200行代码实现一个带界面的爬图小软件 - Python高手成长路(系列)
这次做的是可以边爬图、边下载、边看图的一个小软件,为了更好地演示,特别挑选了一个HTML源码看起来比较有代表性的图库站点。
先来看看最终效果是怎样的:


运行程序后:
① 自动从某图库网站上抓取各种客气小姐姐的照片,在界面上显示预览图
② 每次加载一批并自动保存在本地,需要时再点击按钮加载下一批
③ 双击界面上的预览图打开查看高清大图
听起来是不是略cool?而这些并不需要多大的代码量(包括灵活的界面设计),就可以漂亮地实现。
嗯?你问笔者为何图片是模糊的?由于会引起舒适,笔者在代码里面用PIL图像处理库加了点高斯模糊,不过只处理了界面上的预览图,实际下载下来的图片文件都是原图数据未处理的哦。
(文章最后附上项目源码链接,其中包含用于演示的图库网站的网址)
我们从实现效果倒推一下这个程序需要用到什么“装备”吧。
既然是爬图,一般是会用到爬虫常用的那几款模块,本程序用的是“人用的”requests(“HTTP for humans”,它的slogan)做HTTP请求抓取HTML数据,然后用lxml处理,并用XPath解析得到网页URL、图片URL。
(requests中文文档: http://docs.python-requests.org/zh_CN/latest/user/quickstart.html ;
XPath中文参考资料: https://www.runoob.com/xpath/xpath-tutorial.html )
爬下来的图片需要显示到界面上,那么需要选用一款图形界面模块,这里选了PyQt(Qt的Python实现,Qt是源于1991年、曾在2008年被诺基亚收购、现属Digia公司的一款非常强大的跨平台图形界面库),别问我为什么不用Python自带的Tkinter,因为PyQt实在太香了,各种对图形界面的支持都非常完善,自带界面设计工具、数据转换工具等,支持实现非常复杂的界面效果,而Tkinter扩展性太差就不提了。
综合上面的两种模块使用需求,我们还需要考虑:
① 爬图时对网页URL、图片URL分开处理,从网页URL获取到HTML数据,解析出其中的网页URL或图片URL,而从图片URL则直接获取到图片数据
② 爬图过程中,不能因为爬图正在工作而阻塞图形界面导致界面无法操作,爬图过程需要在后台完成
③ 爬取一批图片后自动暂停工作,点击按钮继续工作爬取下一批图片
我们采用Python自带的threading线程模块(Thread类、Lock类、Event类)、queue队列模块(Queue类)来实现。
到这里我们考虑到需要的暂时是这些:PyQt,requests,lxml,threading,queue。开发过程中需要其他的再作补充。
接下来可以开始动手啦,一边分析,一边开发程序。
01
爬图思路
把图片爬下来必须走的第一步,当然是对图片所在的网页进行解析啦。
我们先选一个网站上的页面作为爬图的起始页面,这个页面会包含很多图集的入口链接。打开Chrome(谷歌浏览器)访问页面,如图。

