以自定义其特有的 Field。

在上图所示,爱番番 RT-CDP 在进行行业抽象后,已经内置了很多行业通用的 Schema ,包括常见的 Identity、Profile、Behavior 等多类 Schema。在爱番番 RT-CDP 管理的统一潜客画像中,Identity、Profile、Tag、Segment 等都业务聚合根。为了支持好 B、C 两种数据模型还有一些B粒度聚合根存在。 Schema如何简化数据接入? 这里需要先说一个 Dataset 的概念。Dataset 是通过 Schema 定义结构的一个数据集,企业对不同的数据源定义成不同的数据集。在数据源管理时,企业可以根据不同的数据集结构化导入的数据,一个数据集可以对应多个数据源,也可以对应一个数据源中的一类数据,一般后者使用较多。另外,一个数据集也可以包含多批次的数据,也就是企业可以周期性的按批次导入同一数据集数据。在数据接入时,如下图,针对不同的 Dataset ,企业可以绑定不同的 Schema,每个 Schema 可以引用、复用其他子 Schema ,然后经过 RT-CDP 的 Schema 解析,自动将数据持久化到存储引擎,根据数据的定义不同,会持久化到不同数据表中。对应实时的客户行为也是通过定义不同的 Schema 来定义数据结构,然后进行持续的数据接入。
扩展1:借助字段映射解决多租户无限扩列问题
存在的问题是什么 爱番番 RT-CDP 是一个支持多租户的平台,但在多租户下,每个企业都有自己的业务数据,一般中小企业可能有几百上千个潜客的数据字段,对于 KA 字段量更多。CDP 做为 Saas 服务,如何在一个模型中支持如此多的字段存储、分析。一般可以无限扩列的引擎可以直接按租户+字段的方式打平。为了进行结构化实时存储,爱番番 CDP 选择了Kudu,Kudu 官方建议单表不超过 300 列,最多也就支持上千列,那刚才的方式无法解决。 我们的解决方案是什么? 我们在租户隔离的前提下,采用字段复用的方式解决该问题。在介绍 Schema 模型时图里也有体现,在实际的 Profile、Event 表里都是 attr 字段。关键点就是:-
事实表只做无业务含义的字段;
- 在数据接入、查询时通过业务字段(逻辑字段)和事实字段的映射关系进行数据转换后与前端、租户交互。
4.3.2 Identity Service
这个服务也可以称之为 ID Mapping 。但相对于传统的 ID Mapping 来说,因为业务场景的不同,功能侧重也有所不同。传统意义的 ID Mapping 更多是广告场景的匿名数据的,基于复杂模型的离线和预测识别;CDP 中的 ID Mapping 是基于更精准的数据身份标识,进行更精准打通,更加要求打通率和实时性。
为此,我们设计了支持 B2B2C、B2C两 种业务的身份关系模型。在标准化租户数据接入后,基于不断接入的数据新增持续的身份关系图谱裂变。在功能层面,我们支持自定义身份类型以及身份权重,也支持针对不同身份租户自定义身份融合动作。另外,根据我们对行业分析,内置了常见的身份及融合策略,方便租户直接使用。
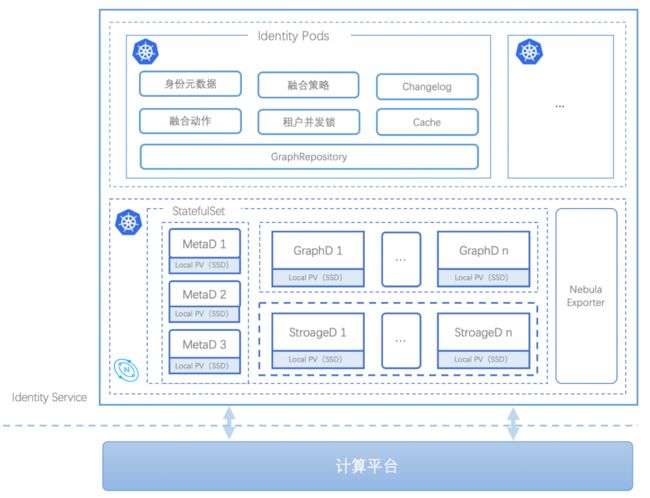
