python_蓝桥杯刷题记录_笔记_入门3
前言
记录我的解法以及笔记思路,谢谢观看。
题单目录
1.P2141 [NOIP2014 普及组] 珠心算测验
2.P1567 统计天数
3.P1055 [NOIP2008 普及组] ISBN 号码
4.P1200 [USACO1.1] 你的飞碟在这儿 Your Ride Is Here
5.P1308 [NOIP2011 普及组] 统计单词数
6.P1047 [NOIP2005 普及组] 校门外的树
7.P1046 [NOIP2005 普及组] 陶陶摘苹果
8.P1553 数字反转(升级版)
9.P1598 垂直柱状图
1.P2141 [NOIP2014 普及组] 珠心算测验
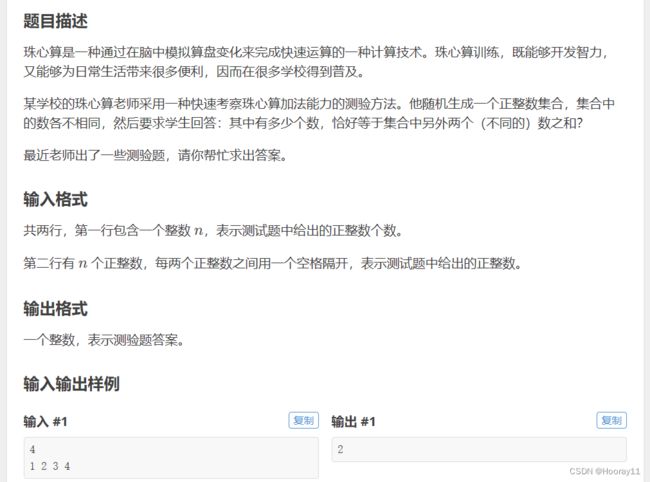
这一道题我是有参考网上的一个大佬的思路来的,但是那个大佬的代码只有两行,很显然我现在的能力达不到就写成了我自己能够理解的样子。
那python有一个容器是集合,关于python中集合的定义跟数学其实差不多,第一次的写的时候没有注意到题目中说得加数与被加数要不相同,所以无法通过。
然后我又开始一直纠结怎么解决,增加了好多判断条件,然后看到大佬直接用集合就可以解决了,所以这个方法一定要记住。
其次,这个大佬还用到了集合的一个函数方法,就是交集,总之思路真的很绝。
intersection() 方法:
用于返回两个或更多集合中都包含的元素,即交集。
intersection() 方法语法:
set.intersection(set1, set2 ... etc)
n = int(input())
l = set(map(int,input().split(' ')))
s = []
count = 0
for i in l:
for j in l:
if i!=j:
s.append(i+j)
s = set(s)
count = len(s.intersection(l))
print(count)2.P1567 统计天数

循环外层必须再要加一个判断,不然就会有一个测试点过不了。
输入:
2
1 2
输出:
不加外层循环输出的是1,但是其实我们知道结果是2
因为在天数一直都处于增加的状态的时候,到最后一天的时候就直接跳出了循环。并不会执行else。
n = int(input())
l = list(map(int,input().split(' ')))
count = 0
flag = 1
last = 0
for i in l:
if i > last:
count += 1
else:
if count > flag:
flag = count
count = 1
last = i
if count > flag:
flag = count
print(flag)3.P1055 [NOIP2008 普及组] ISBN 号码

这道题一开始我想着得是用字符串去做,后来发现很不方便,就是在修改字符串的数值方面远不如列表,换用上了列表就方便很多了。
s = list(input())
flag = 0
count = 1
for i in range(len(s)-1):
if i!=1 and i!=5 and i!=11:
flag += int(s[i])*count
count += 1
num = flag%11
if num == 10:
num = 'X'
if str(num) == s[-1]:
print('Right')
else:
s[-1] = str(num)
for i in s:
print(i,end='')4.P1200 [USACO1.1] 你的飞碟在这儿 Your Ride Is Here

