虚拟化平台 3.0 时代,360 依然是 OpenStack 的坚定拥护者
 本文源自 6 月 15 日『高效开发运维』微信群的在线分享,转载请在文章开头注明来自『高效开发运维』公众号。加群学习请关注『高效开发运维』公众号,并点击菜单中的“加群学习”或直接回复“加群”。
本文源自 6 月 15 日『高效开发运维』微信群的在线分享,转载请在文章开头注明来自『高效开发运维』公众号。加群学习请关注『高效开发运维』公众号,并点击菜单中的“加群学习”或直接回复“加群”。

(1) 第一个阶段是早期虚拟化阶段。在这个阶段虚拟化技术相对不是特别成熟,从性能方面、硬件支持方面、技术实现等方面都相对薄弱。周边工具也不是特别完善,整个虚拟机性能、使用便捷性都不是特别高,正是由于这些不足 促使我们使用了最新的一些虚拟化技术栈来构建当前的虚拟化平台,也就是 2.0 阶段。
(2)这个阶段,虚拟化技术日趋完善、整个的虚拟化技术栈也变得非常丰富。再加上云计算概念的出现,大大加快了虚拟化技术的发展。虚拟化的资源规模不断的增大,围绕基础设施资源为中心的工具、平台等都趋于完善。
(3)第三个阶段是以应用为核心的阶段,这也是我们目前在做的一项工作—容器化。容器化前几年吵得比较火,目前很多企业已经开始慢慢将服务容器化,微服务化,这个也是一个行业趋势。
当前,阶段 1 的虚拟化平台我们还在使用,很多之前的业务也都在上面运行着。但由于这个阶段的虚拟化平台功能有限:譬如机器创建速度很慢(有时创建云主机可以达到 30 分钟)、快照创建特别慢、宿主机故障时不支持热迁移等等。因此,我们很需要一个性能高、创建速度快、故障时能快速迁移虚拟化平台 -- 也就是我们的 Ultron。Ultron 已成为了我们当前的主力。新的云主机基本都是通过 Ultron 来提供的。
Ultron 是 360 Web 平台部为满足公司业务对弹性云主机等资源需求,于 2015 年 7 月基于 OpenStack 研发的内部虚拟化 (IaaS) 平台。Ultron 是 HULK 云平台的核心组成部分,致力于为公司各个业务提供高性能、稳定的适用于各种场景需求的虚拟化解决方案。
Ultron 又叫“奥创”,是美国漫威漫画旗下的超级英雄。拥有天才级的智慧,创造性智力和自我修复能力,可以将部分或全部程序传送到远方的计算机系统或机器身体中,远程控制其他机器。能够以超人的速度准确计算和处理信息。选择 Ultron 作为虚拟化的项目名,就是希望我们的虚拟化平台,能够像 Ultron 一样能够控制成千上万的机器,提供更快的计算的能力和更强大的扩缩容能力。

Ultron 最核心的功能就是给各个业务线提供虚拟机了。
技术选型的话:
平台:是 OpenStack,目前主要用到的组件有 Keystone、Glance、Nova、Neutron、Cinder
存储:是本地存储和 Ceph 共享存储共存
网络:是 Vlan 模式和 Vxlan 模式混跑
在 OpenStack 的基础上为了对接公司现有的一些系统,我们做了很多集成和定制化的工作。像公司的账号系统、CMDB 系统、网络系统等等。这也许就是企业内部私有云都要做的一些事情吧~

Ultron 从 2015 年 7 月份立项、技术调研、测试、管理端开发,到 11 月份上线创建第 1 台虚拟机我们大约花费了 4 个月的时间(在此期间,我们还开发了一套公有云平台,后来由于某些原因放弃掉了~)。
刚开始,从稳定性和性能层面考虑,我们采用的是本地存储 +Vlan 网络模式的方案。后来经过一段时间的调研和研究,我们又尝试着引入了 Ceph 共享存储和基于 Vxlan 的大二层网络,来提供一些高级的功能。然后就是整个 2016 年,我们主要是处理平台中遇到的一些问题和做一些性能上的优化,在年底我们还做了一件“大事”,跨版本升级 OpenStack(Kilo-->Mitaka)。17 年的话,Ultron 我们没有做太多工作,我们的工作重心转移到了容器化上面。

