基于机器学习的物流预测可视化(附源码)
物流行业数据分析简介
物流行业是指负责货物运输、仓储、配送等环节的相关产业。随着互联网和电子商务的发展,物流行业正面临着巨大的变革和机遇。数据分析在物流行业中起着重要的作用,可以帮助企业更好地理解和优化其供应链、运输和仓储管理等方面的运营。
物流行业数据分析涉略内容
运输效率分析:通过对运输网络、路线和调度等数据进行分析,可以评估和改进物流运输的效率和成本。例如,利用运输数据分析可以确定最佳路线、提高装载率、降低运输时间等,从而优化整体运输效率。
仓储优化:通过对仓库操作和存储数据的分析,可以实现仓储设备的合理配置和库存管理的优化。例如,通过数据分析可以确定最佳库存水平、合理布局仓库以及预测需求,并提供仓储容量和资源的最佳规划。
供应链可视化:通过整合和分析供应链各环节的数据,可以建立供应链可视化系统,实时跟踪和监控供应链运作情况。这有助于提高供应链的协调性和可靠性,并及时发现潜在的问题和风险。
客户需求分析:通过对客户订单、投诉、反馈等数据进行分析,可以了解客户需求和偏好,从而优化物流服务。例如,根据数据分析结果,企业可以推出个性化的配送方案,提供更准确的送货时间和更满意的服务体验。
风险管理与预测:通过对历史和实时的物流数据进行分析,可以识别和评估潜在的运营风险,并进行风险预测和应对策略制定。这有助于降低物流成本、避免事故和延误等不可控因素对供应链的影响。
目录
一.数据来源
某企业销售的6种商品所对应的送货及用户反馈数据:
二.解决问题
1、配送服务是否存在问题
2、是否存在尚有潜力的销售区域
3、商品是否存在质量问题
三.解决方法
(一).常规Python数据分析可视化
1、分析前提
(1)导入所需要的包
(2)读取数据
(3)数据清洗
(4)异常值处理
(5)数据规整
a.增加一项辅助列:月份
b.查看规整后的数据
2、数据分析&可视化
(1)配送服务是否存在问题——按时交货率
a.月份维度分析——按时交货率
b.销售区域维度分析按时交货率
c.货品维度分析按时交货率
d.货品和销售区域结合分析按时交货率
(2)是否存在尚有潜力的销售区域——货品的销售数量
a.月份维度分析货品销售数量
b.销售区域维度分析货品销售数量
c.月份和销售区域结合分析货品销售数量
(3)商品是否存在质量问题——货品用户反馈
a.月份维度分析货品用户反馈
b.销售区域维度分析货品用户反馈
c.从货品和销售区域维度进行分析
(4)总结
(二).机器学习分析
1、分析前提
(1)导入所需要的包
(2)读取数据
(3)数据清洗
(4)异常值处理
(5)数据规整
a.增加一项辅助列:月份
b.查看规整后的数据
2、数据分析
(1)配送服务是否存在问题?
(2)是否存在尚有潜力的销售区域?
(3)商品是否存在质量问题?
3、总结
四.项目特色
1、参数优化:通过对参数的优化实现对数据的优化处理
2、数据分析:从数据分析可视化角度解决三个问题
3、机器学习:从机器学习的角度分析处理问题,通过准确率判断问题并提出解决方法
4、方法多元化:综合使用逻辑回归、随机森林、K-Means聚类算法、SVM等算法
五.分析结论
1、数据分析可视化得出结论:
(1)货品4—>西北,货品2—>马来西亚两条路线存在较大问题,急需提升时效;
(2)货品2在华东地区还有较大市场空间,适合加大投入,同时货品2在马来西亚配送时效长,用户拒收率高,从成本角度考虑,应该减少投入;
(3)货品1、2、4质量存在问题,建议扩大抽检范围,增大质检力度。
2、机器学习分析得出结论:
(1)配送服务整体比较正常,不存在特别大的问题;
(2)存在尚有潜力的销售区域,分别是华北、华南和西北;
(3)商品存在质量问题,建议扩大抽检范围,增大质检力度。
一.数据来源
某企业销售的6种商品所对应的送货及用户反馈数据:
【金山文档】 data_wuliu
https://kdocs.cn/l/cjo40kBYVY9M
二.解决问题
1、配送服务是否存在问题
2、是否存在尚有潜力的销售区域
3、商品是否存在质量问题
三.解决方法
(一).常规Python数据分析可视化
1、分析前提
(1)导入所需要的包
import matplotlib.pyplot as plt
from pylab import mpl
import pandas as pd
import warnings
# 忽略警告信息,警告非报错,不影响代码执行
warnings.filterwarnings("ignore")(2)读取数据