我们选用图上有多行每行四张小姐姐预览图的区域作为图集的入口点。仅仅是一个页面上这一小部分而已吗?我们再往下看。
![]()
在最下面有一行有“1”“2”“3”“4”……的翻页链接,我们就选这里作为翻页爬取更多图集的入口吧。
然后我们按F12开启Developer Tools(开发者工具)查看Elements(元素),在这里可以看到页面上的元素对应的HTML源码。不过直接在这里找似乎太麻烦了,我们回到页面,在预览图上点击右键,选择“检查”。
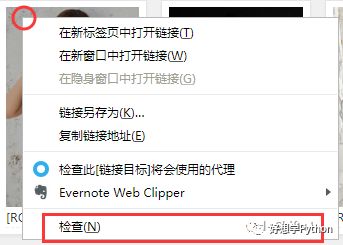
在Elements这边就能直接看到刚才点击“检查”的位置对应的网页元素了。
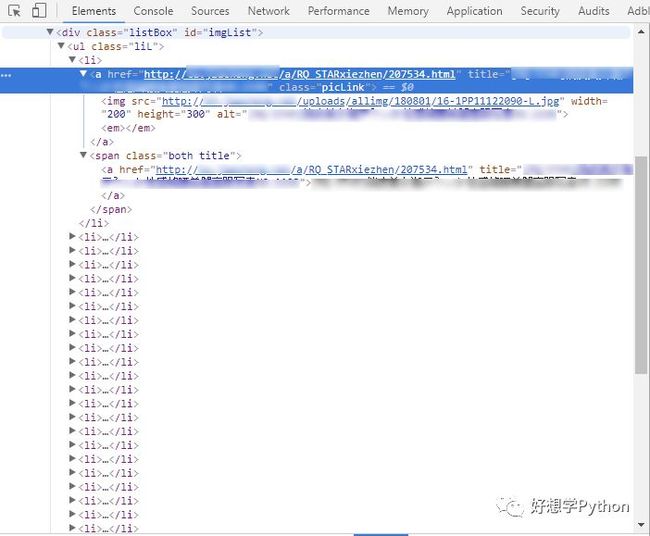
不难发现,网页设计者在设计HTML模板时,对id、class的命名还是挺友好的,比如第一行的div标签,id是“imgList”,我们推测是“图片清单”的意思,可以确定我们需要的区域就在这个div标签下面。
div下的ul标签下面有一堆li标签,每个li标签分别对应一张预览图(li下面的a标签和img标签)以及图下面的文字(li下面的span标签和a标签)。观察到两个a标签的href属性都是一样的,是进入到图集的链接,我们取其一就行。
观察到ul标签有class属性“liL”,我们由此写出取出图集链接的XPath:
![]()
为什么要用ul这个标签来定位呢?往后翻了几个页面,发现基本上是id为“imgList”的div标签下面跟一个class为“liL”的ul标签,我们秉承“让这条XPath尽量通用”的编写原则,尽量利用能提取到确切需要的数据它的最简特征信息,能不用id属性尽量不用。最终写出来的是上面这样。
那下面翻页的链接如何取到呢?别紧张,我们接下来看看进入图集后的页面。

随便点击一个图集后,我们发现这里下面的这行有“1”“2”“3”“4”……的翻页链接,不是长得跟刚才上一个页面的翻页链接一模一样吗?马上用“检查”看一下相关元素,笔者把两边的Elements放在一起截图,方便对比,如图。

不难发现,两边都有class为“pages”的div标签,从“pages”这个词推测这里就是显示翻页链接的地方。同样也是有ul标签,以及下面一堆li标签分别对应网页上的“1”“2”“3”“4”……这些链接。需要排除掉“首页”、当前页标号这些无用的链接,观察到他们的href属性都为“#”,那么加个href属性的筛选条件就可以了。另外观察到需要取的链接的href属性值都是不完整的,只有“xxxx.html”这种形式,这里有个小技巧,通过Python自带库urllib.parse里的urljoin()方法,将当前URL跟“xxxx.html”连接起来,就变成完整的链接了。待会在后面实现。
写出取出翻页链接的XPath如下:
![]()
在同样的页面上通过“检查”查看高清大图对应的链接,

如法炮制,写出取出高清大图的XPath如下:
![]()
测试的时候发现,这样子按部就班取出来的高清大图,每次都是从同一个图集同一个顺序开始爬取。我们用Python自带的random模块里面的shuffle方法,对链接进行打乱,这样每次爬取出来的就不全是一样的了,非常随缘。
抓取到的链接有网页和图片两种,网页的放入一个队列,图片的放入另一个队列。分别开启两个线程,一个按顺序从队列里面取出网页URL,按照上面写的三种XPath规则解析出来,再放入队列,再从队列取出新URL,如此反复;另一个按顺序从队列里面取出图片URL,做下载的操作,并发送Qt的信号更新界面(不允许在非主线程中更新处在主线程中的界面),如此反复。
限于篇幅,完整的双线程+双队列的实现可以在项目代码中结合代码的上下文进行理解。
爬图的核心代码真的不多,除去线程的壳子、连同requests获取数据的操作一起看,如图所示。

