datax使用记录
这里写自定义目录标题
- datax执行命令后出现乱码
-
- datax执行xls文件流程注意事项
- txt到pg库的模板
- 注意分隔符,注意字符编码,注意字段映射,注意url
- 连接pg库时报错Description:[连接数据库失败. 请检查您的 账号、密码、数据库名称、IP、Port或者向 DBA 寻求帮助(注意网络环境).]. - 具体错误信息为:org.postgresql.util.PSQLException: The authentication type 10 is not supported.
- txtreader读取时因为双引号位置问题导致reader切分文件失败的解决办法
- 解决datax抽mysql数据到hdfs之null值变成‘‘(引号)的问题
datax执行命令后出现乱码
控制台出现乱码:直接输入CHCP 65001回车即可
datax执行xls文件流程注意事项
1.全选excel内容,设置单元格格式为"文本"
2.删除多余sheet页,只保留一个sheet页
3.有索引的把索引去掉,有标题的把标题去掉
4.文件另存为csv文件,CSV(逗号分隔)(.csv)
5.文件名后缀’.csv’改为’.txt’
6.打开该txt文档,转换编码格式为utf-8
6.datax的xml配置文件中关于txt的读取或写入部分,要保证index序号与下面的列名一一对应,可能一大堆列数据,但我只想要从其中拿出部分列来依次对应下面的指定列名。如果所有字段全部以string类型读取,可以 “column”: [ "" ],
txt到pg库的模板
{
"job": {
"setting": {
"speed": {
"channel": 5
}
},
"content": [
{
"reader": {
"name": "txtfilereader",
"parameter": {
"path": [
"C:/Users/Dawn/Desktop/CRM_CUST/inf_crm_customer.txt"
],
"encoding": "UTF-8",
"column": [
{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "string"
},
{
"index": 4,
"type": "string"
},
{
"index": 5,
"type": "string"
},
{
"index": 6,
"type": "string"
},
{
"index": 7,
"type": "string"
},
{
"index": 8,
"type": "string"
},
{
"index": 9,
"type": "string"
},
{
"index": 10,
"type": "string"
},
{
"index": 11,
"type": "string"
},
{
"index": 12,
"type": "string"
},
{
"index": 13,
"type": "string"
},
{
"index": 14,
"type": "string"
},
{
"index": 15,
"type": "string"
},
{
"index": 16,
"type": "string"
},
{
"index": 17,
"type": "string"
},
{
"index": 18,
"type": "string"
},
{
"index": 19,
"type": "string"
},
{
"index": 20,
"type": "string"
},
{
"index": 21,
"type": "string"
},
{
"index": 22,
"type": "string"
},
{
"index": 23,
"type": "string"
},
{
"index": 24,
"type": "string"
},
{
"index": 25,
"type": "string"
},
{
"index": 26,
"type": "string"
},
{
"index": 27,
"type": "string"
},
{
"index": 28,
"type": "string"
}
],
"fieldDelimiter": ""
}
},