data = pd.read_csv('data_wuliu.csv', encoding='gbk')
data.info()
通过info()可以看出,包含10列数据,名字,数据量,数据类型等,可以得出
1.订单号、货品交货状况、数量:存在缺失值,但是缺失量不大,可以删除
2.订单行,对分析无关紧要,没有实质意义,可以考虑删除
3.销售金额格式有问题(万元|元,逗号问题),数据类型需要转换为int|float
(3)数据清洗
# 删除重复记录,遇到重复保留第一行,删除后代替源数据
data.drop_duplicates(keep='first', inplace=True)
# 删除缺失值(有na的整行数据,axis=0,how='any'默认)
data.dropna(axis=0, how='any', inplace=True)
# 删除‘订单行’这一列,第二次运行删除操作会报错
data.drop(columns=['订单行'], inplace=True, axis=1)
# 更新索引:drop=True:把原来的索引index列删除,重置index,原来的索引因为删除了行数据变乱
data.reset_index(drop=True, inplace=True)
data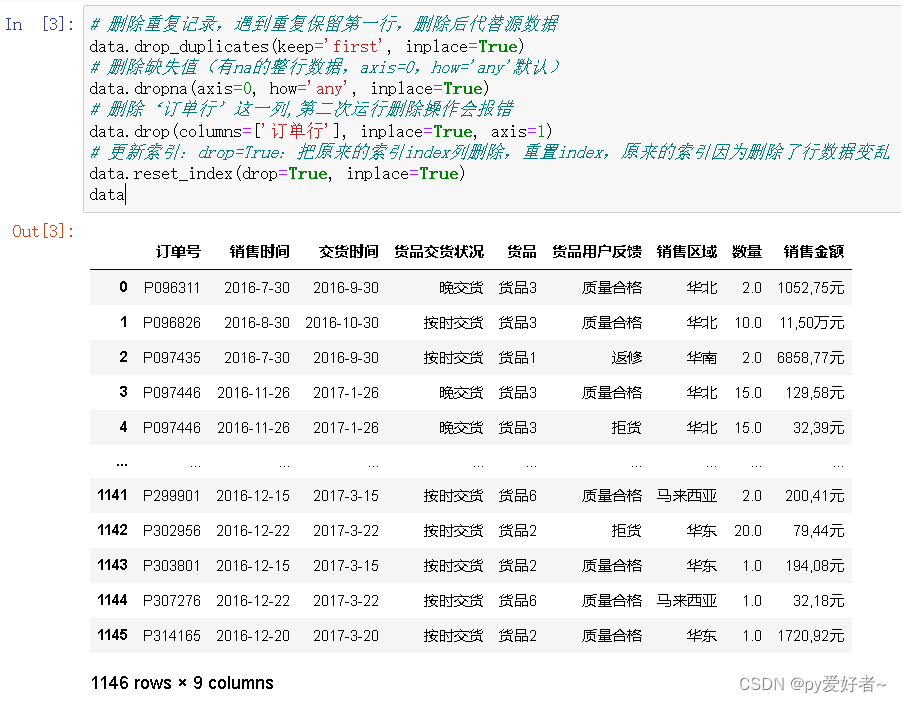
# 取出‘销售金额’列,对每个数据进行清洗,自定义map函数处理万元|元
# 编写自定义过滤函数:1.删除逗号,2.转成float:如果是万元则删除万元再*10000,否则,删除元
def data_deal(number):
# 找到带有万元的,取出数字,去掉逗号,转成float,*10000
if number.find('万元') != -1:
# number[:number.find('万元')]去掉万元
# number[:number.find('万元')].replace(',','')将逗号替换为空
number_new = float(number[:number.find('万元')].replace(',','')) * 10000
pass
else: #找到带有元的,删除元,删除逗号,转成float
if number.find('元') != -1:
number_new = float(number.replace('元','').replace(',',''))
pass
return number_new
data['销售金额'] = data['销售金额'].map(data_deal)
data
(4)异常值处理
data.describe()
销售金额最小值为0,有异常值
# 销售金额==0,采用删除方法,因为数据量很小
data = data[data['销售金额'] != 0]
data.describe()
(5)数据规整
a.增加一项辅助列:月份
配送服务是否存在问题——每个月配送服务的满意度
是否存在尚有潜力的销售区域——根据月份绘制本月销售量的图,看月份和销售量的关系
在数据中,从销售时间里提取月份,两种方法:
1.字符串截取:substr(data['销售时间',6,2])
2.将该列转化为datetime格式,直接month提取月份
data.loc[:, '销售时间'] = pd.to_datetime(data['销售时间'])
data.loc[:, '月份'] = data['销售时间'].apply(lambda x: x.month)
data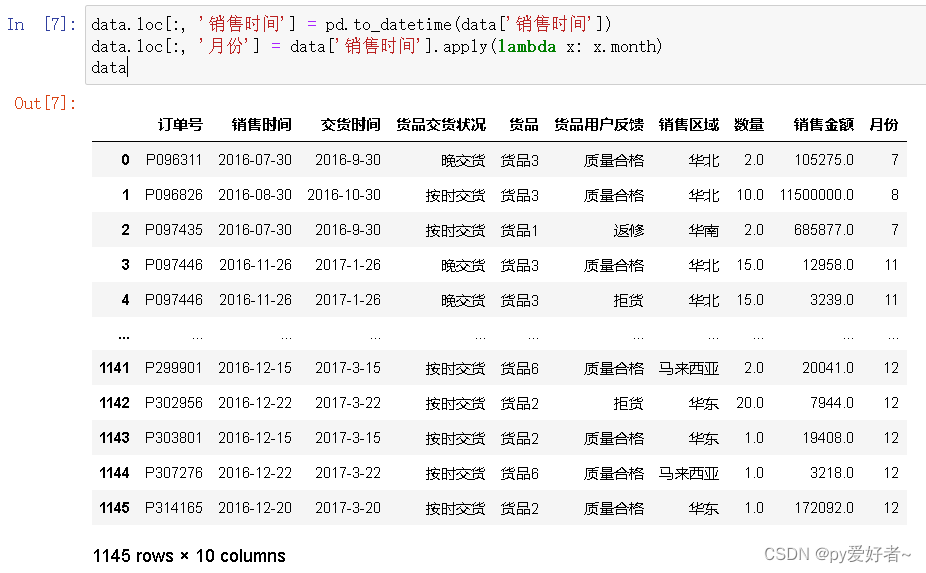
b.查看规整后的数据
data.head()
2、数据分析&可视化
(1)配送服务是否存在问题——按时交货率
- 月份维度
- 销售区域维度
- 货品维度
- 货品和销售区域维度
a.月份维度分析——按时交货率
# # 设置显示中文字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# # 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
data
# 有的‘货品交货状况’内容,开头含有空格,需要删除首位空格 **.strip()**
data1 = data
data1.loc[:, '货品交货状况'] = data1['货品交货状况'].str.strip()
