Ubuntu22.04安装OpenPcDet训练kitti数据集(nuscenes-mini数据集)
0.前言
因为想要接触KITTI数据集和Nuscenes数据集,有相关项目需要配置OpenPcDet,而原服务器因系统重装为Ubuntu22.04版本,该版本较高故重新配置环境是需要参考各种渠道,在此将这些参考汇总,也方便自己以后再配置可以清晰一点。本文综合了多篇文章。
1.环境配置
默认已安装好NVIDIA驱动
1.1 安装cuda和cudnn
1.1.1前置工作
首先查看自己的显卡信息
nvidia-smi+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.54.03 Driver Version: 535.54.03 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 3090 Off | 00000000:3B:00.0 Off | N/A |
| 30% 39C P8 21W / 350W | 10MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
| 1 NVIDIA GeForce RTX 3090 Off | 00000000:AF:00.0 Off | N/A |
| 32% 37C P8 24W / 350W | 9MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
| 2 NVIDIA GeForce RTX 3090 Off | 00000000:D8:00.0 Off | N/A |
| 30% 36C P8 22W / 350W | 9MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1955 G /usr/lib/xorg/Xorg 4MiB |
| 1 N/A N/A 1955 G /usr/lib/xorg/Xorg 4MiB |
| 2 N/A N/A 1955 G /usr/lib/xorg/Xorg 4MiB |
+---------------------------------------------------------------------------------------+
能够显示上述样式即说明已经安装显卡驱动了。通常装好的Ubuntu中都有显卡驱动。
如果没有装驱动,Ubuntu有一种简便的装驱动方式,在软件与更新里找到附加驱动,一般来说挑一个数字版本比较大的安装即可,安装完毕重启电脑,再次输入nvida-smi查看是否安装成功。
在输入nvidia-smi后你可以看到右上角有CUDA Version:12.2(与自己系统的版本有关,可能不同),这不代表你的cuda安装成功了,这个版本是cuda的最高安装版本,所以我们需要根据自己所搭建的网络来决定自己安装的cuda版本。
本文安装的版本cuda 11.3和cudnn 8.2.1
1.1.2 降低g++版本
Ubuntu 22.04默认g++11版本太高,会导致cuda无法安装或后续编译时出现gcc与cuda版本不匹配的问题,因此要先降低g++版本。
sudo apt-get install gcc-7 g++-7
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 9
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-11 1
sudo update-alternatives --display gcc
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-7 9
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-11 1
sudo update-alternatives --display g++
如果分别显示即完成优先度更改
gcc - 自动模式
最佳链接版本为 /usr/bin/gcc-7
链接目前指向 /usr/bin/gcc-7
链接 gcc 指向 /usr/bin/gcc
/usr/bin/gcc-11 - 优先级 1
/usr/bin/gcc-7 - 优先级 9
g++ - 自动模式
最佳链接版本为 /usr/bin/g++-7
链接目前指向 /usr/bin/g++-7
链接 g++ 指向 /usr/bin/g++
/usr/bin/g++-11 - 优先级 1
/usr/bin/g++-7 - 优先级 9
将gcc-7和g++-7的版本优先级提高。
在安装完cuda后可将版本优先级重新升为gcc-11和g++-11,避免后续一些驱动版本更新编译出错!
1.1.3 下载cuda
cuda官网:CUDA Toolkit Archive | NVIDIA Developer


由于官网上最大的版本为20.04,可以找对应的版本,但因为我们已经安装的Ubuntu22.04就选最大的。用runfile安装会简洁一点,只需要两个命令:
wget https://developer.download.nvidia.com/compute/cuda/11.3.0/local_installers/cuda_11.3.0_465.19.01_linux.run
sudo sh cuda_11.3.0_465.19.01_linux.runwget是下载命令
sh是执行脚本命令
如果用官网下载太慢的话,可以直接在浏览器复制网页,然后通过自己的下载器进行下载后再传输cuda_11.3.0_465.19.01_linux.run到所用的服务器上。
运行指令后,出现以下界面选择continue

