Linux系统Shell脚本 文件三剑客-------------awk
一、awk简介
- AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。
- 之所以叫 AWK 是因为其取了三位创始人
Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name的首字符。
awk:Aho, Weinberger, Kernighan,报告生成器,格式化文本输出,GNU/Linux发布的AWK目前由自由软件基金会(FSF)进行开发和维护,通常也称它为 GNU AWK
有多种版本:
-
AWK:原先来源于 AT & T 实验室的的AWK
-
NAWK:New awk,AT & T 实验室的AWK的升级版
-
GAWK:即GNU AWK。所有的GNU/Linux发布版都自带GAWK,它与AWK和NAWK完全兼容
二、awk工作原理
awk 比较倾向于将一行分成多个“字段”然后再进行处理,且默认情况下字段的分隔符为空格或 tab 键。awk 执行结果可以通过 print 的功能将字段数据打印显示。
awk为流编辑器,即读取文件一行处理一行。
三、awk基本格式
格式:
awk [options] 'program' var=value file…说明:
program通常是被放在单引号中,并可以由三种部分组成
-
BEGIN语句块
-
模式匹配的通用语句块
-
END语句块
常见选项:
-
-F “分隔符” 指明输入时用到的字段分隔符,默认的分隔符是若干个连续空白符
-
-v 变量赋值
awk [选项] '处理模式{处理动作}' '{ }'为固定格式 处理动作print:打印
选项若不写默认为以空格为分隔符处理,且会将空格自动压缩。
四、awk基础用法


awk '{print "hello"}'

awk可以支持标准输入、标准输出、还有后面写文件
awk '{print "hello"}' < /etc/passwd


实验:提取df已用%这一列

方法一:
df |awk '{print$5}'|tail -n +2|tr -d %

方法二:
df |awk -F "[ %]+" '{print $5}'|tail -n +2

方法三:
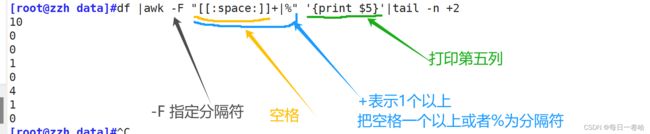
实验2:
输出 /etc/passwd文件中以 ":" 分隔的第一列和第三字段
awk -F: '{print $1,$3}' /etc/passwd


输出内容可以修改,使用 : 或者+++ 等分隔开都可以
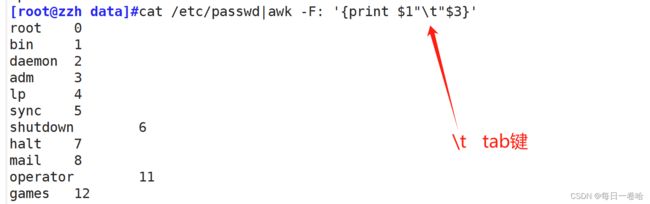
用 : 分隔开


cat /etc/passwd|awk -F: '{print $1"\t"$3}'
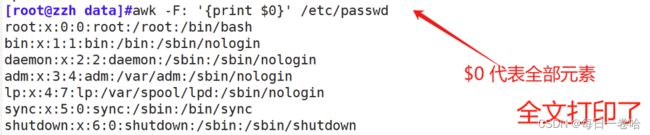
$0代表全部元素
'{print $1}' 即为打印第一列
'{print $n}'即打印为第n列,'{print $n,$m}'即为打印第n列和第m列

awk '/^root/{print}' passwd

实验:提取ip地址
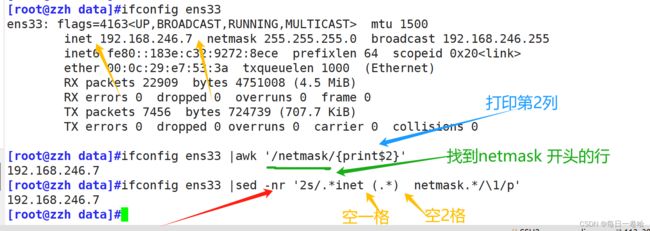
[root@zzh data]#ifconfig ens33
ens33: flags=4163 mtu 1500
inet 192.168.246.7 netmask 255.255.255.0 broadcast 192.168.246.255
inet6 fe80::183e:c32:9272:8ece prefixlen 64 scopeid 0x20
ether 00:0c:29:e7:53:3a txqueuelen 1000 (Ethernet)
RX packets 22909 bytes 4751008 (4.5 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 7456 bytes 724739 (707.7 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@zzh data]#ifconfig ens33 |awk '/netmask/{print$2}'
192.168.246.7
[root@zzh data]#ifconfig ens33 |sed -nr '2s/.*inet (.*) netmask.*/\1/p'
192.168.246.7
[root@zzh data]# 五、awk 常见的内置变量
awk 选项 '模式{print }'
-
FS :列分割符,指定每行文本的字段分隔符,缺省默认为空格或制表符(tab)
-
OFS:输出时的分隔符
-
NF:当前处理的行的字段个数
-
NR:当前处理的行的行号(序数)
-
$0:当前处理的行的整行内容
-
$n:当前处理行的第n个字段(第n列)
-
FILENAME:被处理的文件名
-
RS:行分隔符。awk从文件上读取资料时,将根据RS的定义就把资料切割成许多条记录,而awk一次仅读入一条记录进行处理。预设值是\n
-F “分隔符” 指明输入时用到的字段分隔符,默认的分隔符是若干个连续空白符


