18、Kafka ------ SpringBoot 整合 Kafka 流API(演示发送到test1主题的消息,被导流到 test2主题,通过监听器看是否导流成功)
目录
- SpringBoot 整合 Kafka 流API
-
- 流API的支持
- 配置属性分析
-
- 为流配置应用程序id
- 配置流API
- 使用 @EnableKafkaStreams
- 效果演示
- 完整代码
-
- 1、application.properties 配置文件
- 2、KafkaConfig 配置类
- 3、MessageController 控制层
- 4、MessageService 业务层
- 5、KafkaMessageListener 消息监听器
- 6、pom 依赖文件
- 7、启动Kafka命令汇总
SpringBoot 整合 Kafka 流API
流API的支持
- @EnableKafkaStreams
- 自动配置的 StreamsBuilder
- 程序只要返回 KStreams 就够了,Spring Boot 会自动将
KStreams 中 Topology 对象封装成 KafkaStreams,并开启导流。
Spring Boot 为 Kafka 流API并未提供太多额外的支持,它只提供了一个 @EnableKafkaStreams 注解,
通过该注解能让 Spring Boot 自动配置 StreamsBuilder,当然也能将 StreamsBuilder 注入任意的其他组件,剩下的事情 Spring Boot 就不再参与了。
spring-kafka 项目没有包含 Kafka流API 的依赖,因此如要在 Spring Boot 项目中使用Kafka流,还必须显式添加 kafka-streams 依赖
依赖如图:

配置属性分析
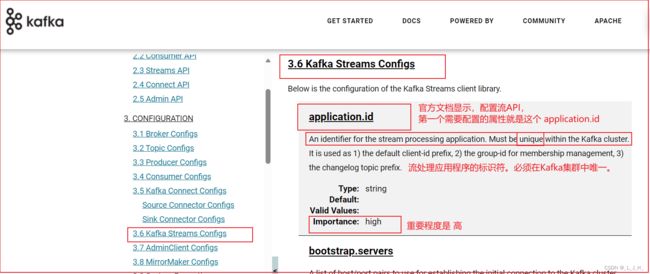
为流配置应用程序id
通过如下配置指定:
# 指定Streams API的应用ID
spring.kafka.streams.application-id=spring-pipe
如果没有配置spring.kafka.streams.application-id属性,Spring Boot 默认使用 spring.application.name 属性值作为应用ID。
配置流API
spring.kafka.streams.* 开头的属性则用于配置 Kafka流,例如如下配置:
指定应用启动时自动创建流
spring.kafka.streams.auto-startup=true
指定消息key默认的序列化和反序列化器
spring.kafka.streams.properties[default.key.serde]=
org.apache.kafka.common.serialization.Serdes$StringSerde
指定消息value默认的序列化和反序列化器
spring.kafka.streams.properties[default.value.serde]=
org.apache.kafka.common.serialization.Serdes$StringSerde
配置文件如图:

配置序列化和反序列化的属性,查官方文档的时候,现在的默认值已经是null了

之前是这样的:

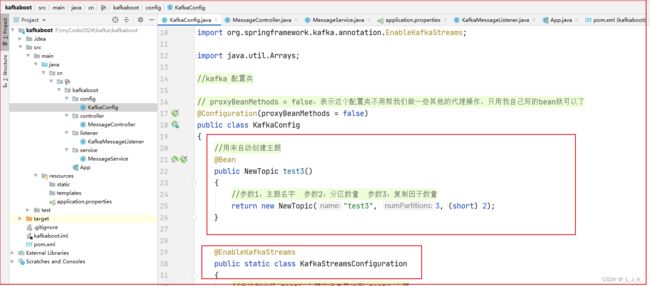
使用 @EnableKafkaStreams
@EnableKafkaStreams 注解只能修饰Type,不能修饰方法。只能放在类和接口上面
所以这里定义一个静态内部配置类,然后放在我们写的那个 KafkaConfig 配置类里面
@EnableKafkaStreams
public static class KafkaStreamsConfiguration
{
//此处指定将 test1 主题的消息导流到 test2 主题
//源主题
public final static String SOURCE_TOPIC = "test1";
//要导流到这个 目标主题
public final static String TO_TOPIC = "test2";
//通过自动注入的StreamBuilder来创建KStream
@Bean
public KStream kStream(StreamsBuilder builder)
{
...
// 直接返回KStream就行了
return stream;
}
}
在 官方文档 API 查这个注解的解释