从架构层面,Identity Service(ID Mapping) 基于云原生+Nebula Graph 搭建,做到了租户数据隔离、实时读写、高性能读写以及水平扩缩容。 1.云原生+Nebula Graph 将 Nebula Graph 部署到 K8s 下,降低运维成本。我们主要是:
-
使用 Nebula Operator 自动化运维我们 K8s 下的 Nebula 集群;
-
使用 Statefulset 管理 Nebula 相关有状态的节点 Pod;
-
每个节点都是使用本地 SSD 盘来保证图存储服务性能。
-
设计好数据模型,尽量减少Nebula内部IO次数;
-
合理利用Nebula语法,避免Graphd多余内存操作;
-
查询上,尽量减少深度查询;更新上,控制好写粒度、降低无事务对业务的影响。
扩展1:如何解决未登录时潜客打通问题
针对一个人多设备场景,单设备被多人使用的场景,我们采用离线矫正的方式进行打通。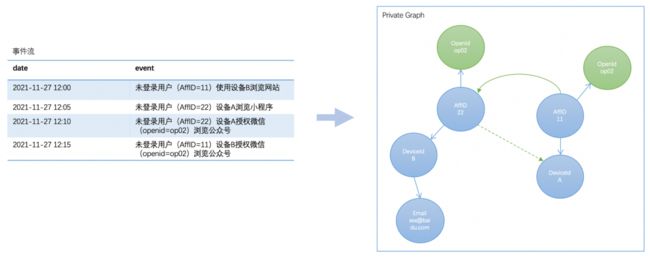
4.3.3 实时存算
4.3.3.1 流计算
爱番番 RT-CDP 核心能力都是依托 Apache Flink+Kafka 实现。在实时流之上进行的流计算,做到毫秒的数据延迟。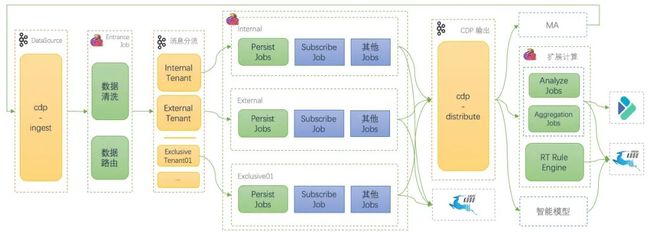
核心数据流如上图,简化后主要包含如下几部分:
- 主要采集和格式化的数据,会统一发到 cdp-ingest 的 topic;
- RT-CDP 有个统一的入口 Job(Entrance Job)负责数据的清洗、校验、Schema 解析以及身份识别等,然后根据租户属性进行数据分发。因为这是 RT-CDP 入口 Job,需要支持横向扩缩,所以这个作业是无状态J ob。
- 经过数据分发,会有不同的 Job 群进行分别的数据处理、持久化,以及数据聚合等数据加工逻辑,一方面丰富潜客画像,另一方面为更多维度的潜客圈群提供数据基础。
- 最后会将打通的数据分发到下游,下游包括外部系统、数据分析、实时规则引擎、策略模型等多类业务模块,以便进行更多的实时驱动。
扩展1:数据路由
为什么要做路由? 爱番番 RT-CDP 做为基础数据平台,不仅服务于百度之外的租户,也服务于百度内部甚至爱番番自己;不仅服务于中小企业,也服务于中大企业。对于前者,服务稳定性要求级别不同,如何避免内外部之间服务能力不相互影响?对于后者,不同规模企业潜客量不同,使用 RT-CDP 圈人群等耗时的资源也不同,如何避免资源不公平分配? 我们怎么做的? 针对上述问题,我们通过数据路由的机制解决。我们维护了一张租户和数据流 Topic 的映射关系,可以根据租户特性进行分流,也可以根据租户需求动态调整。然后在 Entrance Job 根据租户的映射关系进行数据分流,分发到不同资源配比的 Job 群进行分别的数据处理。做到了内外部分离,也可以根据租户个性化需求进行资源控制。扩展2:自定义Trigger批量写
