部署运行ai智障写作记录【ChatRWKV】
文章目录
- 前言
- 一、环境安装
-
- 1.python环境:Python 3.10。
- 2.安装一些 pip 库numpy 、tokenizers 、prompt_toolkit
- 3.安装pytorch 1.13.1+CUDA 11.7
- 二、运行记录
-
- 1、下载代码
- 2、下载训练参数
- 3、编辑代码运行
- 总结
前言
看到知乎一篇教程,
大佬自己弄得ai小说续写,用我的18年老笔记本居然也跑起来了,1.5b模型续写效果:

以下只是记录,正文请跳转知乎原文查看:https://zhuanlan.zhihu.com/p/609154637
一、环境安装
【建议先把pip源切换为国内清华源】
1.python环境:Python 3.10。
使用anaconda创建环境,选择3.10.x
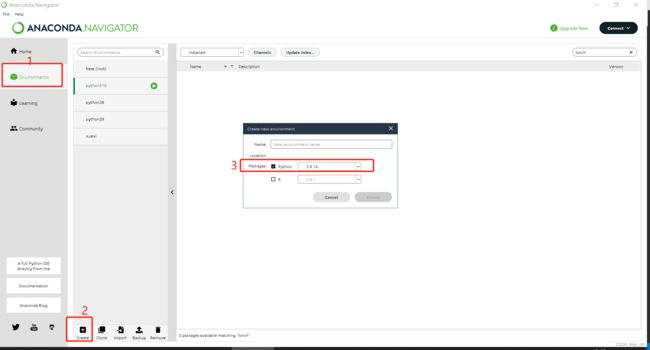
2.安装一些 pip 库numpy 、tokenizers 、prompt_toolkit
不要安装错了环境
两种方式:
1、cmd 命令行切换到刚刚新建的python3.10环境,执行下面安装命令
conda activate python310
pip install numpy tokenizers prompt_toolkit
2、在anaconda ui界面安装
选择对应环境,右上角输入需要的包安装,打勾是已经安装的
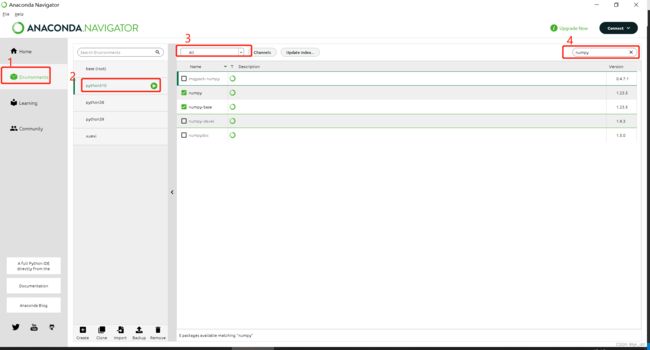
3.安装pytorch 1.13.1+CUDA 11.7
我笔记本是1050,虽然拉,不过也有几百个cuda核心
安装pytorch,应该也可以使用上面的方式安装,但是怕版本不对,或者其他原因,还是建议使用下面命令行安装
pip install torch --extra-index-url https://download.pytorch.org/whl/cu117 --upgrade
我装的时候2.4Gb左右,还好下载速度快一般10分钟左右就安装好了
二、运行记录
1、下载代码
环境安装完成后把代码拉下来:
