辽宁链家新房数据采集与可视化实现
摘 要
网络爬虫也叫做网络机器人,是一种按照一定的规则,自动地抓取网络信息,进行数据信息的采集与整理的程序或者脚本。随着海量数据的出现,如何快速有效的获取到我们想要的数据成为难题。以房源信息为例,该文使用Python语言结合爬虫来对房源信息网——链家网上在售新房数据进行爬取,解读辽宁省大连市和沈阳市的新房数据背后隐藏的房源趋势。
关键词:网络爬虫;房源分析;Python;requests;lxml;
Matloplit;bs4
第1章 绪论
面对有用信息获取的需求,通用网络爬虫技术的基础上,利用 Python 软件对网络
爬虫数据抓取程序进行深度优化。
1.1 本课题研究背景
近年来,大数据、互联网和云计算等技术发展迅速,“智慧城市”建设进程加快,越来越多的实物用数据代为表示,用数据来反映问题成为一种直观又具有说服力的方式。如今,大部分地区已进入城市化进程,人口的众多与住房用地的减少使得房价大涨,如何找到合适的住房已成为常见的民生难题。
互联网为用户提供了各种房源数据,在爬虫的爬取下集中有用的数据,并对这些数据进行清洗、统计和可视化分析,可以为用户挖掘出隐藏在网络数据中的所有房源的分布情况以及价格等特征走向,帮助用户做出更好的决策。
1.2 网络爬虫发展概述
在大数据时代,信息的采集是一项重要的工作,而互联网中的数据是海量的,如果单纯靠人力进行信息采集,不仅低效繁琐,搜集的成本也会提高。如何自动高效地获取互联网中我们感兴趣的信息并为我们所用是一个重要的问题,而爬虫技术就是为了解决这些问题而生的[1]。网络爬虫(Web crawler)也叫做网络机器人,可以代替人们自动地在互联网中进行数据信息的采集与整理[2]。它是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本,可以自动采集所有其能够访问到的页面内容,以获取相关数据。从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。爬虫从一个或若干初始网页的 URL 开始,获得初始网页上的 URL,在抓取网页的过程中,不断从当前页面上抽取新的 URL 放入队列,直到满足系统的一定停止条件。
1.2.1 网络爬虫技术的国内外发展现状
1.国内网络爬虫技术的发展现状
1)网络爬虫技术概述
网络爬虫技术作为搜索引擎的重要组成部分,可以自动地对相关页面和内容进行爬虫和保存。网络爬虫又被称为网络蜘蛛,所以可以看出爬虫就是一只蜘蛛,而互联网其实就是一张巨大的蜘蛛网,爬虫的目的就是将蜘蛛网上的猎物全部抓取起来[3]。 2)国内外研究现状
随着互联网的快速发展,全球互联网网站和网页的数量也在迅速增长,互联网的信息量也呈指数级的增长。互联网是一个巨大的高度开放,缺乏管理的信息空间。虽然信息量十分巨大,但是对于用户来说,真正有价值的信息就变得非常有限。如果用户想要从互联网上获取有用的信息,他们需要搜素引擎的帮助,如信息检索系统。搜索引擎是根据一定的策略和特定的计算机程序从互联网进行搜索的软件系统,在处理和处理信息后为用户提供检索服务。目前市场上比较流行的搜索引擎有百度、Google 等。搜索引擎的发展伴随着信息检索技术的发展[4]。1972 年,APPNET 实验网络的成功标志着互联网的诞生。1993 年浏览器的发展更是促进了搜索引擎的快速发展。1994 年由美籍华人杨致远和 DavidFilo 共同创建了世界上第一个网络检索工具 Web Crawler,也就是大家所熟悉的 Yahoo[5]。
1.3 本课题研究意义
通过爬虫技术收集了链家网辽宁大连和沈阳市包含的有用的新房数据,并对这些数据进行清洗、统计和可视化分析,可以为用户挖掘出隐藏在网络数据中的所有房源的分布情况以及价格等特征走向,帮助用户做出更好的决策。