在随机读写上,Kudu 的表现相对于 HBase 等还是相对差一些。为了做到数十万 TPS 的写能力,我们对 Kudu 写也做了一定逻辑优化。主要是自定义了 Trigger(数量+时间窗口两种触发),在做到毫秒级延迟的前提将单条写改为一次策略的批量。 具体方案:在在批量数据满足 >N 条、或者时间窗口 > M毫秒时,再触发写操作。一般租户的一次营销活动,会集中产生一大批潜客行为,这其中包括系统事件、用户实时行为等,这种批量写的方式,可以有效提高吞吐。
4.3.3.2 实时存储
在 RT-CDP 主要包括三部分的数据:碎片化的租户数据、统一的潜客画像和离线分析数据。我们主要分类两个集群进行数据存储,一个集群存储潜客统一画像和具有时序属性的热数据,另一个集群存储冷数据和用于离线计算的数据。每个集群都集成了数据湖的能力。然后我们研发了统一的 Query Engine ,支持跨源、跨集群的数据查询,对底层存储引擎透明。
扩展1:基于数据分层增强存储
为什么需要分层? 完全基于 Kudu 存储数据的话,一方面成本较高(Kudu 集群都要基于 SSD 盘搭建才能有比较好的性能表现);另一方面在营销场景下更关注短时间段(比如近一个月、三个月、半年等)客户的实时行为变化,对于时间较久的历史数据使用频次很低。 分层机制 综合考量,也从节约资源成本角度,我们选择 Parquet 做为扩展存储,针对存储符合时间序列的海量数据做冷热分层存储。 根据数据使用频率,我们将数据分为热、温、冷三层。热数据,表示租户经常使用的数据,时间范围为三个月内;温数据,表示使用频率较低的数据,一般只用于个别客群的圈选,时间范围为三个月外到一年;冷数据,租户基本不使用的数据,时间范围为一年之外。为了平衡性能,我们将热、温数据存放在同一个集群,将冷数据放在另外集群(和提供给策略模型的集群放在一个集群)。 具体方案:- 在热、温、冷之上建立统一视图,上层根据视图进行数据查询。
- 然后每天定时进行热到温、温到冷的顺序性的分别离线迁移,在分别迁移后会分别进行视图的实时更新。
扩展2:基于潜客融合路径的映射关系管理解决数据迁移问题
为什么需要管理映射?
潜客画像行为数据很多,也可能存在频繁融合的情况,如果在潜客融合时,每次都迁移数据,一方面数据迁移成本很高,另一方面,当潜客行为涉及温冷数据时,是无法进行删除操作的。业内针对类似情况,更多会有所取舍,比如只迁移用户仅一段时间的热数据,再往前的历史不做处理。这种解决方案并不理想。 映射管理机制为此,我们换了种思路,通过维护潜客融合路径的方式方式解决该问题。 具体方案:
- 新增一张潜客融合关系表(user_change_rela)维护映射关系;
- 在融合关系表和时序表(比如 event)之上创建视图,做到对业务层透明。
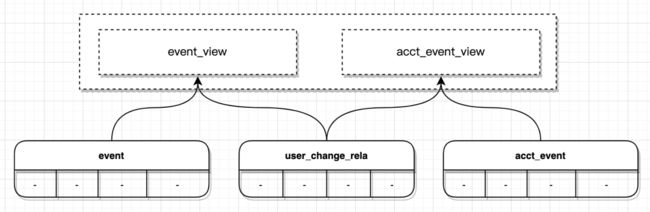
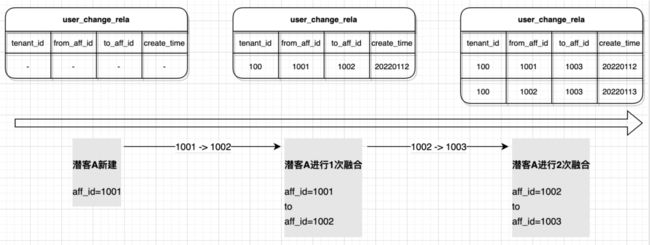
针对融合关系表,我们做了一定的策略优化:不维护路径上的过程关系,而是只维护路径所有过程点到终点的直接关系。这样即便在潜客融合路径涉及过多潜客时,也不会过多增加关系查询的性能。 举个例子潜客发生两次融合(affId=1001 先融合到 1002 上,再融合到 1003 上)时的user_change_rela的数据变化情况,如下图:
4.3.3.3 分析增强
我们选择百度开源的 Apache Doris 做为数据增强的分析引擎,为爱番番拓客版提供客户洞察能力,比如旅程分析、人群、营销效果分析、裂变分析、直播分析等。 为了方便后续OP部署时可灵活去除,我们将 CDP 输出的数据做为增强分析的数据源,然后基于Flink Job做逻辑处理,比如清洗、维度 Join、数据打平等,最后采用 Apache Doris 贡献的 flink-doris-connector 将数据写入 Doris。 使用 connector 方式直接写 Doris 有两个好处:-
使用 flink-doris-connector 往 Doris 写数据,比使用 Routine Load 方式少一次 Kafka。
- 使用 flink-doris-connector 比 Routine Load 方式在数据处理上,也能更加灵活。

Flink-doris-connector 是基于 Doris 的 Stream Load 方式实现,通过 FE redirect 到 BE 进行数据导入处理。我们实际使用 flink-doris-connector 时,是按 10s 进行一次 Flush、每批次最大可提交百万行数据的配置进行写操作。对于 Doris 来说,单批次数据多些不 flush 更频繁要友好。 如果想了解更多 Doris 在爱番番中的实践,可以阅读『 百度爱番番数据分析体系的架构与实践 』。
扩展1:RoutineLoad和Stream Load区别
Routine Load方式 它是提交一个常驻 Doris 的导入任务,通过不断的订阅并消费 Kafka 中的 JSON 格式消息,将数据写入到 Doris 中。 从实现角度来说,是 FE 负责管理导入 Task,Task 在 BE 上通过 Stream Load 方式进行数据导入。Stream Load方式
它利用流数据计算框架 Flink 消费 Kafka 的业务数据,使用 Stream Load 方式,以 HTTP 协议向 Doris 写入。 从实现角度来说,这种方式是框架直接通过 BE 将数据同步写入 Doris,写入成功后由 Coordinator BE 直接返回导入状态。另外,在导入时,同一批次数据最好使用相同的 label ,这样同一批次数据的重复请求只会被接受一次,可以保证了 At-Most-Once。4.3.4 实时规则引擎
在爱番番私域产品中,灵活的圈群能力是一个重要产品能力,如何基于潜客属性、身份、客户行为等维度进行复杂、灵活规则的实时分群?此处的实时规则引擎就是为此而生。就此功能本身来说并不新颖,在 DMP 中就有类似能力。很多 CDP 和客户管理平台都也有类似能力,但如何在多租户、海量数据情况下,做到实时、高吞吐的规则判断是一个挑战。 在爱番番 RT-CDP 中,一方面租户数量大, Saas 服务前提如何支持多租户的高性能分群?另一方面,爱番番 RT-CDP 期望做到真正基于实时流的实时判断。因此,我们自研了基于多层数据的实时规则引擎。这里简单讲一下,后续会有单独文章介绍。面临的问题是什么?