这道题就是关于字母转为ascii数字的问题,要用到一个函数。ord函数。可以直接将字符串转为数字。
ord() 函数:
返回对应的 ASCII 数值
l1 = list(input())
l2 = list(input())
result1 = 1
result2 = 1
for i in l1:
result1 *= (ord(i)-ord('A'))+1
for i in l2:
result2 *= (ord(i)-ord('A'))+1
if result1%47 == result2%47:
print('GO')
else:
print('STAY')
5.P1308 [NOIP2011 普及组] 统计单词数
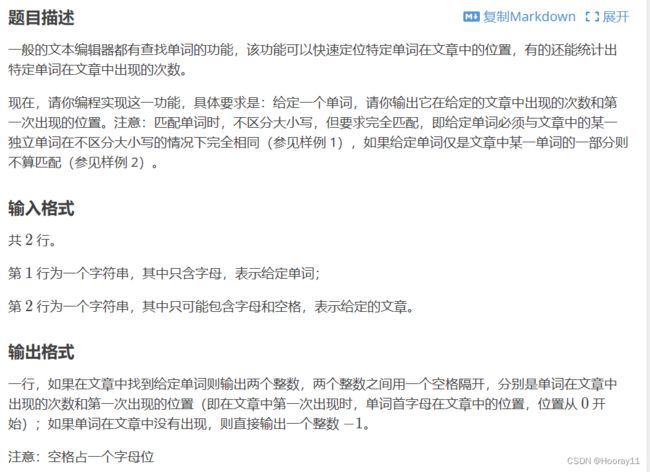
这道题的解法我是看了一个大佬的代码,因为我自己实在是写不出来,大佬的思路简直就是我无法想到的,非常值得学习。大佬还贴心写出来了注释,很好看懂。
s1=input()#输入要查询的单词
s1=s1.upper()#将单词转成大写
x=len(s1)#s1字符串的长度
s2=input()#输入文章
s3=[]#s3每次提取文章的一个单词
y=len(s2)#s2字符串长度
sum=0#sum记录单词出现在文章中的次数
begin=-1#begin记录单词第一次出现在文章中的位置
for i in range(y):
if(s2[i]!=' '):
s3.append(s2[i].upper())#将一个完整的单词放入s3中
else:
if(list(s1)==s3):#比较单词和s3所储存的单词是否相同
sum+=1#如果相同次数加一
if(begin==-1):#首次出现特定单词
begin=i-x#首次出现的位置
s3.clear()#清空准备下一个单词
if(sum>0):
print(sum, begin)
else:
print(-1)#未查询到输出-1
6.P1047 [NOIP2005 普及组] 校门外的树

