总结Java中的单列集合
目录
单列集合
集合体系结构
区别
方法
Collection系列集合三种通用的遍历方式
1 迭代器遍历
2 增强for遍历
3 Lambda表达式遍历
总结
List集合
List集合的特有方法
List集合的遍历方式
五种遍历方式对比
ArrayList
成员方法
ArrayList集合底层原理
LinkedList
HashSet
HashSet底层原理
哈希值
对象的哈希值特点
案例
LinkedHashSet底层原理
TreeSet
特点
练习
TreeSet集合默认的规则
TreeSet的两种比较方式
实现Comparable接口指定比较规则
创建TreeSet对象的时候,传递比较器Comparator指定规则
案例
使用场景:
泛型概述
泛型的好处
泛型的细节
泛型类
泛型方法
泛型方法的练习
泛型接口
泛型的继承和通配符
案例
数据结构概述
常见的数据结构
栈
队列
数组
链表
平衡二叉树
怎样保持平衡?
左旋
右旋
平衡二叉树需要旋转的四种情况
红黑树
红黑规则
添加节点的规则
单列集合
集合体系结构

区别
List集合:添加的元素是有序、可重复、有索引
Set集合:添加的元素是无序、不重复、无索引
方法
| 方法名称 | 说明 |
|---|---|
| public boolean add(E e) | 把给定的对象添加到当前集合中 |
| public void clear() | 清空集合中所有的元素 |
| public boolean remove(E e) | 把给定的对象在当前集合中删除 |
| public boolean contains(object obj) | 判断当前集合中是否包含给定的对象 |
| public boolean isEmpty() | 判断当前集合是否为空 |
| public int size() | 返回集合中元素的个数/集合的长度 |
Collection系列集合三种通用的遍历方式
1 迭代器遍历
迭代器在Java中的类是Iterator,迭代器是集合专用的遍历方式。
collection集合获取迭代器
| 方法名称 | 说明 |
|---|---|
| Iterator |
返回迭代器对象,默认指向当前集合的0索引 |
Iterator中的常用方法
| 方法名称 | 说明 |
|---|---|
| boolean hasNext() | 判断当前位置是否有元素,有元素返回true,没有元素返回false |
| E next() | 获取当前位置的元素,并将迭代器对象移向下一个位置。 |
public class CollectionDemo1 {
/**
* 迭代器遍历集合
* @param args
*/
public static void main(String[] args) {
//创建集合并添加元素
Collection coll = new ArrayList<>();
coll.add("aaa");
coll.add("bbb");
coll.add("ccc");
coll.add("ddd");
//获取迭代器对象
Iterator iterator = coll.iterator();
while (iterator.hasNext()){
String str = iterator.next();
System.out.println(str);
}
}
}
细节注意点
1,如果当前位置没有元素,还要强行获取,会报NoSuchElementException
2,迭代器遍历完毕,指针不会复位
3,循环中只能用一次next方法
4.迭代器遍历时,不能用集合的方法进行增加或者删除;如果要删除:那么可以用迭代器提供的remove方法进行删除。如果要添加,暂时没有办法。
2 增强for遍历
增强for的底层就是迭代器,为了简化迭代器的代码书写的。它是JDK5之后出现的,其内部原理就是一个Iterator迭代器。
所有的单列集合和数组才能用增强for进行遍历。

/**
* 增强for遍历集合
* @param args
*/
public static void main(String[] args) {
//创建集合并添加元素
Collection coll = new ArrayList<>();
coll.add("aaa");
coll.add("bbb");
coll.add("ccc");
coll.add("ddd");
//str其实就是一个第三方变量,在循环过程中依次表示集合中的每一个数据
for (String str : coll){
System.out.println(str);
}
} 3 Lambda表达式遍历
得益于JDK 8开始的新技术Lambda表达式,提供了一种更简单、更直接的遍历集合的方式
| 方法名称 | 说明 |
|---|---|
| default void forEach(consumer action): | 结合lambda遍历集合 |
public static void main(String[] args) {
//创建集合并添加元素
Collection coll = new ArrayList<>();
coll.add("aaa");
coll.add("bbb");
coll.add("ccc");
coll.add("ddd");
//利用匿名内部类的形式
