《C++反汇编与逆向分析技术揭秘》阅读笔记——第二章 基本数据类型的表现形式
现在,我们进入了本书的第二部分,C++反汇编揭秘,在这一部分我的梳理方式是按照章节整理出我自己不太熟悉的知识点,并将我在阅读过程中遇到的疑惑提出来,如果有高手能看到我的文章,希望能对于我的疑惑给一点帮助。
2.1整数类型
(1)数据在内存中存放的两种方式:
1)小尾方式:以字节为单位,按照数据类型长度,低数据位排放在内存的低端,高数据存放在内存的高端,如0x12345678会存储为78 56 34 12。
2)大尾方式:与小尾方式相反,0x12345678会存储为12 34 56 78
逆向通常接触到的数据是以小尾方式储存的。
(2)32位有符号数的表示范围为-2 147 483 648~2 147 483 647,为什么负数要比正数多一个呢?
对于4字节补码,0x80000000所表达的意义可以是负数0(取反加1为10000000),也可以是0x80000001减去1,由于0的正负值是相等的,没有必要来个负数0,因此就把这个值规定为0x80000001减去1,这样0x80000001就成为4字节负数的最小值,也就是多出来的-2 147 483 648。
2.2浮点数类型
(1)实数储存的两种方式
1)定点实数存储方式:约定整数位和小数位的长度,比如用四字节存储实数,约定两个高字节存放整数部分,两个低字节存放小数部分,这样计算效率高但储存不灵活,比如想存储65536.5,由于整数部分超过了2字节,这就无法实现储存了。
2)浮点实数存储方式:用一部分二进制位存放小数点的位置信息(指数域),其它数据位用来存储没有小数点时的数据和符号(数据域、符号域)。
浮点型存储方式是主流,但在一些条件恶劣的嵌入式开发场合,仍可看到定点实数的存储和使用。
(2)浮点寄存器
(2)浮点数的操作不会用到通用寄存器,而会使用浮点协处理器的浮点寄存器。浮点寄存器是通过栈结构来实现的,由ST(0)~ST(7)共8个栈空间组成,每个浮点寄存器占8字节。每次使用浮点寄存器都是率先使用ST(0),而不能越过ST(0)直接使用ST(1)。浮点寄存器的使用就是压栈、出栈的过程,当ST(0)存在数据时,执行压栈操作后,ST(0)中的数据将装入ST(1)。常用浮点数指令的介绍如下,其中,IN表示入栈操作数,OUT表示出栈操作数(原文写的是操作数入栈和操作数出栈,但个人认为我的写法比较贴切)。
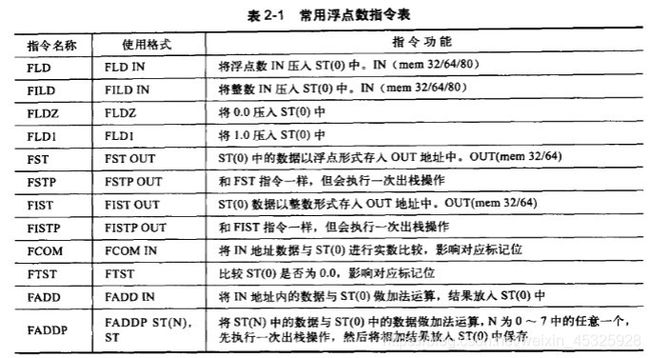
(3)浮点数的编码方式
浮点数的编码采用IEEE规定的编码标准。
1)float类型的IEEE编码
 如将11.3f转换为对应的二进制数1011.01001100110011001100(小数的二进制转换在这里就不说了)(要忽略最高位的1取23位,不够23位用0在后面补齐),整数部分为1011,小数部分01001100110011001100;小数点向左移动,每移动1次指数加1(向右则减1),移动到除符号位的最高位为1处,这里移动3次,即变为1.01101001100110011001100,11.3f转换后各位情况如下:
如将11.3f转换为对应的二进制数1011.01001100110011001100(小数的二进制转换在这里就不说了)(要忽略最高位的1取23位,不够23位用0在后面补齐),整数部分为1011,小数部分01001100110011001100;小数点向左移动,每移动1次指数加1(向右则减1),移动到除符号位的最高位为1处,这里移动3次,即变为1.01101001100110011001100,11.3f转换后各位情况如下:
符号位:0
指数位:十进制127+3,转换为二进制是10000010
尾数位:01101001100110011001100
拼接后即为:01000001001101001100110011001100,转换为16进制为0x4134CCCC,在内存中显示为CC CC 34 41。
为什么指数位要加127呢?由于指数可能出现负数,十进制数127可表示为二进制01111111,IEEE编码方式规定,当指数域小于01111111时为一个负数,反之为正数,因此127相当于0。
2)double类型的IEEE编码
Float占4个字节,而Double占8个字节,两者表达方式基本无异,double最高位也用于表示符号,但double指数位占11位,剩余52位用于表示尾数。
2.3字符与字符串
(1)ASCII编码与Unicode编码与乱码
ASCII只能表示英文的26个字母和常用符号,而仅汉字就足够占满ASCII编码,因此,占双字节,表示范围为0~65535的Unicode编码产生了。在VC中,使用char定义ASCII编码格式的字符,使用wchar_t定义Unicode编码格式的字符。
在程序中使用中文、韩文、日文的时候经常出现显示的内容都是乱码的情况,这是因为系统中缺少程序中所需语种的字符表,而这个字符表是用于解释所需语种的字符编码的,所以程序中的字符编码错误地对应到其他字符表中。
Unicode使用UCS-2编码格式来储存常用汉字,用UCS-4编码(两个Unicode编码解释一个汉字)储存不常用的汉字。
(2)字符串的储存方式
字符串是由一系列按照一定的编码顺序线性排列的字符组成的,在程序中只需要知道字符串的首地址和结束地址就可以确定字符串的长度和大小。在定义字符串的时候会先指定好首地址,结束地址的确定有两种方法。
一是保存总长度:
优点:获取字符串长度时,不用历遍字符串中的每个字符,取得首地址的前n字节(保存长度信息的位置)即可得到字符串的长度。(n的取值一般是1、2、4)
缺点:字符串长度不能超过n字节的表示范围,且要多开销n字节空间保存长度,最重要的是,如果涉及通信,双方交互前必须事先知道通信字符串的长度。
二是结束符
优点:没有记录长度的开销,涉及通信时,通信字符串可以根据实际情况结束,结束时附上结束符即可。
缺点:获取字符串长度需要历遍所有字符,某些情况下处理效率低。
C++使用结束符作为字符串结束标志,ASCII编码使用一个字节’\0’,而Unicode编码使用两个字节’\0’。需要注意的是,不能使用处理ASCII编码的函数对Unicode编码进行处理,否则会发生解释错误。
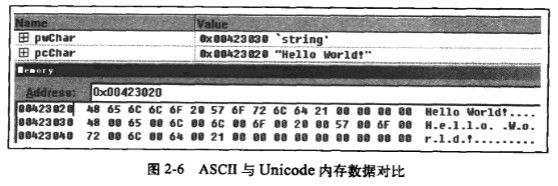
2.5地址、指针和应用
(1)指针与地址的区别