# 按月份和货币交货状况分类,.size()计算数量
# .unstack() 可以使输出表格更直观,方便后面计算
data1 = data1.groupby(['月份','货品交货状况']).size().unstack()
data1['按时交货率'] = data1['按时交货'] / (data1['按时交货']+data1['晚交货'])
data1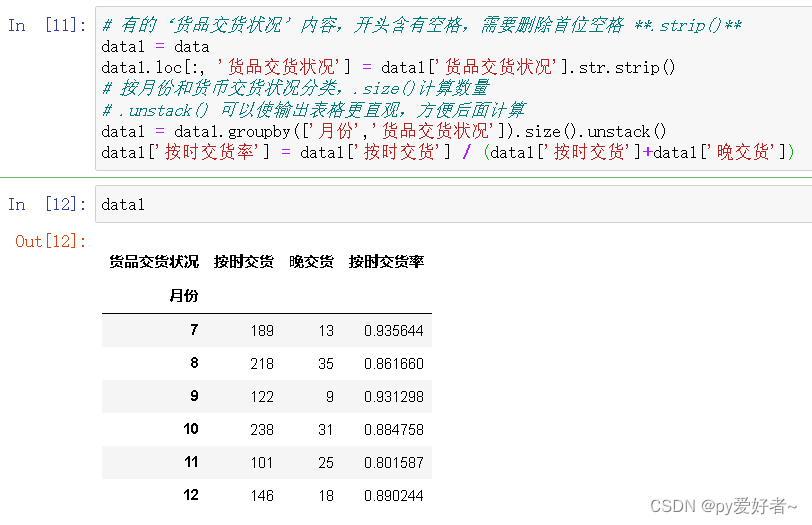
data_1 = data1['按时交货率']
# 柱状图分析对比
data_1.plot(kind='bar', width=0.5, color='c')
plt.title("各月份按时交货率对比图")
plt.ylabel("按时交货率")
# 添加网格显示
plt.grid(True, linestyle="--", alpha=0.3)
# 显示图形
plt.show()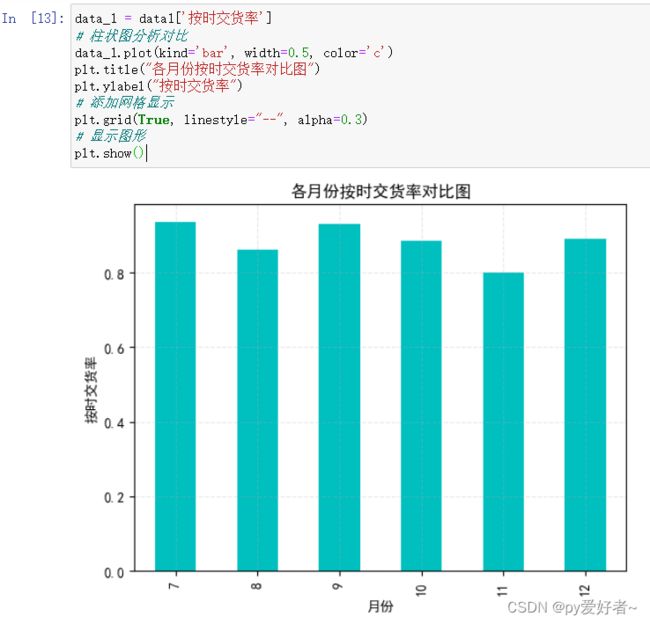
- 分析结果:从按时交货率来看,第四季度低于第三季度,猜测可能是气候原因造成的
b.销售区域维度分析按时交货率
data2 = data.groupby(['销售区域','货品交货状况']).size().unstack()
data2['按时交货率'] = data2['按时交货'] / (data2['按时交货'] + data2['晚交货'])
data2.sort_values(by='按时交货率', ascending=False)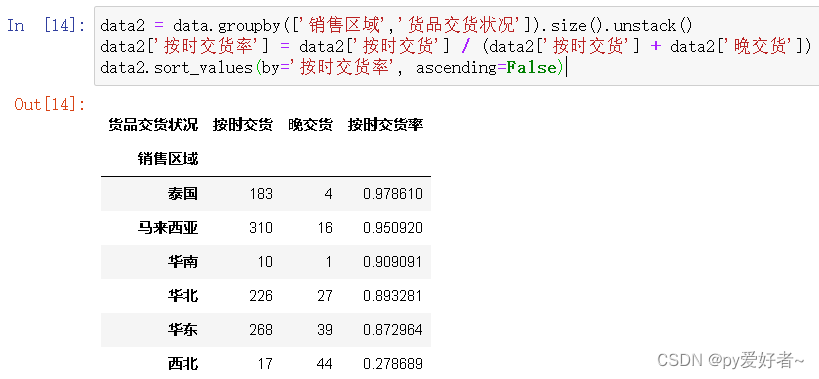
data_2 = data2['按时交货率']
# 柱状图分析对比
data_2.plot(kind='bar', width=0.5, color='m')
plt.title("各销售区域按时交货率对比图")
plt.ylabel("按时交货率")
# 添加网格显示
plt.grid(True, linestyle="--", alpha=0.3)
# 显示图形
plt.show()
- 分析结果:西北存在严重的延时交货问题,急需解决
c.货品维度分析按时交货率
data3 = data.groupby(['货品', '货品交货状况']).size().unstack()
data3['按时交货率'] = data3['按时交货'] / (data3['按时交货'] + data3['晚交货'])
data3.sort_values(by='按时交货率', ascending=False)
data_3 = data3['按时交货率']
# 柱状图分析对比
data_3.plot(kind='bar', width=0.5, color='b')
plt.title("各类货品按时交货率对比图")
plt.ylabel("按时交货率")
# 添加网格显示
plt.grid(True, linestyle="--", alpha=0.3)
# 显示图形
plt.show()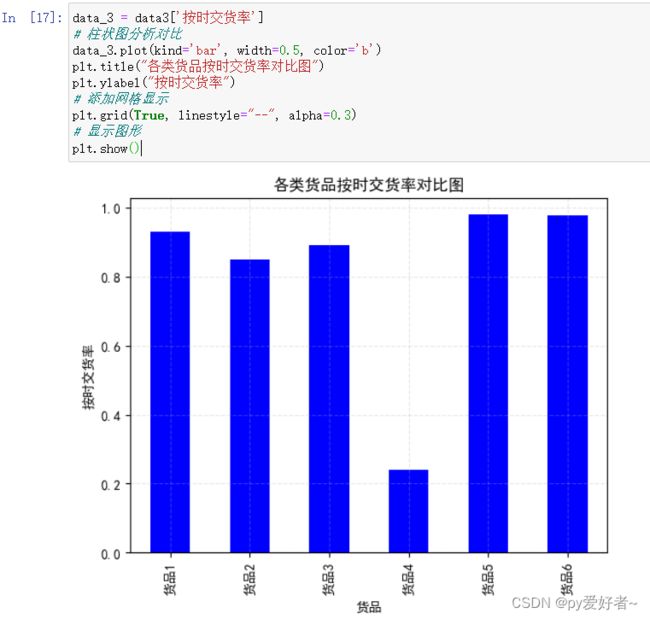
- 分析结果:货品4晚交货非常严重,其余货品相对正常
d.货品和销售区域结合分析按时交货率
data4 = data.groupby(['货品', '销售区域', '货品交货状况']).size().unstack()
data4['按时交货率'] = data4['按时交货'] / (data4['按时交货'] + data4['晚交货'])
data4.sort_values(by='按时交货率', ascending=False)
data_4 = data4['按时交货率']
# 柱状图分析对比
data_4.plot(kind='barh', width=0.5, color='y')
plt.title("各类货品在各自销售区域按时交货率对比图")
plt.xlabel("按时交货率")
plt.ylabel("货品及对应的销售区域")
# 添加网格显示
plt.grid(True, linestyle="--", alpha=0.3)
# 显示图形
plt.show()
- 分析结果:
- 销售区域:最差在西北地区,货品有1和4,主要是货品4送货过晚导致的;
- 货品角度:最差的是货品2,主要送往华东和马来西亚,主要是马来西亚的送货过晚导致的。
(2)是否存在尚有潜力的销售区域——货品的销售数量