【备注】:如果你直接用原生 Kafka 流API,那你需要最终得到 KafkaStreams ,然后调用 KafkaStreams 的 start() 方法开始导流。
整合 Spring Boot 之后,你只要得到 KStream 就行了,Spring Boot 会帮你把 KStream 中 Topology 封装成 KafkaStreams ,并开启导流。
整个完整的导流代码:
这个是配置类里面的其他bean代码,也贴上来防止忘记。
这个就是导流的代码:
把test1 主题的消息导流到test2主题里面去。
因为写在配置类里面,所以项目启动过得时候,就会加载到这个代码,所以如果监听器监听到test1有消息,就会自动导流到test2主题里面去

效果演示
流API的代码,也是从之前写的这个文章引用的,里面有更详细的解释
1、打开一个小黑窗,往test1 发送消息

2、然后配置类里面,就会通过我们写的配置,把 test1 主题的消息 导流到 test2 主题里面去

3、然后两个不同组的监听器,它们都是在监听 test2 主题的消息
监听器的代码,在这篇有更详细的解释
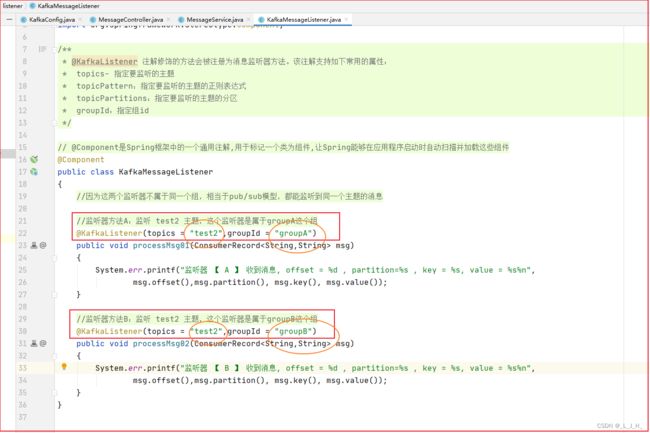
4、运行结果正确,test1的消息成功被导流到test2 主题里面,然后被监听器监听到。
这里发送给test1主题的消息,在导流的时候是经过处理的。
而且因为监听器是不同组的,类似 pub / sub 发布/订阅模型,所以两个监听题因为是监听同一个主题,所以能监听消费到同一个主题的消息。