FS :列分割符,指定每行文本的字段分隔符,缺省默认为空格或制表符(tab)


shell中的变量


OFS 输出时的分隔符
awk -v FS=':' -v OFS='==' '{print $1,$3}' /etc/passwd
RS 行分隔符 ,换行
默认是以 /n(换行符)为一条记录的分隔符

NF 代表字段的个数

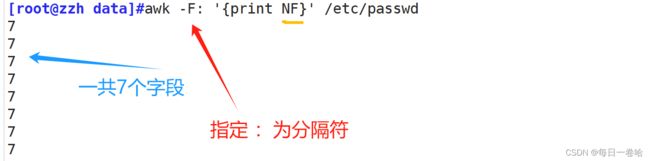
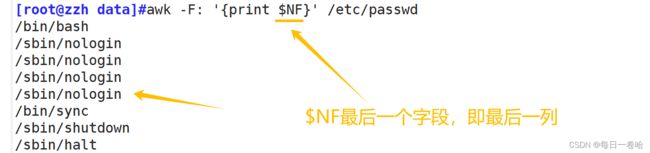
实验:提取df已用%这一列
df |awk '{print $(NF-1)}'
df|awk -F "[ %]+" '{print $(NF-1)}'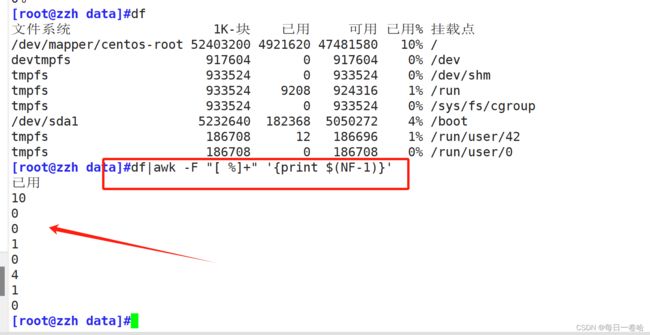
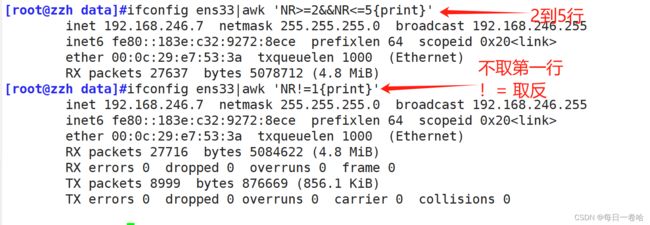
NR:当前处理的行的行号(序数)

NR——筛选ip地址行

[root@zzh data]#ifconfig ens33|awk 'NR==2'
inet 192.168.246.7 netmask 255.255.255.0 broadcast 192.168.246.255
[root@zzh data]#ifconfig ens33|awk 'NR==2{print $0}'
inet 192.168.246.7 netmask 255.255.255.0 broadcast 192.168.246.255
[root@zzh data]#ifconfig ens33|awk 'NR==2{print}'
inet 192.168.246.7 netmask 255.255.255.0 broadcast 192.168.246.255
[root@zzh data]#ifconfig ens33|awk 'NR>=2&&NR<=5{print}'
inet 192.168.246.7 netmask 255.255.255.0 broadcast 192.168.246.255
inet6 fe80::183e:c32:9272:8ece prefixlen 64 scopeid 0x20
ether 00:0c:29:e7:53:3a txqueuelen 1000 (Ethernet)
RX packets 27637 bytes 5078712 (4.8 MiB)
[root@zzh data]#ifconfig ens33|awk 'NR!=1{print}'
inet 192.168.246.7 netmask 255.255.255.0 broadcast 192.168.246.255
inet6 fe80::183e:c32:9272:8ece prefixlen 64 scopeid 0x20
ether 00:0c:29:e7:53:3a txqueuelen 1000 (Ethernet)
RX packets 27716 bytes 5084622 (4.8 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 8999 bytes 876669 (856.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
面试题:
打印出普通用户

