【Kafka】 存储机制
目录
- 日志存储结构
-
- 总体结构
- LogSegment
- 文件具体结构
-
- 偏移量索引文件结构
- 时间戳索引文件结构
- 消息日志文件结构
- 查找 message过程
-
- 使用偏移量索引文件
- 使用时间戳索引文件
- 相关配置
- 日志清除及压缩
-
- 日志清理
-
- 基于时间
- 基于日志大小
- 基于偏移量
- 日志压缩
-
- 概述
- 日志压缩实现细节
- 磁盘数据存储
-
- 顺序写
- 零拷贝
- 页缓存
- 总结
日志存储结构
总体结构
Kafka 的消息数据存储结构如上图所示,基于「主题 + 分区 + 副本 + 分段 + 索引」的结构。
Kafka 消息是以主题为单位进行归类,各个主题之间是彼此独立的,互不影响。
每个主题又可以分为一个或多个分区。
每个分区各自存在一个记录消息数据的日志文件。
然后每个分区又被划分成了多个 LogSegment,相当于一个巨型文件被平均分割为一些相对较小的文件,这样也便于消息的查找、维护和清理。
加入我们有一个主题tp-demo-01,并且有6个分区,查看日志如下:

可以看到对应的每个Parition下存在一个[Topic-Parition] 命名的消息日志文件夹。
在理想情况下,数据流量分摊到各个 Parition 中,实现了负载均衡的效果。
同时在分区日志文件中,你会发现很多类型的文件,比如: .index、.timestamp、.log、.snapshot 等。如下:

LogSegment
一个LogSegment中有很多后缀文件,其中最重要的是.index、.timestamp、.log 三种类型文件。
| 文件后缀名 | 说明 |
|---|---|
| .index | 偏移量索引文件 |
| .timestamp | 时间戳索引文件 |
| .log | 日志文件 |
| .snapshot | 快照文件 |
| .deleted | 日志删除任务用来标记已删除的日志分段文件 |
| .cleaned | 日志清理时临时文件 |
| .swap | 日志压缩之后的临时文件 |
| leader-epoch-checkpoint | 存储leader epoch信息的文件。Leader epoch是一个单调递增的正整数,用于标识leader的版本。每当leader变更时,epoch版本都会加1。 |
每个LogSegment 的大小可以在server.properties 中log.segment.bytes=1073741824 (设置分段大小,默认是1G)选项进行设置。log文件默认写满1G后,会进行log rolling形成一个新的组合来记录消息。
文件命名规则:一组index+log+timeindex文件的名字是一样的,当前文件的名字第一条message的offset,比如00000000000000345678.log文件,他中的第一条消息的offset为345679, 最大为64位的long,不足位数补0。
文件具体结构
偏移量索引文件结构
偏移量索引文件 .index 用于记录消息偏移量与物理地址之间的映射关系。
Kafka 中的偏移量索引文件是以稀疏索引的方式构造消息的索引,并不保证每一个消息在索引文件中都有对应的索引项。
每个索引项共占用 8 个字节,索引文件的数据结构则是由相对offset和position组成:
- 相对偏移量:表示消息相对于基准偏移量的偏移量,占 4 个字节
- 物理地址:消息在日志分段文件 .log 中对应的物理位置,也占 4 个字节
由于保存的是相对第一个消息的相对offset,只需要4byte就可以了,可以节省空间,在实际查找后还需要计算回实际的offset,这对用户是透明的。
注意:offset 与 position 没有直接关系,因为会删除数据和清理日志。
稀疏索引,索引密度不高,但是offset有序,二分查找的时间复杂度为O(lgN),如果从头遍历时间复杂度是O(N)。
示意图如下:

偏移量索引由相对偏移量和物理地址组成:

可以通过如下命令解析 .index 文件:
kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.index --print-data-log | head