1.4 课题的研究主要内容
本课程设计针对爬虫技术中 requests 模块的应用进行了深入的研究,全文共分 3 章,主要内容分别是:
绪论。主要介绍了本课程设计的主要内容与主要目的;
第一部分:讲了一些常见的爬虫分类,并且简单介绍了这些爬虫背景与其适用场景;第二部分:系统框架,各框架的功能介绍,以及存储数据的属性;第三部分:代码的储存以及数据的展示。
课题的创新点在于整合辽宁省链家网两千多条新房的信息数据与结构,整合、筛
选、处理持久化存储为csv文件,并利用pandas读取分析新房数据。
第2章 系统设计
2.1 系统构架
本课程设计发挥了 requests 模块的优势,获取了辽宁链家新房的信息,Python 代码通过 pycharm 编写,编写步骤大致可分为五步:指定 url、发送请求、获取响应数据、持久化存储、数据可视化,对应数据爬取模块、数据存储模块、数据可视化模块。

图2.1 系统架构图
2.2 系统构架介绍
图2.1展示的是项目系统的整体结构, 各个模块功能简述如下:
爬虫模块:主要是用来爬取数据,爬取链家新房信息的数据,包括房源名称、房价、所属地区、销售状态、用途等。
数据存储模块:主要是通过csv进行数据存储
可视化模块:主要是对爬取的新房数据进行分析,采用了pandas处理csv存储的数据,然后通过matliplot库进行可视化处理
2.3 技术模块
表 2.1 项目所使用模块
| 库名 |
项目中作用 |
|---|---|
| Requests |
网页数据采集 |
| Lxml |
网页采集数据分析 |
| Time |
控制爬取数据的时间间隔 |
| pandas |
数据处理 |
| csv |
储存数据信息 |
| matliplot |
数据可视化 |
2.3.1requests 模块
HTTP库中的Requests模块,作用是发送网络请求,获得响应数据。
Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库。它比urllib更加方便,可以节约大量的工作,完全满足HTTP测试需求的。requests 库的get方法,可进行特定url页面信息的检索与抓取,并在计算机屏幕中进行显示。这一过程需要使用 get方法,反复对 URL 地址队列的数据内容,进行抓取与解析操作,并将网页爬取的 URL 参数返回至 Request 对象。本文就是利用get方法获取链接页面信息。
2.3.2lxml 模块
使用lxml模块的XPath 路径语言。XPath 是用来确定 XML 文档中某些内容的语言,其能够对树状结构的数据节点进行找寻、定位,以获取到 XML 文档中具有特定属性
的元素内容。而 lxml 库作为 Python 编程系统的第三方库,也支持对 XPath
规范中的 XML 文档标签,进行标签内容语言的提取与导航。在利用lxml 库进行
XML 文档节点、文本、属性、类别等寻找的过程中,需要将 lxml 库的数据信息
导入至 etree 包,之后对网站中的楼盘信息进行爬取,保存至本地csv文件。
2.3.3time 模块
time库是Python中处理时间的标准库,是计算机时间的表达提供获取系统时间并格式化输出功能提供系统级精确计时功能,用于程序性能分析。在爬虫里面一般用作延迟爬取处理,降低爬虫的爬取频率,能有效防止网站反爬
2.3.4csv 模块
CSV文件又称为逗号分隔值文件,是一种通用的、相对简单的文件格式,用以存储表格数据,包括数字或者字符。CSV是电子表格和数据库中最常见的输入、输出文件格式。
通过爬虫将数据抓取的下来,然后把数据保存在文件,或者数据库中,这个过程称为数据的持久化存储。本节介绍Python内置模块CSV的写入操作,csv模块中的writer类可用于写入爬取的数据。
2.5 本章小结