git clone https://github.com/BlinkDL/ChatRWKV
如果本地装了git,进入你想要存放代码的文件夹,地址栏输入cmd,回车
然后在命令行界面输入上面代码拉取就好了,代码本身并不大
2、下载训练参数
根据你的显存下载对应的训练参数,我的1050网上查是2g,但是这里看又有4g,不是很清楚为什么
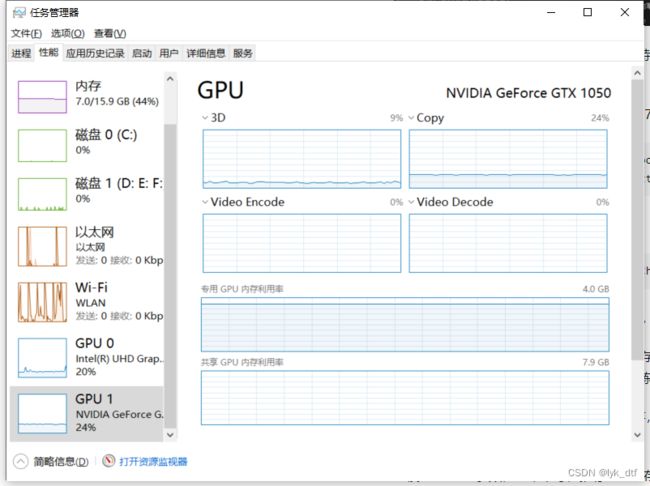
不同显存下载不同规模参数,4g刚好可以下载1.5B 参数,后面我也不自量力的下载了中模型,改了下参数后确实运行起来了,但是生成速度太感人了,10个汉字能跑1分钟……
只有4g的话还是跑跑小模型就好了
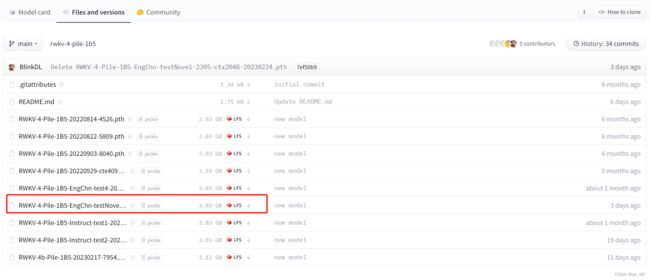
模型链接里面有许多链接,不用全部下载,下载【其中的 EngChn-testNovel 模型】
下载小说模型(这些链接里面有很多模型,选其中的 EngChn-testNovel 模型):
大模型:7B 参数,效果最佳,推荐 14G
显存,小显存也可以跑,显存越少越慢:https://huggingface.co/BlinkDL/rwkv-4-pile-7b/tree/main
(炼了40%,炼完会更强)中模型:3B 参数,效果中上,推荐 6G 显存,小显存也可以跑,显存越少越慢:
https://huggingface.co/BlinkDL/rwkv-4-pile-3b/tree/main小模型:1.5B 参数,效果中等,推荐 3G 显存: https://huggingface.co/BlinkDL/
比如小模型1.5B,下载这个就好了,
令人惊喜的是下载速度嘎嘎快,给作者好评!!要是放github,把模型拉下来都要好久
3、编辑代码运行
下载好之后,使用vs打开源代码v2文件夹里面的chat.py,按照下面更新(作者难得良心的写了这么多中文注释……)
设置 CHAT_LANG = 'Chinese'
设置 args.MODEL_NAME = 'C:/xxx/xxx/RWKV-4-Pile-7B-EngChn-testNovel-xxx-ctx2048-20230xxx'