然后输出accept

在选择时一定要注意把Driver取消

1.1.4 环境变量设置
若环境未配置好,后续程序会找不到cuda
首先用vim查看环境配置文件
vim ~/.bashrc在最后添加如下几行(注意请根据实际情况修改,你可以查看/usr/loacl目录下cuda的文件名是什么)
export PATH="/usr/local/cuda-11.3/bin${PATH:+:${PATH}}"
export LD_LIBRARY_PATH="/usr/local/cuda-11.3/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}"
export CUDA_HOME="/usr/local/cuda-11.3"
![]()
刷新环境变量
source ~/.bashrc可以通过nvcc -V来查看cuda版本

1.1.5 安装cudnn
cudnn的安装比较简单,只需要下载对应版本的安装包,拷贝文件到指定目录,给予权限即可
CUDNN官网:https://developer.nvidia.com/cudnn



下载后会得到cudnn-11.3-linux-x64-v8.2.1.32.tgz的文件,将其转置要搭载的环境内进行解压
tar -zxvf cudnn-11.3-linux-x64-v8.2.1.32.tgz然后拷贝文件+授予权限
sudo cp cuda/include/cudnn* /usr/local/cuda-11.3/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda-11.3/lib64
sudo chmod a+r /usr/local/cuda-11.3/include/cudnn*
sudo chmod a+r /usr/local/cuda-11.3/lib64/libcudnn*
查看cudnn版本:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2执行该指令可能没有结果,因为新版本可能更改了位置,可以用:
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
查看到版本为cudnn8.2.1即为安装完成
1.2 OpenPCdet代码下载
OpenPCdet官网:https://github.com/open-mmlab/OpenPCDet
运用 git clone 命令将代码下载:
git clone https://github.com/open-mmlab/OpenPCDet1.3 环境创建
1.3.1 安装Anaconda
在清华镜像下载Linux版本的anaconda
Anaconda清华镜像:https://repo.anaconda.com/archive/
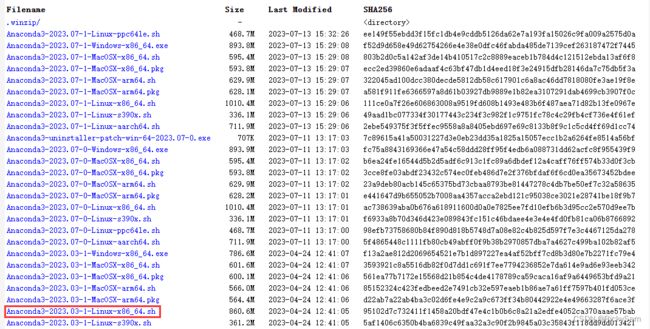
可以根据自己的需求选择版本,我选择的是Anaconda3-2023.03-1-Linux-x86_64.sh下载好后同样转移至自己所用的环境内。
运行如下指令:
bash Anaconda3-2022.10-Linux-x86_64.sh
根据安装提示,一路输入yes和回车即可,其中出现安装位置提示,若不需要更改则回车选择默认的安装目录(默认在用户主目录下创建一个名为anaconda3的文件夹作为安装地址)。
1.3.2 创建conda环境
conda create -n open python=3.8
conda activate open1.3.3 运行安装包(除开torch)
用记事本打开requirements.txt将其中的torch删除,剩余如图

然后再运行:
pip install -r requirements.txt
1.3.3 安装torch
pip install torch==1.11.0+cu113 torchvision==0.12.0+cu113 torchaudio==0.11.0 --extra-index-url https://download.pytorch.org/whl/cu1131.3.4 安装稀疏卷积库
pip install spconv-cu113
稀疏卷积库官网:https://github.com/traveller59/spconv
1.3.5 安装相关工具包
cmake安装
pip install cmake可视化工具mayavi
pip install vtk
pip install mayavi
python
import mayavi
在python里查看mayavi是否安装完成

