5. seaborn-构建结构化多图网络
在探索中等维度数据时,经常需要在数据集的不同子集上绘制同一类型图的多个实例,这种技术有时被称为“网格”绘图,可以从复杂数据中快速提取大量信息。Matplotlib 为此提供了很好的支持,seaborn 构建于此之上,可直接将绘图结构和数据集结构关系起来。
要使用网格图功能,数据必须是 Pandas 数据框的形式,且为整洁形式,即用来绘图的数据框应该为每列一个变量,每一行一个观察的形式。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
sns.set(style='whitegrid', color_codes=True)
plt.rc(
"figure",
autolayout=True,
figsize=(6, 5),
titlesize=18,
titleweight='bold',
)
plt.rc(
"axes",
labelweight="bold",
labelsize="large",
titleweight="bold",
titlesize=16,
titlepad=10,
)
%config InlineBackend.figure_format = 'retina'
warnings.filterwarnings('ignore')
基于一定条件的多重小图
当我们想在数据集的不同子集中分别可视化变量分布或多个变量之间的关系时,就需要用到FacetGrid类,它最多有三个维度:row、col和hue。前两者与轴阵列对应;色调变量hue为第三个维度,不同级别采用不同的颜色绘制。
首先,使用数据框初始化FacetGrid对象并指定将形成网格的行、列或色调维度的变量名称。这些变量应是离散的,然后对应于变量不同取值的数据将用于绘制沿该轴的不同小平面。relplot()、catplot()和lmplot()都在内部使用此对象,并且它们在完成时返回该对象,以便进一步调整。
tips = sns.load_dataset('tips', data_home='data', cache=True)
tips.head()
| total_bill | tip | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | 1.66 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | 3.50 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | 3.31 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | 3.61 | Female | No | Sun | Dinner | 4 |
g = sns.FacetGrid(tips, col='time')
g.map(plt.hist, 'tip')

map函数绘制图形并注释轴,生成图。要绘制关系图,只需传递多个变量名称。还可以提供关键字参数,这些参数将传递给绘图函数。
g = sns.FacetGrid(tips, col='sex', hue='smoker')
g.map(plt.scatter, 'total_bill', 'tip', alpha=0.7)
g.add_legend()

有几个传递给类构造函数的选项可以用于控制网格外观。
g = sns.FacetGrid(tips, row='smoker', col='time', margin_titles=True)
g.map(sns.regplot, 'size', 'total_bill', color='.3', fit_reg=False, x_jitter=.1)

通过提供每个面的高度以及纵横比来设置图形的大小
g = sns.FacetGrid(tips, col='day', height=4, aspect=0.5)
g.map(sns.barplot, 'sex', 'total_bill')