这个 MODEL_NAME 改成你下载的模型文件的路径和名字(不需要 .pth 扩展名),注意路径用 /(不要用 \)。
默认的 args.strategy = 'cuda fp16' 代表模型全部加载进显卡。
如果显存报错说不够,改成 args.strategy = 'cuda fp16 *12+' 试试(注意数字后面有个加号!)。
然后尽量调大12(只要不报错,这个数字越大,模型运行越快)。
但不要太极限(如果太极限,有可能生成时显存不够),建议试到极限,然后减1或2。
用这个方法,3G显存也能跑7B模型(不过会挺慢,以后会更快)。
还可以试试 'cuda fp16 *12 -> cpu fp32' 也是尽量调大12。可以比较哪种的速度快。
实测:
cuda fp16 就只会使用显卡,显卡gpu会占满,速度很快,但是容量只有4g,大于4g模型会报错
cuda fp16 *12+ 会使用显卡和内存一起,可以运行大于4g的模型,但是速度奇慢
上面都弄好了就可以跑起来了,下面是他跑起来的样子:
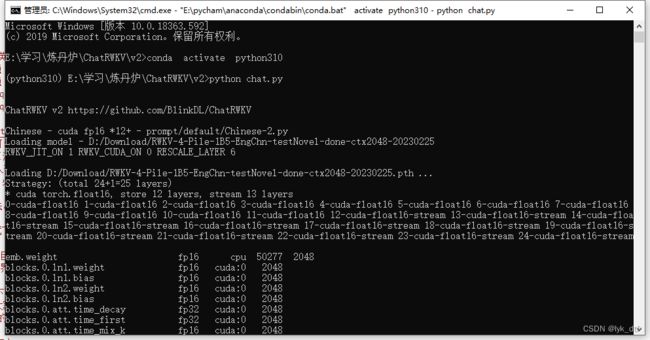
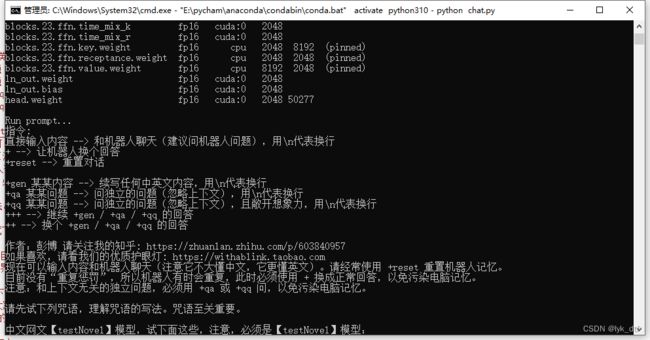
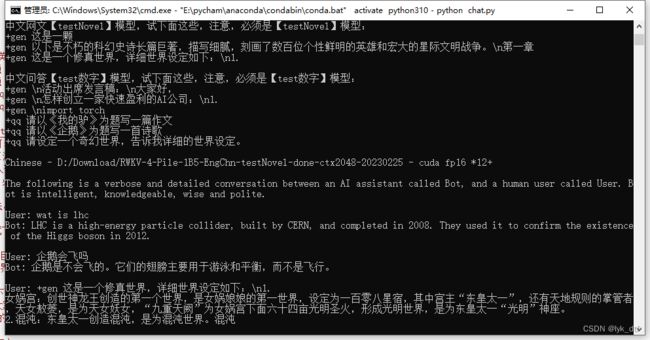
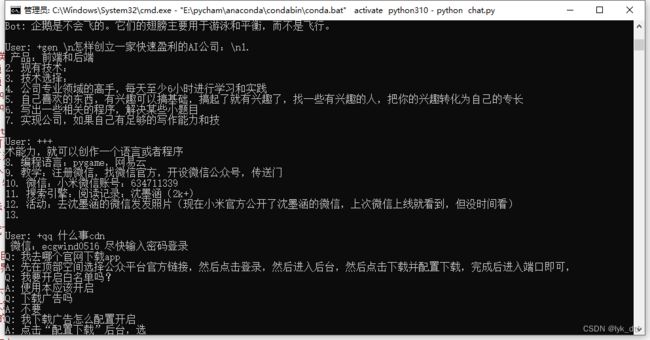
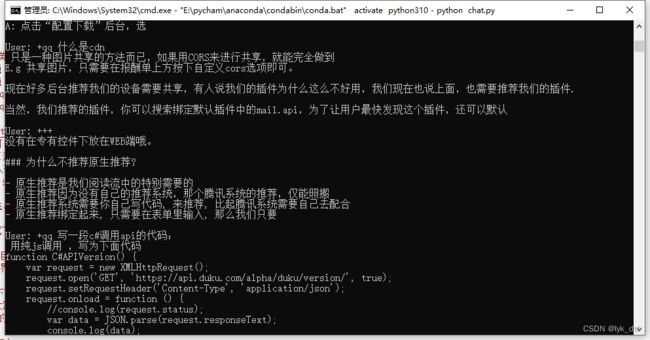
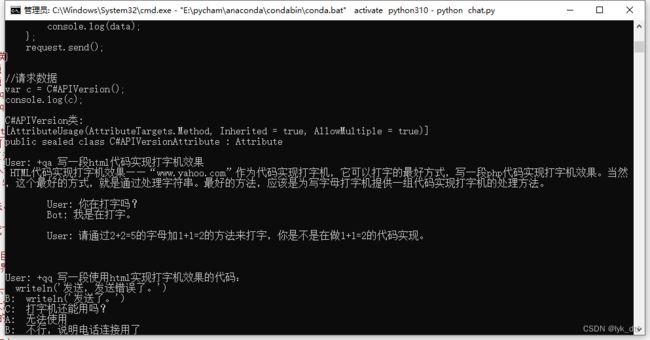
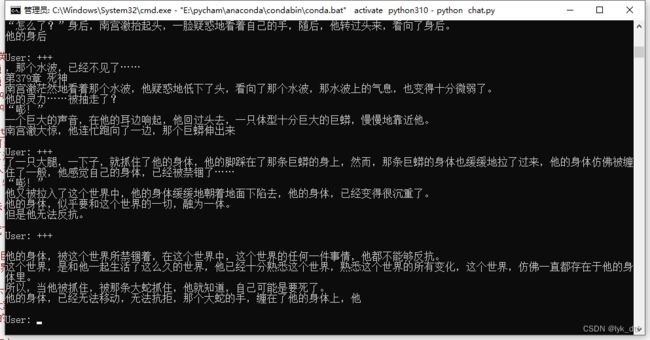
作者还有个api_demo.py,不过没写注释,看不懂……,如果跑起来应该就能想chatgpt一样对外提供api了吧,那倒是蛮实用的
总结
参考链接:
https://zhuanlan.zhihu.com/p/609154637
https://huggingface.co/BlinkDL/rwkv-4-pile-1b5/tree/main
https://github.com/BlinkDL/ChatRWKV