【一】【C++】C++入门
命名空间
命名空间namespace
使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染。
/*1 rand与rand()冲突*/
#include
#include
int rand = 10;
int main() {
printf("%d\n", rand);
return 0;
} stdlib.h库中有一个函数rand(),此时如果我们想要定义一个int类型,名字为rand的变量,此时就会报错。

/*2 在main中定义rand不会报错*/
#include
#include
int main() {
int rand = 10;
printf("%d\n", rand);
return 0;
} 在main函数中定义rand变量,并且打印,此时不会报错。

/*3 在main中定义rand不会报错,但是此时rand()无法使用*/
#include
#include
int main() {
int rand = 10;
rand = rand();
printf("%d\n", rand);
return 0;
} 但是此时rand()无法使用。
这就是命名冲突。为了避免这种情况我们引入了命名空间,namespace关键字。
命名空间namaspace的定义
/*4 引入命名空间*/
#include
#include
namespace _240121 {
int rand = 10;
int add(int left, int right) {
return left + right;
}
struct node {
int data;
struct node* next;
};
}
int main() {
_240121::rand = rand();
printf("%d\n", _240121::rand);
return 0;
} 命名空间的定义规则:namespace+空间名称+{}
命名空间namaspace的使用
此时命名空间_240121是一个独立的空间,我们不能直接对该空间内的成员进行访问。
命名空间的使用有三种方式:
1.加命名空名称及作用域限定符
/*5 命名空间的使用方法 1.加命名空间名称及作用域限定符*/
#include
#include
namespace _240121 {
int rand = 10;
}
int main() {
printf("%d\n", _240121::rand);
return 0;
} 想要使用_240121中的成员时,在成员的前面添加成员所属命名空间的名称以及“::”作用域限定符。此时可以完全避免命名冲突。
此时编辑器直接到_240121命名空间中访问rand成员。
使用规则:命名空间名称+作用域限定符+具体某个成员
2.使用using将命名空间中某个成员引入
/*6 命名空间的使用方法 2.使用using将命名空间中某个成员引入
冲突解决不能用using引入成员,引入之后在外面还是有冲突,
而是应该直接加命名空间名称以及作用域限定符,直接找到命名空间中的rand*/
#include
#include
namespace _240121 {
int rand = 10;
}
using _240121::rand;
int main() {
printf("%d\n", rand());
printf("%d\n", rand);
return 0;
} ![]()
使用using 将_240121命名空间中rand成员引入到全局中,此时rand与stdlib.h中的rand会产生冲突。
#include
#include
namespace _240121 {
int a = 10;
}
using _240121::a;
int main() {
printf("%d\n", a);
return 0;
} 此时把_240121命名空间中a这个成员引入了,可以直接对a这个成员进行访问。
使用规则:using+命名空间名称+作用域限定符+具体某个成员
3.使用using将namespace命名空间名称引入
/*9 命名空间的使用方法 3.使用using namespace 命名空间名称引入*/
#include
#include
namespace _240121 {
int a = 10;
int b = 20;
}
using namespace _240121;
int main() {
printf("%d\n%d", a, b);
return 0;
} 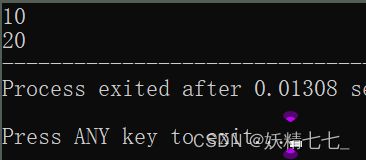
此时把_240121命名空间中所有成员都引入,对所有成员都可以直接访问。
/*8 命名空间的使用方法 3.使用using namespace 命名空间名称引入
冲突解决不能用using引入命名空间,引入之后在外面还是有冲突,
而是应该直接加命名空间名称以及作用域限定符,直接找到命名空间中的rand
综上所述,冲突解决,可以用命名空间解决,但是此时命名空间的引入只能通过,
加命名空间名称及作用域限定符,来解决
而不能用using 引入成员或者整个命名空间*/
#include
#include
namespace _240121 {
int rand = 10;
}
using namespace _240121;
int main() {
printf("%d\n", rand());
printf("%d\n", rand);
return 0;
} 冲突解决只能用第一种方式解决,但是平常我们一般不会遇到命名冲突的问题。
使用规则:using namespace+命名空间名称
命名空间的使用习惯
std命名空间的使用惯例:
std是C++标准库的命名空间,如何展开std使用更合理呢?
-
在日常练习中,建议直接using namespace std即可,这样就很方便。
-
using namespace std展开,标准库就全部暴露出来了,如果我们定义跟库重名的类型/对
象/函数,就存在冲突问题。该问题在日常练习中很少出现,但是项目开发中代码较多、规模
大,就很容易出现。所以建议在项目开发中使用,像std::cout这样使用时指定命名空间 +
using std::cout展开常用的库对象/类型等方式(第一种方式避免命名冲突)
C++输入输出
输出cout
/*10 C++的输出*/
#include
using namespace std;//std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中
int main() {
int a = 10;
cout << a << endl;//输出,a数据流向cout,即屏幕
return 0;
} 可以理解为cout为屏幕,a变量流向屏幕,即打印a,endl再流向屏幕,即换行。
cout的使用需要使用#include
cout是输出,相当于C语言中的printf。
我们会发现,cout打印数据不需要规定他的数据类型,而C语言使用printf打印数据时需要告诉编辑器该打印数据的数据类型是什么,这也是C++的一种优化。
输入cin
/*11 C++的输入*/
#include
using namespace std;//std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中
int main() {
int a;
cin >> a;//屏幕数据流向a
cout << a << endl;
return 0;
} 可以理解为cin表示屏幕,屏幕输入的数据流向a变量。
cin的使用同样需要使用#include
cin是输入,相当于C语言中的scanf。
cin同样不需要规定数据类型。
自动识别数据类型
/*12 C++的输入输出可以自动识别数据类型*/
#include
using namespace std;//std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中
int main() {
int a;
double b;
char c;
cin >> a;//屏幕数据流向a
cin >> b >> c;
cout << a << endl;
cout << b << " " << c << endl;
return 0;
} cout和cin都可以自动识别数据类型。
缺省参数
缺省参数的定义
/*13 缺省参数,缺省参数是声明或定义函数时为函数的参数指定一个缺省值。*/
#include
using namespace std;//std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中
void Func(int a=10){//定义函数时候
cout< 在函数定义的时候,对参数进行“赋值”,这不是真正的赋值,而是缺省参数的定义。
当这个形参缺少的时候,就是用我们定义的10,如果形参没有缺少,就使用我们传过去的形参值。