在偏移量索引文件中,索引数据都是顺序记录 offset。每当写入一定量的消息时,偏移量索引文件和时间戳索引文件分别增加一个偏移量索引项和时间戳索引项。通过修改 log.index.interval.bytes 的值,改变索引项的密度。
时间戳索引文件结构
时间戳索引文件则根据时间戳查找对应的偏移量。它的作用是可以让用户查询某个时间段内的消息,它一条数据的结构是时间戳(8byte)+相对offset(4byte),如果要使用这个索引文件,首先需要通过时间范围,找到对应的相对offset,然后再去对应的index文件找到position信息,然后才能遍历log文件,它也是需要使用上面说的index文件的。
也就是通过时间戳方式进行查找消息,需要通过查找时间戳索引和偏移量索引两个文件。
但是由于producer生产消息可以指定消息的时间戳,这可能将导致消息的时间戳不一定有先后顺序,因此尽量不要生产消息时指定时间戳。
时间戳索引文件中每个追加的索引时间戳必须大于之前追加的索引项,否则不予追加。在 Kafka 0.11.0.0 以后,消息信息中存在若干的时间戳信息。如果 broker 端参数 log.message.timestamp.type 设置为 LogAppendTIme ,那么时间戳必能保持单调增长。反之如果是 CreateTime 则无法保证顺序。
时间戳索引索引格式:前八个字节表示时间戳,后四个字节表示偏移量:

消息日志文件结构
消息封装为Record,追加到log日志文件末尾,采用的是顺序写模式。

对于一个成熟的消息中间件来说,日志格式不仅影响功能的扩展,还关乎性能维度的优化。所以随着 Kafka 的迅猛发展,其日志格式也在不断升级改进中,Kafka 的日志格式总共经历了3个大版本:V0,V1和V2版本。
1)V0 版本
在 Kafka 0.10.0 之前的版本都是采用这个版本的日志格式的。
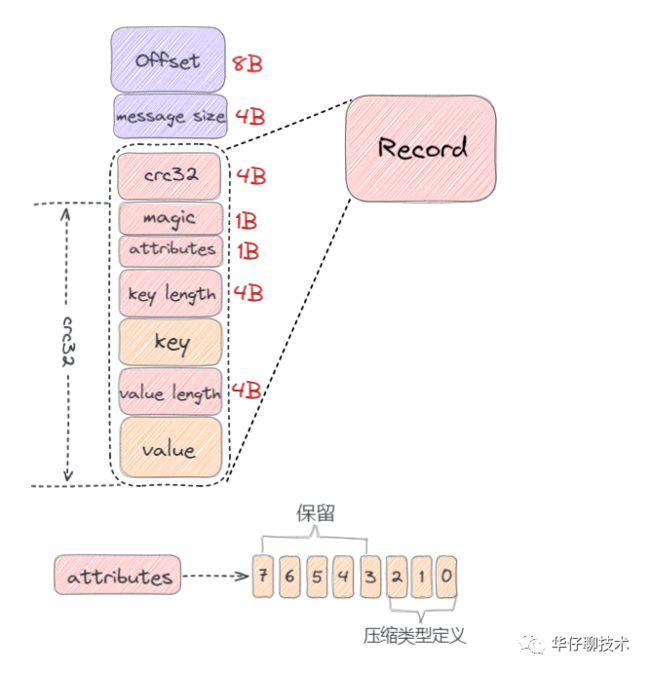
有如下几部分组成:
- crc32(4B):crc32校验值。校验范围为magic至value之间。
- magic(1B):日志格式版本号,此版本的magic值为0。
- attributes(1B):消息的属性。总共占1个字节,低3位表示压缩类型:0 表示NONE、1表示GZIP、2表示SNAPPY、3表示LZ4(LZ4自Kafka 0.9.x 版本引入),其余位保留。
- key length(4B):表示消息的key的长度。如果为-1,则没有设置key。
- key:可选,如果没有key则无此字段。
- value length(4B):实际消息体的长度。如果为-1,则消息为空。
- value:消息体。
V0 版本的消息最小为 14 字节,小于 14 字节的消息会被 Kafka 认为是非法消息。
2)V1 版本
随着 Kafka 版本的不断迭代发展, 用户发现 V0 版本的日志格式由于没有保存时间信息导致 Kafka 无法根据消息的具体时间进行判断,在进行清理日志的时候只能使用日志文件的修改时间导致可能会被误删。
从 V0.10.0 开始到 V0.11.0 版本之间所使用的日志格式版本为 V1,比 V0 版本多了一个 timestamp 字段,表示消息的时间戳。如下图所示:

timestamp 字段作用:
- 对内:会影响日志保存、切分策略;
- 对外:影响消息审计、端到端延迟等功能扩展
V1 版本的消息最小为 22 字节,小于 22 字节的消息会被 Kafka 认为是非法消息。
3)V0、V1 版本的设计缺陷
通过上面我们分析画出的 V0、V1 版本日志格式,我们会发现它们在设计上的一定的缺陷,比如:
- 空间使用率低:无论 key 或 value 是否存在,都需要一个固定大小 4 字节去保存它们的长度信息,当消息足够多时,会浪费非常多的存储空间。
- 消息长度没有保存:需要实时计算得出每条消息的总大小,效率低下。
- 只保存最新消息位移。
- 冗余的 CRC 校验:即使是批次发送消息,每条消息也需要单独保存 CRC。
4)V2 版本
针对 上面我们分析的 关于 V0、V1 版本日志格式的缺陷,Kafka 在 0.11.0.0 版本对日志格式进行了大幅度重构,使用可变长度类型解决了空间使用率低的问题,增加了消息总长度字段,使用增量的形式保存时间戳和位移,并且把一些字段统一抽取到 RecordBatch 中。

从以上图可以看出,V2 版本的消息批次(RecordBatch),相比 V0、V1 版本主要有以下变动:
- 将 CRC 值从消息中移除,被抽取到消息批次中。
- 增加了 procuder id、producer epoch、序列号等信息主要是为了支持幂等性以及事务消息的。
- 使用增量形式来保存时间戳和位移。
- 消息批次最小为 61 字节,比 V0、V1 版本要大很多,但是在批量消息发送场景下,会提供发送效率,降低使用空间。
综上可以看出 V2 版本日志格式主要是通过可变长度提高了消息格式的空间使用率,并将某些字段抽取到消息批次(RecordBatch)中,同时消息批次可以存放多条消息,从而在批量发送消息时,可以大幅度地节省了磁盘空间。
查找 message过程
使用偏移量索引文件
- 根据 offset 的值,查找 segment 段中的 index 索引文件。由于索引文件命名是以上一个文件的最后一个offset 进行命名的,所以,使用二分查找算法能够根据offset 快速定位到指定的索引文件
- 找到索引文件后,根据 offset 进行定位,找到索引文件中的匹配范围的偏移量position。(kafka 采用稀疏索引的方式来提高查找性能)
- 得到 position 以后,再到对应的 log 文件中,从 position处开始查找 offset 对应的消息,将每条消息的 offset 与目标 offset 进行比较,直到找到消息
示例:假如有00000000000000000000.index和00000000000001000000.index两个索引文件,查找找 offset 值为 1002490的消息。
- 首先遍历所有Segment文件,得到文件名,根据二分查找算法,得到数据在
00000000000001000000.index文件中 - 先访问该文件,根据offset值,即1002490,使用二分查找,查询到索引文件的数据为[2487,49111],其中2487是索引的相对位置,其绝对索引位置要加上文件名的后缀,结果就是1002487, 49111是物理位置。拿到物理存放位置49111。
- 根据 49111 这个 position 开始查找,比较每条消息的 offset 是否大于等于 1002490。最后查找到对应的消息以后返回。
**注意:**可以利用offset在partition中查找,不能在整个topic中查找的,因为offset只保证在partition中唯一、有序。
使用时间戳索引文件
- 查找该时间戳应该在哪个日志分段中
- 查找该日志分段的偏移量索引文件,接着就和上面使用索引文件查找过程一样了
注意:timestamp文件中的 offset 与 index 文件中的 relativeOffset 不是一一对应的,因为数据的写入是各自追加。
示例:查找时间戳为1557554753430开始的消息。
-
查找该时间戳应该在哪个日志分段中。将1557554753430和每个日志分段中最大时间戳largestTimeStamp逐一对比,直到找到不小于1557554753430所对应的日志分段。
日志分段中的largestTimeStamp的计算是:先查询该日志分段所对应时间戳索引文件,找到最后一条
索引项,若最后一条索引项的时间戳字段值大于0,则取该值,否则取该日志分段的最近修改时间。
-
查找该日志分段的偏移量索引文件,查找该偏移量对应的物理地址。
-
后面过程与偏移量索引文件查找相同了。
相关配置
| 配置 | 默认值 | 说明 |
|---|---|---|
| log.index.interval.bytes | 4096(4K) | 增加索引项字节间隔密度,会影响索引文件中的区间密度和查询效率 |
| log.segment.bytes | 1073741824(1G) | 日志文件最大值 |
| log.roll.ms | 当前日志分段中消息的最大时间戳与当前系统的时间戳的差值允许的最大范围,单位毫秒 | |
| log.roll.hours | 168(7天) | 当前日志分段中消息的最大时间戳与当前系统的时间戳的差值允许的最大范围,单位小时 |
| log.index.size.max.bytes | 10485760(10MB) | 触发偏移量索引文件或时间戳索引文件分段字节限额 |
上面的配置项如何影响文件切分?
当满足如下几个条件中的其中之一,就会触发文件的切分:
- 当前日志分段文件的大小超过了 broker 端参数 log.segment.bytes 配置的值。的默认值为 1073741824,即 1GB。