/*coll.forEach(new Consumer() {
@Override
public void accept(String s) {
System.out.println(s);
}
});//aaa
//bbb
//ccc
//ddd*/
//lambda表达式 () -> {}
coll.forEach(s -> System.out.println(s));
} 总结
1.Collection是单列集合的顶层接口,所有方法被List和Set系列集合共享 2.常见成员方法: add、clear、remove、contains、isEmpty、size 3.三种通用的遍历方式 迭代器:在遍历的过程中需要删除元素,请使用迭代器增强for、Lambda: 仅仅想遍历,那么使用增强for或Lambda表达式
List集合
List集合的特有方法
Collection的方法List都继承了 List集合因为有索引,所以多了很多索引操作的方法。
| 方法名称 | 说明 |
|---|---|
| void add(int index,E element) | 在此集合中的指定位置插入指定的元素 |
| E remove(int index) | 删除指定索引处的元素,返回被删除的元素 |
| E set(int index,E element) | 修改指定索引处的元素,返回被修改的元素 |
| E get(int index) | 返回指定索引处的元素 |
List集合的遍历方式
迭代器遍历 列表迭代器遍历 增强for遍历 Lambda表达式遍历 普通for循环(因为List集合存在索引)
五种遍历方式对比
迭代器遍历 : 在遍历的过程中需要删除元素,请使用迭代器。
列表迭代器 : 在遍历的过程中需要添加元素,请使用列表迭代器
增强for遍历 Lambda表达式 仅仅想遍历,那么使用增强for或Lambda表达式
普通for : 如果遍历的时候想操作索引,可以用普通for。
public class ListDemo1 {
/**
* list集合的五种遍历方式
*
* @param args
*/
public static void main(String[] args) {
List list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
//1.迭代器遍历
System.out.println("1.迭代器遍历:");
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
String s = iterator.next();
System.out.println(s);
}
//增强for遍历
System.out.println("2.增强for遍历:");
for (String s : list) {
System.out.println(s);
}
//lambda表达式遍历
System.out.println("3.lambda表达式遍历:");
list.forEach(s -> System.out.println(s));
//普通for遍历
System.out.println("4.普通for遍历:");
for (int i = 0; i < list.size(); i++) {
String s = list.get(i);
System.out.println(s);
}
//列表迭代器遍历
System.out.println("5.列表迭代器遍历");
ListIterator stringListIterator = list.listIterator();
while (stringListIterator.hasNext()){
String s = stringListIterator.next();
System.out.println(s);
}
}
} ArrayList
成员方法
| 方法名 | 说明 |
|---|---|
| boolean add(E e) | 添加元素,返回值表示是否添加成功 |
| boolean remove(E e) | 删除指定元素,返回值表示是否成功 |
| E remove(int index) | 删除指定索引元素,返回被删除的元素 |
| E set(int index,E e) | 修改指定索引下的元素,返回原来的元素 |
| E get(int index) | 获取指定索引处的元素 |
| int size() | 集合的长度,也就是集合中元素的个数 |
ArrayList集合底层原理
ArrayList底层是数组结构的
① 利用空参创建的集合,在底层创建一个默认长度为0的数组
② 添加第一个元素时,底层会创建一个新的长度为10的数组 ③ 存满时,会扩容1.5倍 ④ 如果一次添加多个元素,1.5倍还放不下,则新创建数组的长度以实际为准

LinkedList
底层数据结构是双链表,查询慢,增删快,但是如果操作的是首尾元素,速度也是极快的,LinkedList本身多了很多直接操作首尾元素的特有API。
| 特有方法 | 说明 |
|---|---|
| public void addFirst(E e) | 在该列表开头插入指定的元素 |
| public void addLast(E e) | 将指定的元素追加到此列表的末尾 |