缺省参数的分类
-
全缺省
-
半缺省
1.全缺省
/*14 缺省参数,全缺省。*/
#include
using namespace std;//std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中
void Func(int a = 10,int b = 20, int c = 30) { //定义函数时候
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}
int main() {
Func();
return 0;
} 此时Func函数中有三个参数,a,b,c,且这三个参数都是缺省参数。
2.半缺省
/*15 缺省参数,半缺省。*/
#include
using namespace std;//std是C++标准库的命名空间名,C++将标准库的定义实现都放到这个命名空间中
void Func(int a ,int b = 20, int c = 30) { //定义函数时候
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}
int main() {
Func(10);
return 0;
} 不严谨的说法就是,不是全缺省的就是半缺省。
注意事项
半缺省从右往左依次给出缺省值
需要注意的是半缺省,必须从右往左依次给出缺省值。
/*16 缺省参数,半缺省。
1.半缺省必须从右往左依次给出*/
#include
using namespace std;
void Func(int a =10,int b , int c = 30) {
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
}
int main() {
Func(10);
return 0;
} 
半缺省应该分为两个部分,左边部分无缺省值,右边部分有缺省值。

缺省参数不能在函数声明和定义中同时出现
/*17 缺省参数。
1.半缺省必须从右往左依次给出
2.缺省参数不能在函数声明和定义中同时出现*/
#include
using namespace std;
void Func(int a = 10);
void Func(int a = 20) {
cout << a << endl;
}
int main() {
return 0;
} 此时编辑器不知道使用那一个缺省值。
函数重载
函数重载定义
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这 些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型 不同的问题。
/*18 函数重载。
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这
些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型
不同的问题。*/
#include
using namespace std;
//参数类型不同
int add(int left, int right) {
cout << "int add(int left,int right)" << endl;
return left + right;
}
double add(double left, double right) {
cout << "double add(int left,int right)" << endl;
return left + right;
}
//参数个数不同
void f() {
cout << "void f()" << endl;
}
void f(int a) {
cout << "void f(int a)" << endl;
}
//参数类型顺序不同
void f(int a, char b) {
cout << "void f(int a, char b)" << endl;
}
void f(char b, int a) {
cout << "void f(char b, int a)" << endl;
}
int main() {
add(10, 20);
add(10.1, 20.2);
f();
f(10);
f(10, 'a');
f('a', 10);
return 0;
} 实现函数重载,首先函数名需要相同,其次是,形参列表(参数个数 或 类型 或 类型顺序)不同。
需要注意的是,
/*18 函数重载。
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这
些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型
不同的问题。*/
#include
using namespace std;
//参数类型顺序不同,不是参数顺序不同
void f(int a, int b) {
cout << "void f(int a, int b)" << endl;
}
void f(int b, int a) {
cout << "void f(int b, int a)" << endl;
}
int main() {
f(10, 1);
f(1, 10);
return 0;
} 这样是不构成函数重载的,因为参数个数是一样的,参数的类型和类型顺序也是一样的。
函数重载原理
c:函数名 c++:_Z+函数长度+函数名+类型首字母。
这是C语言和C++对于函数的修饰规则。
C++中:

而C语言中修饰规则是函数名。
引用
引用的定义
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空 间,它和它引用的变量共用同一块内存空间。
/*20 引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空
间,它和它引用的变量共用同一块内存空间。
类型& 引用变量名(对象名) = 引用实体;*/
#include
using namespace std;
void testRef(){
int a=10;
int& ra=a;
cout< 
他们的地址是一样的,引用只是给变量取了一个别名,他们共用同一内存空间。
引用的特性
/*21.引用的特性
1.引用在定义时必须初始化
2.一个变量可以有多个引用
3.引用一旦引用一个实体,再不能引用其他实体*/
#include
using namespace std;
void test1(){
int a=10;
int& ra;
ra=a;
cout< 1.引用必须初始化
在test1中,定义int类型的引用但是没有初始化化,系统报错。
![]()
2.一个变量可以用多个引用
运行test2得到,

变量a可以有多个引用,也就是可以有多个别名,就像一个人在不同阶段会有其对应的外号,不同的人取的不同的外号,他们都是一个人的别名。
3.引用一旦引用一个实体,就不能引用其他实体
运行test3得到,

我们发现b变量是20,我们没有改变b变量的值。也就是ra=b并不能使得ra变成b的别名。
ra=b的真正含义是b的值赋值匪ra,而ra是a的别名。
引用一旦引用一个实体,就不能引用其他实体。
常引用
用const修饰,表示只读。
/*22.常引用 */
#include
using namespace std;
void testconstref1() {
const int a = 10;
int& ra = a;//该语句编译时会出错,a为常量
}
void testconstref2(){
const int a = 10;
const int& ra = a;
cout << ra << endl << endl;
}
void testconstref3(){
int& b = 10;// 该语句编译时会出错,b为常量
const int& b = 10;
double d = 3.14;
int& rd = d;// 该语句编译时会出错,类型不同
}
void testconstref4(){
double d = 3.14;
const int& rd = d;//常引用自动类型转换
const double& rrd=d;
cout< testconstref1中定义了a变量是const只读,此时不能用ra引用a变量,因为如果用ra表示a的别名,此时ra是可读可写,我们用ra改变了a的值,这样就不合理了。
testconstref2中用const修饰的ra引用a,此时ra表示a的别名,且ra是只读的,这样就不会发生通过ra改变只读a的值的情况,所以这个用法是正确的。
testconstref3中b引用常量10,b是可读可写的,但是常量10是只读的,不可以这样使用。
而const int& b = 10; 用只读的b引用常量10这个用法是正确的。
double d = 3.14; int& rd = d;// 该语句编译时会出错,类型不同
此时rd引用的类型是int而d为double,类型不同会报错。
testconstref4中用常量引用rd表示d的别名,这个用法是可以的,可以理解为只读的引用,可以转换数据类型。
引用的使用场景
1.做参数
2.做返回值
/*23.引用的使用场景 */
#include
using namespace std;
void swap(int& a,int&b){
int temp=a;
a=b;
b=temp;
}
int& count(){
static int n=20;//出了作用域还存在
n++;
return n;
}
int main() {
int a=1,b=10;
swap(a,b);
cout< 1.做参数
2.做返回值
注意:如果函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用引用返回,如果已经还给系统了,则必须使用传值返回。
/*24.引用
如果函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用
引用返回,如果已经还给系统了,则必须使用传值返回。 */
#include
using namespace std;
int& add(int a, int b) {
int c = a + b;
return c;
}
int main() {
int& ret = add(1, 2);
cout << "add(1,2)=" << ret << endl;
return 0;
} 程序会崩掉,因为c变量出来作用域就还给系统了,而ret是c的别名,而c已经不存在了。
传值传引用效率比较
1.做函数参数
/*25.传值和传引用的效率比较
作为函数参数*/
#include
using namespace std;
#include
struct A {
int a[10000];
};
void testfunc1(A a) {}
void testfunc2(A& a) {}
void testrefandvalue() {
A a;
size_t begin1 = clock();
for (size_t i = 0; i < 1000000; i++) {
testfunc1(a);
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < 1000000; i++) {
testfunc2(a);
}
size_t end2 = clock();
cout << "testfunc1(A a)-->time:" << end1 - begin1 << endl;
cout << "testfunc2(A a)-->time:" << end2 - begin2 << endl;
}
int main() {
testrefandvalue();
return 0;
} 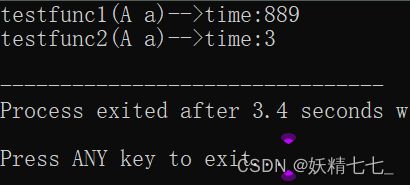
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
2.做函数返回值
/*26.传值和传引用的效率比较
作为函数返回值返回*/
#include
using namespace std;
#include
struct A {
int a[10000];
};
A a;
A testfunc1() {
return a;
}
A& testfunc2() {
return a;
}
void testrefandvalue() {
size_t begin1 = clock();