传统的实现方案主要是当租户实时或定时触发分群请求时,将规则翻译成一个复杂 SQL,临时从租户的潜客数据池中进行 SQL 查询。另外,一般都会在潜客上做一层倒排索引,在租户少或者 OP 部署时,数据查询速度也尚可接受。但在基于实时流实现规则引擎需要解决如下几个问题:- 海量数据实时判断
- 窗口粒度数据聚合的内存占用问题
- 滑动窗口下的窗口风暴
- 无窗口规则的数据聚合问题
- 潜客数据变更后的窗口数据更新
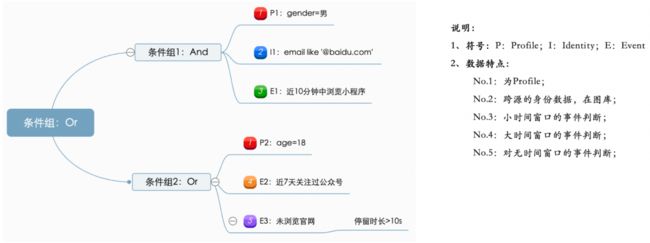
为了规则灵活度和高效的数据处理能力,我们定义了一套规则解析算法。然后借助 Flink 强大的分布式计算能力和状态管理能力驱动实时规则引擎计算。上面已经说了流数据理念,这里结合一条潜客行为进来到实时规则判断来更直观说明数据在流中的实时填充,如下图:数据进来之后,先经过 Identity Service 补充身份 Ids ,在经过数据 Job 补充潜客对应的属性信息,最后基于一个完整的潜客数据进行实时规则判断,最后将负责规则的潜客落入 Segment 表。
另外,规则引擎是一个独立于 Segment 等业务对象的服务,可以支持圈群、打标签、 MA 旅程节点等各个规则相关的业务场景。
4.3.5 扩展
4.3.5.1 弹性集群
爱番番 RT-CDP 的计算、存储集群基于百度云搭建,借助云上能力,很好实现了资源的存算分离和动态伸缩。我们可以自定义灵活的资源扩缩策略,根据消息量情况进行资源增减,做到波峰时实时加大集群规模提供计算能力,波谷时缩减集群做到及时降本。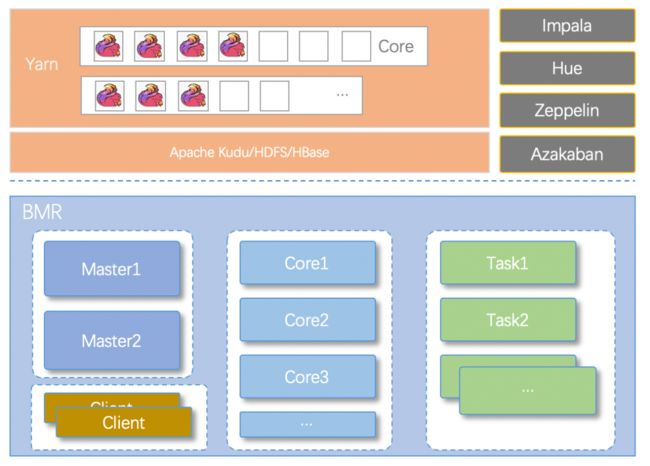
我们的集群主要分为四类节点:Master、Core、Task、Client。具体如上图。
-
Master节点: 集群管理节点,部署 NameNode、ResourceManager 等进程,并且做到组件故障时的自动迁移;
-
Core节点: 计算及数据存储节点,部署 DataNode、NodeManager 等进程;
-
Task节点: 计算节点,用来补充 core 节点的算力,部署 NodeManger 等进程,该节点一般不用来存储数据,支持按需动态扩容和缩容操作;
-
Client节点: 独立的集群管控节点及作业提交节点。
4.3.5.2 全链监控
RT-CDP 在建设了完整的链路监控能力,能够实时发现集群、数据流问题,方便及时干预、处理,为租户提供更好的数据服务能力提供保证。也建设了全链的日志收集、分析能力,极大简化了服务问题排查成本。
具体如上图,我们依托爱番番强大的技术服务能力完成了跨平台的日志采集&报警和全链路的延时监控:
- 日志采集: 基于爱番番贡献给 Skywalking 的 Satellite 收集全链路服务日志,支持了 K8s 下微服务的日志收集,也支持了 Flink Job 的日志采集,做到一个日志平台,汇集全链服务日志。然后通过 Grafana 进行日志查询、分析;
- 服务指标采集: 我们通过 PushGateway 将各个微服务,Apache Flink、Impala、Kudu等算存集群指标统一采集到爱番番 Prometheus,做到服务实时监控&报警。
- 全链路延时监控: 我们也通过 Skywalking Satellite 采集 RT-CDP 全链路的数据埋点,然后通过自研的打点分析平台进行延时分析,做到全链路数据延时可视化和阈值报警。
五、平台成果
5.1 资产数据化
基于 RT-CDP 解决企业数据孤岛问题,帮助企业将数据资产数字化、多方化、智能化、安全化。- 多方化: 集成一方数据,打通二方数据,利用三方数据,通过多方数据打通,实现更精准、深度的客户洞察。
- 数字化: 通过自定义属性、标签、模型属性等将客户信息全面数字化管理。
