DARPA可解释AI研究(XAI计划)的4年回顾与经验总结

导语:DARPA(美国防部高级研究计划局)于 2015 年制定了可解释人工智能 (XAI) 计划,目标是使最终用户能够更好地理解、信任和有效管理人工智能系统。2017年,为期4年的XAI研究计划启动。现在,随着 XAI 在 2021 年结束,本文总结和反思了 XAI 项目的目标、组织和研究进展。
作者:David Gunning, Eric Vorm, Jennifer Yunyan Wang, Matt Turek
编译:牛梦琳
摘要:
从项目管理人员和评估人员的角度,对国防高级研究计划局(DARPA)的可解释人工智能(XAI)项目进行总结。
以帮助终端用户更好地理解、信任并有效管理人工智能系统为目标,美国国防部高级研究计划局(DARPA)于2015年制定了可解释人工智能(XAI)计划。2017年,这一为期4年的研究开始落实。现在,随着2021年XAI的结束,是时候稍作暂停,反思一下,对这个计划中的成功,失败,以及给我们的启发做出总结。本文介绍了XAI项目的目标、组织和研究进展。
01
XAI的创建
机器学习的巨大成功创造了人工智能能力方面的新的爆发,但由于机器无法向人类用户解释其决定和行动,其有效性将受到限制。
这个问题对美国国防部(DoD)尤为重要,国防部面临的挑战通常意味着需要开发出更多智能、自主、可靠的系统。而XAI在用户理解、适当信任和有效管理这一代新兴的人工智能伙伴方面将至关重要。
在某种意义上,可解释性问题是人工智能成功的结果。在人工智能的早期,主要的推理方法是逻辑和符号的。这些早期系统通过对(一定程度上)人类可读的符号进行某种形式的逻辑推理,生成其推理步骤的痕迹,这个痕迹就成为解释的基础。因此,这些系统在可解释性方面做了大量的工作。
然而,这样的早期系统是无效的:事实证明,它们的构造成本过高,且对现实世界的复杂性来说太脆弱了。人工智能的成功是随着研究人员开发出新的机器学习技术而产生的,这些技术支持使用它们自己的内部表征(例如支持向量、随机森林、概率模型和神经网络等)构建世界模型。这些新的模型更加有效,同时却也必然更加不透明,难以解释。
2015年是对XAI需求的一个转折点。数据分析和机器学习刚刚经历了十年的快速发展。继2012年ImageNet的突破性成果之后,深度学习革命方兴未艾,大众媒体对超级智能(Superintelligence)和即将到来的AI启示录(AI Apocalypse)进行了各种各样的猜测。
2015年也提出了可解释性的初步想法。一些研究人员选择探索深度学习技术,例如利用去卷积网络来可视化卷积网络的层次。还有一些则追求学习更多可解释性模型技术,如贝叶斯规则列表。
DARPA花了一年时间调查研究人员,分析可能的研究策略,并制定了该计划的目标和结构。2016年8月,DARPA发布了DARPA-BAA-16-53来征集提案。
1.1 XAI 的目标program goals
可解释人工智能(XAI)的既定目标是创建一套新的或修正过的机器学习技术,产生可解释的模型,当与有效的解释技术相结合时,终端用户能够理解、适当地信任并有效地管理新一代的人工智能系统。
XAI的目标是依赖AI系统给出决定或建议,或由AI 系统采取行动的终端用户,因此用户需要理解系统做出决定的理由。例如,一个情报分析员需要了解他的大数据分析系统为什么建议对某些活动进行进一步调查。同样,一个给自主系统布置任务的操作员需要了解系统的决策模型,以便在未来的任务中恰当地使用它。XAI的概念是为用户提供解释,使他们能够理解系统的整体优势和劣势;传达对系统在未来/不同情况下的行为的理解,并许允许用户纠正系统的错误。
XAI项目假定在机器学习性能(如预测准确性)和可解释性之间存在一种固有的紧张关系,这种担忧与当时的研究成果是一致的。通常情况下,性能最高的方法(如深度学习)是最不容易解释的,而最容易解释的方法(如决策树)是最不准确的。该计划希望创建一个新的机器学习和解释技术组合,为未来的从业者提供涵盖性能-解释能力均衡空间的更广泛的设计选择。如果一个应用需要更高的性能,XAI的组合将包括更多可解释的、高性能的深度学习技术。如果一个应用需要更多的可解释性,那么XAI将包括性能更高的、可解释的模型。
1.2 XAI的结构
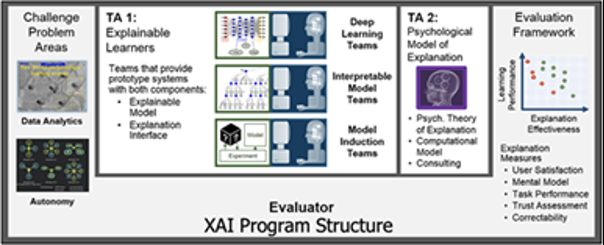
该计划被组织成三个主要的技术领域(TA),如图1所示:(a)开发新的XAI机器学习和解释技术,以生成有效的解释;(b)通过总结、扩展和应用解释的心理学理论来理解解释的原理;以及(c)在数据分析和自主性这两个具有挑战性的领域评估新的XAI技术。
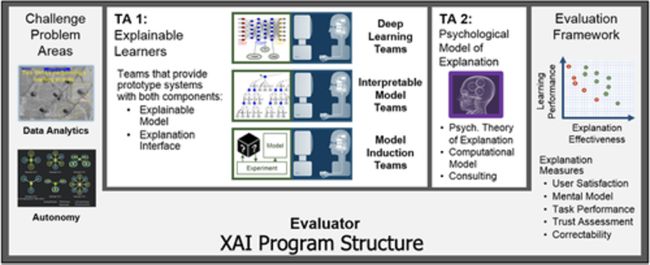
图1 美国国防部高级研究计划局(DARPA)可解释人工智能(XAI)计划结构,包括技术领域(TAs)和评估框架
最初的计划时间表包括两个阶段:第一阶段,技术演示(18个月);第二阶段,比较评估(30个月)。第一阶段,要求开发者针对各自的测试问题进行技术展示。第二阶段,原本计划让开发者针对政府评估员定义的两个共同问题之一(图2)进行技术测试。在第二阶段结束时,开发人员将为一个开源的XAI工具包提供原型软件。