这道题就是运用了集合中元素的互异性。
l,m = map(int,input().split(' '))
a = []
for i in range(m):
u,v = map(int,input().split(' '))
for i in range(u,v+1):
a.append(i)
a = set(a)
print(f'{l - len(a)+1}')7.P1046 [NOIP2005 普及组] 陶陶摘苹果
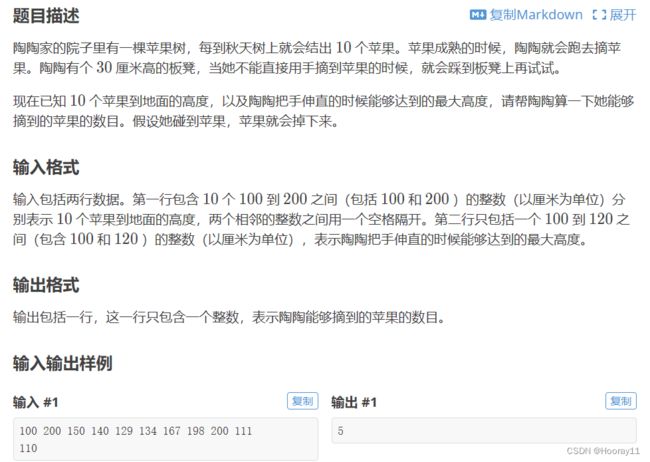
l = list(input().split(' '))
h = int(input())
count = 0
for i in l:
if h+30 >= int(i):
count += 1
print(count)8.P1553 数字反转(升级版)
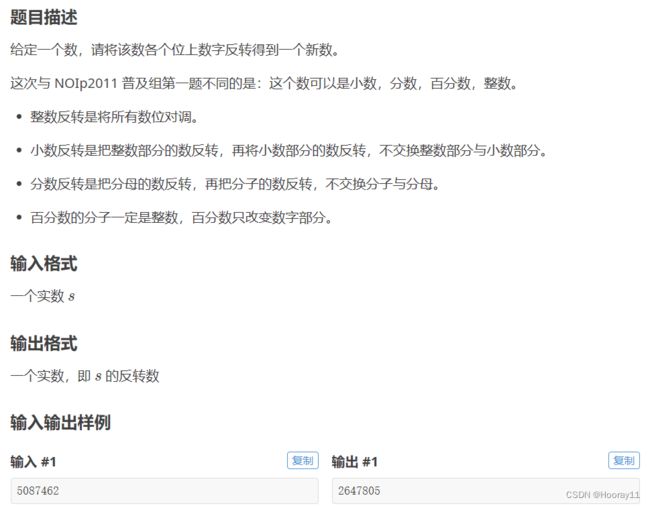
这道题写出100分实在是太难了,在下载了洛谷提供的多次数据之后终于全部 AC,因为情况很多,所以必须得考虑得/十分仔细。其实这道题的思路就是比较简单的,分不同情况进行处理,但是本质上都是对整数的处理。最难的情况是小数,因为在数字进行反转的时候0不能在开头,对于小数点的前一部分的反转,直接转变为Int之后就不用考虑那些0,但是对于小数点后面的数字就比较麻烦,这个时候就需要重新寻找pos的数值。但是这个时候我们必须考虑到如果小数点的右边只有一个0,按照我的那个方法是会报错的,所以我加了一个try语法就解决了。
find函数:
如果包含子字符串返回开始的索引值,否则返回-1。
s = input()
if '.' in s:
pos = s.find('.')
s1 = ''
s2 = ''
s3 = ''
for i in range(0,pos):
s1 +=s[pos-i-1]
print(int(s1),end='')
print('.',end='')
try:
for i in range(pos+1,len(s)):
if s[i] != '0':
pos2 = i
break
for j in range(len(s)-1,pos2-1,-1):
s3 += s[j]
print(int(s3))
except:
print("0")
elif '/' in s:
pos = s.find('/')
s1 = ''
s2 = ''
for i in range(0, pos):
s1 += s[pos - i - 1]
print(int(s1),end='')
print('/', end='')
for j in range(len(s) - 1, pos, -1):
s2 += s[j]
print(int(s2))
elif '%' in s:
pos = s.find('%')
s1 = ''
for i in range(0, pos):
s1 += s[pos - i - 1]
print(int(s1), end='')
print('%', end='')
else:
s1 = ''
for i in range(0,len(s)):
s1 += s[len(s)-i-1]
print(int(s1))9.P1598 垂直柱状图

简单来说一下这道题我做的思路,首先我们要算出26个字母出现的次数,然后存入一个列表,仔细观察打印的格式,我们需要关注打印多少行是由什么决定的,最后我们发现,打印的行数与出现次数的最大值有关,于是我们通过找到出现次数的最大值来决定打印的行数。接着就是如何打印出格式出来,这个就比较简单就是次数问题,那需要注意的就是最后一个打印出来的没有空格。
chr函数:
返回值是当前整数对应的 ASCII 字符。
ls = ''
for i in range(4):
s = input()
ls += s.replace(' ','')
ls = ls.replace('.','')
ls = ls.replace('!','')
var = 'A'
l = []
for i in range(26):
temp = chr(ord(var) + i)
num = ls.count(temp)
l.append(num)
Max = max(l)
for i in range(Max):
for j in range(len(l)):
if l[j] >= (Max-i):
if j != len(l)-1:
print("*",end=' ')
else:
print("*")
else:
if j != len(l) - 1:
print(" ", end=' ')
else:
print(" ")
for i in range(26):
if i != 25:
print(f'{chr(ord(var)+i)}',end=' ')
else:
print(f'{chr(ord(var) + i)}')10.总结
继续加油!!!!!