for (size_t i = 0; i < 1000000; i++) {
testfunc1();
}
size_t end1 = clock();
size_t begin2 = clock();
for (size_t i = 0; i < 1000000; i++) {
testfunc2();
}
size_t end2 = clock();
cout << "testfunc1(A a)-->time:" << end1 - begin1 << endl;
cout << "testfunc2(A a)-->time:" << end2 - begin2 << endl;
}
int main() {
testrefandvalue();
return 0;
} 
以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
引用和指针的区别
引用和指针的不同点:
1.引用概念上定义一个变量的别名,指针存储一个变量地址。
2.引用在定义时必须初始化,指针没有要求
3.引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
4.引用没有NULL引用,但指针有NULL指针
5.在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
6.引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
7.有多级指针,但是没有多级引用
8.访问实体方式不同,指针需要显式解引用,引用编译器自己处理
9.引用比指针使用起来相对更安全
内联函数
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率。
/*27.内联函数
无法声明和定义分离
空间换时间
将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不
是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。*/
#include
using namespace std;
inline int add(int left, int right) {
return left + right;
}
int main() {
int ret;
ret = add(1, 2);
cout << ret << endl;
return 0;
} -
inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率。
-
inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。
-
inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。
auto关键字
auto定义
auto作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
/*28.auto关键字*/
#include
using namespace std;
int testauto(){
return 10;
}
int main(){
int a=10;
auto b=a;
auto c='a';
auto d=testauto();
cout< 注意:使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto的实际类型。
auto使用规则
1.auto与指针和引用结合使用
/*29.auto关键字的使用规则*/
#include
using namespace std;
int main() {
int x = 10;
auto a = &x;
auto* b = &x;
auto& c = x;
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
*a = 20;
cout< 用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须加&
2.在同一行定义多个变量
/*30.auto关键字的使用规则
一行的变量数据类型必须是相同的*/
#include
using namespace std;
void testauto() {
auto a = 1, b = 2;
cout << a << endl << b << endl;
auto c=3,d=4.0;//报错
cout< 当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
不能使用auto的场景
/*31.auto关键字无法使用的场景*/
#include
using namespace std;
void testauto(auto a) {
}
void testauto() {
int a[] = {1, 2, 3};
auto a[] = {1, 2, 3};
}
int main() {
return 0;
}
1.auto不能作为函数的参数
2.auto不能直接用来声明数组
范围for
/*32.范围for遍历*/
#include
using namespace std;
void testfor() {
int array[] = {1, 2, 3, 4, 5};
for (auto& e : array) {
e *= 2;
}
for (auto e : array) {
cout << e << endl;
}
}
int main() {
testfor();
return 0;
}
for(auto& e:array)表示用e作为第一个元素的别名,接着用e作为第二个元素的别名,一直到e作为最后一个元素的别名为止。
for (auto e : array) 表示用e作为临时变量,其值等于第一个元素的值,接着e作为临时变量,其值等于第二个元素的值。一直到e作为临时变量,其值等于第最后一个元素的值为止。
nullptr空指针
/*33.nullptr*/
#include
using namespace std;
void f(int) {
cout << "f(int)" << endl;
}
void f(int*) {
cout << "f(int*)" << endl;
}
int main() {
f(0);
// f(NULL);
f((int*)NULL);
f(nullptr);
return 0;
} 传入Null实际上是想调用f(int*) ,但是Null可能被定义为0或者无类型指针(void*)的常量。
而传nullptr就可以直接调用f(int*) 。
结尾
最后,感谢您阅读我的文章,希望这些内容能够对您有所启发和帮助。如果您有任何问题或想要分享您的观点,请随时在评论区留言。
同时,不要忘记订阅我的博客以获取更多有趣的内容。在未来的文章中,我将继续探讨这个话题的不同方面,为您呈现更多深度和见解。
谢谢您的支持,期待与您在下一篇文章中再次相遇!