小图的默认排序是由 DataFrame 中的信息确定的。如果用于定义小图的变量是类别变量,则使用类别的顺序。否则,小图将按照各类的出现顺序排列。可以使用*_order参数指定任意构面维度的顺序。
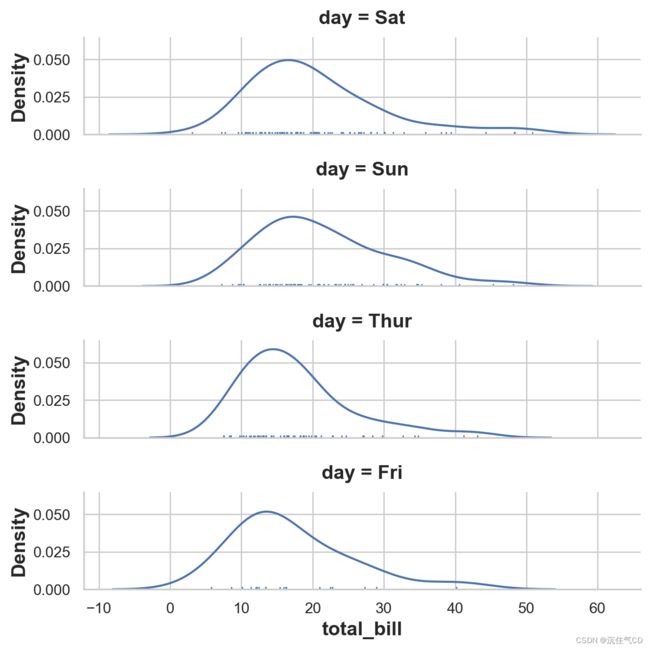
ordered_days = tips.day.value_counts().index
g = sns.FacetGrid(tips, row='day', row_order=ordered_days,
height=1.7, aspect=4)
g.map(sns.distplot, 'total_bill', hist=False, rug=True)
可以用 seaborn 调色板(即可以传递给color.palette()参数)。还可以用字典将hue变量中的值映射到 matplotlib 颜色:
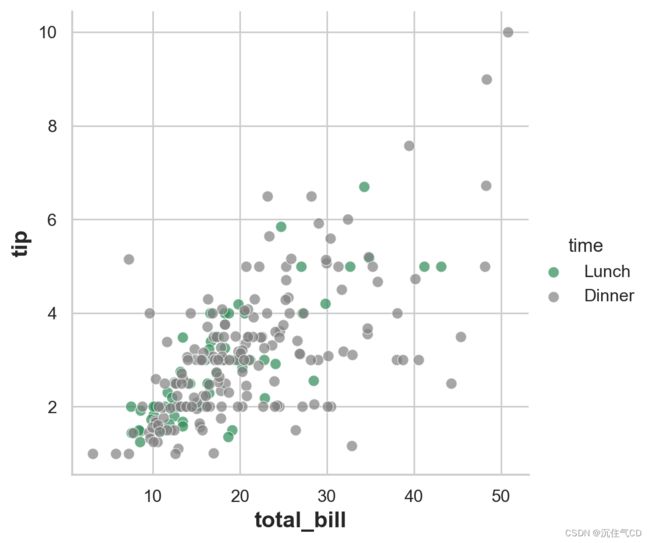
pal = dict(Lunch='seagreen', Dinner='gray')
g = sns.FacetGrid(tips, hue='time', palette=pal, height=5)
g.map(plt.scatter, 'total_bill', 'tip', s=50, alpha=.7, linewidth=.5, edgecolor='white')
g.add_legend()
如果一个变量的类别太多,除了可以沿着列绘制之外,也可以“包装”它们以便跨越多行,执行此 wrap 操作时,不能使用row变量。
attend = sns.load_dataset('attention', cache=True, data_home='data').query("subject <= 12")
g = sns.FacetGrid(attend, col='subject', col_wrap=4, height=2, ylim=(0, 10))
g.map(sns.pointplot, 'solutions', 'score', color='.3', ci=None)

使用FacetGrid.map()(可多次调用)绘图后,我们可以调整绘图的外观。FacetGrid对象有许多方法可以在更高的抽象层次上操作图形。最一般的是FacetGrid.set(),还有其他更专业的方法,如FacetGrid.set_axis_labels(),它们都遵循内部构面没有轴标签的约定。例如:
with sns.axes_style('white'):
g = sns.FacetGrid(tips, row='sex', col='smoker', margin_titles=True, height=2.5)
g.map(plt.scatter, 'total_bill', 'tip', color='#334488', edgecolor='white', lw=.5)
g.set_axis_labels('Total bill (US Dollars)', 'Tip')
g.set(xticks=[10, 30, 50], yticks=[2, 6, 10])
g.fig.subplots_adjust(wspace=.02, hspace=.02)

对于需要更多自定义的情形,我们可以直接使用底层 matplotlib 的图形Figure和轴Axes对象,它们分别作为成员属性存储在Figure和Axes(一个二维数组中)。在制作没有行或列刻面的图形时,还可以使用ax属性直接访问单个轴。
g = sns.FacetGrid(tips, col='smoker', margin_titles=True, height=4)
g.map(plt.scatter, 'total_bill', 'tip', color='#338844', edgecolor='white', s=50, lw=1)
for ax in g.axes.flat:
ax.plot((0,50), (0, .2*50), c='.2', ls='--')
g.set(xlim=(0, 60), ylim=(0, 14))

绘制成对数据关系
PairGrid允许使用相同的绘图类型快速绘制小子图网格。在PairGrid中,每个行和列都分配给一个不同的变量,结果图显示数据集中每个变量对的关系,即“散点图矩阵”,但PairGrid不仅仅限于散点图。
了解PairGrid和FacetGrid之间的差异很重要,前者每个构面显示以不同级别的变量为条件的相同关系,后者显示不同的关系(上三角和下三角组成镜像图)。使用PairGrid可为我们快速提供有趣的关系和高级摘要。
PairGrid和FacetGrid非常相似,首先初始化网格,然后将绘图函数传递给map方法,并在每个子图上调用,pairplot()函数可以帮助快速绘图。
iris = sns.load_dataset('iris', cache=True, data_home='data')
g = sns.PairGrid(iris)
g.map(plt.scatter)