小技巧:requests请求数据所用的User-agent可以通过在浏览器地址栏输入执行以下代码,在出现的弹窗中获取。
![]()
02
界面设计
界面设计的部分相对简单,这里说一些比较关键的点吧。
安装好PyQt后,在安装目录下会有qtdesigner程序,运行它开启“Qt Designer”(Qt设计师),可以在这里直接设计界面。
选择MainWindow模板(包含基本窗体、菜单栏、状态栏),然后来一波控件拖放操作,界面控件就设计好了。如图。
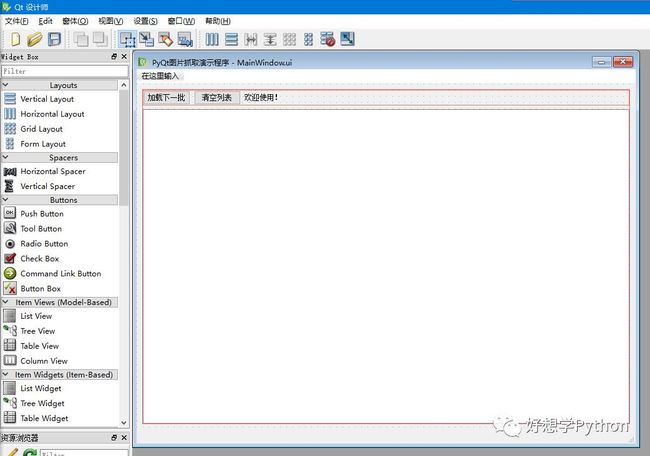