(1)Ultron 目前支持公司 90% 以上的线上业务。
(2)Ultron 分布在北京、上海、广州、郑州、廊坊等 9 个机房。
(3)Ultron 当前已有物理节点 1183 台、虚拟机 5944 台(本地存储和基于 Ceph 的共享存储混跑)。
初期 Ceph 本身成熟度不是很高,鉴于对平台稳定性及对业务负责任的态度,我们以本地存储为主,共享存储为辅的混跑模式。随着 Ceph 本身的稳定和实际线上业务运行的经验,我们觉得基于 Ceph 的共享存储的云主机已经可以作为主要类型来使用。后期我们资源的上线也会以共享存储为主。
首先它是开源的。(对,这很重要。省钱哈......)
其次 OpenStack 自 2010.1 诞生以来便担任着开源云技术的“颜值担当”,也是 IaaS 平台的事实上的标准。不管是从技术的完备角度还是社区的支持力度都是其它开源云平台难以媲美的。经过 5 年 (截止 2015 年 7 月我们研发时) 社区的打磨,OpenStack 已经逐渐褪去最初的青涩与稚嫩,成为了全球发展最快的开源项目。OpenStack 社区成为了仅次于 Linux 的全球第二大活跃的开源社区,世界 100 强企业中近 50% 的企业采用了 OpenStack,开发者、用户遍及全球。(其它的就不用我多解释了,我都觉得不用它,都对不住社区。)
1、组件
目前我们使用到的组件有:keystone、glance、cinder、nova、neutron。
2、逻辑架构

(1)控制节点 Active/Active 模式高可用
(2)Rabbitmq 采用 mirror 模式
(3)本地存储虚拟机 HA 由上层应用层决定
业务自己选择在不同机房创建多台,保证业务不会因机房割接等中断
(4) 共享存储虚拟机 HA 既可由底层存储保证也可由上层应用层保证,更灵活
共享存储模式的虚拟机在宿主机故障时可以使用热迁移方式进行迁移和快速恢复
3、做的一些工作


初期技术调研阶段,我们的部署还比较简单、粗暴。基本上就是按照 OpenStack 官方文档一步一步的搞,部署一套测试环境非常耗时,而且非常痛苦。后来,随着我们对 OpenStack 认识的加深,我们开始调研社区主流的自动化部署工具,像 Puppet、Fuel、Ansible 等,最终从上手速度和复杂度角度考虑,我们选择 Ansible。
对于 OpenStak 的部署,我们分为四个部分:
(1)系统级别的初始化。主要是完成一些操作系统参数的调整、NTP 服务和网卡、yum 源设置等通用设置。
(2)控制节点部署。主要是完成 OpenStack 控制节点组件的安装和配置。
(3)网络节点部署。主要是完成 OpenStack 网络组件的安装和配置及监控代理的安装。
(4)计算节点部署。主要是完成 OpenStack 计算组件的安装和配置及其它辅助工具的安装。
目前,针对 OpenStack 的部署,我们的 Ansible 大约使用了 50 个 role。

基于 vxlan 大二层和 ceph 共享存储,我们可以使用很多高级功能。
(1)虚拟机秒级创建
本地存储创建虚拟机时需要先拉取镜像到计算节点本地,如果镜像比较大会比较耗时。
基于 Ceph 共享存储虚拟机创建时无需从 Glance 下载镜像到本地,所以虚拟机的启动非常快。
(2)虚拟机的秒级热迁移
OpenStack 中支持冷迁移和热迁移。冷迁移是将虚拟机磁盘数据和配置通过网络拷贝到新的计算节点。我们知道虚拟机磁盘数据一般都比较大几十 GB 到几百 GB 不等,所以该过程非常耗时且消耗带宽,个人感觉其应用价值不大。而热迁移通过利用 vxlan 大二层和共享存储的优势,“无需”拷贝虚拟机磁盘数据,只需拷贝少量内存数据和虚拟机配置到新的节点即可,整个过程非常快,以秒计,而且虚拟机网络不中断,内部业务无影响。
通过热迁移我么可以在计算节点故障时将云主机快速迁移,保证业务不中断;通过热迁移我们还可以在计算节点资源紧张时将虚拟机迁移到资源充足的节点,减少因资源征用对业务的影响。
(3)虚拟机分钟级别创建快照
与本地存储相比,基于 Ceph 的共享存储的虚拟机在创建快照时,无需快照上传的过程。整个过程全部在 Ceph 端完成,所以速度上要远远地快于本地存储。
虚拟机高可用
Ceph 数据三副本机制,一方面保证了虚拟机数据丢失的可能性大大降低;另一方面当虚拟机所在计算节点故障时,虚拟机的数据任然在 Ceph 共享存储中,可以很快的在其它计算节点重新启动虚拟机,保证虚拟机“不丢失”,可恢复。