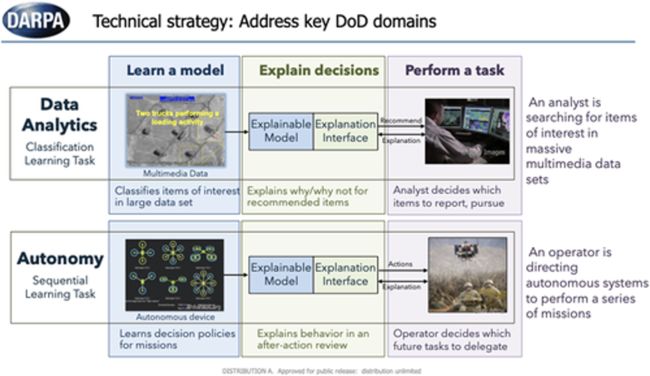
图2 挑战领域
02
XAI 的开发
2017年5月,XAI计划正式开始。有11个研究小组被选中,开发可解释学习(TA1),另一个小组则被选中开发解释的心理学模型。评估是由海军研究实验室提供。下面总结了这些开发以及该计划结束时这项工作的最终状况。Gunning和Aha.给出了2018年底的XAI发展临时总结。
2.1 XAI 可解释学习方法
该计划预计,研究人员将检测训练过程、模型表现以及解释界面。对于模型的表述,设想了三种一般的方法。可解释的模型方法将寻求开发ML模型,这些模型对于机器学习专家来说本质上更容易解释,也更容易自省。深度解释方法将利用或混合深度学习方法,在预测的基础上产生解释。最后,模型归纳技术将从更不透明的黑盒子模型中创建近似的可解释模型。解释界面有望成为XAI的一个关键要素,它将用户与模型连接起来,使用户能够理解决策过程并与之互动。
随着研究的进展,11个XAI团队逐渐探索了一些机器学习方法,如可操作的概率模型和因果模型以及解释技术,如强化学习算法产生的状态机、贝叶斯教学、视觉显著性地图以及网络和GAN剖析。也许最具挑战性,也是最独特的贡献来自于将机器学习和解释技术结合起来,并通过精心设计的心理学实验来评估解释的有效性。
同时,我们也对用户的范围和开发时间表有了更精细的了解(图3)
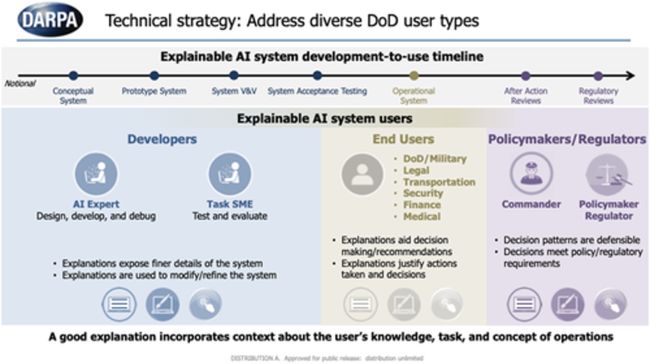
图 3 可解释的人工智能(XAI)用户和开发时间表
2.2 “解释”的心理学模型
该计划预计需要对解释进行有理论支持的心理学理解。我们选择了一个团队来总结当前解释的心理学理论,以协助XAI开发者和评估团队。这项工作始于对解释心理学的广泛文献调查和以前关于人工智能可解释性的工作。
起先,这个团队被要求(a)对当前的解释理论进行总结,(b)从这些理论中开发一个解释的计算模型,以及(c)根据XAI开发者的评估结果验证该计算模型。最终发现开发计算模型工作过于复杂,但该团队确实对该领域产生另深刻的理解,并成功地给出了描述性模型。这些描述性模型对于支持有效的评估方法至关重要,这涉及到根据国防部人类主体研究指南进行的精心设计的用户研究。图4展示了XAI解释过程的顶层描述性模型。
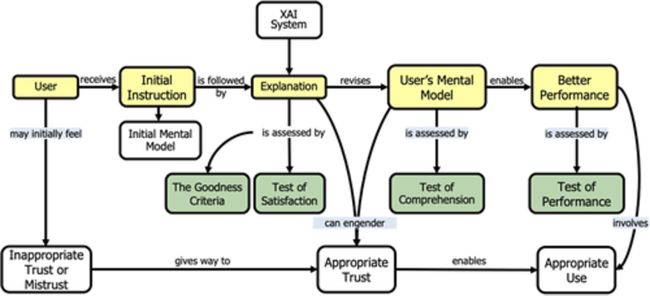
图4 解释的心理学模型——黄色方框说明了基本过程,绿色方框说明了测量机会,白框说明了潜在的结果
2.3 评估
最初设想是基于一组共同的问题,在数据分析和自主性领域进行评估。然而很快就发现,在广泛的问题领域探索各种方法更有价值。为了评估项目最后一年的表现,由美国海军研究实验室(NRL)的Eric Vorm博士领导的评估小组开发了一个解释评分系统(ESS)。
这个评分系统提供了一个量化机制,用于评估XAI用户研究在技术和方法上的适当性和稳健性。ESS能够对每个用户研究的要素进行评估,包括任务、领域、解释、解释界面、用户、假设、数据收集和分析,以确保每个研究符合人类研究的高标准。XAI评价措施如图5所示,包括功能措施、学习性能措施和解释有效性措施。
DARPA的XAI项目明确表明了精心设计用户研究的重要性,以便准确评估解释的有效性,从而直接增强人类用户的适当使用和信任,并适当支持人机协作。很多时候,多种类型(即性能、功能和解释的有效性)的测量对于评估XAI算法的性能是必要的。XAI用户研究的设有时很棘手,但是DARPA XAI项目发现,最那些具有跨学科专长(即计算机科学与人机交互和/或实验心理学相结合等)的多样化团队的研究最有效。
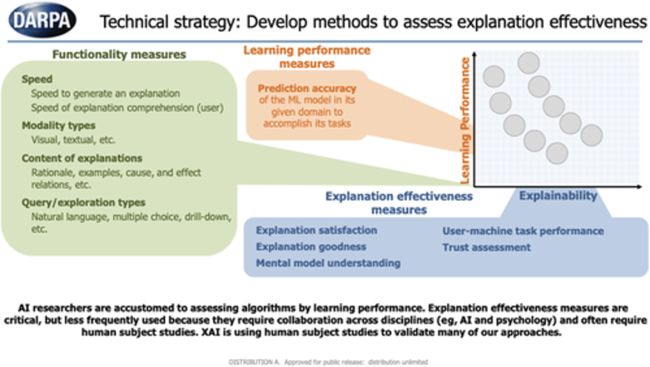
图5 可解释人工智能(XAI)算法的评估措施
2.4 XAI 的开发方法
XAI项目探索了许多方法,如表1所示。
表1. 国防高级研究计划局(DARPA)可解释人工智能(XAI)项目上的技术方法
Team |
Approach |
Application |
UC Berkeley |
Salience-map attention mechanisms implemented in DNNs19 |
Saliency maps for object detectors allow users to identify the detector which will be more accurate by reviewing sample detections and maps |
Transduction of DNN states into natural language explanations31 |
Explainable and advisable autonomous driving systems to fill in knowledge gaps. Humans can evaluate AI-generated explanations for navigation decisions21, 30 |
|
Charles River Analytics |
Causal models of deep reinforcement learning policies to enable explanation-enhanced training by answering counterfactual queries17 |