av2 及 kornia 安装
pip install av2==0.2.1
pip install kornia==0.6.121.3.6 运行编译项目
cd到OpenPCDet文件下来运行编译
cd OpenPCDet
python setup.py develop2.训练数据
2.1 KITTI数据集
2.1.1 KITTI数据集下载
以下内容参考OpenPCDet官网数据集介绍
请下载官方KITTI 3D目标检测数据集,下载的文件整理如下(公路飞机可以从【公路飞机】下载,训练中数据增强可选):如果您想训练 CaDDN,请下载 KITTI 训练集的预先计算的。
#注意:如果您已经拥有来自 的数据信息,则可以选择使用旧信息,并将tools/cfgs/dataset_configs/kitti_dataset.yaml 中的DATABASE_WITH_FAKELIDAR选项设置为 True。第二种选择是您可以再次创建信息和 gt 数据库并保持配置不变。pcdet v0.1
并将下载好的数据集整理成如下形式:
OpenPCDet
├── data
│ ├── kitti
│ │ │── ImageSets
│ │ │── training
│ │ │ ├──calib & velodyne & label_2 & image_2 & (optional: planes) & (optional: depth_2)
│ │ │── testing
│ │ │ ├──calib & velodyne & image_2
├── pcdet
├── tools2.1.2数据处理
准备数据(数据格式如下图)和生成数据的一些信息
python -m pcdet.datasets.kitti.kitti_dataset create_kitti_infos tools/cfgs/dataset_configs/kitti_dataset.yaml
训练完成后显示为:

然后就可以训练模型了
cd tools/
python train.py --cfg_file ./cfgs/kitti_models/pointpillar_pyramid_aug.yaml --batch_size 4 --epochs 50
batch_size可以根据自己服务器的GPU来进行调整。
最后训练完

训练结束后我们可以用demo看一下效果:
python demo.py --cfg_file ./cfgs/kitti_models/pointpillar_pyramid_aug.yaml --ckpt /home/用户名称/OpenPCDet/output/cfgs/kitti_models/pointpillar_pyramid_aug/default/ckpt/checkpoint_epoch_50.pth --data_path /home/用户名称/OpenPCDet/data/kitti/testing/velodyne/000010.bin
注意要根据自己的路径进行修改哦!

可视化结果如图
2.2 Nuscenes数据集
2.2.1 Nuscenes数据集下载
以下内容参考OpenPCDet官网数据集介绍
首先下载nusences数据集,根据自己服务器端的硬盘空间大小,可以先用v1.0-mini版的nuscenes数据集进行测试下载的时候要注册并登录。
也可以从全网首发 nuScenes数据集(百度网盘 + 迅雷网盘) + 下载方法中从百度云下载再传输到服务器上。
并将下载好的数据集整理成如下形式:
OpenPCDet
├── data
│ ├── nuscenes
│ │ │── v1.0-trainval (or v1.0-mini if you use mini)
│ │ │ │── samples
│ │ │ │── sweeps
│ │ │ │── maps
│ │ │ │── v1.0-trainval
├── pcdet
├── tools如果用的是v1.0-mini版 则为
OpenPCDet
├── data
│ ├── nuscenes
│ │ │── v1.0-mini
│ │ │ │── samples
│ │ │ │── sweeps
│ │ │ │── maps
│ │ │ │── v1.0-mini
├── pcdet
├── tools通过运行以下命令安装 with 版本:nuscenes-devkit1.0.5
pip install nuscenes-devkit==1.0.52.2.2 数据处理
通过运行以下命令生成数据信息(可能需要几个小时):
# for lidar-only setting
python -m pcdet.datasets.nuscenes.nuscenes_dataset --func create_nuscenes_infos \
--cfg_file tools/cfgs/dataset_configs/nuscenes_dataset.yaml \
--version v1.0-trainval
# for multi-modal setting
python -m pcdet.datasets.nuscenes.nuscenes_dataset --func create_nuscenes_infos \
--cfg_file tools/cfgs/dataset_configs/nuscenes_dataset.yaml \
--version v1.0-trainval \
--with_cam
v1.0-trainval完成后如图

