MySQL亿级数据的查询优化-历史表该如何建
前端时间在知乎上看到一个问题,今天有空整理并测试了一下:
这个问题很具体,所以还是可以去尝试优化一下,我们基于InnoDB并使用自增主键来讲。
比较简单的做法是将历史数据存放到另一个表中,与最近的数据分开。那是不是历史表随便建就行了?其实这里的区别很大:
先讲一下优化思路:如果数据量太大(远远超过内存),对于批量查询来说单纯的添加索引作用不大,需要将数据按照查询重新组织降低查询需要的IO次数。
首先拿一组数据来分析一下,如果采用自增ID,数据按写入顺序存储在磁盘上,数据在磁盘上的分布情况大体如下:
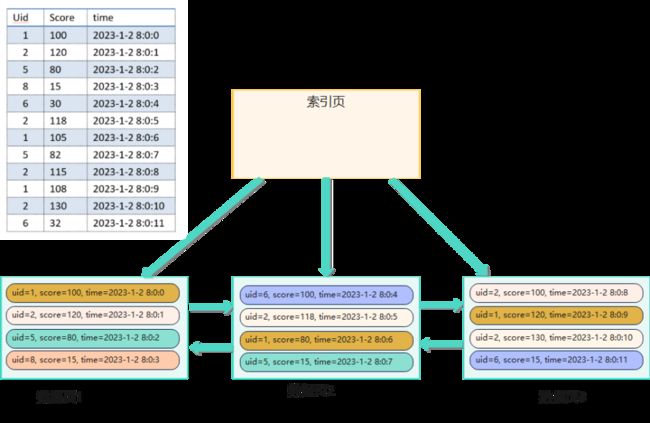
如果把用户1的所有数据都查询出来,并且这些数据页都不在内存的情况下,需要执行3次IO。
但是,只要将数据整理一下,同一个用户的数据顺序存放,即数据的组织方式如下:
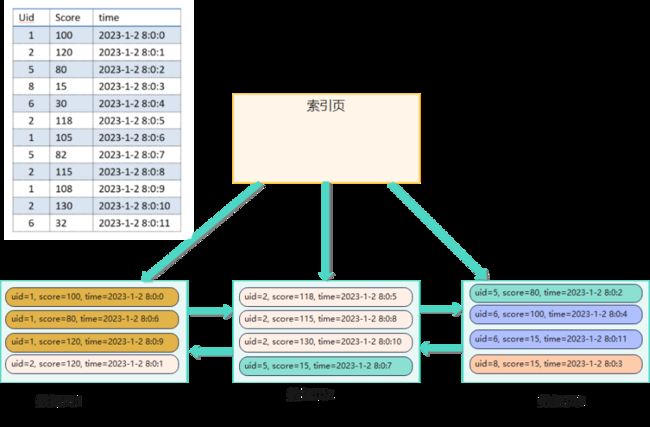
查询用户1的所有数据,并且这些数据页都不在内存的情况下,只需要执行1次IO即可。
在这个场景中,通常一次读取几百条到上千条积分变化数据,性能差异还是非常明显的。
现在的问题是:怎么让数据的组织是顺序的?其实很简单,只需要在转储时将一个用户的所有数据一起转储(也就是相邻写入,这样他们存储在磁盘上也是相邻的)。
附:这里我们设计一个场景分别测试一下这两种情况的性能差别。
使用下面的语句创建两个表:
CREATE TABLE t_score_log_1
(
`id` bigint AUTO_INCREMENT,
`user_id` int,
`score` int,
`log_time` datetime,
PRIMARY KEY(`id`),
KEY `idx_user_id`(`user_id`)
);
CREATE TABLE t_score_log_2
(
`id` bigint AUTO_INCREMENT,
`user_id` int,
`score` int,
`log_time` datetime,
PRIMARY KEY(`id`),
KEY `idx_user_id`(`user_id`)
) ;然后,创建两个存储过程用于向两个表中插入数据:
DELIMITER $
CREATE PROCEDURE insert_proc_1()
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE uid INT DEFAULT 0;
WHILE i < 1000
DO
SET uid = 1;
WHILE uid < 100001
DO
INSERT INTO t_score_log_1(`user_id`,`score`,`log_time`)
VALUES(uid, i % 100, DATE_ADD('2023-1-1',interval i second));
SET uid = uid + 1;
IF uid % 1000 = 0 THEN
COMMIT;
END IF;
END WHILE;
SET i = i + 1;
COMMIT;
END WHILE;
END $
DELIMITER ;
DELIMITER $
CREATE PROCEDURE insert_proc_2()
BEGIN
DECLARE i INT DEFAULT 0;
DECLARE uid INT DEFAULT 1;
WHILE uid < 100001
DO
SET i = 0;
WHILE i < 1000
DO
INSERT INTO t_score_log_2(`user_id`,`score`,`log_time`)
VALUES(uid, i % 100, DATE_ADD('2023-1-1',interval i second));
SET i = i + 1;
END WHILE;
SET uid = uid + 1;
COMMIT;
END WHILE;
END $
DELIMITER ;接着,调用这两个函数向两个表中写入数据:
call insert_proc_1();
call insert_proc_2();注意:为了更快的插入数据,关闭mysql的binlog并设置innodb_flush_log_at_trx_commit为0。
***************等待中****************
终于,数据插入完成,随机查询一些用户的历史数据比较一下耗时:
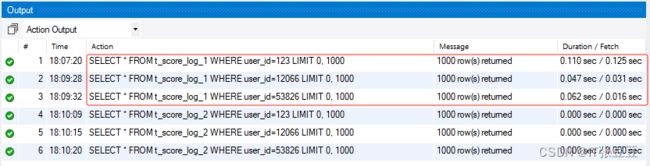
可以看到针对整理过后的数据(也就是表:t_score_log_2)查询性能远远高于未整理的表。
所以,针对历史数据特别大的场景,适当调整数据的分布情况可以极大的提升查询性能。