铁轨语义分割(Unet结合resnet系列)
数据介绍
一类是图片,一类是图像标签。


引入库,处理数据
import torch.nn as nn
import torch
import torch.nn.functional as F
import os
from PIL import Image
import torch
from torch.utils.data import Dataset
import torchvision.transforms as transforms
from torch.utils.data import random_split
import cv2
import numpy as np
# 读取数据
class SemanticSegmentationDataset(Dataset):
def __init__(self, data_dir, transform=None):
self.data_dir = data_dir
self.transform = transform
self.images_dir = os.path.join(data_dir, 'Railsurfaceimages')
self.labels_dir = os.path.join(data_dir, 'GroundTruth')
self.filenames = sorted(os.listdir(self.images_dir))
def __len__(self):
return len(self.filenames)
def __getitem__(self, idx):
img_name = self.filenames[idx]
img_path = os.path.join(self.images_dir, img_name)
label_path = os.path.join(self.labels_dir, img_name)
image = Image.open(img_path)
label = Image.open(label_path)
image = np.array(image)
label = np.array(label)
image = image.reshape(1, image.shape[0], image.shape[1])
label = label.reshape(1, label.shape[0], label.shape[1])
# 标签操作
label[label<=122] = 0
label[label>122] = 1
return image, label
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
])
读取图像
# 读取图像
data_dir = 'C:/Users/jiaoyang/Desktop/数据集/RSDDs 数据集/RSDDs 数据集/Type-II RSDDs dataset'
dataset = SemanticSegmentationDataset(data_dir=data_dir,transform=transform)
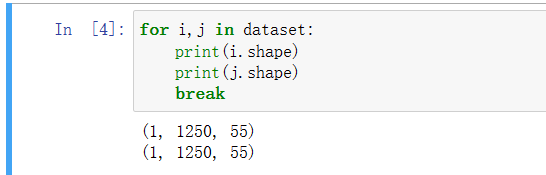
for i,j in dataset:
print(i.shape)
print(j.shape)
break
数据集划分
# 数据集的划分
val_size = int(len(dataset) * 0.1)
test_size = int(len(dataset)*0.1)
train_size = len(dataset) - val_size - test_size
train_dataset, val_dataset, test_dataset = random_split(dataset, [train_size, val_size, test_size],generator=torch.Generator().manual_seed(42))
读取数据
# 读取数据
batch_size=2
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=0)
查看数据
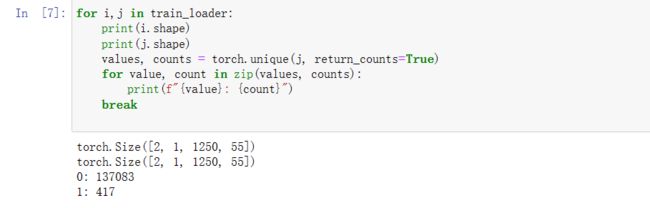
for i,j in train_loader:
print(i.shape)
print(j.shape)
values, counts = torch.unique(j, return_counts=True)
for value, count in zip(values, counts):
print(f"{value}: {count}")
break
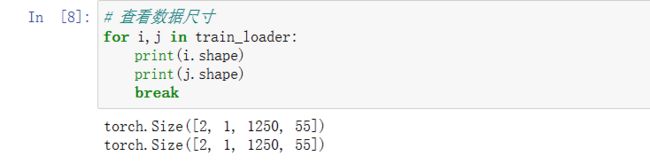
# 查看数据尺寸
for i,j in train_loader:
print(i.shape)
print(j.shape)
break
搭建网络
# 搭建网络
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = torch.tensor([x2.size()[2] - x1.size()[2]])
diffX = torch.tensor([x2.size()[3] - x1.size()[3]])
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=False):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
self.down4 = Down(512, 1024)
self.up1 = Up(1024, 512, bilinear)
self.up2 = Up(512, 256, bilinear)
self.up3 = Up(256, 128, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
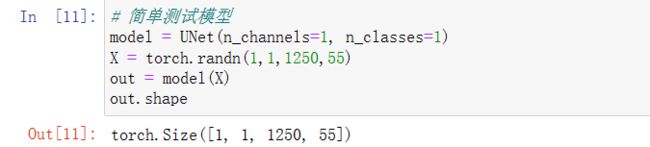
简单测试模型
# 简单测试模型
model = UNet(n_channels=1, n_classes=1)
X = torch.randn(1,1,1250,55)
out = model(X)
out.shape
训练函数及训练
设置训练参数
# 参数设置
lr=0.0001
#model = UNet(n_channels=1, n_classes=1).to(device='cuda', dtype=torch.float32)
optimizer = torch.optim.RMSprop(model.parameters(), lr=lr, weight_decay=1e-8, momentum=0.9)
criterion = nn.BCEWithLogitsLoss()
num_epochs = 50
训练函数
def train(model, criterion, optimizer, train_loader, val_loader, num_epochs,device='cuda'):
for epoch in range(num_epochs):
# 训练模式
model.train()
train_loss = 0.0
for images, masks in train_loader:
# 将数据移动到计算设备上
images = images.to(device,dtype=torch.float32)
masks = masks.to(device,dtype=torch.float32)
# 前向传播
outputs = model(images)
loss = criterion(outputs, masks)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item() * images.size(0)
# 验证模式
model.eval()
val_loss = 0.0
num_correct = 0
num_pixels = 0
with torch.no_grad():
for images, masks in val_loader:
# 将数据移动到计算设备上
images = images.to(device,dtype=torch.float32)
masks = masks.to(device,dtype=torch.float32)
# 前向传播
outputs = model(images)
loss = criterion(outputs, masks)
# 计算指标
val_loss += loss.item() * images.size(0)
outputs[outputs >= 0] = 255
outputs[outputs < 0] = 0
outputs[outputs==255] = 1
preds = outputs
num_correct += torch.sum(preds == masks).item()
num_pixels += torch.numel(preds)
train_loss /= len(train_dataset)
val_loss /= len(val_dataset)
accuracy = num_correct / num_pixels
# 打印训练过程中的相关指标
print('Epoch: {}, Train Loss: {:.4f}, Val Loss: {:.4f}, Accuracy: {:.4f}'.format(epoch+1, train_loss, val_loss, accuracy))
开始训练
train(model, criterion, optimizer, train_loader, val_loader, num_epochs)

保存及预测,各项评价指标
保存模型
# 保存模型
# 保存模型参数
PATH = "./data/resnet+unet++.pt"
torch.save(model.state_dict(), PATH)
加载模型参数
# 加载模型参数
# 创建一个新的模型
model = NestedUResnet(block=BasicBlock,layers=[3,4,6,3],num_classes=1).to(device='cuda', dtype=torch.float32)
# 加载之前保存的模型参数
PATH = "./data/resnet+unet++.pt"
model.load_state_dict(torch.load(PATH))
预测并保存图片
# 保存图片
for data,label in test_loader:
data = data.to(device='cuda',dtype=torch.float32)
out = model(data)
out[out >= 0] = 255
out[out < 0] = 0
out = out[0][0].cpu().detach().numpy()
#print(out)
label[label==1] = 255
label = label[0][0].cpu()
label = np.array(label)
cv2.imwrite('./data/label.png', label)
cv2.imwrite('./data/out.png', out)
break
for data,label in test_loader:
data = data.to(device='cuda',dtype=torch.float32)
out = model(data)
out[out >= 0] = 255
out[out < 0] = 0
out = out[1][0].cpu().detach().numpy()
#print(out)
label[label==1] = 255
label = label[1][0].cpu()
label = np.array(label)
cv2.imwrite('./data/label2.png', label)
cv2.imwrite('./data/out2.png', out)
break
计算混淆矩阵
# 计算混淆矩阵,0表示白色像素,表示正例
from sklearn.metrics import confusion_matrix
TP = []
FN = []
FP = []
TN = []
for data,label in test_loader:
data = data.to(device='cuda',dtype=torch.float32)
out = model(data)
out[out >= 0] = 255
out[out < 0] = 0
# 转换以便求混淆矩阵
out[out == 0] = 1
out[out == 255] = 0
label[label == 0] = 255
label[label == 1] = 0
label[label == 255] = 1
out = out.view(-1).cpu().detach().numpy()
label = label.view(-1).cpu().detach().numpy()
confusion = confusion_matrix(label, out)
TP.append(confusion[0][0])
FN.append(confusion[0][1])
FP.append(confusion[1][0])
TN.append(confusion[1][1])
TP = np.sum(np.array(TP))
FN = np.sum(np.array(FN))
FP = np.sum(np.array(FP))
TN = np.sum(np.array(TN))
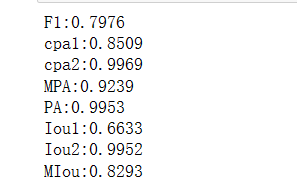
计算各项评价指标
# 计算各评价指标
# 计算F1的值
Precision = TP / (TP + FP)
Recall = TP / (TP + FN)
F1 = 2 * (Precision * Recall) / (Precision + Recall)
print('F1:{:.4f}'.format(F1))
# 类别像素准确率1
cpa1 = TP/(TP+FP)
print('cpa1:{:.4f}'.format(cpa1))
# 类别像素准确率2
cpa2 = TN / (TN + FN)
print('cpa2:{:.4f}'.format(cpa2))
# MPA
mpa = (cpa2+cpa1)/2
print('MPA:{:.4f}'.format(mpa))
# PA(像素准确率)
pa = (TP + TN) / (TP + TN + FP + FN)