可以在对角线上绘制不同的函数,以显示每列中变量的单变量分布。但请注意,轴刻度与该绘图的计数或密度轴不对应。
一种常见的做法是通过单独的分类变量对观察结果进行着色。例如,iris 数据集三种不同种类的鸢尾花都有四个特征值,因此我们可以看到不同花在这些取值上的差异。
g = sns.PairGrid(iris, hue='species')
g.map_diag(plt.hist)
g.map_offdiag(plt.scatter)
g.add_legend()

默认情况下,使用数据集中的每个数值列,但如果需要,我们可以专注于特定列。
g = sns.PairGrid(iris, vars=['sepal_length', 'sepal_width'], hue='species')
g.map(plt.scatter)

也可以在上三角和下三角中使用不同的函数来强调关系的不同方面。
g = sns.PairGrid(iris)
g.map_upper(plt.scatter)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3, legend=False)

对角线上具有单位关系的方形网格实际上只是一种特殊情况,我们也可以在行和列中使用不同的变量进行绘图。
g = sns.PairGrid(tips, y_vars=['tip'], x_vars=['total_bill', 'size'], height=4)
g.map(sns.regplot, color='.3')
g.set(ylim=(-1, 11), yticks=[0, 5, 10])

我们可以使用不同的调色板,并将关键字参数传递到绘图函数中。
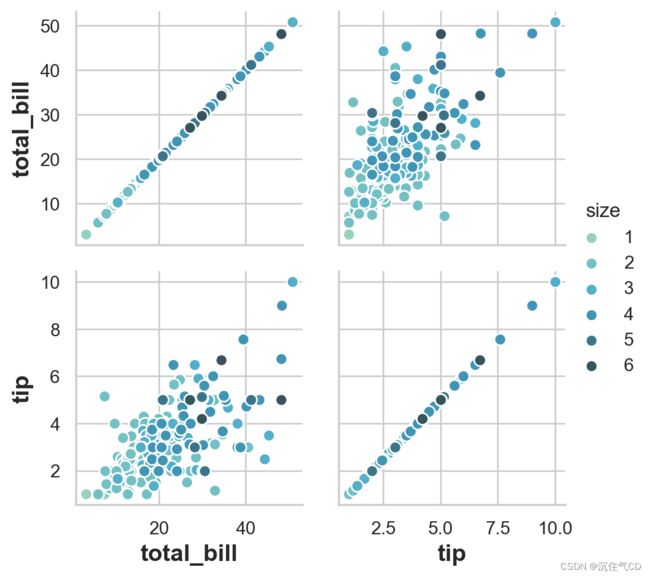
g = sns.PairGrid(tips, hue='size', palette='GnBu_d')
g.map(plt.scatter, s=50, edgecolor='white')
g.add_legend()
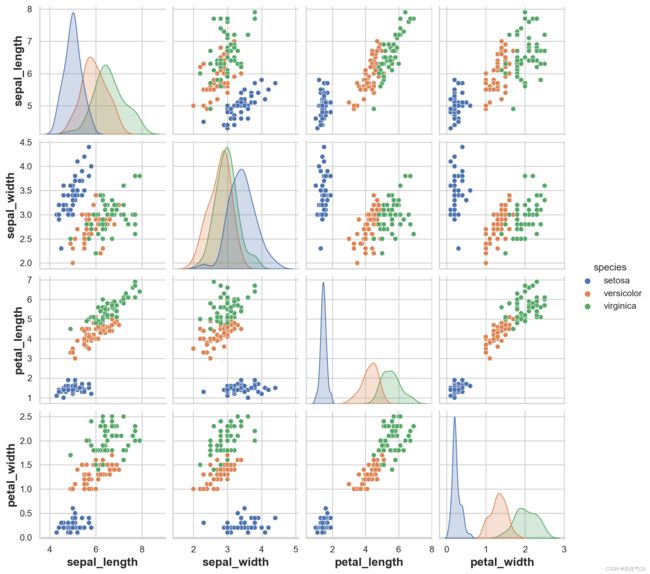
PairGrid很灵活,但要快速查看数据集,使用pairplot()更容易。此函数默认使用散点图和直方图,但会添加一些其他类型,比如对角线上的 KDE 和非对角线上的回归图。
sns.pairplot(iris, hue='species', height=2.5)
sns.pairplot(iris, hue='species', palette='Set2', diag_kind='kde', height=2.5)
