2024-01-31(MapReduce,YARN)
1.MapReduce --- 分布式计算框架
MapReduce是分散--->汇总模式的分布式框架,可以供开发人员开发相关程序进行分布式数据计算
MapReduce提供了2个编程接口:Map接口,Reduce接口
其中,Map接口提供了“分散”功能,由服务器分布式对数据进行处理;Reduce提供了“汇总”功能将分布式的处理结果汇总统计。
程序员如果需要使用MapReduce框架完成自定义需求的c程序开发,只需要使用java,Python等语言实现MapReduce中的两个接口即可。(但现在没人写了,过时)
2.MapReduce的运行机制:
将要执行的需求,分解为多个Map Task和Reduce Task,然后将Map Task
3.YARN概述(分布式资源调度组件):
资源:服务器的硬件资源,CPU,内存,硬盘,网络等。
资源调度:管控服务器的硬件资源,提供更好的利用率。
分布式资源调度:管控整个分布式服务器集群的全部资源,整合进行统一调度。
4.YARN架构:主从架构,两种角色
主角色(Master):ResourceManager,整个集群的资源调度者,负责协调各个程序所需资源。
从角色(Slave):NodeManager,单个服务器的资源调度者,管理分配单个服务器的资源,即创建管理容器,由容器提供资源供程序使用。
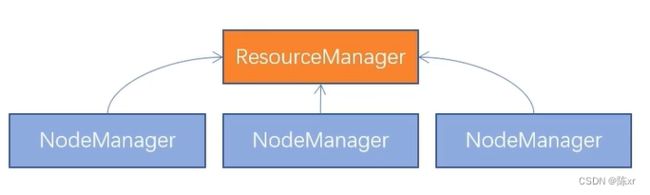
大致流程:
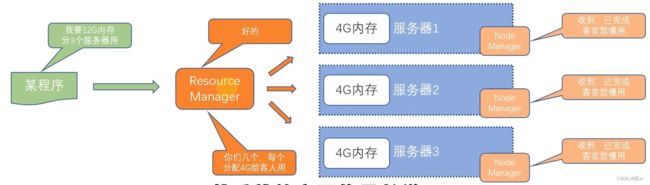
5.YARN容器
容器(Container)是YARN的NodeManager在所属服务器上分配资源的手段。创建一个资源容器,即由NodeManager占用这部分资源,然后应用程序运行在NodeManager创建的这个容器内部,应用程序无法突破容器的资源限制。
6.YARN的辅助角色
YARN架构中除了核心角色(ResourceManager,NodeManager),还可以搭配两个辅助角色使得YARN运行的更加稳定:
代理服务器:减少对YARN的网络攻击
历史服务器:记录历史运行的程序信息以及产生的日志并提供WEB UI站点供用户使用浏览器查看
7.Apache Hive(分布式SQL计算平台)
SQL语句用来做统计分析很方便,相比于Java和Python语言。
但是MapReduce只支持java和python,不支持sql。因此出现了Apache Hive,简单来说它的作用就是将SQL语句翻译成MapReduce程序来运行。
8.为什么要使用Hive
使用Hadoop 的 MapReduce直接处理数据所面临的问题:
1)学习Java,python等编程语言成本高
2)MapReduce实现复杂的查询逻辑开发难度比较大
使用Hive来处理数据的好处
1)操作接口采用类SQL语法,提供快速开发的能力(简单)
2)底层执行MapReduce,可以完成分布式海量数据的SQL处理。
9.基于MapReduce构建分布式SQL执行引擎,主要需要组件:
元数据管理
SQL解析器
10.Hive基础架构
元数据存储:通常是存储在关系数据库如mysql/derby中。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性,表的数据所在目录等。Hive提供了Metastore服务进程来提供元数据管理的功能。
SQL解析器(Driver驱动程序):完成SQL解析,执行优化,代码提交等功能。
用户接口:提供用户和Hive交互的功能。