【论文翻译】Generation of Non-Deterministic Synthetic Face Datasets Guided by Identity Priors(21.12)
文章目录
- 读后感
- Abstract
- 1 Introduction
-
- 1.1 Our contributions
- 2 Related Works
-
- 2.1 Synthetic Image Generation
- 2.2 Mated Sample Generation
- 2.3 Limitations in State-of-the-art
- 3 PCA-FR-Guided Sampling
- 4 Synthetic Mated Face (SymFace) Dataset
- 5 Experimental Results
- 6 Conclusion and Future Work
论文标题: Generation of Non-Deterministic Synthetic Face Datasets Guided by Identity Priors
基于身份先验的非确定性合成人脸数据集生成
论文地址:https://arxiv.org/abs/2112.03632v1

读后感
核心方法:操纵 潜在空间 向 所想要的空间 转化? 潜在空间? define semantically meaningful directions?
This work proposes a non-deterministic method for generating mated face images by exploiting the well-structured latent space of StyleGAN. Mated samples are generated by manipulating latent vectors, and more precisely, we exploit Principal Component Analysis (PCA) to define semantically meaningful directions in the latent space and control the similarity between the original and the mated samples using a pre-trained face recognition system.
一个数据集:非常适合biometric performance tests
We create a new dataset of synthetic face images (SymFace) consisting of 77,034 samples including 25,919 synthetic IDs.
synthetic mated samples generated with PCA-FR-Guided sampling are well suited for biometric performance tests.
Abstract
通过人脸识别实现高度安全的应用(如越境)需要通过大规模数据进行广泛的生物特征性能测试。然而,使用真实的人脸图像会引起人们对隐私的担忧,因为法律不允许将这些图像用于最初计划之外的其他目的。使用具有代表性的人脸数据和人脸数据子集也可能导致不必要的人口统计偏差,并导致数据集的不平衡。
克服这些问题的一个可能的解决方案是用合成生成的样本替换真实的人脸图像。虽然生成合成图像得益于计算机视觉的最新进展,但生成具有类似真实世界变化的相同合成身份的多个样本(即配对样本)仍然没有得到解决。
本文提出了一种利用StyleGAN结构良好的潜在空间生成匹配人脸图像的非确定性方法。通过操纵潜在向量生成匹配样本,更准确地说,我们利用主成分分析(PCA)在潜在空间中定义语义上有意义的方向,并使用预训练的人脸识别系统控制原始样本和匹配样本之间的相似性。
我们创建了一个新的合成人脸图像数据集(SymFace),该数据集由77034个样本组成,其中包括25919个合成ID。通过使用成熟的人脸图像质量指标进行分析,我们展示了模拟真实生物特征数据特征的合成样本在生物特征质量方面的差异。分析及其结果表明,使用所提议的方法创建的合成样本作为替代真实生物测定数据的可行替代方案。