Human-machine teaming gameplay in StarCraft2 |
Developed a distilled version of a pedestrian detection model, which used convolutional auto encoders to condense the activations into user understandable “chunks” |
||
Carnegie Mellon University |
Robustified classifiers with salient gradients |
Interactive debugger interface for visualizing poisoned training datasets. Work is applied on the IARPA TrojAI dataset.33 Establishing objective/quantitative criteria to assess value of explanations for ML models34 |
Oregon State University |
iGOS++ visual saliency algorithm24 |
Debugging of COVID-19 diagnosis chest x-ray classifier |
Quantized bottleneck networks for deep RL algorithms |
Understanding recurrent policy networks through extracted state machines and key decision points in video games and control35 |
|
Explanation analysis process for reinforcement learning systems36 |
After-action review of AI decisions mirror the army's after action review system to understand why AI made its decisions to improve explainability and AI trust36, 37 |
|
Reinforcement learning model via embedded self-predictions |
Contrastive explanations of action choices in terms of human understandable properties of future outcomes38 |
|
Rutgers University |
Bayesian teaching to select examples and features from the training data to explain model inferences to a domain expert18 |
Interactive tool for analyzing a pneumothorax detector for chest X-rays. Targeted user study engaging ~10 radiologists demonstrated the effectiveness of the explanations39 |
UT Dallas |
Tractable probabilistic logic models where local explanations are queries over probabilistic models and global explanations are generated using logic, probability, and directed trees and graphs |
Activity recognition in videos using TACoS cooking tasks and WetLab scientific lab procedure datasets. Generates explanations about whether activities are present in the video data16 |
PARC |
Reinforcement learning implementing a hierarchical multifactor framework for decision problems |
Simulated drone flight mission planning task where users learned to predict each agent's behavior to choose the best flight plan. User study tested the usefulness of AI-generated local and global explanations in helping users predict AI behavior40 |