这里发送给test1主题的消息,在导流的时候是经过处理的。

上面的截图就是流API用到的代码
完整代码
这里的完整代码是结合springboot整合kafka的所有代码,包括之前的发送消息和消费消息的代码。
全部贴在这里,用于以后复盘。
1、application.properties 配置文件
通用的属性配置,消息生产者、消费者、监听器、流API 的相关属性配置
# 由于zookeeper 默认占用了8080端口,那么web应用的端口修改成8081
server.port=8081
# 通用的配置,就是生产者和消费者等都用到这些配置------------
# 指定连接 kafka 的 Broker 服务器的地址
spring.kafka.bootstrap-servers=localhost:9092,localhost:9093,localhost:9094
# 发送请求是传递给服务器的ID,用于服务器端做日志
spring.kafka.client-id=ljh-boot
# 生产者相关的配置 --------------------------
# 指定Kafka的消息确认机制 --> 0:不等待消息确认;1:只等待领导者分区的消息写入之后确认;all:等待所有分区的消息都写入之后才确认
spring.kafka.producer.acks=all
# 指定消息发送失败的重试多少次
spring.kafka.producer.retries=0
# 当 Producer 内部类没有为 linger.ms 配置属性提供对应的字段时,可通过 properties 来设置
# springboot 没有为这个属性添加对应的字段,所以我们需要自己用properties来给其添加进去
spring.kafka.producer.properties[linger.ms]=3
# 设置序列化器
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 消费者相关的配置 --------------------------
# 自动提交offset,就是类似之前的自动消息确认
spring.kafka.consumer.enable-auto-commit=true
# 多个消息之间,自动提交消息的时间间隔
# 当 Consumer 内部类没有为 auto.commit.interval.ms 这个配置属性提供对应的字段时,可通过 properties 来设置
# springboot 没有为这个属性添加对应的字段,所以我们需要自己用properties来给其添加进去
spring.kafka.consumer.properties[auto.commit.interval.ms]=1000
# 设置session的超时时长,默认是10秒,这里设置15秒
spring.kafka.consumer.properties[session.timeout.ms]=15000
# 设置每次都从最新的消息开始读取
spring.kafka.consumer.auto-offset-reset=latest
# 设置序列化器
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# 以下配置对监听器的容器工厂生效 --------------------------
# 配置消息如何提交offset
spring.kafka.listener.ack-mode=batch
# 指定消息监听器每次处理消息的数量(single:单条消息; batch:批量处理)
spring.kafka.listener.type=single
# 轮询的超时时间
spring.kafka.listener.poll-timeout=5s
# 配置 流API 相关的配置 --------------------------
# 指定Streams API的应用ID
spring.kafka.streams.application-id=ljh-pipe-test
# 指定随着应用的启动,自动开启导流功能
spring.kafka.streams.auto-startup=true
# 指定消息key默认的序列化和反序列化器
spring.kafka.streams.properties[default.key.serde]=org.apache.kafka.common.serialization.Serdes$StringSerde
# 指定消息value默认的序列化和反序列化器
spring.kafka.streams.properties[default.value.serde]=org.apache.kafka.common.serialization.Serdes$StringSerde
2、KafkaConfig 配置类
项目启动的时候,会自动加载配置类里面的代码
这里有两个bean,一个是自动创建主题,一个是流API的导流功能
package cn.ljh.kafkaboot.config;
import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.ValueMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafkaStreams;
import java.util.Arrays;
//kafka 配置类
// proxyBeanMethods = false:表示这个配置类不用帮我们做一些其他的代理操作,只用我自己写的bean就可以了
@Configuration(proxyBeanMethods = false)
public class KafkaConfig
{
//用来自动创建主题
@Bean
public NewTopic test3()
{
//参数1:主题名字 参数2:分区数量 参数3:复制因子数量
return new NewTopic("test3", 3, (short) 2);
}
//流API的导流功能
@EnableKafkaStreams
public static class KafkaStreamsConfiguration
{
//此处指定将 test1 主题的消息导流到 test2 主题
public final static String SOURCE_TOPIC = "test1"; //源主题
public final static String TO_TOPIC = "test2"; //目标主题
//通过自动注入的StreamBuilder来创建KStream
@Bean
public KStream<String, String> kStream(StreamsBuilder builder)
{
//使用StreamBuilder来创建KStream
KStream<String,String> kStream = builder
//设置 source 主题,类似的源的主题
.stream(SOURCE_TOPIC);
kStream
//这里的 mapValues 就是对消息(数据项、记录)进行转换处理(也可以理解为业务处理),这里我在消息前面加上 "【 ljh: " 这个字符串操作
//使用lambda表达式来构建转换器
//此处是一条消息,转换后也还是一条消息,只是在消息内容的前后添加特定的字符串
//.mapValues(value -> "【 ljh: " + value + " 】")
//此处使用匿名内部类构建转换器
.flatMapValues(new ValueMapper<String, Iterable<String>>()
{
@Override
//该方法的参数就代表传入的一个数据项(消息)
public Iterable<String> apply(String value)
{
//Arrays.asList : 把一个数组转换成list
//value.split("\\w+") :( 一条带有空格的消息)通过空格将消息分解成多个消息
//此处是一条消息,转换后变成多条消息
return Arrays.asList(value.split("\\W+"));
}
})
//设置sink主题:就是把test01主题的消息导流到这个test02主题
.to(TO_TOPIC);
//输出 kStream 对应的拓扑结构
System.err.println(builder.build().describe());
//直接返回 KStream 就可以了
//springboot 会自动将该 KStream 中的 Topology 对象封装到 kafkaStream 对象中,并开启导流功能
return kStream;
}
}
}
3、MessageController 控制层