关键词:Biometrics, Face recognition, Synthetic Face Image Generation, Deep learning, StyleGAN
1 Introduction
随着更准确、更方便的识别技术的发展,生物特征识别的普及程度稳步提高。根据ISO/IEC 2382-37:2017[17],生物特征识别是指根据个人的生物学和行为特征自动识别个人。特别是,人脸已被证明具有足够的独特性和易于捕捉的生物特征,导致了广泛的现实世界应用,包括边境控制、护照签发和平民身份管理。在当前人脸识别系统良好性能的推动下,欧盟内部启动了智能边界计划,以建立出入境系统(EES)[4],这是一个用于为来自第三国的旅行者登记的自动化IT系统,取代了当前的手动护照盖章系统。这一系统旨在帮助真正的第三国国民更容易旅行,同时也更有效地查明在押人员以及证件和身份欺诈案件。若要自动执行,EES将注册此人的姓名、旅行证件类型和生物特征数据(人脸图像和/或指纹)。
在欧洲边境部署生物识别的要求符合欧洲边境和海岸警卫队(Frontex)自动边境控制最佳实践中定义的高标准[6]。必须通过进行需要大型数据集的大规模生物特征性能测试来验证是否符合这些指南。由于真实人脸图像的收集成本高昂、耗时且涉及隐私,因此生成合成人脸图像已成为一种有吸引力且可行的选择。在技术进步的推动下,StyleGAN和StyleGAN2[20][21]等方法有望创建具有独特身份的大规模人脸数据集。
虽然合成图像生成方法在各种应用中得到了很好的应用,但这些图像在生物特征识别中的适用性是有限的。具体而言,用于训练算法和性能测试的生物特征数据需要模拟真实数据,其姿势、表情、遮挡和照明变化会反映任何特定身份的真实条件。本质上,每个合成身份应该伴随一组变体,这些变体可以组成所谓的配对样本,以获得比较分数。具体地说,合成数据应该表示类内变化,类似于真实数据,同时保留身份信息。配对样本基本上需要生成真实分数分布,以衡量生物特征性能,如假匹配率(FMR)和假不匹配率(FNMR)。然而,尽管合成图像生成[20][21]最近取得了一些进展,但使用配对样本创建合成数据集仍然是一个技术问题,这些样本具有代表性,并与在边界控制场景中捕获的真实人脸图像相比较(例如,无面部遮挡的额头姿势)。
1.1 Our contributions
这项工作通过引入一种生成合成匹配样品的新技术来应对上述挑战。更准确地说,利用预先训练的StyleGAN生成器[20]用于生成distinct synthetic individuals的合成人脸图像(“”base images”)。每个base images由潜在向量w1×512表示,作为原始图像的压缩版本,反映StyleGAN学习的内部数据表示。受通过在潜在空间中的特定方向上移动相应的潜在向量来编辑人脸属性的想法[25]的启发,我们建议以不确定的方式生成匹配的人脸。我们断言,这种属性编辑方法可以更好地近似真实匹配样本的自然身份内变化,如图1所示。

由于潜在向量空间的分量可以表示各种可能的语义,因此主分量可以解释为StyleGAN潜在空间中语义上有意义的方向。具体地说,从50000到512的潜在向量空间中提取主成分[22]可以获得语义上有意义的值。受此启发,我们通过将潜在向量转移到最相关的特征向量(即主分量)给出的方向来创建匹配样本。然而,随着潜在向量远离其原始位置,丢失身份信息的风险增加,因此,使用预先训练的人脸识别系统(FR)[5]动态获取原始图像和编辑图像之间的距离,以确保保存用于编辑的原始身份的配对样本中的身份信息。我们将非确定性人脸编辑称为以无监督的方式更改多个语义,而不是控制人脸编辑,在控制人脸编辑中选择特定的人脸属性进行编辑。
基于我们提出的方法的基本原理,我们创建了一个新的人脸图像数据集,其中包含合成身份和每个身份的匹配样本,我们称之为合成匹配人脸数据集(SymFace dataset)。该数据集由77034个样本组成,每个合成身份平均有三个配对样本。为了更好地模拟半受控的拍摄环境,将具有极端特征的图像分类,同时考虑照明条件、头部姿势旋转和眼睛间距离。此外,由于幼儿和老年人可获得的训练数据有限,该研究集中于成人面部图像。We refer to Figure 3 to get an impression of typical images filtered out by our filtering pipeline.