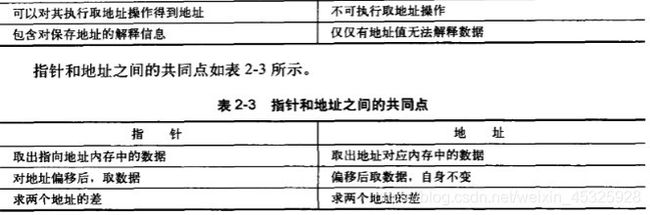
看到地址不能再取地址之后,我顿时明白了地址是个常数而指针是个变量的含义,一个指针取100次指针之后都还能取地址,而一个地址却不能再取地址了,这对我们分辨地址和指针有较大的助记意义。由于指针在定义时会根据指向的变量定义指针类型,所以可以对地址对应的数据进行解释,得出指向变量的类型(疑惑点:这个类型信息是如何储存的呢?书上似乎并没有明确提到这一点),这也是指针和地址的重要区别。

(2)引用与指针
引用类型在C++中被描述为变量的别名。实际上,C++为了简化指针操作,对指针的操作进行了封装,产生了引用类型。实际上引用类型就是指针类型,只不过它用于存放地址的内存空间对使用者而言是隐藏的。在汇编代码中其实引用与指针几乎没有区别,只是引用是通过编译器实现寻址,而指针需要手动寻址。
2.6常量
(1)常量是怎样的
常量数据在程序运行之前就已经存在,它们被编译到可执行文件中,当程序启动后,它们就被加载进来。它们通常在常量数据区中保存,该节区没有可写权限,所以在对常量进行修改时,程序会报错。
(2)#define与const
在C++中可以使用宏机制#define来定义变量,也可以使用const将变量定义为一个常量。#define定义的是一个真常量,const定义的是由编译器判断实现的常量,是一个假常量。

const修饰过的常量是可以修改的,利用指针获取到const修饰过的变量地址,强制将指针的const修饰去掉,就可以修改对应的数据内容。


我觉得这可以理解为尝试修改的时候相当于要穿墙而过,走到地下一层还有墙穿不过去,但当走到地下二层的时候就不需要穿墙而过去了,然后再走回上地面就相当于实现了穿墙,也即修改const修饰过的数值。
疑惑点:关于系统和编译器是如何对#define和const进行检查的,作者也没有作出解释,希望能有大佬解释一下。
在连接生成可执行文件后,这两者都将不复存在,而是直接被编译器优化为立即数,在二进制编码中也没有这两种类型存在。
(3)疑惑点:书上的预处理文件的部分完全没看懂


这段文字和图片意味着什么?
2.7章末总结
个人认为这一章的章末总结非常有意义:作为逆向工作者,需要对数据进行正确考察,对数据的考察有两点,一是“在何处”,二是“如何解释”。
关于“在何处”,首先要确定的是内存地址,然后得到内存属性,我们需要了解的属性有:可读、可写、可执行,藉此,我们可以知道此数据是否为变量(可读写),是否为常量(只读),是否为代码(可执行)等,除了属性以外,我们还可以考察进程在内存的布局,如战区、堆区、全局区、代码区等,藉此,我们又可以知道数据的作用域。是代码还是数据,这需要程序员依靠经验去判断。
关于“如何解释”,本章归纳了各种数据的解释方式和特点,需要我们重点掌握。