针对 OpenStack 我们主要是做了三方面的监控:
(1)基于公司现有的监控系统 Wonder 实现对节点 OS 级别监控。
像节点的 CPU、内存、磁盘、网络、存活等基础监控都是通过 Wonder 来实现收集和报警。有关 Wonder 我们之前有过详细的介绍,感兴趣的移步这里 http://www.infoq.com/cn/articles/360-wonder-monitoring-system
(2)基于开源监控二次开发,实现对 OpenStack 组件存活的监控。
Wonder 实现了 OS 层面的监控,对于 OpenStack 组件的存活和其是否正常工作也是我们非常关心的,经过调研我们通过对社区开源的监控组件进行二次开发,然后对接 Wonder 实现。该监控不仅仅是组件的存活,我们还模拟用户真实操作,调用 OpenStack Api 实现资源查看、创建等基本操作来监控组件是否正常工作。
(3)基于 ELK 实现对 OpenStack 组件的日志监控。
有时候,系统状态正常、OpenStack 进程也是存活的,资源增删也是 OK,但是由于是 Active/Active 模式,其中一个 controller 服务或者 agent 服务有问题,我们也检测不到;特别是计算节点众多,某个 nova-compute、libvirt 组件有问题,我们不能第一时间发现。作为运维我们是不能忍的。怎么办呢?有问题查日志,这是我们技术人员定位问题的第一法宝,因此,通过 ELK 对节点上日志的收集与分析来监控服务的健康状况是非常必要的。
在近 2 年的时间内,通过 ELK 对日志的监控、分析我们及时发现的问题举例:
Libvirt 证书过期
Rbd 连接异常
组件连接 rabbitmq 异常
虚拟机创建失败
......

引入 Rally 框架对平台进行基本功能测试和并发性能测试等。
任何系统上线前肯定都要经过各种测试,以便管理员对其稳定性和性能有个清晰的认识。对于当前资源池能够支持的量和后期的资源规划都非常有帮助。鉴于此,我们在平台上线前也对其进行了一定程度的测试。

我们也参考社区对平台进行了一系列的调优。
(1)超卖。目前只超卖 CPU,内存和磁盘都不超卖。根据我们实际线上跑的情况,超卖内存会经常出现虚拟机 OOM 的问题 、超卖磁盘会出现宿主机磁盘满的问题。
(2)NUMA。我们都知道 NUMA 架构每个处理器都可以访问自己和别的处理器的存储器,访问自己的存储器要比访问别的存储器的快很多,NUMA 调优的目标就是让处理器尽量的访问自己的存储器,提高 cache 的命中率,提高处理速度。在 Kilo 版本中 OpenStack 已经开始了对 NUMA 的支持,Mitaka 版本中支持的更加完善。
(3)KSM。内核共享存储,该特性可以使得不同的处理器共享相同内容的内存页。内核会主动扫描内存,合并内容相同的内存页。如果有处理器改变这个共享的内存页时,会采用写时复制的方式写入新的内存页。当一台主机上的多台虚拟机使用相同操作系统或者虚拟机使用很多相同内容内存页时,KSM 可以显著提高内存的利用率。因为内存扫描的消耗,使用 KSM 的代价是增加了 CPU 的负载,并且如果虚拟机突然做写操作时,会引发大量共享的页面,此时会存在潜在的内存压力峰值,超过一定的水平限制,将会引发大量不可预知的 swap 操作,甚至引发 OOM。因为,其比较消耗 CPU,所以我们默认是给它关闭的,只有当节点内存压力较大时,用来合并内存,来增加内存的可用空间。
(4)DPDK。引入 DPDK 技术,来提高虚拟机数据包的处理速度和吞吐量。
(5)Ceph 的一系列调优。像使用 rbd cache、cache tier 等。
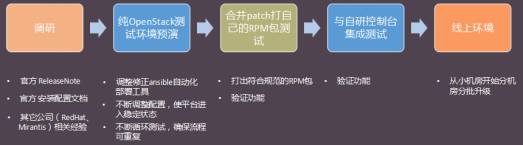
平台最初使用的是 Kilo 版本,为了使用一些高级功能(像 DPDK),我们在 16 年底对所有机房进行了跨版本升级,跨过 Liberty 直接升级到 Mitaka。在整个升级过程中遇到了不少坑(像 RPC 版本不兼容问题、kombu 库依赖版本不匹配问题、之前添加的 patch 与新版本集成等)。
合理规划资源逻辑区域,资源调度更灵活
外界限制,从软件角度加以规避,加快项目进度(主要是与公司内部现有周边系统集成的限制)
基础服务、ELK 日志监控,ansible 部署,提高运维效率(工具要到位,减少无畏的人为劳动)
限制虚拟机创建、启动并发量,避免启动风暴
规划存储需要根据线上业务建立模型评估性能、容量、规模
超卖等设置合理,磁盘是问题(qcow2 格式虚拟机磁盘使用率很低、 xfs 碎片激增导致虚拟机 qemu 进程成为僵尸进程)
RabbitMQ 与 erlang 版本匹配(版本不匹配会造成内存吃的非常厉害,最终导致宿主机宕机。我们当前使用的 rabbitmq-server-3.6.1-1、erlang-R16B-03.11,目前运行良好)
A1:这里虚拟机理论带宽是可以跑满宿主机网卡带宽的,DPDK 在一定程度上瓶颈在于 CPU 上或者说在小包的处理能力上目前我们测试的几个点
(1). 以 64byte 最小包做测试,1GB 网卡,PPS(packet per second)的理论上限是:148.8 万包 / 每秒
(2). 内核的 vhost-net 下,虚拟机的 1GB 网卡只能达到约 17 万
(3). ovs-dpdk 下,虚拟机的 1GB 网卡,达到了 126 万,几乎达到理论峰值(没有达到,还有可能 CPU 已经是瓶颈了)(4). ovs-dpdk 是 vhost-net 大约 7 倍的性能
A2:我们是做了划分的,目前我们每个机房一个 region,这些 region 公用一个 keystone。