- 月份维度
- 销售区域维度
- 月份和销售区域维度
a.月份维度分析货品销售数量
- 每个月,每个商品的销售情况
data5 = data.groupby(['月份','货品'])['数量'].sum().unstack()
data5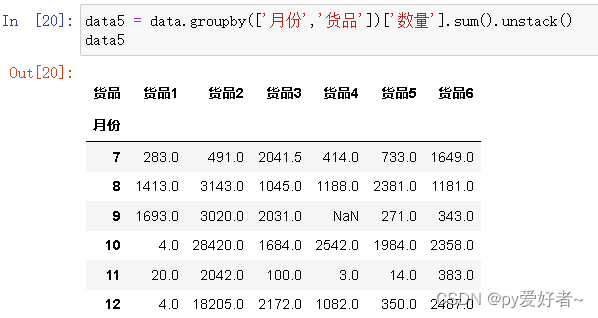
# 1.创建画布
plt.figure(figsize=(20,8), dpi=100)
# 2.向画布绘制内容
# 2.1 添加描述信息
data5.plot(kind='line')
plt.title("各月份各个货品的销量趋势图")
plt.ylabel("销量")
# 2.2 添加网格显示
plt.grid(True, linestyle="--", alpha=0.3)
# 3. 显示图形
plt.show()
- 结果分析:货品2在9-10月和11-12月份,销量猛增。
- 原因猜测有二:
- 1.公司加大营销力度
- 2.开发了新的市场
b.销售区域维度分析货品销售数量
data6 = data.groupby(['销售区域', '货品'])['数量'].sum().unstack()
data6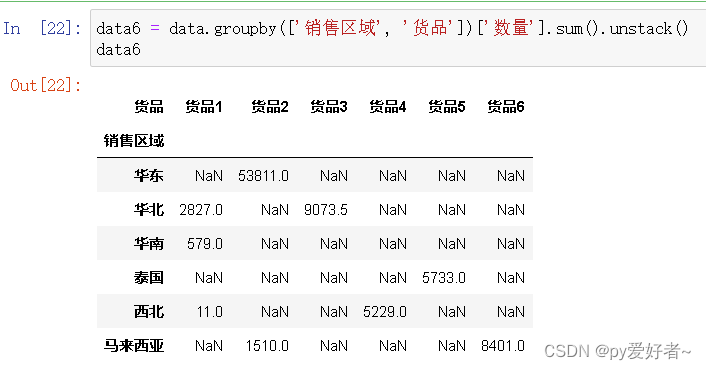
# 1.创建画布
plt.figure(figsize=(20,8), dpi=100)
# 2.向画布绘制内容
# 2.1 添加描述信息
data6.plot(kind='barh')
plt.title("各类货品在各销售区域的销量对比图")
plt.xlabel("销量")
plt.ylabel("销售区域")
# 2.2 添加网格显示
plt.grid(True, linestyle="--", alpha=0.3)
# 3. 显示图形
plt.show()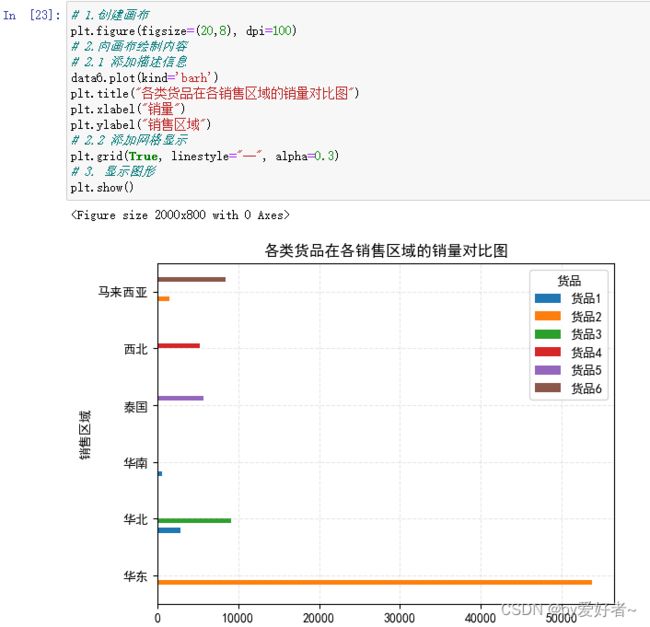
- 结果分析:
- 从销售区域看,每种货品销售区域为1~3个,货品1有3个销售区域,货品2有两个销售区域
- 其余货品均有1个销售区域
c.月份和销售区域结合分析货品销售数量
data7 = data.groupby(['月份', '销售区域', '货品'])['数量'].sum().unstack()
data7
data7['货品2'].unstack()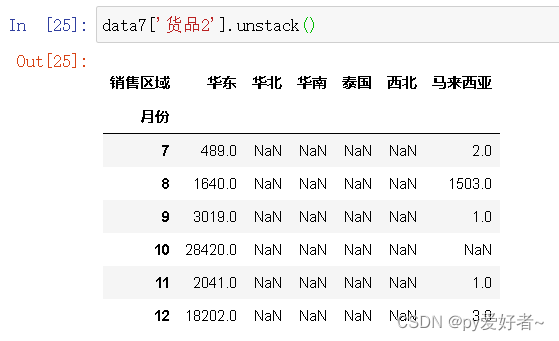
data_7 = data7['货品2'].unstack()
data_7 = data_7[['华东','马来西亚']]
data_7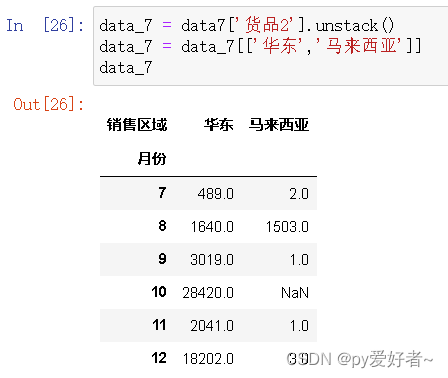
# 1.创建画布
plt.figure(figsize=(20,8), dpi=100)
# 2.向画布绘制内容
# 2.1 添加描述信息
data_7.plot(kind='line')
plt.title("货品2在华东和马来西亚两个销售区域的销量趋势图")
plt.ylabel("销量")
# 2.2 添加网格显示
plt.grid(True, linestyle="--", alpha=0.3)
# 3. 显示图形
plt.show()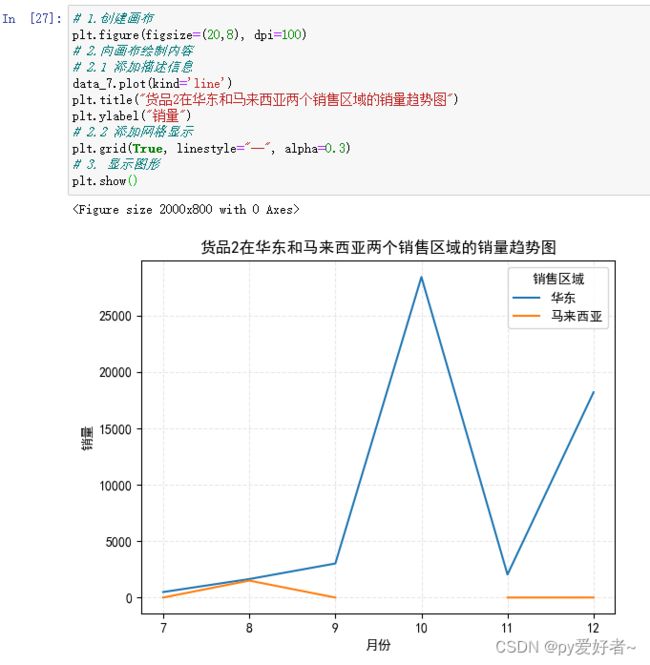
- 结果分析:
- 货品2在10、12月份销量猛增,原因主要发生在原有销售区域;
- 货品2在7、8、9、11月份销售数量还有很大提升空间,可以适当加大营销力度;
- 货品2在8月份在两个销售区域的销量均有提升,在马来西亚地区的涨幅更大,可以尝试继续在马来西亚增大营销力度。
(3)商品是否存在质量问题——货品用户反馈
- 月份维度
- 销售区域维度
- 货品和销售区域维度
a.月份维度分析货品用户反馈
data8 = data.groupby(['月份','货品用户反馈']).size().unstack()
data8
data8['拒货率'] = data8['拒货'] / data8.sum(axis=1)
data8['返修率'] = data8['返修'] / data8.sum(axis=1)
data8['合格率'] = data8['质量合格'] / data8.sum(axis=1)
data8[['合格率', '返修率', '拒货率']]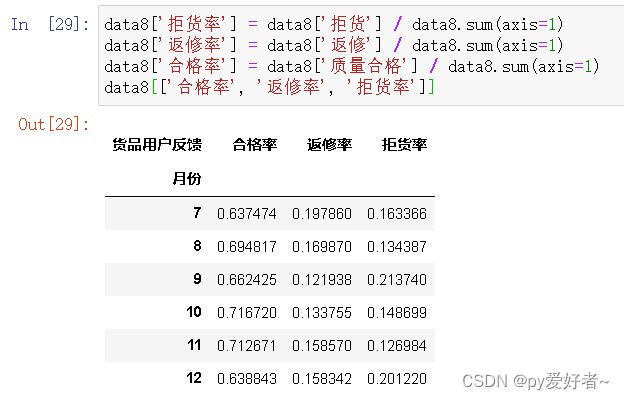