以v1.0-mini版为例
处理v1.0-mini:
python -m pcdet.datasets.nuscenes.nuscenes_dataset --func create_nuscenes_infos \
--cfg_file tools/cfgs/dataset_configs/nuscenes_dataset.yaml \
--version v1.0-mini
v1.0-mini完成后如图:
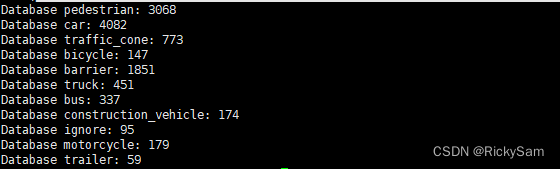
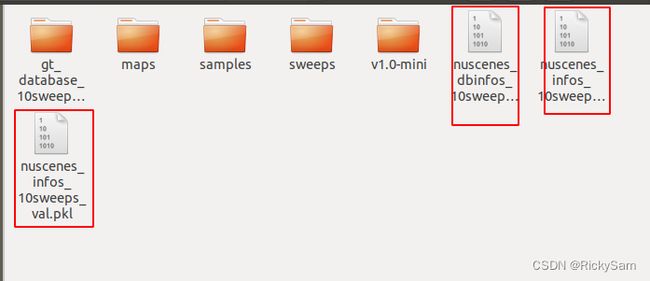
将会生成三个pkl文件:
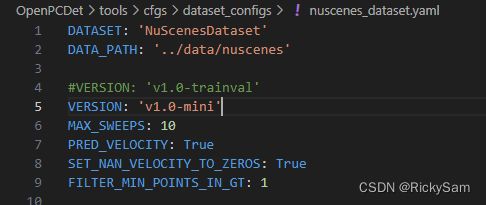
然后我们修改下nuscenes_dataset.yaml里面的一个配置,在nuscenes_dataset.yaml里面第四行将VERSION:‘v1.0-trainval’改为VERSION:‘v1.0-mini’
然后就可以输入命令进行训练了(batch-size根据自己显卡的显存进行设定,若为8G则设置为2)
cd tool/
python train.py --cfg_file ./cfgs/nuscenes_models/cbgs_pp_multihead.yaml --batch_size 2 --epochs 160
若为多GPU训练则:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 train.py --cfg_file ./cfgs/nuscenes_models/cbgs_pp_multihead.yaml --launcher pytorch --batch_size 2 --epochs 160
其中:
CUDA_VISIBLE_DEVICES:选择GPU
torch.distributed.launch:表明利用该工具进行分布式训练
nproc_per_node:每个物理节点(机器)上有多少GPU。如果是单机器,就是你所用GPU的数量。
cfg_file:配置文件,在OpenPCDet/tools/cfgs下。
--launcher pytorch:表明使用PyTorch架构
训练开始如下图

v1.0-mini训练完成后如下图

v1.0-trainval训练完成后如下图

之后我们就可以进行可视化了!
在可视化之前,如果是运用pcdet里的demo.py 则需要修改一下,找到__getitem__ 将reshape(-1,4)改为reshape(-1,5)
def __getitem__(self, index):
if self.ext == '.bin':
#针对kitti数据集,需要reshape(-1,4)
# points = np.fromfile(self.sample_file_list[index],dtype=np.float32).reshape(-1,4)
#针对nuscenes数据集,需要reshape(-1,5)
points = np.fromfile(self.sample_file_list[index],dtype=np.float32).reshape(-1,5)
elif self.ext == '.npy':
points = np.load(self.sample_file_list[index])
else:
raise NotImplementedError然后我们可以用demo看一下效果:
python demo_nu.py --cfg_file ./cfgs/nuscenes_models/cbgs_pp_multihead.yaml --ckpt /home/用户/OpenPCDet/output/cfgs/nuscenes_models/cbgs_pp_multihead/default/ckpt/checkpoint_epoch_160.pth --data_path /home/用户名称/OpenPCDet/data/nuscenes/v1.0-mini/sweeps/LIDAR_TOP/n008-2018-08-01-15-16-36-0400__LIDAR_TOP__1533151603597909.pcd.bin