print('PA:{:.4f}'.format(pa))
# 交并比1
Iou1 = TP/(TP+FP+FN)
print('Iou1:{:.4f}'.format(Iou1))
# 交并比2
Iou2 = TN / (TN + FN + FP)
print('Iou2:{:.4f}'.format(Iou2))
# MIou
MIou = (Iou1+Iou2)/2
print('MIou:{:.4f}'.format(MIou))
Unet++网络的搭建
class VGGBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.first = nn.Sequential(
nn.Conv2d(in_channels, middle_channels, 3, padding=1,bias = False),
nn.BatchNorm2d(middle_channels),
nn.ReLU(inplace = True)
)
self.second = nn.Sequential(
nn.Conv2d(middle_channels, out_channels, 3, padding=1,bias = False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace = True)
)
def forward(self, x):
out = self.first(x)
out = self.second(out)
return out
class Up(nn.Module): # 将x1上采样,然后调整为x2的大小
"""Upscaling then double conv"""
def __init__(self):
super().__init__()
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
def forward(self, x1, x2):
x1 = self.up(x1) # 将传入数据上采样,
diffY = torch.tensor([x2.size()[2] - x1.size()[2]])
diffX = torch.tensor([x2.size()[3] - x1.size()[3]])
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2]) # 填充为x2相同的大小
return x1
class UNetplusplus(nn.Module):
def __init__(self, num_classes, input_channels=1, deep_supervision=False, **kwargs):
super().__init__()
nb_filter = [64, 128, 256, 512,1024]
self.deep_supervision = deep_supervision
self.Up = Up()
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
self.conv0_1 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_1 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_1 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3])
self.conv0_2 = VGGBlock(nb_filter[0]*2+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_2 = VGGBlock(nb_filter[1]*2+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_2 = VGGBlock(nb_filter[2]*2+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv0_3 = VGGBlock(nb_filter[0]*3+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_3 = VGGBlock(nb_filter[1]*3+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv0_4 = VGGBlock(nb_filter[0]*4+nb_filter[1], nb_filter[0], nb_filter[0])
if self.deep_supervision:
self.final1 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final2 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final3 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final4 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
else:
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def forward(self, input):
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x0_1 = self.conv0_1(torch.cat([x0_0, self.Up(x1_0,x0_0)], 1))
x2_0 = self.conv2_0(self.pool(x1_0))
x1_1 = self.conv1_1(torch.cat([x1_0, self.Up(x2_0,x1_0)], 1))
x0_2 = self.conv0_2(torch.cat([x0_0, x0_1, self.Up(x1_1,x0_0)], 1))
x3_0 = self.conv3_0(self.pool(x2_0))
x2_1 = self.conv2_1(torch.cat([x2_0, self.Up(x3_0,x2_0)], 1))
x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.Up(x2_1,x1_0)], 1))
x0_3 = self.conv0_3(torch.cat([x0_0, x0_1, x0_2, self.Up(x1_2,x0_0)], 1))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.Up(x4_0,x3_0)], 1))
x2_2 = self.conv2_2(torch.cat([x2_0, x2_1, self.Up(x3_1,x2_0)], 1))
x1_3 = self.conv1_3(torch.cat([x1_0, x1_1, x1_2, self.Up(x2_2,x1_0)], 1))
x0_4 = self.conv0_4(torch.cat([x0_0, x0_1, x0_2, x0_3, self.Up(x1_3,x0_0)], 1))