综合窗体设计预览和“对象查看器”来看,按钮(QPushButton)和文字标签(QLabel)是排列在“Horizontal Layout”(水平排列层,对应QHBoxLayout)里面的,这个Layout跟下面的“List Widget”(列表控件,对应QListWidget)又是排列在“Vertical Layout”(垂直排列层,对应QVBoxLayout)里面的。这些控件并不是随随便便从控件栏拖动到窗体上处于绝对位置的哦!通过对控件属性的简单调校,是可以实现调整窗口大小或者最大化时只有下面的List Widget扩大这样的效果的。
其实用List Widget列表控件来显示爬到的图片的预览图并不是它本身设定的用法,借助的是它“IconMode”(图标模式)的显示方式,利用将图片放入列表项的图标(QIcon)里面,把图片排列显示在列表控件上。
既然不是它本身设定的用法,必然会出现一些纠结的问题,比如横竖向不同的图片排列在一起的时候,会出现横向图片在格子中居上而不是居中的问题。查了很多文档资料,尝试了很多种方式,最后选择“QPainter居中画图”的方式来解决问题,这些在项目源码中都有体现,这里暂时不细讲。
限于篇幅,对控件的调校细节,可以下载项目源码,用Qt Designer打开“MainWindow.ui”文件详细查看。
通过代码加载“MainWindow.ui”界面文件的方式也很简单,只需要调用uic.loadUi()方法即可。接着作一些事件关联、信号关联。抽取出来看,大体框架如图。
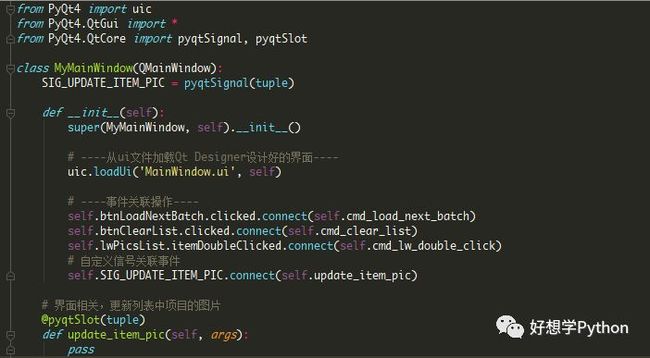
注意这里的pyqtSignal产生的对象一定要放在类共有属性下面,否则会报错“AttributeError: ‘PyQt4.QtCore.pyqtSignal’ object has no attribute ‘connect’”。限于篇幅,pyqtSignal相关用法请参考官方文档(英文, http://pyqt.sourceforge.net/Docs/PyQt4/new_style_signals_slots.html )。
03
程序优化
爬图、界面两部分都设计好了,接下来考虑一下程序优化问题。
01
图片分批加载
由于图片的加载是在线程里面实现的,线程里面用一个“while True”循环,从队列中取出图片URL进行下载。我们需要一种能控制线程暂停的方式,来解决“分批加载”这个问题。
既然是线程相关,我们优先考虑一下threading模块里面有什么适合用的。查看文档发现,Event事件类比较适合这种使用场景。简单说,Event产生的实例对象可以存储一个标记,标记为False时,调用它的wait()方法可以进行阻塞等待,而标记为True时wait()方法不阻塞或者从阻塞中恢复。
为了方便,我们在MyMainWindow的初始化__init__()里面操作一下:
self.running_event = Event()
self.running_event.set() # 一开始不需要让线程等待,设置标志为True
然后在线程中加入等待的代码:
self.running_event.wait()
但这样子并不会自己自动产生阻塞,还需要写一段代码主动设置标志为False从而产生阻塞,于是在处理图片URL的线程中加入判断代码,如果达到批次数量时,就改变event的标志为False,这样当执行到wait()就会自动产生阻塞了,如下代码:
with self.data_lock:
… if len(self.data_list) % self.PAGE_LIMIT == 0:
… … self.running_event.clear()
最后在“加载下一批”的按钮中加入代码解除wait()阻塞即可:
self.running_event.set()
02
预览图加载小图、高斯模糊、居中显示
如果我们不清除列表控件中的图片,随着图片数量增加,内存占用会越来越高。不管Qt或者别的模块有没有对这些地方作出优化,我们在程序开发的时候都要保持着随时做优化的好习惯。
利用PIL模块,简单几行代码就可以把缩小图片、高斯模糊两种操作一起实现,先缩小再高斯模糊,在一般配置的机器上处理时间是非常短的。
考虑到预览小图的空间占用并不会太高,我们在产生小图的时候直接写入到BytesIO即字节内存IO中,让QIcon最终加载存在于内存中的字节数据即可。
关键代码如下:
# PIL打开图片
img = Image.open(file_name)
# 锁定长宽比缩小图片
w, h = img.size
ratio = self.PIC_SIZE / (h if h >= w else w)
img = img.resize((int(w * ratio), int(h * ratio)), Image.ANTIALIAS)
# 高斯模糊
img = img.filter(ImageFilter.GaussianBlur(radius=2))
# 暂存于内存中,使用BytesIO
bio = BytesIO()
img.save(bio, ‘jpeg’)
# 关闭PIL图像句柄
img.close()
# 从BytesIO加载图片数据
qimg = QImage.fromData(bio.getvalue())
# 关闭BytesIO句柄
bio.close()
限于篇幅,可以在下载项目代码后查看具体实现。
03
爬取到的图片文件名的命名
文章开头有一张保存的图片文件的截图,观察到所有图片文件都是从图片URL得到的原始文件名,乱七八糟的。我们可以利用网页上的标题文字来给图片文件重新命名。
这一个优化点作为扩展练习题吧。处理思路:引用原网页的img标签的alt属性文字(alt的值刚好是图片标题)即可,如图所示。同样也可以用XPath取出。

获取本项目请访问:
https://github.com/djun/PyQtPicsCrawler

以上就是“200行代码实现一个带界面的爬图小软件 - Python高手成长路(系列)”的全部内容,希望对你有所帮助。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、Python练习题
检查学习结果。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。