# 1.创建画布
plt.figure(figsize=(20,8), dpi=100)
# 2.向画布绘制内容
# 2.1 添加描述信息
data8[['合格率', '返修率', '拒货率']].plot(kind='line')
plt.title("每月货品用户反馈变化图")
plt.ylabel("比率")
# 2.2 添加网格显示
plt.grid(True, linestyle="--", alpha=0.3)
# 3. 显示图形
plt.show()
- 结果分析:
- 8-9月和11-12月拒货率呈上升趋势,且在8-10月拒货率较高,可能是气候原因造成
b.销售区域维度分析货品用户反馈
data9 = data.groupby(['销售区域','货品用户反馈']).size().unstack()
data9
# 1.创建画布
plt.figure(figsize=(20,8), dpi=100)
# 2.向画布绘制内容
# 2.1 添加描述信息
data9.plot(kind='bar')
plt.title("各销售区域货品用户反馈对比图")
plt.ylabel("数量")
# 2.2 添加网格显示
plt.grid(True, linestyle="--", alpha=0.3)
# 3. 显示图形
plt.show()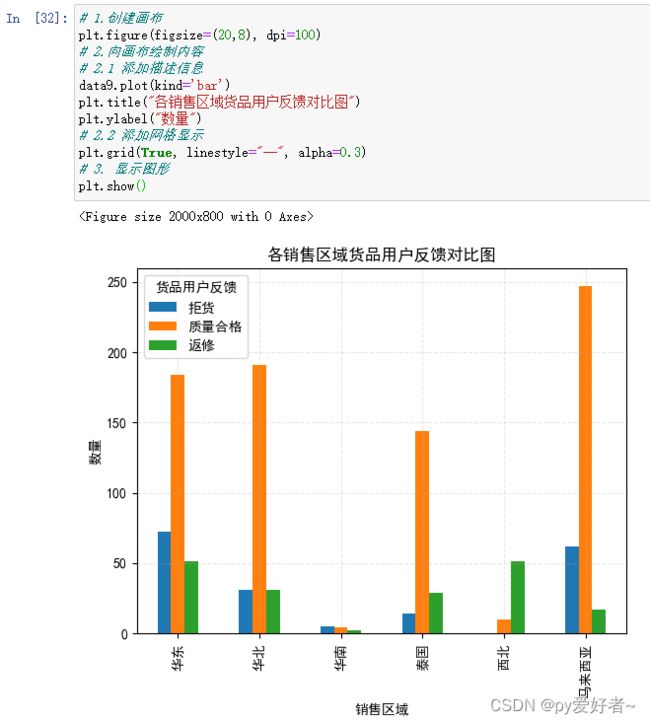
- 结果分析:
- 送往华东、华北和马来西亚的货品合格数量较多,特别是送往马来西亚的,建议继续保持;
- 送往泰国和西北的货品返修数量较多;
- 送往华东和马来西亚的货品拒货数量较多
c.从货品和销售区域维度进行分析
# 取出首位空格
data10 = data
data10.loc[:, '货品用户反馈'] = data10['货品用户反馈'].str.strip()
data10['货品用户反馈']
data10 = data.groupby(['货品', '销售区域'])['货品用户反馈'].value_counts().unstack()
data10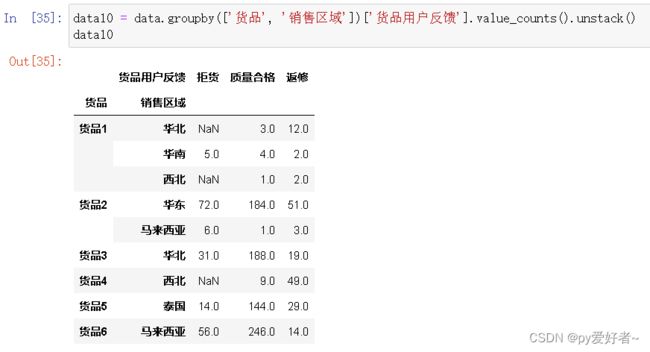
# 计算拒收率
#按行进行求和汇总
data10['拒货率'] = data10['拒货'] / data10.sum(axis=1)
data10['返修率'] = data10['返修'] / data10.sum(axis=1)
data10['合格率'] = data10['质量合格'] / data10.sum(axis=1)
data10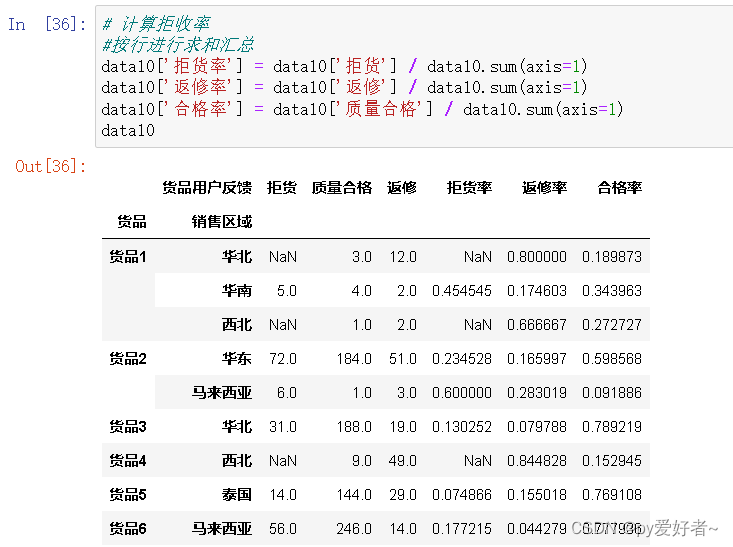
data10[['合格率', '返修率', '拒货率']]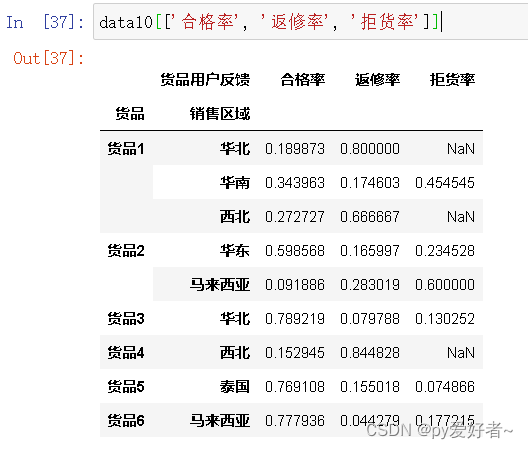
#先按合格率排序,再按返修率,拒货率; 降序排序
data10[['合格率', '返修率', '拒货率']].sort_values(['合格率', '返修率', '拒货率'], ascending=False)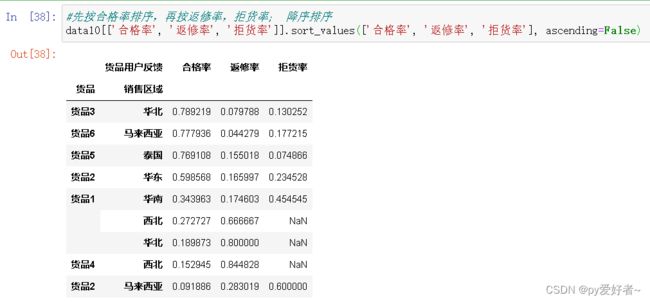
# 1.创建画布
plt.figure(figsize=(20,8), dpi=100)
# 2.向画布绘制内容
# 2.1 添加描述信息
data10[['合格率', '返修率', '拒货率']].plot(kind='barh')
plt.title("各类货品在各自销售区域的货品用户反馈对比图")
plt.xlabel("比率")
plt.ylabel("货品及对应销售区域")
# 2.2 添加网格显示
plt.grid(True, linestyle="--", alpha=0.3)
# 3. 显示图形
plt.show()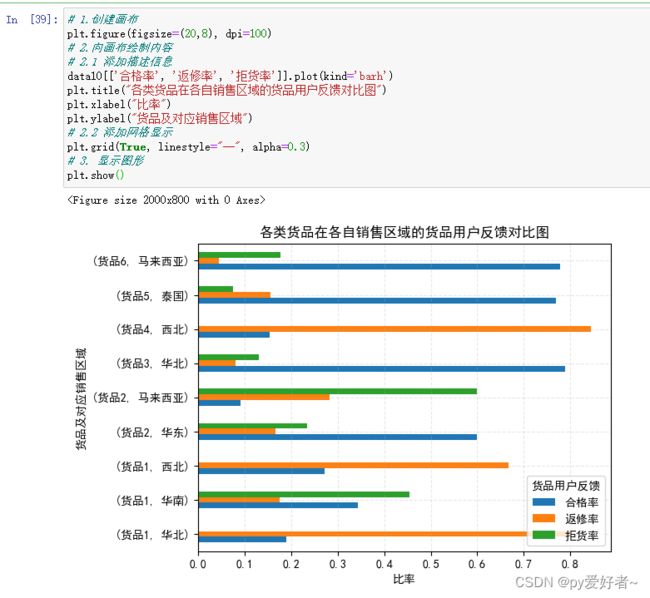
- 结果分析:
- 货品3、6、5合格率均较高,返修率比较低,说明质量还可以;
- 货品1、2、4合格率较低,返修率较高,质量存在一定问题,需要改善,建议扩大抽检范围,增大质检力度;
- 货品2在马来西亚的拒货率最高,同时在马来西亚的按时交货率也非常低,猜测:马来西亚人对送货的时效性要求较高,如果没有按时到货,往往考虑退货,建议加快运输;
- 虑到货品2主要在华东地区销量大,可以考虑增大在华东的投资,适当减少马来西亚的投入。