if self.deep_supervision: #多个输出
output1 = self.final1(x0_1)
output2 = self.final2(x0_2)
output3 = self.final3(x0_3)
output4 = self.final4(x0_4)
return [output1, output2, output3, output4]
else:
output = self.final(x0_4)
return output
简单测试模型
# 简单测试模型
model = UNetplusplus(1)
x = torch.rand(1,1,1250,55)
out = model(x)
print(out.shape)

resnet+unet网络的搭建
class Up(nn.Module): # 将x1上采样,然后调整为x2的大小
"""Upscaling then double conv"""
def __init__(self):
super().__init__()
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
def forward(self, x1, x2):
x1 = self.up(x1) # 将传入数据上采样,
diffY = torch.tensor([x2.size()[2] - x1.size()[2]])
diffX = torch.tensor([x2.size()[3] - x1.size()[3]])
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2]) # 填充为x2相同的大小
return x1
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BasicBlock.expansion, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != BasicBlock.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BasicBlock.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class BottleNeck(nn.Module):
expansion = 4
'''
espansion是通道扩充的比例
注意实际输出channel = middle_channels * BottleNeck.expansion
'''
def __init__(self, in_channels, middle_channels, stride=1):
super().__init__()
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, middle_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(middle_channels),
nn.ReLU(inplace=True),
nn.Conv2d(middle_channels, middle_channels, stride=stride, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(middle_channels),
nn.ReLU(inplace=True),
nn.Conv2d(middle_channels, middle_channels * BottleNeck.expansion, kernel_size=1, bias=False),
nn.BatchNorm2d(middle_channels * BottleNeck.expansion),
)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != middle_channels * BottleNeck.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, middle_channels * BottleNeck.expansion, stride=stride, kernel_size=1, bias=False),
nn.BatchNorm2d(middle_channels * BottleNeck.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class VGGBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.first = nn.Sequential(
nn.Conv2d(in_channels, middle_channels, 3, padding=1),
nn.BatchNorm2d(middle_channels),
nn.ReLU()
)
self.second = nn.Sequential(
nn.Conv2d(middle_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU()
)
def forward(self, x):
out = self.first(x)
out = self.second(out)
return out
class UResnet(nn.Module):
def __init__(self, block, layers, num_classes, input_channels=1):
super().__init__()
nb_filter = [64, 128, 256, 512, 1024]
self.Up = Up()
self.in_channel = nb_filter[0]
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = self._make_layer(block,nb_filter[1], layers[0], 1)
self.conv2_0 = self._make_layer(block,nb_filter[2], layers[1], 1)
self.conv3_0 = self._make_layer(block,nb_filter[3], layers[2], 1)
self.conv4_0 = self._make_layer(block,nb_filter[4], layers[3], 1)
self.conv3_1 = VGGBlock((nb_filter[3] + nb_filter[4]) * block.expansion, nb_filter[3],
nb_filter[3] * block.expansion)
self.conv2_2 = VGGBlock((nb_filter[2] + nb_filter[3]) * block.expansion, nb_filter[2],
nb_filter[2] * block.expansion)
self.conv1_3 = VGGBlock((nb_filter[1] + nb_filter[2]) * block.expansion, nb_filter[1],
nb_filter[1] * block.expansion)