"writer": {
"name": "postgresqlwriter",
"parameter": {
"username": "bdta_mid",
"password": "xxxxxx",
"column": ["CUST_ID","SEQ_NBR","CUST_ORDER_ID","ACTION_TYPE","CUST_NAME","CUST_NUMBER","INDUSTRY_TYPE_ID","TYPE_FLAG","CUST_TYPE","CUST_SUB_TYPE","IS_VIP","INDUSTRY_CD","CUST_AREA_GRADE","TOWN_FLAG","LIEU_ID","STATUS_CD","CUST_ADDR","ADDR_ID","CUST_MGR","INI_PASSWORD","DEF_ACCT_ID","GRP_CUST_CODE","CHARGE_PROVINCE_CODE","CHARGE_LAN_ID","NOT_REAL_REASON","ACCEPT_CHANNEL","REMARK","REGION_ID","CUST_BRAND_MODIFY"],
"preSql": [
"truncate table inf_crm_customer"
],
"connection": [
{
"jdbcUrl": "jdbc:postgresql://134.186.85.20:9999/bdta_middb",
"table": [
"inf_crm_customer"
]
}
]
}
}
}
]
}
}
字段全部为string时,reader的column部分可简写如下
{
"job": {
"setting": {
"speed": {
"channel": 5
}
},
"content": [
{
"reader": {
"name": "txtfilereader",
"parameter": {
"path": [
"C:/Users/Dawn/Desktop/CRM_CUST/org_user.txt"
],
"encoding": "UTF-8",
"column": [
"*"
],
"fieldDelimiter": ","
}
},
"writer": {
"name": "postgresqlwriter",
"parameter": {
"username": "bdta_mid",
"password": "2Jiv6bkLr8E%",
"column": ["USERID","USERTYPE","LOGINNAME","USERNAME","PASSWORD","GENDER","EMPLOYDATE","EMAIL","OFFICEPHONE","HOMEPHONE","MOBILEPHONE","PHS","PAGER","FAX","ISVALID","REMARK","LIMITEDIP","CREATEDATE","EXPIREDDATE","CREATORID","ISVIRTUAL","PHOTO","USERRDN","LASTCHANGEPWD","ISLIMITMULTILOGIN","INSERVICESTATUS"],
"preSql": [
"truncate table org_user"
],
"connection": [
{
"jdbcUrl": "jdbc:postgresql://134.176.84.20:18921/bdta_middb",
"table": [
"org_user"
]
}
]
}
}
}
]
}
}
注意分隔符,注意字符编码,注意字段映射,注意url
连接pg库时报错Description:[连接数据库失败. 请检查您的 账号、密码、数据库名称、IP、Port或者向 DBA 寻求帮助(注意网络环境).]. - 具体错误信息为:org.postgresql.util.PSQLException: The authentication type 10 is not supported.
这应该是需要换个和当前Pg库版本匹配的驱动包。
1.到datax工程下选取对应的模块reader和writer
2.在Pgwriter部分的pom.xml文件里进行修改

3.重新mvn打包编译
mvn -U clean package assembly:assembly -Dmaven.test.skip=true