生产者发送消息的接口
package cn.ljh.kafkaboot.controller;
import cn.ljh.kafkaboot.service.MessageService;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
/**
* author JH
*/
@RestController
public class MessageController
{
//业务层
public final MessageService messageService;
//构造器依赖注入
public MessageController(MessageService messageService)
{
this.messageService = messageService;
}
//发送带key的消息
@GetMapping("/send/{key}/{value}")
public String sendMessage(@PathVariable String key, @PathVariable String value){
//发送带key的消息成功
messageService.sendMessage(key,value);
return "发送带key的消息成功";
}
//发送不带key的消息
@GetMapping("/sendNoKey/{value}")
public String sendNoKey(@PathVariable String value)
{
//发送不带key的消息成功
messageService.sendMessage(null,value);
return "发送不带key的消息成功";
}
}
4、MessageService 业务层
送消息的业务逻辑
package cn.ljh.kafkaboot.service;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
import java.util.Objects;
/**
* author JH
*/
@Service
public class MessageService
{
//定义一个主题的常量
public static final String TARGET_TOPIC = "test2";
//因为没有自己写KafkaTemplate这个类,所以是没有初始化的,需要进行依赖注入才行
private final KafkaTemplate<String, String> kafkaTemplate;
//通过构造函数进行依赖注入
public MessageService(KafkaTemplate<String, String> kafkaTemplate)
{
this.kafkaTemplate = kafkaTemplate;
}
//发送消息
public void sendMessage(String key, String value)
{
//如果这个key不为空,则为true
if(Objects.nonNull(key))
{
//发送带 key、value的消息
kafkaTemplate.send(TARGET_TOPIC,key,value);
}
else
{
//发送不带 key 的消息
kafkaTemplate.send(TARGET_TOPIC,value);
}
}
}
5、KafkaMessageListener 消息监听器
监听器组件,在项目启动的时候也会自动加载这个监听器代码
package cn.ljh.kafkaboot.listener;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
/**
* @KafkaListener 注解修饰的方法会被注册为消息监听器方法。该注解支持如下常用的属性:
* topics- 指定要监听的主题
* topicPattern:指定要监听的主题的正则表达式
* topicPartitions:指定要监听的主题的分区
* groupId:指定组id
*/
// @Component是Spring框架中的一个通用注解,用于标记一个类为组件,让Spring能够在应用程序启动时自动扫描并加载这些组件
@Component
public class KafkaMessageListener
{
//因为这两个监听器不属于同一个组,相当于pub/sub模型,都能监听到同一个主题的消息
//监听器方法A:监听 test2 主题,这个监听器是属于groupA这个组
@KafkaListener(topics = "test2",groupId = "groupA")
public void processMsg01(ConsumerRecord<String,String> msg)
{
System.err.printf("监听器 【 A 】 收到消息, offset = %d , partition=%s , key = %s, value = %s%n",
msg.offset(),msg.partition(), msg.key(), msg.value());
}
//监听器方法B:监听 test2 主题,这个监听器是属于groupB这个组
@KafkaListener(topics = "test2",groupId = "groupB")
public void processMsg02(ConsumerRecord<String,String> msg)
{
System.err.printf("监听器 【 B 】 收到消息, offset = %d , partition=%s , key = %s, value = %s%n",
msg.offset(),msg.partition(), msg.key(), msg.value());
}
}
6、pom 依赖文件
主要是有 kafka 客户端的依赖 和 流 API 的依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.5</version>
</parent>
<groupId>cn.ljh</groupId>
<artifactId>kafkaboot</artifactId>
<version>1.0.0</version>
<name>kafkaboot</name>
<properties>
<java.version>11</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- springboot 最基础的web依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- kafka 的依赖 -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- 为使用 kafka 流 API 添加的依赖 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
7、启动Kafka命令汇总
kafka 运行环境的一些启动操作
1、启动 zookeeper 服务器端
小黑窗输入命令: zkServer
启动 zookeeper 的命令行客户端工具(不用启动这个,仅作为记录,跟启动环境无关)
小黑窗输入命令:zkCli -server 127.0.0.1:2181
2、启动 Kafka 服务器:
第1个kafka服务器,也就是第1个节点:9092
kafka-server-start E:/install/kafka_2.13-3.6.1/config/server.properties
第2个kafka服务器,也就是第2个节点:9093
kafka-server-start E:/install/kafka_2.13-3.6.1/config/server-1.properties
第3个kafka服务器,也就是第3个节点:9094
kafka-server-start E:/install/kafka_2.13-3.6.1/config/server-2.properties
3、打开小黑窗,运行如下命令来启动CMAK:
E:\cmak\bin\cmak.bat
4、打开CMAK图形界面
http://localhost:9000/
可以在小黑窗查看有哪些kafka命令(这个命令仅作为记录,跟启动环境无关)
kafka-topics
小黑窗启动效果如图:
CMAK 启动效果如图:

注意点,每次打开小黑窗,要重新运行命令来启动CMAK:
E:\cmak\bin\cmak.bat
需要把C盘的这个文件删除掉,重启启动生成才行,不然这个命令会运行失败