我们进一步评估我们提出的合成数据集的质量,将其属性与从FRGC v2.0 [23].获取的真实人脸图像进行比较。在进行此类分析的其他方法中,我们使用面部质量评估算法(FQAAs)[19]将每个图像的生物特征质量转换为[0,100]之间的质量分数。在这种情况下,高分数表示相应的生物特征样本非常适合生物特征识别。相反,由于输入图像的低质量,低分数会降低识别精度。对生物特征质量的理解与ISO/IEC 29794-1[16]规定的术语相对应,定义了生物特征样本作为生物特征识别性能预测的效用。在这项工作中,两种FQAAs用于评估和比较 biometric quality:FaceQnet v1[11]和SER-FIQ[26]。此时,读者可参考第2节,以获得这些方法的更详细描述。
在本文的其余部分,第2节总结了生成合成人脸图像和匹配样本的概念思想。接下来,第3节详细描述了提出的PCA-FR-Guided采样方法。第4节详细介绍了新创建的SymFace数据集,最后,第5节给出了实验结果的概述,然后是第6节中关于关键发现的结论。
2 Related Works
2.1 Synthetic Image Generation
2019年,Karras等人[20]提出了一种基于样式的生成对抗网络生成器架构(StyleGAN),能够生成具有高分辨率(1024x1024)和逼真外观的合成图像。除了他们提出的GAN架构之外,作者还从社交媒体平台(Flickr)上对高质量的人脸图像进行网络爬取,以创建一个新的数据集(FFHQ),覆盖各种各样的soft biometrics。
尽管深度生成网络最近取得了成功,但大多数生成器仍像黑匣子一样运行,对潜在空间缺乏更深入的了解。为了解决这些弱点并改善潜在空间的disentanglement 特性,StyleGAN将最初绘制的潜在向量映射到中间潜在空间,从而以更disentangled (理顺;分清,清理出(混乱的论据、想法等);使解脱;使脱出;使摆脱;解开…的结)的方式对面部特征进行编码。此外,自适应实例规范化(AdaIN)[13]能够在多个特征级别上融合不同面的样式。此外,通过在每次卷积操作后向特征映射添加高斯噪声来改变细粒度细节,从而实现随机变化。最近,StyleGAN 2由同一作者发表[21],改进了架构设计,并修复了StyleGAN生成的合成图像中出现的特征 artefacts(人工制品,手工艺品(尤指有历史或文化价值的))。
在StyleGAN和StyleGAN2中,通过从已知分布(潜在空间)随机采样生成合成图像。如果从分布的尾部区域提取这些潜在向量,则生成的人脸图像的质量恶化,而人脸属性的多样性增加。为了平衡这一平衡,可以使用截断因子来稳定采样:截断的潜在代码w0计算为w0=`w+ψ(w− w’),其中w表示潜在空间的质心,ψ表示截断因子。根据Zhang等人[9]的实验分析,我们选择了ψ=0.75的截断因子。在[9]中,作者已经证明,使用StyleGAN和StyleGAN2生成的合成样本的生物识别性能与FRGC v2.0[23]中的真实图像相似且可比。因此,这项工作使用StyleGAN生成合成基础图像,使PCA-FR-Guided采样的实现能够在InterFaceGAN[25]的框架内运行。
2.2 Mated Sample Generation
尽管[9]中已经表明,单个合成人脸图像可以实现与人脸识别真实样本相当的性能,但在生物特征性能评估中,配对样本更为常见。给定合成的基础图像,可以通过编辑面部属性来模拟真实样本中存在的变化因素来导出匹配样本。随着Shen等人[25]的开创性工作,InterFaceGAN被引入作为一个框架,通过操纵潜在空间中的潜在向量,可以编辑合成身份的面部属性。在这种情况下,潜在空间反映了StyleGAN的内部数据表示,并构造了从训练数据集中学习到的各种语义。此外,StyleGAN的创新架构显著减少了编码语义的纠缠,这为受控修改面部属性提供了最佳条件。
InterFaceGAN的主要贡献是基于这样一个观察,即潜在空间可以根据二元语义划分为线性子空间,如“微笑”或“不微笑”。具体地说,线性支持向量机(SVM)[3]用于将潜在空间划分为每个感兴趣的人脸属性的子空间。一旦支持向量机被训练,通过将潜在向量移动到先前发现的边界的垂直方向来修改面部属性,从而引起连续的变化。Colbois等人[2]也采用了同样的原理,他们通过近似 Multi-PIE的真实条件来操纵yaw angle, illumination(照明), and a smile [7]。
2.3 Limitations in State-of-the-art
尽管InterFaceGAN生成的交配样本在视觉上很吸引人,但它们在一般生物特征性能测试中的适用性仍然有限,尚待研究。如图1所示,在真实场景中采集的交配样本自然包括同时变化的几种变化,例如姿势、照明、表情以及它们的组合。相比之下,受控人脸编辑只关注于更改少数语义,而其他语义则保持不变。因此,controlled modifications有助于确定人脸识别系统针对目标语义的脆弱性,同时仅代表真实数据集中潜在多样性的一小部分。基于这一观察,我们引入PCA-FR-Guided sampling作为一种生成非确定性匹配样本的技术,以替换或补充现有的测试数据集。
3 PCA-FR-Guided Sampling
本节介绍我们生成匹配样本的新方法,我们称之为PCA-FR-Guided Sampling。如第2节所述,语义修改可以通过在潜在空间中移动潜在向量来引起。However, this approach still leaves two questions unanswered: 1) How to choose semantically meaningful directions? 2) How to choose the distance to preserve identities while maximising the intra-identity variation?(然而,这种方法仍然有两个问题没有解决:1)如何选择语义上有意义的方向?2) 如何选择距离来保持身份,同时最大化身份内部差异?)