问题汇总
1.出现 subprocess.CalledProcessError: Command ‘[‘ninja‘, ‘--version‘]‘ returned non-zero exit status 1
(或 subprocess.CalledProcessError: Command ‘[‘ninja‘, ‘-v‘]‘returned non-zero exit status 1)
在对应的setup.py文件下找到
cmdclass={'build_ext': BuildExtension}将其改为
cmdclass={'build_ext': BuildExtension.with_options(use_ninja=False)}以此来让pytorch禁用ninja。
最后重新再运行
python setup.py install2.安装过程中报错:fatal error: THC/THC.h: No such file or directory
主要是pytorch版本太高导致,可将版本降低至1.11以下,或者更改./OpenPCDet/pcdet/ops/pointnet2/pointnet2_batch/src和./OpenPCDet/pcdet/ops/pointnet2/pointnet2_stack/src文件夹下的几个cpp文件
//#include
...
//extern THCState *state
将这两行注释掉之后重新编译
3. 生成pkl文件出现
dataset_cfg = EasyDict(yaml.load(open(args.cfg_file)))
TypeError: load() missing 1 required positional argument: 'Loader'
报错原因
yaml 5.1版本后不再使用yaml.load(file),而是是使用yaml.load(file,Loader = yaml.FullLoader)
将dataset_cfg = EasyDict(yaml.load(open(args.cfg_file)))改为
dataset_cfg = EasyDict(yaml.load(open(args.cfg_file),Loader = yaml.FullLoader))
4.如果在训练trian.py文件时出现
AttributeError: module 'numpy' has no attribute 'bool'.
`np.bool` was a deprecated alias for the builtin `bool`. To avoid this error in existing code, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here.根据提示在相关的代码行内将'np.bool'改为'np.bool_'即可

AttributeError: module 'numpy' has no attribute 'int'.
`np.int` was a deprecated alias for the builtin `int`. To avoid this error in existing code, use `int` by itself. 将提示的文件名下中的'np.int'改为'int'即可
File "/home/用户称/OpenPCDet/tools/../pcdet/models/backbones_2d/base_bev_backbone.py", line 60, in __init__
stride = np.round(1 / stride).astype(np.int)
改为:
stride = np.round(1 / stride).astype(int)
5.AttributeError: module 'spconv' has no attribute 'SparseModule'
找到相关的错误提示文件,将
将import spconv 改写成
import spconv.pytorch as spconv
6. import SharedArray
ModuleNotFoundError: No module named 'SharedArray'
看自己是否已经进入自己的conda虚拟环境,或者因为numpy版本问题,会导致找不到‘’SharedArray'
7.使用如下命令监控GPU使用情况时, 报错:
/bin/sh: 1: gpustat: not found
gpustat 是 python的一个包, 只需要使用 pip install 即可
pip install gpustat!!! 如若安装完后有如下警告:
Installing collected packages: nvidia-ml-py3, blessings, gpustat
WARNING: The script gpustat is installed in '/home/zhangsan/.local/bin' which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.
Successfully installed blessings-1.7 gpustat-0.6.0 nvidia-ml-py3-7.352.0则需要将 gpustat 安装路径添加至环境变量中, 添加
1. 添加如下内容至 /home/用户名称/.bashrc 用户环境变量中
export PATH="/home/用户名称/.local/bin/:$PATH"
2. 使用 source .bashrc 激活配置注意!若NVIDIA驱动需要更新到最新版本,由于之间将gcc和g++版本降为了7,所以需要反向使用最开始的操作重新将gcc-11和g++-11的优先级设为9后再进行更新!
参考博客:
Ubuntu20.04安装CUDA和CUDNN
ubuntu 18.04 从零开始复现 OpenPCDet 训练kitti数据集并评估 可视化 损失函数
OpenPCDet复现过程记录
ubuntu 18.04 从零开始复现 OpenPCDet 训练nuSences数据集并评估 可视化 损失函数