txtreader读取时因为双引号位置问题导致reader切分文件失败的解决办法
“位置的不同会影响txtreader读取时划分字段,比如双引号紧邻分隔符就不行。
数据不多时或者数据不是自动传送时,notepad++将 " 全部转换为 " 就行。
关于"的错误数据样例,分隔符是chr(5):
RM20200102000139服保派单服保系统ARCHIVE20200102105759335A1CCE4859B772E1DE04400144FE31F7AEFCC29B1A7D336618D7FA2F8F1F650EEA28E9782CE94B4D925013BFCFA81660200000000B647059F99714435F9803F175F5693600nullQualityQualityOthernullnullAD99AADCB04624FF4EAE0A4EC9E01DAD144nullF9FA993DE7C8E7D5ADDDF0688AFDC9FCnullnullnullnullnullnullnullnullnullnullnullnullnullnullnull"16104-湘潭河西(新大楼方向)-核心环(工程态)//rack=0/shelf=1-28-EONA-401001(OUT)<>16105-湘潭新大楼(河西方向)-核心环(工程态)//rack=0/shelf=1-8-EONA-402001(IN)--OTS-单向-709496
也可以通过修改datax源码,xml文件增加相应配置来使其忽略杂七杂八分隔符。
通过不断的尝试,发现与CsvReader相关,需要在源码里修改为启用csvreader 的相关操作 并xml补充CsvReader的相关配置。
关于如何启动csvReaderConfig配置:
https://github.com/alibaba/DataX/pull/161/commits/08735a58be5e6e709112175cef1020472b0ef3d5
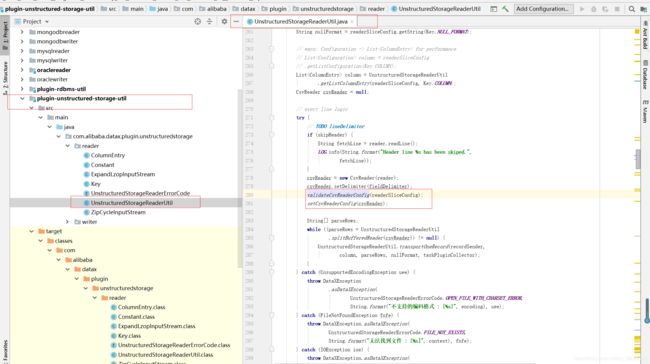
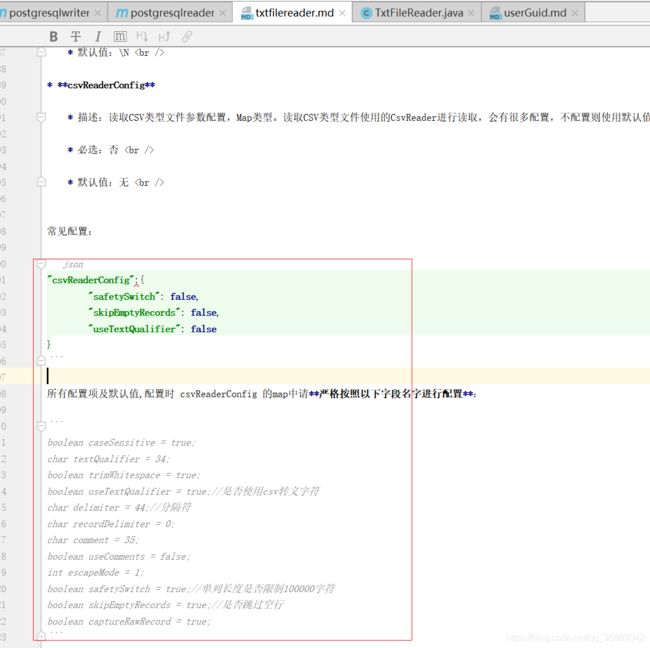
改码后重新编译,然后这个jar包覆盖替换txtreader里的jar包,然后xml reader配置参数

放在如图位置,重要参数useTextQualifier,使其忽略"
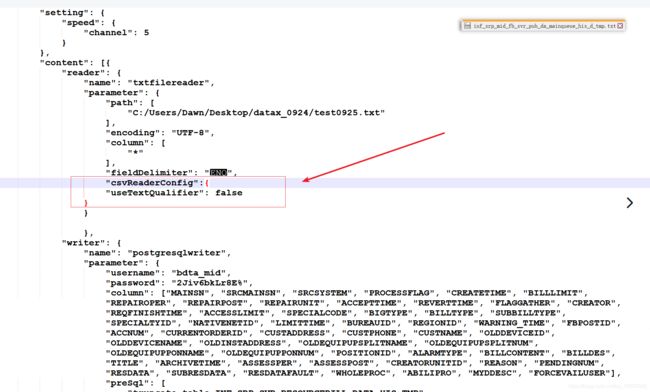
此时才启动Csvreader
TxtFileReader$Task - reading file : [/app/data/20200923/inf_srp_mid_fb_svr_pub_da_dispqueue_tmp.txt]
2020-09-24 21:55:02.528 [0-0-0-reader] INFO UnstructuredStorageReaderUtil - CsvReader使用默认值[{"captureRawRecord":true,"columnCount":0,"comment":"#","currentRecord":-1,"delimiter":"\u0005","escapeMode":1,"headerCount":0,"rawRecord":"","recordDelimiter":"\u0000","safetySwitch":false,"skipEmptyRecords":true,"textQualifier":"\"","trimWhitespace":true,"useComments":false,"useTextQualifier":true,"values":[]}],csvReaderConfig值为[null]
解决datax抽mysql数据到hdfs之null值变成‘‘(引号)的问题
https://blog.csdn.net/zuochang_liu/article/details/87807835
mysql的null值通过datax抽取到hdfs,会变成引号,这不是我们所需要的,所以需要修改一下datax的源码

(在pg库数据插入时,copy_from的方法执行的时候,空值也会变成’’,到时候看看源码看能不能改吧,但是copy_from是pg库本身的一个命令,,但是corsor.copy_from。。。)