SRI |
Spatial attention VQA (SVQA) and spatial-object attention BERT VQA (SOBERT)20, 23 |
Attention-based (gradCAM) explanations for MRI brain-tumor segmentation. Visual salience models for video Q&A |
Raytheon BBN |
CNN-based one-shot detector, using network dissection to identify the most salient features41 Explanations produced by heat maps and text explanations42 Human-machine common ground modeling |
Indoor navigation with a robot (in collaboration with GA Tech) Video Q&A Human-assisted one-shot classification system by identifying the most salient features |
Texas A&M |
Mimic learning methodology to detect falsified text29 |
News claim truth classification |
UCLA |
CX-ToM framework: A new XAI framework using theory-of-mind where we pose explanation as an iterative communication process, that is, dialog, between the machine and human user. In addition, we replace the standard attention-based explanations with novel counterfactual explanations called fault-lines43, 44 |
Image classification, human body pose estimation |
A learning framework to acquire interpretable knowledge representation and an augmented reality system for explanation interface45, 46 |
Robot learning to open medicine bottles with locks and allows user interventions to correct wrong behaviors |
|
Theory of mind explanation network with multilevel belief updates from learning |
Minesweeper-like game to find optimal path for an agent |
|
IHMC |
Explanation scorecard |
Evaluate the utility of an explanation. Defines seven levels of capability, from the null case of no explanation, to surface features (eg, heat maps), to AI introspections such as choice logic, to diagnoses of the reasons for failures |
Cognitive tutorial |
A straightforward way to help users understand complex systems is to provide a tutorial up front but the tutorial should not be restricted to how the system works27 |
|
Stakeholder playbook |
Survey of stakeholder needs, including development team leaders, trainers, system developers, and user team leaders in industry and government |
|
AI evaluation guidebook |