(4)总结
- (1)货品4—>西北,货品2—>马来西亚两条路线存在较大问题,急需提升时效;
- (2)货品2在华东地区还有较大市场空间,适合加大投入,同时货品2在马来西亚配送时效长,用户拒收率高,从成本角度考虑,应该减少投入;
- (3)货品1、2、4质量存在问题,建议扩大抽检范围,增大质检力度。
(二).机器学习分析
1、分析前提
(1)导入所需要的包
import matplotlib.pyplot as plt
from pylab import mpl
import pandas as pd
import warnings
# 忽略警告信息,警告非报错,不影响代码执行
warnings.filterwarnings("ignore")(2)读取数据
data = pd.read_csv('data_wuliu.csv', encoding='gbk')
data.info()通过info()可以看出,包含10列数据,名字,数据量,数据类型等,可以得出
1.订单号、货品交货状况、数量:存在缺失值,但是缺失量不大,可以删除
2.订单行,对分析无关紧要,没有实质意义,可以考虑删除
3.销售金额格式有问题(万元|元,逗号问题),数据类型需要转换为int|float
(3)数据清洗
# 删除重复记录,遇到重复保留第一行,删除后代替源数据
data.drop_duplicates(keep='first', inplace=True)
# 删除缺失值(有na的整行数据,axis=0,how='any'默认)
data.dropna(axis=0, how='any', inplace=True)
# 删除‘订单行’这一列,第二次运行删除操作会报错
data.drop(columns=['订单行'], inplace=True, axis=1)
# 更新索引:drop=True:把原来的索引index列删除,重置index,原来的索引因为删除了行数据变乱
data.reset_index(drop=True, inplace=True)
data
# 取出‘销售金额’列,对每个数据进行清洗,自定义map函数处理万元|元
# 编写自定义过滤函数:1.删除逗号,2.转成float:如果是万元则删除万元再*10000,否则,删除元
def data_deal(number):
# 找到带有万元的,取出数字,去掉逗号,转成float,*10000
if number.find('万元') != -1:
# number[:number.find('万元')]去掉万元
# number[:number.find('万元')].replace(',','')将逗号替换为空
number_new = float(number[:number.find('万元')].replace(',','')) * 10000
pass
else: #找到带有元的,删除元,删除逗号,转成float
if number.find('元') != -1:
number_new = float(number.replace('元','').replace(',',''))
pass
return number_new
data['销售金额'] = data['销售金额'].map(data_deal)
data
(4)异常值处理
data.describe()销售金额最小值为0,有异常值
# 销售金额==0,采用删除方法,因为数据量很小
data = data[data['销售金额'] != 0]
data.describe()(5)数据规整
a.增加一项辅助列:月份
配送服务是否存在问题——每个月配送服务的满意度
是否存在尚有潜力的销售区域——根据月份绘制本月销售量的图,看月份和销售量的关系
在数据中,从销售时间里提取月份,两种方法:
1.字符串截取:substr(data['销售时间',6,2])
2.将该列转化为datetime格式,直接month提取月份
data.loc[:, '销售时间'] = pd.to_datetime(data['销售时间'])
data.loc[:, '月份'] = data['销售时间'].apply(lambda x: x.month)
datab.查看规整后的数据
data.head()
2、数据分析
data1 = data.copy()
data2 = data.copy()
data3 = data.copy()(1)配送服务是否存在问题?