- 当前日志分段中消息的最大时间戳与当前系统的时间戳的差值大于 log.roll.ms 或 log.roll.hours 参数配置的值。如果同时配置了 log.roll.ms 和 log.roll.hours 参数,那么 log.roll.ms 的优先级高。默认情况下,只配置了 log.roll.hours 参数,其值为168,即 7 天。也就是即使文件大小没有达到log.segment.bytes,到了时间也会保存到下一个文件。
- 偏移量索引文件或时间戳索引文件的大小达到 broker 端参数 log.index.size.max.bytes配置的值。log.index.size.max.bytes 的默认值为 10485760,即 10MB。索引文件达到大小了也要切分。
- 追加的消息的偏移量与当前日志分段的偏移量之间的差值大于 Integer.MAX_VALUE ,即要追加的消息的偏移量不能转变为相对偏移量。
第4种情况为什么是Integer.MAX_VALUE?
4 个字节刚好对应 Integer.MAX_VALUE ,如果大于 Integer.MAX_VALUE,那么索引的相对位置就不能用4个字节表示了。
索引文件切分过程:
索引文件会根据 log.index.size.max.bytes 值进行预先分配空间,即文件创建的时候就是最大值。当真正的进行索引文件切分的时候,才会将其裁剪到实际数据大小的文件。这一点是跟日志文件有所区别的地方。其意义降低了代码逻辑的复杂性。
日志清除及压缩
Kafka 将消息存储到磁盘中,随着写入数据不断增加,磁盘占用空间越来越大,为了控制占用空间就需要对消息做一定的清理操作。从上面 Kafka 存储日志结构分析中每一个分区副本(Replica)都对应一个 Log,而 Log 又可以分为多个日志分段(LogSegment),这样就便于 Kafka 对日志的清理操作。
Kafka 提供两种日志清理策略:
- 日志删除:按照一定的删除策略,将不满足条件的数据进行数据删除
- 日志压缩:针对每个消息的 Key 进行整合,对于有相同 Key 的不同 Value 值,只保留最后一个版本。
Kafka 提供 log.cleanup.policy 参数进行相应配置,默认值: delete ,还可以选择compact 。如果想要同时支持两种清理策略, 可以直接将 log.cleanup.policy 参数设置为delete,compact。
主题级别的配置项是 cleanup.policy 。
日志清理
基于时间
Kafka 的日志管理器(LogManager)中有一个专门的日志清理任务通过周期性检测和删除不符合条件的日志分段文件(LogSegment),这里我们可以通过 Kafka Broker 端的参数 log.retention.check.interval.ms 来配置,用于设置Kafka检查数据是否过期的间隔,默认值为300000,即5分钟。
另外,参数 log.retention.hours、log.retention.minutes、log.retention.ms 用于设置Kafka中数据保存的时间。如果超过该设定值,就需要进行删除。
按照log.retention.ms > log.retention.minutes > log.retention.hours优先级来设置,默认情况只会配置 log.retention.hours 参数,值为168,即为7天。
Kafka 依据日志分段中最大的时间戳进行定位。首先要查询该日志分段所对应的时间戳索引文件,查找时间戳索引文件中最后一条索引项,若最后一条索引项的时间戳字段值大于 0,则取该值,否则取最近修改时间。
为什么不直接选最近修改时间呢?
因为日志文件可以有意无意的被修改,并不能真实的反应日志分段的最大时间信息。
删除过程
- 首先从 Log 对象所维护的日志段的跳跃表中移除要删除的日志段,用来确保已经没有线程来读取这些日志段。
- 将日志段所对应的所有文件,包括索引文件都添加上“.deleted”的后缀。
- 最后交给一个以“delete-file”命名的延迟任务来删除这些以“ .deleted ”为后缀的文件。默认1分钟执行一次, 可以通过 file.delete.delay.ms 来配置。
如果活跃的日志分段中也存在需要删除的数据时?
Kafka 会先切分出一个新的日志分段作为活跃日志分段,该日志分段不删除,删除原来的日志分段。先腾出地方,再删除。
基于日志大小
日志删除任务会周期检查当前日志大小是否超过设定的阈值(retentionSize) 来寻找可删除的日志段文件集合(deletableSegments)。
其中 retentionSize 这里我们可以通过 Kafka Broker 端的参数log.retention.bytes来设置, 默认值为-1,即无穷大。
这里需要注意的是 log.retention.bytes 设置的是Log中所有日志文件的大小,而不是单个日志段的大小。单个日志段可以通过参数 log.segment.bytes 来设置,默认大小为1G。
删除过程
- 先计算日志文件的总大小Size和retentionSize的差值,即需要删除的日志总大小
- 然后从日志文件中的第一个日志段开始进行查找可删除的日志段的文件集合(deletableSegments)
- 找到后就可以进行删除操作了
基于偏移量
根据日志分段的下一个日志分段的起始偏移量是否大于等于日志文件的起始偏移量,若是,则可以删除此日志分段。
注意:日志文件的起始偏移量并不一定等于第一个日志分段的基准偏移量,存在数据删除,可能与之相等的那条数据已经被删除了。