- 安全化: 通过数据加密、隐私计算、多方计算实现数据安全和隐私保护,保护企业数据资产。
- 智能化: 通过智能模型不断丰富客户画像,服务更多营销场景。
5.2 高效支撑业务
1.灵活的数据定义能力 RT-CDP 在业务层面具备了灵活的数据定义能力,来满足企业的个性化需求:- 丰富的自定义 API,用于可以自定义 Schema、属性、事件等不同场景的数据上报结构;
- 支持了身份类型自定义,方便企业根据自身数据特定指定潜客标识;
- 针对不同企业的不同结构的数据可以做到零开发成本接入。

5.3 架构先进
目前我们完成 RT-CDP1.0 的建设,并且在一些核心指标上都取得了不错的效果:5.3.1 实时高吞吐
-
Identity Service 做到数十万 QPS 的关系查询,支持上万 TPS 的身份裂变。
-
实时计算做到了数十万 TPS 的实时处理、实时持久化,做到毫秒级延迟。
-
支持企业海量数据、高并发下毫秒级实时分析。
-
真正基于实时流数据实现规则判断,支撑了私域打标、实时规则判断、圈群等多个实时业务场景,让营销毫秒触达。
5.3.2 高扩展性
平台架构存算分离,可水平扩展:-
基于云原生+Nebula 搭建了可动态伸缩的图存储集群;
-
借助百度云原生 CCE、BMR 等云上能力,搭建了存算分离的弹性伸缩的存算集群;
-
计算集群动态伸缩,节约企业资源成本。
5.3.3 高稳定性
各个模块、各个集群稳定性指标长期维持在 99.99 %以上。六、未来展望
【业务层面】 更多贴近行业的中台能力-
平台目前在业务支撑上已经具备了比较好的定义能力。下一步将结合重点服务的企业行业,内置更多行业业务对象,进一步简化企业数据接入成本。
-
在 B2B2C 数据模型上做更多业务尝试,更好服务 ToB 企业。
- RT-CDP 已经为企业提供了智能化的潜客评分能力,支持企业灵活定义评分规则。在AI时代,我们将继续丰富更多的AI模型来帮助企业管理、洞察、营销客户。
-
目前 Flink 作业还是基于Yarn管理资源、基于 API、脚本方式流程化操作(比如涉及到 CK 的操作)作业监控通过如流、短信、电话报警。后续我们将作业管理、运维上做更多尝试,比如基于 K8s 管理 Flink 作业、结合如流的 Webhook 能力完善作业运维能力等。
-
在流数据驱动下,数据处理机制的变化让数据治理、数据检查变得更有挑战。为了提供更可靠的数据服务,还有很多工作要做。
-
国内互联网公司已经有不少数据湖技术实践案例,确实可以解决一些原有数仓架构的痛点,比如数据不支持更新操作,无法做到准实时的数据查询。我们目前也在做 Flink 和 Iceberg/Hudi 集成的一些尝试,后续会逐步落地。
- 作者介绍 -
Jimmy:带着团队为爱番番奔走的资深工程师
【精彩文章】
社区人物志|王博:每一位你,都是前进道路上的一团星光。
社区人物志|张家锋:一个人可能走得更快,但一群人会走得更远
活动回顾|Apache Doris 向量化技术实现与后续规划
从NoSQL到Lakehouse,Apache Doris的13年技术演进之路
欢迎扫码关注:

Apache Doris(incubating)官方公众号
相关链接:
Apache Doris官方网站:
http://doris.incubator.apache.org
Apache Doris Githu b:
https://github.com/apache/incubator-doris
Apache Doris 开发者邮件组:
本文分享自微信公众号 - ApacheDoris(gh_80d448709a68)。
如有侵权,请联系 [email protected] 删除。
本文参与“ OSC源创计划 ”,欢迎正在阅读的你也加入,一起分享。