本章主要介绍了本课程设计的系统框架,然后对各框架所涉及到的功能进行了简单介绍
第3章 系统实现
第二章中详细介绍了 Python 网络爬虫所需要的一些技术。第三章主要介绍系统的
三大基本模块——数据爬取模块、数据存储模块、数据可视化模块实现的一些细节
3.1 数据爬取
3.1.1 request库的运用
通过request库获取响应数据,一般用到get和post方法。相对于两种方法各有优势,post方法就必须要携带参数,传递一个表单,如果对表单不熟悉,就很容易报错。所以本文就以相对简单的get方法获取网页响应的请求数据,get方法可传递参数也不用传递参数,只需要判断这个网站是否有较强的反爬虫手段即可。通过链家网站发现,是需要有一定的反爬虫手段的,这样才能降低触发网站反爬虫的策略,通过传递header请求头,即可大幅度降低反爬虫风险,获取网页信息。
3.1.2XPath 的运用
在获取网页信息之后第二步就要对获得的网页信息进行解析。目前比较热门的解析方式有很多,有beautifulsoup、json、xpath等方式。每一种方式各有优势,相比于前面两种方式,对于静态网页,xpath更容易定位标签位置。通过etree解析网页数据后,调用xpath去定位链接网页每一条信息的父标签,在通过for循环遍历提取包含在父标签的每一个子标签的房源名称、房价等数据,大大提高代码的简单程度。当然提取处理的数据是列表类型,必须转换处理,并把里面一些特殊情况处理掉,就必要使用条件语句对数据进行处理。
3.2 数据存储
使用的是csv模块来存储为csv文件,好处就是相对简单,没有那么复杂,只需要调用csv模块的writer函数即可,难度比较低,且易于保存。

图 3.1 链接新房数据
3.3 数据展示
3.3.1 Pandas
Pandas提供了大量快速便捷处理数据的函数和方法。它是使Python成为强大而高效的数据分析环境的重要因素之一。
Pandas中主要的数据结构有Series、DataFrame和Panel。其中Series是一维数组,与NumPy中的一维array以及Python基本的数据结构List类似;DataFrame是二维的表格型数据结构,可以将DataFrame理解为Series的容器; Panel是三维的数组,可看作为DataFrame的容器。本文通过pandas中的groupby方法对数据进行分组处理,并将分组的数据用reset-index方法转换成二维表结构,方便提取数据。
3.3.2 Matplotlib
Matplotlib是Python 的绘图库,是用于生成出版质量级别图形的桌面绘图包,让用户很轻松地将数据图形化,同时还提供多样化的输出格式。本文就是通过matloplit库结合pandas数据处理,对链家新房数据进行可视化处理。

该图为不同地区的平均房价,通过这个折线图,清晰明了知道哪个地区房价多高,哪个地区房价滴,方便用户了解各个地区的房价差异。

图 3.2 不同地区不同住宅类型的数量占比
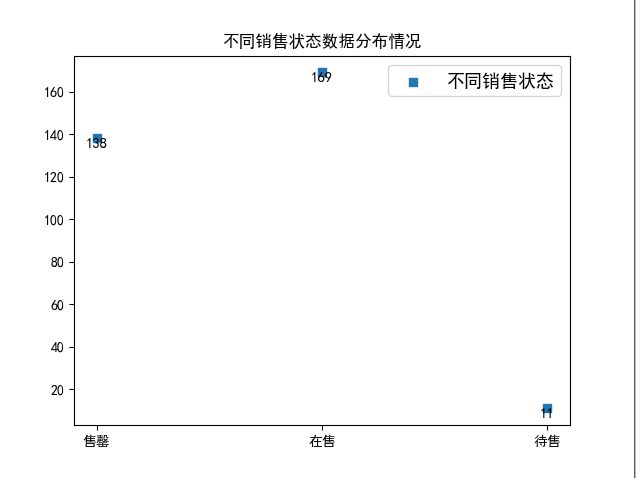
图 3.3 辽宁大连新房不同销售状态数据分布
该图为辽宁大连新房不同销售状态数据分布,通过改图,用户可以直观了解大连有多少待售多少在售多少售完,方便用户调整策略。
第4章 全文总结
本课程设计是基于 Python 网络爬虫的技术爬取的链接新房数据并使用matloplit库 实现了对爬取到的部分信息的可视化展示。随着信息技术越来越成熟,如何使用爬虫和数据可视化等技术更好地了解用户以及他们的意向是WEB2.0时代的关键领域。本文通过研究如何从互联网上采集相关数据,让数据采集更高效,把采集到的数据进行清洗、过滤,将有用的数据进行统计和可视化分析,从中分析和挖掘出有价值的信息,充分利用大数据潜在的价值。