| public E getFirst() | 返回此列表中的第一个元素 |
| public E getLast() | 返回此列表中的最后一个元素 |
| public E removeFirst() | 从此列表中删除并返回第一个元素 |
| public E removeLast() | 从此列表中删除并返回最后一个元素 |

HashSet
HashSet底层原理
HashSet集合底层采取哈希表存储数据 哈希表是一种对于增删改查数据性能都较好的结构 哈希表组成: JDK8之前:数组+链表 JDK8开始:数组+链表+红黑树
创建一个默认长度16,默认加载因子0.75的数组,数组名table 根据元素的哈希值跟数组的长度计算出应存入的位置 : int index = (数组长度 - 1) & 哈希值; 判断当前位置是否为null,如果是null直接存入 如果位置不为null,表示有元素,则调用equals方法比较属性值 一样:不存 不一样:存入数组,形成链表 JDK8以前:新元素存入数组,老元素挂在新元素下面 JDK8以后:新元素直接挂在老元素下面
JDK8以后,当链表长度超过8而且数组长度大于等于64时,自动转换为红黑树 如果集合中存储的是自定义对象,必须要重写hashcode和equals方法
哈希值
根据hashcode方法算出来的int类型的整数 该方法定义在0bject类中,所有对象都可以调用,默认使用地址值进行计算
一般情况下,会重写hashcode方法,利用对象内部的属性值计算哈希值
对象的哈希值特点
如果没有重写hashcode方法,不同对象计算出的哈希值是不同的 如果已经重写hashcode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样。(哈希碰撞)
public class HashSetDemo1 {
public static void main(String[] args) {
/**
* 如果没有重写hashcode方法,不同对象计算出的哈希值是不同的
* 如果已经重写hashcode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
* 在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样。(哈希碰撞)
*/
Student s1 = new Student("张三",23);
Student s2 = new Student("张三",23);
//如果没有重写hashcode方法,不同对象计算出的哈希值是不同的
//System.out.println(s1.hashCode());//1784662007
//System.out.println(s2.hashCode());//997110508
//如果已经重写hashcode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
System.out.println(s1.hashCode());//24022543
System.out.println(s2.hashCode());//24022543
//在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样。(哈希碰撞)
System.out.println("abc".hashCode());//96354
System.out.println("acD".hashCode());//96354
}
}案例
利用HashSet集合去除重复元素 需求创建一个存储学生对象的集合,存储多个学生对象。 使用程序实现在控制台遍历该集合 学生对要求象的成员变量值相同,我们就认为是同一个对象
public class Student {
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "Student{name = " + name + ", age = " + age + "}";
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
public class HashSetDemo2 {
public static void main(String[] args) {
Student student = new Student("张三", 23);
Student student1 = new Student("李四", 24);
Student student2 = new Student("王五", 25);
Student student3 = new Student("张三", 23);
HashSet set = new HashSet<>();
set.add(student);
set.add(student1);
set.add(student2);
set.add(student3);
for (Student student4 : set) {
System.out.println(student4);
}
}
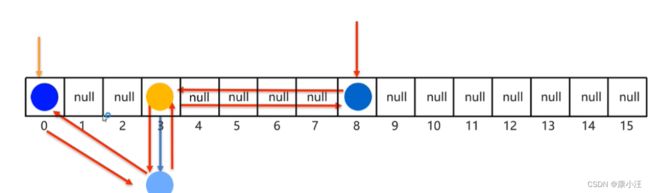
} LinkedHashSet底层原理
有序、不重复、无索引。
这里的有序指的是保证存储和取出的元素顺序一致.