A3:我们当前其实做的还比较简单, 匹配 error 信息后,我们会将整个抛出的异常栈日志信息通过邮件的形式发送出来。
A4: 这个更多的是要看公司对存储的 cover 的能力和成本的考虑吧。 再就是对于和 OpenStack 结合而言,没有比 Ceph 更合适的了.
A5: 我们是功能驱动的,如果新版本没有我们需要的功能,我们也不会做升级。目前我们做了一个跨版本的升级,当前是 Mitaka 版本。
A6: 哈,这个问题。 首先 RabbitMQ 是官方默认的消息队列组件(刚开始也没得选);其次 rabbitmq 性能、稳定性等都能够扛得住当前的规模具体坑的话:
erlang 和 rabbitmq 的版本要匹配
网络分区问题
内存疯长问题(也是由于版本不匹配导致)
A7: 这个话题比较大,不便细说 但是“似乎很多人并不是很看好?” 这个观点不知道从哪来的, 当前全球百强企业 50% 左右都已经使用了~
A8: 一个 region 最多承载多少台节点,这个要看多个方面:你的网络架构是什么样的?存储模式等等。当前我们最大的 region 有接近 400 个计算节点(当然,还会继续增长)
A9: 目前我们是 9 个 region,两个 keystone 节点,运行良好(keystone 支持多种 token 的生成方式,选择一个最合适的)。扩展的话,加节点呗。我们使用 OpenStack 就是创建虚拟机,频率不是非常高的话,keystone 的压力并没有很大。
A10:主要 3 个阶段吧,最早的时候是把容器当虚拟机用,然后是将容器跑在业务申请的虚拟机里面的,目前我们是将容器直接跑在物理机上的。
A11:后者,其实数据库部分我们是不关心的,我们有强大的 DBA 团队,我们只管用~ 哈哈 (DBA 很贴心的)
A12: 两者都是云管理平台~,且都是开源的。就成熟度而言 cloudstack 可能略高(毕竟最初是商用产品),不过 OpenStack 发展到现在也已经非常成熟了。具体使用哪个要根据企业的实际需求。
A13: 对,目前我们是 uuid。
A14: 我们虚拟机任然存在,看业务的需求了,容器不是银弹,有些系统不太适合或者短时间内不能容器化,这些系统还是会跑在虚拟机上的。当然,我们尽力去将业务容器化,微服务化。
2017 年,有哪些值得关注的运维技术热点?智能化运维、Serverless、DevOps ......CNUTCon 全球运维技术大会将于 9 月上海举办,12 位大牛联合出品,揭秘最前沿运维技术,推荐学习!点击“阅读原文”,先睹为快!
 点击阅读原文,移步阅读。
点击阅读原文,移步阅读。