self.conv0_4 = VGGBlock(nb_filter[0] + nb_filter[1] * block.expansion, nb_filter[0], nb_filter[0])
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def _make_layer(self, block,middle_channel, num_blocks, stride):
'''
middle_channels中间维度,实际输出channels = middle_channels * block.expansion
num_blocks,一个Layer包含block的个数
'''
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channel, middle_channel, stride))
self.in_channel = middle_channel * block.expansion
return nn.Sequential(*layers)
def forward(self, input):
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x2_0 = self.conv2_0(self.pool(x1_0))
x3_0 = self.conv3_0(self.pool(x2_0))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.Up(x4_0,x3_0)], 1))
x2_2 = self.conv2_2(torch.cat([x2_0, self.Up(x3_1,x2_0)], 1))
x1_3 = self.conv1_3(torch.cat([x1_0, self.Up(x2_2,x1_0)], 1))
x0_4 = self.conv0_4(torch.cat([x0_0, self.Up(x1_3,x0_0)], 1))
output = self.final(x0_4)
return output
简单测试模型
UResnet34 = UResnet(block=BasicBlock,layers=[3,4,6,3],num_classes=1)
x = torch.rand(1,1,1250,55)
out = UResnet34(x)
print(out.shape)

resnet+unet++网络的搭建
class VGGBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.first = nn.Sequential(
nn.Conv2d(in_channels, middle_channels, 3, padding=1,bias=False),
nn.BatchNorm2d(middle_channels),
nn.ReLU(inplace = True)
)
self.second = nn.Sequential(
nn.Conv2d(middle_channels, out_channels, 3, padding=1,bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace = True)
)
def forward(self, x):
out = self.first(x)
out = self.second(out)
return out
class Up(nn.Module): # 将x1上采样,然后调整为x2的大小
"""Upscaling then double conv"""
def __init__(self):
super().__init__()
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
def forward(self, x1, x2):
x1 = self.up(x1) # 将传入数据上采样,
diffY = torch.tensor([x2.size()[2] - x1.size()[2]])
diffX = torch.tensor([x2.size()[3] - x1.size()[3]])
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2]) # 填充为x2相同的大小
return x1
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BasicBlock.expansion, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != BasicBlock.expansion * out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BasicBlock.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * BasicBlock.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class BottleNeck(nn.Module):
expansion = 4
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.residual_function = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, stride=stride, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels * BottleNeck.expansion, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels * BottleNeck.expansion),
)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels * BottleNeck.expansion:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * BottleNeck.expansion, stride=stride, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels * BottleNeck.expansion)
)
def forward(self, x):
return nn.ReLU(inplace=True)(self.residual_function(x) + self.shortcut(x))
class NestedUResnet(nn.Module):
def __init__(self,block,layers,num_classes, input_channels=1, deep_supervision=False):
super().__init__()
nb_filter = [64, 128, 256, 512, 1024]
self.in_channels = nb_filter[0]
self.relu = nn.ReLU()
self.deep_supervision = deep_supervision