- 可以使用机器学习算法对交货时间进行预测,并与实际交货情况进行比较,以评估配送服务的准时性和延迟情况。
- 可以建立一个二分类模型(随机森林分类)来预测配送服务是否存在问题,将"货品交货状况"作为目标变量,其他列作为特征变量。首先,需要对目标变量进行编码,然后使用合适的分类算法进行训练和预测。
# 导入所需的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestClassifier
data1
# 数据预处理
le = LabelEncoder()
data1['销售区域'] = le.fit_transform(data1['销售区域'])
data1['货品'] = le.fit_transform(data1['货品'])
data1['货品用户反馈'] = le.fit_transform(data1['货品用户反馈'])
# 将日期特征转换为天数差
data1['销售时间'] = (pd.to_datetime(data1['销售时间']) - pd.to_datetime('2016-07-01')).dt.days
data1['交货时间'] = (pd.to_datetime(data1['交货时间']) - pd.to_datetime('2016-07-01')).dt.days# 创建特征向量X和目标变量y
X = data1.drop(['订单号', '货品交货状况'], axis=1)
y = data1['货品交货状况']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 训练模型
model = RandomForestClassifier()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
print(y_pred)
a = pd.DataFrame() # 创建一个空DataFrame
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
a.head()
# 查看预测概率
y_pred_proba = model.predict_proba(X_test)
y_pred_proba[0:5]
# 分析数据特征的重要性
# 通过如下代码可以更好的展示特征及其特征重要性:
features = X.columns
importances = model.feature_importances_
a = pd.DataFrame()
a['特征'] = features
a['特征重要性'] = importances
a = a.sort_values('特征重要性', ascending=False)
a
# 参数调优
from sklearn.model_selection import RandomizedSearchCV
import numpy as np
n_estimators = [int(x) for x in np.linspace(start = 1000, stop = 1500, num = 10)]
max_features = ['auto','sqrt']
max_depth = [int(x) for x in np.linspace(10, 30, num = 5)]
max_depth.append(None)
min_samples_split = [9, 10, 11]
min_samples_leaf = [2, 3, 5]
bootstrap = [True, False]
random_grid = {
'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf,
'bootstrap': bootstrap
}
# 构建分类器
clf = RandomForestClassifier(random_state=1)
clf_random = RandomizedSearchCV(estimator=clf,
param_distributions=random_grid,
n_iter = 10,
cv = 3,
verbose=2,
random_state=42,
n_jobs=1)# 传入数据
clf_random.fit(X_train, y_train)
# 输出参数的最优值
# 查看最好的模型参数
print("最好的模型参数:", clf_random.best_params_)
# 查看最好的模型
print("最好的模型:", clf_random.best_estimator_)
# 查看最好的分数
print("最好的分数:", clf_random.best_score_)
# 准确度评估
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
if accuracy > 0.8:
print("配送服务正常")
else:
print("存在配送服务问题")
- 结果分析:
- 模型根据已知数据学习,预测是否按时交货的准确率高达0.88;
- 配送服务正常。
(2)是否存在尚有潜力的销售区域?