Identifies methodological shortcomings for evaluating XAI techniques, spanning experimental design, control conditions, experimental tasks and procedures, and statistical methodologies |
03
XAI 的结果,启发和教训
该项目进行了三次主要的评估:一次在第一阶段,两次在第二阶段。为了评估XAI技术的有效性,研究人员设计并执行了用户研究。用户研究是评估解释的黄金标准。在XAI研究人员进行的用户研究中,大约有12700名参与者,包括约1900名有监督的参与者,即个人在研究团队的指导(例如,亲自或通过Zoom)下完成实验,以及10800名无监督的参与者,即个人自我指导完成实验(例如,Amazon Mechanical Turk)。根据所有美国国防部资助的人类研究的政策,每个研究方案都由当地的机构审查委员会(IRB)审查,然后由国防部人类研究保护办公室审查该方案和当地IRB的结论。
在进行用户研究的过程中,发现了几个关键的启示:
与只提供决策的系统相比,用户更喜欢提供决策与解释的系统。在那些用户需要了解人工智能系统如何做出决定的内部运作的任务中,解释能够提供最大的价值。(由11个团队的实验支持)。
为了使解释能够提高用户任务表现,任务必须足够困难,以便于人工智能的解释起作用(PARC,UT Dallas)。
用户的认知负荷会阻碍用户解读解释时的表现。结合前面的观点,解释和任务难度需要被校准,以提高用户的表现(加州大学洛杉矶分校、俄勒冈州立大学)。
当人工智能不正确时,解释更有帮助,这一点对边缘案例特别有价值(加州大学洛杉矶分校、罗格斯大学)。
解释的有效性的措施可以随着时间的推移而改变(Raytheon, BBN)。
相对于单独的解释而言,建议性(Advisability)可以明显提高用户的信任度(加州大学伯克利分校)。
XAI对于测量和调整用户和XAI系统的心理模型很有帮助(罗格斯、SRI)。
最后,由于XAI的最后一年发生在COVID-19大流行的时期,我们的执行团队开发了设计网络界面的最佳实践,以便在不可能进行现场研究时进行XAI用户研究(OSU、UCLA)。
如前文所述,学习的性能和可解释性之间似乎存在着一种自然的紧张关系。然而在项目过程中,我们却发现,可解释性可以提高性能。从一个直观的角度来看,训练一个系统生成解释,通过额外的损失函数、训练数据或其他机制,提供额外的监督,以鼓励系统学习更有效的世界表征。虽然这不一定在所有情况下都是正确的,为了确定可解释的技术何时会有更高的性能,还需要做大量的工作,但它提供了希望,即未来的XAI系统可以比目前的系统性能更好,并同时满足用户对解释的需求。
04
DARPA 2021年计划之后的世界,AI和XAI的情况
目前还没有通用的XAI解决方案。如前文所述,就像我们与其他人互动时面临的情况一样,不同的用户类型需要不同类型的解释。可以参考一下医生向医生同事、病人或医疗审查委员会解释诊断的三个不同情景。也许未来的XAI系统能够在大规模的用户类型范围内自动校准并向特定的用户传达解释,但这大大超出了目前的技术水平。
开发XAI的挑战之一是衡量解释的有效性。DARPA的XAI工作已经帮忙开发了这个领域的基础技术,但还需要继续进行大量的研究,包括从人类因素和心理学界汲取更多的力量。为了使有效的解释成为ML系统的核心能力,需要认真确立解释有效性的衡量标准,这个标准应当易于理解,便于实施。
加州大学伯克利分校的研究结果表明,建议性,即人工智能系统接受用户建议的能力,可以提高用户对解释以外的信任度。当然,用户可能更喜欢那些像人类一样可以快速提供反馈,纠正行为的系统。这种既能生产又能消费解释的可建议的人工智能系统将成为实现人类和AI系统之间更紧密合作的关键。
为了有效地开发XAI技术,需要研究者跨多个学科进行密切合作,包括计算机科学、机器学习、人工智能、人类因素和心理学等等。这可能特别具有挑战性,因为研究人员往往专注于一个单一的领域,所以需要被动地进行跨领域工作。也许将来会在当前多个学科的交叉点上创建一个专门的XAI研究学科。
为此,我们努力创建了一个XAI工具包,该工具包收集了各种项目工件(如代码、论文、报告等)以及从为期4年的DARPA XAI项目中获得的经验教训,并将其放在一个可公开访问的中央位置(https://xaitk.org/)。我们相信,对那些在作战环境中部署AI能力,并需要在广泛的现实条件和应用领域中验证、描述和信任AI性能的人来说,该工具包将具有广泛的意义。
今天,我们对人工智能的理解比2015年时更加细致,也更加准确。当然,对深度学习的可能性和局限性也有了更深入的理解。AI的启示已经从一个迫在眉睫的危险淡化为一个渺远的探索目标。同样,XAI项目也为XAI领域提供了更细微的、正常的、可能也更准确的理解。该项目无疑是刺激XAI研究的催化剂(包括项目内部和外部),并得到了对XAI的使用和用户、XAI的心理学、衡量解释有效性的挑战了解更细致的结果,产生了新的XAI ML和人机交互技术组合。当然,前方任重而道远,特别是随着新的人工智能技术的开发,对解释的需求也将继续发展。XAI将在一段时间内继续作为一个活跃的研究领域。作者认为,XAI项目为启动这一大工程提供了基础,从而做出了重大贡献。