原理:底层数据结构是依然哈希表,只是每个元素又额外的多了一个双链表的机制记录存储的顺序。
TreeSet
特点
不重复、无索引、可排序 可排序:按照元素的默认规则(有小到大)排序 TreeSet集合底层是基于红黑树的数据结构实现排序的,增删改查性能都较好
练习
TreeSet对象排序练习题 需求:存储整数并进行排序
public class TreeSetDemo1 {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet<>();
treeSet.add(3);
treeSet.add(5);
treeSet.add(2);
treeSet.add(4);
treeSet.add(1);
System.out.println(treeSet); //[1, 2, 3, 4, 5]
}
} TreeSet集合默认的规则
对于数值类型:Integer,Double,默认按照从小到大的顺序进行排序
对于字符、字符串类型:按照字符在ASCII码表中的数字升序进行排序。
TreeSet的两种比较方式
方式一:默认排序/自然排序:JavaBean类实现Comparable接口指定比较规则 方式二:比较器排序:创建TreeSet对象的时候,传递比较器Comparator指定规则
使用原则:默认使用第一种,如果第一种不能满足当前需求,就使用第二种
实现Comparable接口指定比较规则
实现Comparable接口指定比较规则
/**
需求:创建TreeSet集合,并添加3个学生对象
学生对象属性:
姓名,年龄。
要求按照学生的年龄进行排序
同年龄按照姓名字母排列(暂不考虑中文)同姓名,同年龄认为是同一个人
*/
public class Student2 implements Comparable{
private String name;
private int age;
public Student2() {
}
public Student2(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "Student2{name = " + name + ", age = " + age + "}";
}
@Override
public int compareTo(Student2 o) {
//this:当前要存入的元素
//o : 已经存在的元素
//正数 : 存右边
//负数 : 存左边
// 0 : 不存
return o.getAge() - this.getAge();
}
}
public class TreeSetDemo2 {
public static void main(String[] args) {
TreeSet set = new TreeSet<>();
Student2 s1 = new Student2("zhangsan",23);
Student2 s2 = new Student2("lisi",24);
Student2 s3 = new Student2("wangwu",25);
set.add(s1);
set.add(s2);
set.add(s3);
System.out.println(set);
}
}
[Student2{name = wangwu, age = 25}, Student2{name = lisi, age = 24}, Student2{name = zhangsan, age = 23}] 创建TreeSet对象的时候,传递比较器Comparator指定规则
创建TreeSet对象的时候,传递比较器Comparator指定规则
/**
* 需求:请自行选择比较器排序和自然排序两种方式,
* 要求:存入四个字符串,"c"“ab”,“df”"qwer*
* 按照长度排序,如果一样长则按照首字母排序
*/
public class TreeSetDemo3 {
public static void main(String[] args) {
TreeSet ts = new TreeSet<>(new Comparator() {
@Override
public int compare(String o1, String o2) {
int i = o1.length() - o2.length();
i = i == 0 ? o1.compareTo(o2) : i;
return i;
}
});
ts.add("c");
ts.add("ab");
ts.add("df");
ts.add("qwer");
System.out.println(ts);
System.out.println("-----------------");
//Comparator是函数式接口,所以可以使用lambda表达式
TreeSet ts1 = new TreeSet<>((o1, o2)-> {
int i = o1.length() - o2.length();
i = i == 0 ? o1.compareTo(o2) : i;
return i;
}
);
ts.add("c");
ts.add("ab");
ts.add("df");
ts.add("qwer");
System.out.println(ts);
}
} 案例
需求:创建5个学生对象 属性:(姓名,年龄,语文成绩,数学成绩,英语成绩)按照总分从高到低输出到控制台 如果总分一样,按照语文成绩排;如果语文一样,按照数学成绩排;如果数学成绩一样,按照英语成绩;排如果英文成绩一样,按照年龄排;如果年龄一样,按照姓名的字母顺序排;如果都一样,认为是同一个学生,不存。
public class Student3 implements Comparable {
private String name;
private int age;
