近期,几个典型 Elasticsearch 8.X 问题及方案探讨
问题1:max_expansions 设置大了会报错,什么原因?
大佬们问个问题,我在使用match_phrase_prefix时候,设置了一个比较大的max_expansions,比如10000。
这个时候会报错:too_many_clauses: maxClauseCount is set to 1024。我搜了下 maxClauseCount 这是控制搜索条件数量的,但我这只是改了个 max_expansions 就这样了,这2者有什么联系呀?
根本原因:
如果你设置了一个很高的值( 10000),Elasticsearch 会尝试生成所有可能的匹配项,直到达到这个限制。
而进行 match_phrase_prefix 查询时,每个可能的匹配项都会被视为一个子句。
如果生成的匹配项数量超过 maxClauseCount 的限制,就会出现 too_many_clauses 错误。
可行的解决方案:
选择一个更合理的 max_expansions 值,以保持生成的查询子句数量在 maxClauseCount 的限制范围内。
问题2:集群数据迁移能不能直接拷贝文件?
各位大佬,同版本的es集群间数据迁移,假设两个集群节点数相同,是不是可以通过直接拷贝数据文件来进行啊?
去年年底咱们就讨论过:腊月27日凌晨的一个紧急 Elasticsearch 线上问题复盘
一句话,非必要不要直接拷贝文件。
官方文档在集群备份部分有过强调如下:
you cannot back up an Elasticsearch cluster by making copies of the data directories of its nodes. There are no supported methods to restore any data from a filesystem-level backup. If you try to restore a cluster from such a backup, it may fail with reports of corruption or missing files or other data inconsistencies, or it may appear to have succeeded having silently lost some of your data.
中文释义:
你无法通过复制其节点的数据目录来备份 Elasticsearch 集群。
不支持从文件系统级备份恢复任何数据的方法。
如果你尝试从此类备份恢复集群,则可能会失败,并报告损坏或丢失文件或其他数据不一致的情况,或者可能看似已成功,但悄无声息地丢失了一些数据。
https://discuss.elastic.co/t/why-are-we-told-to-copy-the-data-folder-when-upgrading/168951
https://www.elastic.co/guide/en/elasticsearch/reference/current/snapshot-restore.html
问题3:全局超时如何设置?
除了每个search可以配置自己的timeout,集群有没有参数可以配置一个统一的timeout,针对所有search都生效额?
建议:看看这个参数: search.default_search_timeout。
To set a cluster-wide default timeout for all search requests, configure search.default_search_timeout using the cluster settings API. This global timeout duration is used if no timeout argument is passed in the request. If the global search timeout expires before the search request finishes, the request is cancelled using task cancellation. The search.default_search_timeout setting defaults to -1 (no timeout).
集群层面设置解决方案如下:

PUT /_cluster/settings
{
"persistent": {
"search.default_search_timeout": "30s"
}
}要为所有搜索请求设置集群范围内的默认超时时间,可以使用集群设置 API 配置 search.default_search_timeout。
如果请求中没有传递超时参数,则使用这个全局超时持续时间。
如果全局搜索超时在搜索请求完成之前到期,请求将通过任务取消被取消。
search.default_search_timeout 设置的默认值为 -1(无超时)。
https://www.elastic.co/guide/en/elasticsearch/reference/8.12/search-your-data.html#search-timeout
问题4:自定义ID如何自动设置为 MD5呢?
铭毅老师你好,想请问一下,往es索引里面插入文档分为指定文档id和自动生成文档id,目前有一个需求在插入文档的时候,将文档的id值取插入的文档中的一个字段。
比如我插入的是一个关于文件的相关信息的文档,字段有md5值,大小,文件类型等等信息,此时我希望插入的这个文档的ID是这个文件的md5值, 不太明白怎么设置这样的关系,谢谢!
题目来源:https://t.zsxq.com/16mobA3PV
实践参考:
Elasticsearch “指纹”去重机制,你实践中用到了吗?
方案:
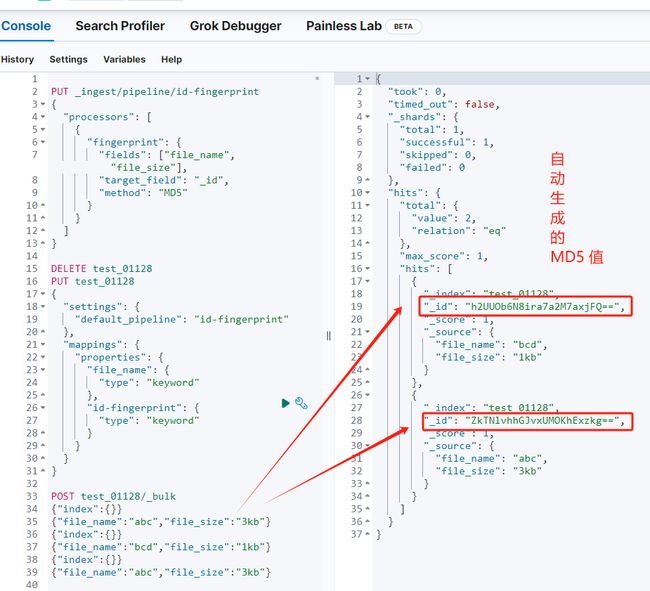
使用 fingerprint 预处理器,借助已有的多个字段构建 MD5值,然后将目标字段设置为 _id 即可。
PUT _ingest/pipeline/id-fingerprint
{
"processors": [
{
"fingerprint": {
"fields": ["file_name", "file_size"],
"target_field": "_id",
"method": "MD5"
}
}
]
}
DELETE test_01128
PUT test_01128
{
"settings": {
"default_pipeline": "id-fingerprint"
},
"mappings": {
"properties": {
"file_name": {
"type": "keyword"
},
"id-fingerprint": {
"type": "keyword"
}
}
}
}
POST test_01128/_bulk
{"index":{}}
{"file_name":"abc","file_size":"3kb"}
{"index":{}}
{"file_name":"bcd","file_size":"1kb"}
{"index":{}}
{"file_name":"abc","file_size":"3kb"}小结
以上都是实战环境遇到的典型问题,如果你也有类似问题,欢迎发出来,咱们一起讨论解决!
7 年+积累、 Elastic 创始人Shay Banon 等 15 位专家推荐的 Elasticsearch 8.X新书已上线

更短时间更快习得更多干货!
和全球 近2000+ Elastic 爱好者一起精进!

比同事抢先一步学习进阶干货!