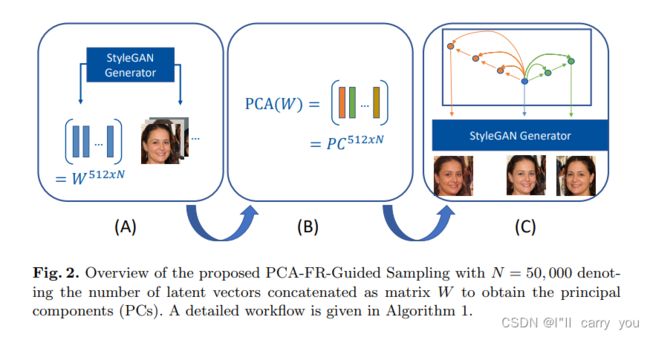
为了找到上述问题的解决方案,图2提供了PCA FR引导采样技术的概述。使用StyleGAN生成截断因子为ψ=0.75(a)的初始合成数据集后,应用PCA从相应的潜在向量(B)中提取语义上有意义的方向。其思想是提取方差最大的潜在方向,从而在图像生成后产生有效的方差。最后,通过以逐步方式(C)测量原始样本和移位匹配样本之间的相似性,沿主分量轴移动潜在向量,同时动态调整距离。算法1提供了PCA FR引导匹配样本生成过程的详细工作流程。

我们特别使用步长和验证阈值作为控制参数来平衡 intra-class variation and identity retaining(保留) factor for generated mated samples. 换言之,增加比较阈值减小原始潜在向量和移位潜在向量之间的距离,从而生成具有较少变化因子的更多相似面。另一方面,减小步长以较小的步长接近给定阈值,从而产生closer to the desired similarity t o l e r a n c e 3 tolerance^{3} tolerance3.的匹配样本

4 Synthetic Mated Face (SymFace) Dataset
5 Experimental Results
6 Conclusion and Future Work
为了解决真实数据集的隐私相关问题并克服训练数据的不足,我们引入PCA-FR-Guided采样以非确定性方式生成匹配样本。与在潜在空间中操作的受控人脸图像编辑技术不同,我们应用PCA来寻找语义上有意义的方向。在将潜在向量移动到这些方向的同时,通过预先训练的人脸识别系统进行渐进式监控来保持基础人脸图像的身份。利用新创建的包含77034张图像的合成配对样本数据集(SymFace数据集),我们评估了最先进的人脸质量评估算法和生物特征比较分数分析,以验证所提出方法的适用性。配对和非配对比较分数之间的The well-separated distributions表明,使用PCA-FR-Guided采样生成的合成配对样本非常适合生物特征性能测试。此外,面部质量和比较分数的分析与真实数据集中的观察结果具有可比性,表明了所提出方法的有效性。
Although this work has illustrated to include synthetic samples in face recognition performance tests, we emphasise the open challenge to mimic(模仿) the full extent of intra-identity variation measurable in bona fide datasets(真实数据集)。未来的工作还应侧重于对不同主成分的探索性分析,从而探索StyleGAN的潜在空间,并加强对内部数据表示的理解。We foresee using the proposed approach to reduce the need for large training sets and minimise the demographic(adj. 人口统计学的; 人口学的; ) bias by diversifying(多样化) latent space in synthetic generation schemes.