- 可以使用聚类分析算法(K-Means聚类算法)对销售区域进行分组,以发现潜在的相似销售区域。
# 导入所需的库
from sklearn.cluster import KMeans
from sklearn import metrics
from sklearn.model_selection import GridSearchCV
data2
# 创建特征向量X
X = data2[['销售区域', '数量', '销售金额']]
X
# 将销售区域转换为数值特征
X.loc[X['销售区域'] == '华北', '销售区域'] = 0
X.loc[X['销售区域'] == '华东', '销售区域'] = 1
X.loc[X['销售区域'] == '华南', '销售区域'] = 2
X.loc[X['销售区域'] == '马来西亚', '销售区域'] = 3
X.loc[X['销售区域'] == '泰国', '销售区域'] = 4
X.loc[X['销售区域'] == '西北', '销售区域'] = 5
X
# 使用K均值聚类进行区域划分
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans.fit(X)
# 得到每个销售区域所属的类别标签
labels = kmeans.labels_
# 聚类结果
data2['销售区域聚类'] = labels
data2['销售区域聚类']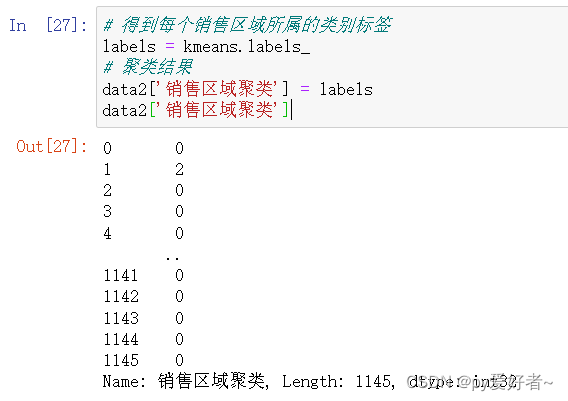
# 输出潜在的销售区域
potential_regions = set(X['销售区域'][labels == labels.max()])
print("存在潜力的销售区域:", potential_regions)
- 销售区域:0代表华北、2代表华南、5代表西北;
- 所以存在潜力的销售区域为:华北、华南、西北。
# 模型评估
# 使用外部标签评估指标,如轮廓系数和Calinski-Harabasz指数
silhouette_score = metrics.silhouette_score(X, labels)
calinski_harabasz_score = metrics.calinski_harabasz_score(X, labels)
# 打印评估结果
print("轮廓系数(Silhouette Coefficient):结合了簇内样本的紧密度和簇间样本的分离度,用于评估整体的聚类效果。轮廓系数取值范围在[-1, 1]之间,越接近于1表示聚类效果越好。")
print("轮廓系数: %.3f" % silhouette_score)
print("Calinski-Harabasz指数(也称为方差比率准则):根据簇内的样本离散程度和簇间的样本分离程度,计算一个适应性准则。Calinski-Harabasz指数的值越大表示聚类效果越好。")
print("Calinski-Harabasz指数: %.3f" % calinski_harabasz_score)
# 使用内部指标进行评估,如SSE和Davis-Bouldin指数
sse = kmeans.inertia_
davis_bouldin_score = metrics.davies_bouldin_score(X, labels)
# 打印评估结果
print("SSE(Sum of Squared Errors):计算所有样本点与其所属簇中心的距离平方和,用于衡量簇内的紧密度。SSE值越小表示簇内样本越相似。")
print("SSE: %.3f" % sse)
print("Davis-Bouldin指数:基于类间和类内的平均距离来评估聚类效果。Davis-Bouldin指数的值越小表示聚类效果越好。")
print("Davis-Bouldin指数: %.3f" % davis_bouldin_score)
# 模型优化
# 创建GridSearchCV对象
param_grid = {'n_clusters': [2, 3, 4, 5], 'init': ['k-means++', 'random'], 'n_init': [5, 10, 15], 'max_iter': [100, 200, 300]}
grid_search = GridSearchCV(kmeans, param_grid, cv=5)
# 使用GridSearchCV进行参数搜索和模型训练
grid_search.fit(X)
# 输出最优参数
print("最好的模型参数: ", grid_search.best_params_)
# 查看最好的模型
print("最好的模型: ", grid_search.best_estimator_)
# 输出每个聚类的数据统计信息
cluster_info = data2.groupby(['销售区域聚类'])['销售区域'].unique()
print(cluster_info)
- 结果分析:
- 从聚类结果可以看出:华北在三个类别中均存在,华南和西北在0和2类别中存在;
- 所以华北、华南和西北这三个销售区域存在潜力.
(3)商品是否存在质量问题?
- 可以建立一个二分类模型来预测商品是否存在质量问题,将"货品用户反馈"作为目标变量,其他列作为特征变量。需要对目标变量进行编码,并使用合适的分类算法(支持向量机算法)进行训练和预测。
import pandas as pd
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.model_selection import GridSearchCV
data3
# 数据预处理
le = LabelEncoder()
data3['销售区域'] = le.fit_transform(data3['销售区域'])
data3['货品'] = le.fit_transform(data3['货品'])
data3['货品用户反馈'] = le.fit_transform(data3['货品用户反馈'])
# 将日期特征转换为天数差
data3['销售时间'] = (pd.to_datetime(data3['销售时间']) - pd.to_datetime('2016-07-01')).dt.days
data3['交货时间'] = (pd.to_datetime(data3['交货时间']) - pd.to_datetime('2016-07-01')).dt.days# 创建特征向量X和目标变量y
X_3 = data3.drop(['订单号', '货品交货状况'], axis=1)
y_3 = data3['货品用户反馈']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_3, y_3, test_size=0.2, random_state=42)X_train
# 训练支持向量机模型
model = SVC()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
y_pred
a = pd.DataFrame() # 创建一个空DataFrame
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
a.head()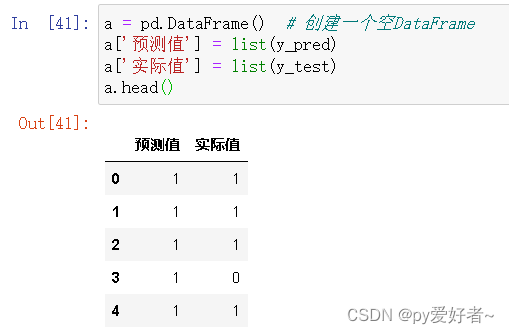
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("模型准确率:", accuracy)
# 参数调优
# 使用GridSearchCV进行参数调优
grid_search = GridSearchCV(SVC(), param_grid={'C': [0.1, 1, 10], 'gamma': [0.1, 1, 10]}, cv=5)
grid_search.fit(X_train, y_train)
# 输出最优参数
print("最好的模型参数: ", grid_search.best_params_)
# 查看最好的模型
print("最好的模型: ", grid_search.best_estimator_)
# 查看最好的分数
print("最好的分数:", grid_search.best_score_)
# 准确度评估
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
if accuracy > 0.8:
print("商品不存在质量问题")
else:
print("商品存在质量问题")
- 结果分析:
- 测试了逻辑回归、随机森林、K近邻、决策树、SVM等算法;
- 结果是SVM分类算法的准确率最高,准确率为0.71,准确率小于0.8;
- 说明货品用户反馈预测并不算非常准确,商品存在质量问题。
3、总结
- (1)配送服务整体比较正常,不存在特别大的问题;
- (2)存在尚有潜力的销售区域,分别是华北、华南和西北;
- (3)商品存在质量问题,建议扩大抽检范围,增大质检力度。
四.项目特色
1、参数优化:通过对参数的优化实现对数据的优化处理
2、数据分析:从数据分析可视化角度解决三个问题
3、机器学习:从机器学习的角度分析处理问题,通过准确率判断问题并提出解决方法
4、方法多元化:综合使用逻辑回归、随机森林、K-Means聚类算法、SVM等算法
五.分析结论
1、数据分析可视化得出结论:
(1)货品4—>西北,货品2—>马来西亚两条路线存在较大问题,急需提升时效;
(2)货品2在华东地区还有较大市场空间,适合加大投入,同时货品2在马来西亚配送时效长,用户拒收率高,从成本角度考虑,应该减少投入;
(3)货品1、2、4质量存在问题,建议扩大抽检范围,增大质检力度。
2、机器学习分析得出结论:
(1)配送服务整体比较正常,不存在特别大的问题;
(2)存在尚有潜力的销售区域,分别是华北、华南和西北;
(3)商品存在质量问题,建议扩大抽检范围,增大质检力度。
六.源码和PPT
基于机器学习的物流预测可视化: 基于机器学习的物流预测可视化项目