private int chinese;
private int math;
private int english;
public Student3() {
}
public Student3(String name, int age, int chinese, int math, int english) {
this.name = name;
this.age = age;
this.chinese = chinese;
this.math = math;
this.english = english;
}
/**
* 获取
*
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
*
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
*
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
*
* @param age
*/
public void setAge(int age) {
this.age = age;
}
/**
* 获取
*
* @return chinese
*/
public int getChinese() {
return chinese;
}
/**
* 设置
*
* @param chinese
*/
public void setChinese(int chinese) {
this.chinese = chinese;
}
/**
* 获取
*
* @return math
*/
public int getMath() {
return math;
}
/**
* 设置
*
* @param math
*/
public void setMath(int math) {
this.math = math;
}
/**
* 获取
*
* @return english
*/
public int getEnglish() {
return english;
}
/**
* 设置
*
* @param english
*/
public void setEnglish(int english) {
this.english = english;
}
public String toString() {
return "Student3{name = " + name + ", age = " + age + ", chinese = " + chinese + ", math = " + math + ", english = " + english + "}";
}
@Override
public int compareTo(Student3 o) {
//先比较总分
int sum1 = this.chinese + this.getMath() + this.getEnglish();
int sum2 = o.chinese + o.getMath() + o.getEnglish();
//如果总分一样,按照语文成绩排
int i = sum1 - sum2;
i = i == 0 ? this.getChinese() - o.getChinese() : i;
//如果语文一样,按照数学成绩排
i = i == 0 ? this.getMath() - o.getMath() : i;
//如果数学成绩一样,按照英语成绩
i = i == 0 ? this.getEnglish() - o.getEnglish() : i;
//如果英文成绩一样,按照年龄排
i = i == 0 ? this.getAge() - o.getAge() : i;
//如果年龄一样,按照姓名的字母顺序排
i = i == 0 ? this.getName().compareTo(o.getName()) : i;
return i;
}
}
public class TreeSet4 {
public static void main(String[] args) {
//创建学生对象
Student3 sd1 = new Student3("zhangsan",23,90,99,50);
Student3 sd2 = new Student3("lisi",24,90,98,50);
Student3 sd3 = new Student3("wangwu",25,95,100,30);
Student3 sd4 = new Student3("zhaoliu",26,60,99,70);
Student3 sd5 = new Student3("qianqi",26,70,80,70);
//创建集合对象
TreeSet ts = new TreeSet<>();
//添加元素
ts.add(sd1);
ts.add(sd2);
ts.add(sd3);
ts.add(sd4);
ts.add(sd5);
for (Student3 t : ts) {
System.out.print(t + " " + "总分 : ");
System.out.println(t.getChinese()+t.getMath()+t.getEnglish());
}
}
} 使用场景:
1.如果想要集合中的元素可重复
用ArrayList集合,基于数组的。(用的最多)
2.如果想要集合中的元素可重复,而且当前的增删操作明显多于查询
用LinkedList集合,基于链表的, 3.如果想对集合中的元素去重
用Hashset集合,基于哈希表的。(用的最多) 4.如果想对集合中的元素去重,而且保证存取顺序
用LinkedHashSet集合,基于哈希表和双链表,效率低于Hashset 5.如果想对集合中的元素进行排序
用TreeSet集合,基于红黑树。后续也可以用List集合实现排序。
泛型概述