删除过程
- 从头开始遍历每个日志分段,日志分段1的下一个日志分段的起始偏移量为21,小于logStartOffset,将日志分段1加入到删除队列中
- 日志分段 2 的下一个日志分段的起始偏移量为35,小于 logStartOffset,将 日志分段 2 加入到删除队列中
- 日志分段 3 的下一个日志分段的起始偏移量为57,小于logStartOffset,将日志分段3加入删除集合中
- 日志分段4的下一个日志分段的其实偏移量为71,大于logStartOffset,则不进行删除。
日志压缩
概述
日志压缩是Kafka的一种机制,可以提供较为细粒度的记录保留,而不是基于粗粒度的基于时间的保留。对于具有相同的Key,而数据不同,只保留最后一条数据,前面的数据在合适的情况下删除。
日志压缩特性,就实时计算来说,可以在异常容灾方面有很好的应用途径。比如,我们在Spark、Flink中做实时计算时,需要长期在内存里面维护一些数据,这些数据可能是通过聚合了一天或者一周的日志得到的,这些数据一旦由于异常因素(内存、网络、磁盘等)崩溃了,从头开始计算需要很长的时间。一个比较有效可行的方式就是定时将内存里的数据备份到外部存储介质中,当崩溃出现时,再从外部存储介质中恢复并继续计算。
使用日志压缩来替代这些外部存储有哪些优势及好处呢?这里为大家列举并总结了几点:
- Kafka即是数据源又是存储工具,可以简化技术栈,降低维护成本
- 使用外部存储介质的话,需要将存储的Key记录下来,恢复的时候再使用这些Key将数据取回,实现起来有一定的工程难度和复杂度。使用Kafka的日志压缩特性,只需要把数据写进Kafka,等异常出现恢复任务时再读回到内存就可以了
- Kafka对于磁盘的读写做了大量的优化工作,比如磁盘顺序读写。相对于外部存储介质没有索引查询等工作量的负担,可以实现高性能。同时,Kafka的日志压缩机制可以充分利用廉价的磁盘,不用依赖昂贵的内存来处理,在性能相似的情况下,实现非常高的性价比(这个观点仅仅针对于异常处理和容灾的场景来说)
日志压缩实现细节
想要使用日志压缩,设置参数主题的 cleanup.policy 需要设置为compact。
Kafka的后台线程会定时将Topic遍历两次:
- 记录每个key的hash值最后一次出现的偏移量
- 第二次检查每个offset对应的Key是否在后面的日志中出现过,如果出现了就删除对应的日志。
日志压缩允许删除,除最后一个key之外,删除先前出现的所有该key对应的记录。在一段时间后从日志中清理,以释放空间。
注意:日志压缩与key有关,确保每个消息的key不为null。
压缩是在Kafka后台通过定时重新打开Segment来完成的,Segment的压缩细节如下图所示:

日志压缩可以确保:
- 任何保持在日志头部以内的使用者都将看到所写的每条消息,这些消息将具有顺序偏移量。可以使用Topic的
min.compaction.lag.ms属性来保证消息在被压缩之前必须经过的最短时间。也就是说,它为每个消息在(未压缩)头部停留的时间提供了一个下限。可以使用Topic的max.compaction.lag.ms属性来保证从收到消息到消息符合压缩条件之间的最大延时 - 消息始终保持顺序,压缩永远不会重新排序消息,只是删除一些而已
- 消息的偏移量永远不会改变,它是日志中位置的永久标识符从日志开始的任何使用者将至少看到所有记录的最终状态,按记录的顺序写入。
- 另外,如果使用者在比Topic的
log.cleaner.delete.retention.ms短的时间内到达日志的头部,则会看到已删除记录的所有delete标记。保留时间默认是24小时。
默认情况下,启动日志清理器,若需要启动特定Topic的日志清理,请添加特定的属性。配置日志清
理器,这里为大家总结了以下几点:
log.cleanup.policy设置为 compact ,Broker的配置,影响集群中所有的Topic。log.cleaner.min.compaction.lag.ms,用于防止对更新超过最小消息进行压缩,如果没有设置,除最后一个Segment之外,所有Segment都有资格进行压缩log.cleaner.max.compaction.lag.ms,用于防止低生产速率的日志在无限制的时间内不压缩。
Kafka的日志压缩原理并不复杂,就是定时把所有的日志读取两遍,写一遍,而CPU的速度超过磁盘完全不是问题,只要日志的量对应的读取两遍和写入一遍的时间在可接受的范围内,那么它的性能就是可以接受的。
磁盘数据存储
顺序写
Kafka利用分段、追加日志的方式,在很大程度上将读写限制为顺序I/O(sequential I/O),这在大多数的存储介质上都很快。
人们普遍错误地认为硬盘很慢。然而,存储介质的性能,很大程度上依赖于数据被访问的模式。同样在一块普通的7200 RPM SATA硬盘上,随机I/O(random I/O)与顺序I/O相比,随机I/O的性能要比顺序I/O慢3到4个数量级。
此外,现代的操作系统提供了预先读和延迟写的技术,这些技术可以以块为单位,预先读取大量数据,并将较小的逻辑写操作合并成较大的物理写操作。
零拷贝
kafka高性能,是多方面协同的结果,包括宏观架构、分布式partition存储、ISR数据同步、以及“无所不用其极”的高效利用磁盘/操作系统特性。
零拷贝并不是不需要拷贝,而是减少不必要的拷贝次数。通常是说在IO读写过程中。
nginx的高性能也有零拷贝的身影。
传统IO
比如:读取文件,socket发送
传统方式实现:先读取、再发送,实际经过1~4四次copy。
- 第一次:将磁盘文件,读取到操作系统内核缓冲区;
- 第二次:将内核缓冲区的数据,copy到application应用程序的buffer;
- 第三步:将application应用程序buffer中的数据,copy到socket网络发送缓冲区(属于操作系统内核的缓冲区);
- 第四次:将socket buffer的数据,copy到网络协议栈,由网卡进行网络传输。

实际IO读写,需要进行IO中断,需要CPU响应中断(内核态到用户态转换),尽管引入DMA(Direct Memory Access,直接存储器访问)来接管CPU的中断请求,但四次copy是存在“不必要的拷贝”的。
Kafka IO
Kafka IO 实际上并不需要第二个和第三个数据副本。数据可以直接从读缓冲区传输到套接字缓冲区。
kafka的两个过程:
- 网络数据持久化到磁盘 (Producer 到 Broker)
- 磁盘文件通过网络发送(Broker 到 Consumer)
数据落盘通常都是非实时的,Kafka的数据并不是实时的写入硬盘,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。
kafka零拷贝原理
磁盘数据通过DMA(Direct Memory Access,直接存储器访问)拷贝到内核态 Buffer直接通过 DMA 拷贝到 NIC Buffer(socket buffer),无需 CPU 拷贝。
除了减少数据拷贝外,整个读文件到网络发送由一个 sendfile 调用完成,整个过程只有两次上下文切换,因此大大提高了性能。
Java NIO对sendfile的支持就是FileChannel.transferTo()/transferFrom()和fileChannel.transferTo( position, count, socketChannel);
把磁盘文件读取OS内核缓冲区后的fileChannel,直接转给socketChannel发送;底层就是sendfile。消费者从broker读取数据,就是由此实现。
具体来看,Kafka 的数据传输通过 TransportLayer 来完成,其子类 PlaintextTransportLayer通过Java NIO 的 FileChannel 的 transferTo 和 transferFrom 方法实现零拷贝。

kafka IO过程如下:

图片来源:https://mp.weixin.qq.com/s/CCAP8n0mTCrUT-NzOAacCg
页缓存
页缓存是操作系统实现的一种主要的磁盘缓存,以此用来减少对磁盘 I/O 的操作。具体来说,就是把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问。
Kafka接收来自socket buffer的网络数据,应用进程不需要中间处理、直接进行持久化时。可以使用mmap内存文件映射。
什么是mmap?
Memory Mapped Files
简称mmap,简单描述其作用就是:将磁盘文件映射到内存, 用户通过修改内存就能修改磁盘文件。
它的工作原理是直接利用操作系统的Page来实现磁盘文件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上(操作系统在适当的时候)。

通过mmap,进程像读写硬盘一样读写内存(当然是虚拟机内存)。使用这种方式可以获取很大的I/O提升,省去了用户空间到内核空间复制的开销。
mmap也有一个很明显的缺陷:不可靠,写到mmap中的数据并没有被真正的写到硬盘,操作系统会在程序主动调用flush的时候才把数据真正的写到硬盘。
Kafka提供了一个参数 producer.type 来控制是不是主动flush;如果Kafka写入到mmap之后就立即flush然后再返回Producer叫同步(sync);写入mmap之后立即返回Producer不调用flush叫异步(async)。
Java NIO对文件映射的支持
Java NIO,提供了一个MappedByteBuffer 类可以用来实现内存映射。
MappedByteBuffer只能通过调用FileChannel的map()取得,再没有其他方式。
FileChannel.map()是抽象方法,具体实现是在 FileChannelImpl.map()可自行查看JDK源码,其map0()方法就是调用了Linux内核的mmap的API。
使用 MappedByteBuffer类要注意的是:mmap的文件映射,在full gc时才会进行释放。当close时,需要手动清除内存映射文件,可以反射调用sun.misc.Cleaner方法。
kafka使用页缓存读取过程
当一个进程准备读取磁盘上的文件内容时:
- 操作系统会先查看待读取的数据所在的页 (page)是否在页缓存(pagecache)中,如果存在(命中)则直接返回数据,从而避免了对物理磁盘的 I/O 操作;
- 如果没有命中,则操作系统会向磁盘发起读取请求并将读取的数据页存入页缓存,之后再将数据返回给进程。
如果一个进程需要将数据写入磁盘:
- 操作系统也会检测数据对应的页是否在页缓存中,如果不存在,则会先在页缓存中添加相应的页,最后将数据写入对应的页。
- 被修改过后的页也就变成了脏页,操作系统会在合适的时间把脏页中的数据写入磁盘,以保持数据的一致性
总结
对一个进程而言,它会在进程内部缓存处理所需的数据,然而这些数据有可能还缓存在操作系统的页缓存中,因此同一份数据有可能被缓存了两次。并且,除非使用Direct I/O的方式, 否则页缓存很难被禁止。
当使用页缓存的时候,即使Kafka服务重启, 页缓存还是会保持有效,然而进程内的缓存却需要重建。这样也极大地简化了代码逻辑,因为维护页缓存和文件之间的一致性交由操作系统来负责,这样会比进程内维护更加安全有效。
Kafka中大量使用了页缓存,这是 Kafka 实现高吞吐的重要因素之一。
消息先被写入页缓存,由操作系统负责刷盘任务。
总结
Kafka速度快是因为:
- partition顺序读写,充分利用磁盘特性,这是基础;
- Consumer 读取数据采用稀疏索引,可以快速定位消费数据
- Producer生产的数据持久化到broker,采用mmap文件映射,实现顺序的快速写入;
- Customer从broker读取数据,采用sendfile,将磁盘文件读到OS内核缓冲区后,直接转到socket buffer进行网络发送。
参考:https://mp.weixin.qq.com/s/kbUZf1ys3JZXyr_2zVeFcA
https://mp.weixin.qq.com/s/kbUZf1ys3JZXyr_2zVeFcA
https://mp.weixin.qq.com/s/aVqtYkjRj-wzak1emY3Yng