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.Up = Up()
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = self._make_layer(block,nb_filter[1],layers[0],1)
self.conv2_0 = self._make_layer(block,nb_filter[2],layers[1],1)
self.conv3_0 = self._make_layer(block,nb_filter[3],layers[2],1)
self.conv4_0 = self._make_layer(block,nb_filter[4],layers[3],1)
self.conv0_1 = VGGBlock(nb_filter[0] + nb_filter[1] * block.expansion, nb_filter[0], nb_filter[0])
self.conv1_1 = VGGBlock((nb_filter[1] +nb_filter[2]) * block.expansion, nb_filter[1], nb_filter[1] * block.expansion)
self.conv2_1 = VGGBlock((nb_filter[2] +nb_filter[3]) * block.expansion, nb_filter[2], nb_filter[2] * block.expansion)
self.conv3_1 = VGGBlock((nb_filter[3] +nb_filter[4]) * block.expansion, nb_filter[3], nb_filter[3] * block.expansion)
self.conv0_2 = VGGBlock(nb_filter[0]*2+nb_filter[1] * block.expansion, nb_filter[0], nb_filter[0])
self.conv1_2 = VGGBlock((nb_filter[1]*2+nb_filter[2]) * block.expansion, nb_filter[1], nb_filter[1] * block.expansion)
self.conv2_2 = VGGBlock((nb_filter[2]*2+nb_filter[3]) * block.expansion, nb_filter[2], nb_filter[2] * block.expansion)
self.conv0_3 = VGGBlock(nb_filter[0]*3+nb_filter[1] * block.expansion, nb_filter[0], nb_filter[0])
self.conv1_3 = VGGBlock((nb_filter[1]*3+nb_filter[2]) * block.expansion, nb_filter[1], nb_filter[1] * block.expansion)
self.conv0_4 = VGGBlock(nb_filter[0]*4+nb_filter[1] * block.expansion, nb_filter[0], nb_filter[0])
if self.deep_supervision:
self.final1 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final2 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final3 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final4 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
else:
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def _make_layer(self,block, middle_channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, middle_channels, stride))
self.in_channels = middle_channels * block.expansion
return nn.Sequential(*layers)
def forward(self, input):
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x0_1 = self.conv0_1(torch.cat([x0_0, self.Up(x1_0,x0_0)], 1))
x2_0 = self.conv2_0(self.pool(x1_0))
x1_1 = self.conv1_1(torch.cat([x1_0, self.Up(x2_0,x1_0)], 1))
x0_2 = self.conv0_2(torch.cat([x0_0, x0_1, self.Up(x1_1,x0_0)], 1))
x3_0 = self.conv3_0(self.pool(x2_0))
x2_1 = self.conv2_1(torch.cat([x2_0, self.Up(x3_0,x2_0)], 1))
x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.Up(x2_1,x1_0)], 1))
x0_3 = self.conv0_3(torch.cat([x0_0, x0_1, x0_2, self.Up(x1_2,x0_0)], 1))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.Up(x4_0,x3_0)], 1))
x2_2 = self.conv2_2(torch.cat([x2_0, x2_1, self.Up(x3_1,x2_0)], 1))
x1_3 = self.conv1_3(torch.cat([x1_0, x1_1, x1_2, self.Up(x2_2,x1_0)], 1))
x0_4 = self.conv0_4(torch.cat([x0_0, x0_1, x0_2, x0_3, self.Up(x1_3,x0_0)], 1))
if self.deep_supervision:
output1 = self.final1(x0_1)
output2 = self.final2(x0_2)
output3 = self.final3(x0_3)
output4 = self.final4(x0_4)
return [output1, output2, output3, output4]
else:
output = self.final(x0_4)
return output
简单测试模型
model = NestedUResnet(block=BottleNeck,layers=[3,4,6,3],num_classes=1)
x = torch.rand(1,1,1250,55)
out = model(x)
print(out.shape)