泛型:是JDK5中引入的特性,可以在编译阶段约束操作的数据类型,并进行检查。
泛型的格式:<数据类型>
注意:泛型只能支持引用数据类型
没有泛型的时候,集合如何存储数据? 如果我们没有给集合指定类型,默认认为所有的数据类型都是object类型,此时可以往集合添加任意的数据类型。 带来一个坏处:我们在获取数据的时候,无法使用他的特有行为。
泛型的好处
统一数据类型。 把运行时期的问题提前到了编译期间,避免了强制类型转换可能出现的异常,因为在编译阶段类型就能确定下来。
泛型的细节
泛型中不能写基本数据类型,要写对应的包装类 指定泛型的具体类型后,传递数据时,可以传入该类类型或者其子类类型 如果不写泛型,类型默认是Object
泛型类
使用场景:当一个类中,某个变量的数据类型不确定时,就可以定义带有泛型的类
格式:
修饰符 class 类名<类型>{
}
举例:
public class ArrayList {
}
此处E可以理解为变量,但是不是用来记录数据的,而是记录数据的类型,可以写成:T、E、K、V等 /**
* 当编写一个类时,如果不确定类型,那么这个类就可以定义成泛型类
* @param
*/
public class MyArrayList {
Object[] object = new Object[10];
int size;
/**
* T 表示一个不确定的类型,该类型已经在类名后面定义过了
* @param t
* @return
*/
public boolean add(T t){
object[size] = t;
size++;
return true;
}
} 泛型方法
当方法中形参类型不确定时 方案①:使用类名后面定义的泛型 : 所有方法都能用 方案②:在方法申明上定义自己的泛型 : 只有本方法能用
格式:
修饰符 <类型>返回值类型 方法名(类型 变量名){
}
举例:
public void show(T t)P{
}
调用该方法时,T就确定类型
此处T可以理解为变量,但是不是用来记录数据的,而是记录类型的,可以写成:T、E、K、V等 泛型方法的练习
定义一个工具类:Listutil 类中定义一个静态方法addAll,用来添加多个集合的元素。
public class ListUtil {
private ListUtil(){}
public static void addAll(ArrayList list,T...t){
for (T t1 : t) {
list.add(t1);
}
}
} 泛型接口
格式:
修饰符 interface 接囗名<类型>{
}
举例:
public interface List {
} 如何使用一个带泛型的接口
方式1:实现类给出具体类型
方式2:实现类延续泛型,创建对象时再确定
实现类给出具体类型
public class MyList implements List {
}
实现类延续泛型,创建对象时再确定
public class MyList implements List {
}
MyList list = new MyList<>(); 泛型的继承和通配符
泛型不具备继承性,但是数据具备继承性
如果我们在定义类、方法、接口的时候,类型不确定,就可以定义泛型类、泛型方法、泛型接口。
如果类型不确定,但是能知道以后只能传递某个继承体系中的,就可以使用泛型的通配符 泛型的通配符:就是可以限定类型的范围。
?也表示不确定的类型 他可以进行类型的限定 ? extends E:表示可以传递E或者E所有的子类类型 ? super E:表示可以传递E或者E所有的父类类型
案例
需求: 定义一个继承结构: 动物 猫 狗 猫 波斯猫 狸花猫 狗 泰迪 哈士奇
属性: 名字,年龄 行为: 吃东西 方法体打印: 一只叫做xXX的,X岁的波斯猫,正在吃小饼干 方法体打印: -只叫做xxX的,X岁的狸花猫,正在吃鱼 方法体打印: 一只叫做XXX的,X岁的泰迪,正在吃骨头,边吃边蹭 方法体打印: 一只叫做xXX的,X岁的哈士奇,正在吃骨头,边吃边拆家 测试类中定义一个方法用于饲养动物 public static void keepPet(ArrayList 1ist){
//遍历集合,调用动物的eat方法
}
要求1:该方法能养所有品种的猫,但是不能养狗 要求2:该方法能养所有品种的狗,但是不能养猫 要求3:该方法能养所有的动物,但是不能传递其他类型
package myList.Demo;
/**
* @Description:
* @ClassName: Animals
* @Author: 康小汪
* @Date: 2024/1/31 18:47
* @Version: 1.0
*/
public abstract class Animals {
private String name;
private int age;
public Animals() {
}
public Animals(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "Animals{name = " + name + ", age = " + age + "}";
}
public abstract void eat();
}
public abstract class Cat extends Animals{
}
public class BoSiCat extends Cat {
@Override
public void eat() {
System.out.println("一只叫做" + getName() + "的," + getAge() + "岁的波斯猫,正在吃小饼干");
}
}
public class LiHuaCat extends Cat {
@Override
public void eat() {
System.out.println("-只叫做" + getName() + "的," + getAge() + "岁的狸花猫,正在吃鱼");
}
}
public abstract class Dog extends Animals{
}
public class TaiDiDog extends Dog {
@Override
public void eat() {
System.out.println("一只叫做" + getName() + "的," + getAge() + "岁的泰迪,正在吃骨头,边吃边蹭");
}
}
public class HaShiQiDog extends Dog {
@Override
public void eat() {
System.out.println("一只叫做" + getName() + "的," + getAge() + "岁的哈士奇,正在吃骨头,边吃边拆家");
}
}
public class Test {
public static void main(String[] args) {
ArrayList cats = new ArrayList<>();
Cat cat = new BoSiCat();
cat.setName("k");
cat.setAge(1);
cats.add(cat);
ArrayList dogs = new ArrayList<>();
ArrayList animals = new ArrayList<>();
keepPet(cats);
keepPet1(dogs);
keepPet2(animals);
}
/**
* 该方法能养所有品种的猫,但是不能养狗
*/
public static void keepPet(ArrayList list) {
for (Cat cat : list) {
cat.eat();
}
}
/**
* 该方法能养所有品种的狗,但是不能养猫
*/
public static void keepPet1(ArrayList list) {
}
/**
* 该方法能养所有的动物,但是不能传递其他类型
*/
public static void keepPet2(ArrayList list) {
}
}
数据结构概述
数据结构是计算机底层存储、组织数据的方式。 是指数据相互之间是以什么方式排列在一起的。 数据结构是为了更加方便的管理和使用数据,需要结合具体的业务场景来进行选择。 一般情况下,精心选择的数据结构可以带来更高的运行或者存储效率。
常见的数据结构
栈、队列、数组、链表、二叉树、二叉查找树、平衡二叉树、红黑树
栈
栈的特点:后进先出,先进后出
数据进入栈模型的过程称为:压/进栈
数据离开栈模型的过程称为:弹/出栈
队列
队列的特点:先进先出,后进后出
数据从后端进入队列模型的过程称为:入队列
数据从前端离开队列模型的过程称为:出队列
数组
数组是一种查询快,增删慢的模型 查询速度快:查询数据通过地址值和索引定位,查询任意数据耗时相同。(元素在内存中是连续存储的) 删除效率低:要将原始数据删除,同时后面每个数据前移。 添加效率极低:添加位置后的每个数据后移,再添加元素。
链表
链表中的结点是独立的对象,在内存中是不连续的,每个结点包含数据值和下一个结点的地址。 链表查询慢,无论查询哪个数据都要从头开始找。 链表增删相对快(数组)
平衡二叉树
规则:任意节点左右子树高度差不超过1
怎样保持平衡?
平衡二叉树的旋转机制 规则1:左旋 规则2:右旋 触发时机:当添加一个节点之后,该树不再是一颗平衡二叉树
左旋

步骤:
确定支点:从添加的节点开始,不断的往父节点找不平衡的节点 以不平衡的点作为支点
把支点左旋降级,变成左子节点
晋升原来的右子节点

确定支点:从添加的节点开始,不断的往父节点找不平衡的节点 如以不平衡的点作为支点 将根节点的右侧往左拉 原先的右子节点变成新的父节点,并把多余的左子节点出让,给已经降级的根节点当右子节点
右旋

确定支点:从添加的节点开始,不断的往父节点找不平衡的节点 以不平衡的点作为支点 把支点右旋降级,变成右子节点 晋升原来的左子节点

确定支点:从添加的节点开始,不断的往父节点找不平衡的节点 以不平衡的点作为支点 就是将根节点的左侧往右拉 原先的左子节点变成新的父节点,并把多余的右子节点出让,给已经降级的根节点当左子节点
平衡二叉树需要旋转的四种情况
左左 :当根节点左子树的左子树有节点插入,导致二叉树不平衡
一次右旋
左右 : 当根节点左子树的右子树有节点插入,导致二叉树不平衡
先局部左旋,再整体右旋
右右:当根节点右子树的右子树有节点插入,导致二叉树不平衡
一次左旋:当根节点右子树的左子树有节点插入,导致二叉树不平衡
右左 先局部右旋,再整体左旋
红黑树
红黑树是一种自平衡的二叉查找树,是计算机科学中用到的一种数据结构。 1972年出现,当时被称之为平衡二叉B树。后来,1978年被修改为如今的"红黑树"。它是一种特殊的二叉查找树,红黑树的每一个节点上都有存储位表示节点的颜色,每一个节点可以是红或者黑;红黑树不是高度平衡的,它的平衡是通过"红黑规则"进行实现的。
平衡二叉树和红黑树的区别:
平衡二叉树 : 高度平衡;当左右子树高度差超过1时,通过旋转保持平衡
红黑树 : 是一个二叉查找树:但是不是高度平衡的
条件:特有的红黑规则
红黑规则
① 每一个节点或是红色的,或者是黑色的 ② 根节点必须是黑色 ③ 如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点,每个叶节点(Nil)是黑色的
④ 如果某一个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)
⑤ 对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点;

添加节点的规则
——红黑树在添加节点的时候,添加的节点默认是红色的(效率高)。
红黑树增删改查的性能都很好。