找出当前文件中uid最大的用户名


[root@zzh data]#awk -F: '$3>=1000{print $1,$3}' /etc/passwd
nfsnobody 65534
zz 1000
[root@zzh data]#awk -F: '$3>=1000{print $1,$3}' /etc/passwd|sort -n
nfsnobody 65534
zz 1000
[root@zzh data]#cat /etc/passwd |sort -t: -k3 -n |tail -n1
nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin
[root@zzh data]#FNR——查看多个文件各有多少行

FILENAME 显示处理的文件名

六、自定义变量
[root@localhost ~]#awk -v test='hello' 'BEGIN{print test}'
hello
awk -v test1=test2="hello" 'BEGIN{test1=test2="hello";print test1,test2}'
awk -v test='hello gawk' '{print test}' /etc/fstab
awk -v test='hello gawk' 'BEGIN{print test}'
awk 'BEGIN{test="hello,gawk";print test}'
awk -F: '{sex="male";print $1,sex,age;age=18}' /etc/passwd七、printf
printf
%s:显示字符串
%d, %i:显示十进制整数
%f:显示为浮点数
%e, %E:显示科学计数法数值
%c:显示字符的ASCII码
%g, %G:以科学计数法或浮点形式显示数值
%u:无符号整数
%%:显示%自身
awk -F: '{printf "%s",$1}' /etc/passwd
awk -F: '{printf "%s\n",$1}' /etc/passwd
awk -F: '{printf "%20s\n",$1}' /etc/passwd
awk -F: '{printf "%-20s\n",$1}' /etc/passwd
awk -F: '{printf "%-20s %10d\n",$1,$3}' /etc/passwd
awk -F: '{printf "Username: %s\n",$1}' /etc/passwd
awk -F: '{printf “Username: %sUID:%d\n",$1,$3}' /etc/passwd
awk -F: '{printf "Username: %25sUID:%d\n",$1,$3}' /etc/passwd
awk -F: '{printf "Username: %-25sUID:%d\n",$1,$3}' /etc/passwd
awk -F: 'BEGIN{printf "--------------------------------\n%-20s|%10s|\n--------------------------------\n","username","uid"}{printf "%-20s|%10d|\n--------------------------------\n",$1,$3}' /etc/passwd
八、模式PATTERN
awk ' 模式 {处理动作} '
PATTERN:根据pattern条件,过滤匹配的行,再做处理
1.模式为空
如果模式为空表示每一行都匹配成功,相当于没有额外条件

2.正则匹配
正则匹配:与正则表达式配合使用。
/regular expression/:仅处理能够模式匹配到的行,需要用/ /括起来
3. line ranges:行范围
不支持使用行号,但是可以使用变量NR 间接指定行号加上比较操作符 或者逻辑关系
算术操作符
x+y, x-y, x*y, x/y, x^y, x%y
-x:转换为负数
+x:将字符串转换为数值
比较操作符:
==, !=, >, >=, <, <=
逻辑关系
与:&&,并且关系
或:||,或者关系
非:!,取反
面试题:
找到10:00到11:00的日志 大概写一下
通过awk找 awk '/10/,/11/' 文件名
通过sed找 sed -nr '/10/,/11/p' 文件名
4 BEGIN END
BEGIN{}:仅在开始处理文件中的文本之前执行一次
END{}:仅在文本处理完成之后执行一次
BEGIN{ }模式表示,在处理指定的文本前,需要先执行BEGIN模式中的指定动作; awk再处理指定的文本,之后再执行END模式中的指定动作,END{ }语句中,一般会放入打印结果等语句
实验:
END{}:仅在文本处理完成之后执行一次

BEGIN{}:仅在开始处理文件中的文本之前执行一次

5 关系表达式
关系表达式结果为“真”才会被处理
真:结果为非0值,非空字符串
假:结果为空字符串或0值

[root@zzh data]#seq 10 |awk 'n++'
2
3
4
5
6
7
8
9
10
[root@zzh data]#seq 10 |awk '!n++'
1
[root@zzh data]#
[root@zzh data]#seq 10 |awk '!0'
1
2
3
4
5
6
7
8
9
10
seq 10 |awk 'i=!i' 奇数行
seq 10 |awk -v i=1 'i=!i' 偶数行
seq 10 |awk '!(i=!i)' 偶数行


6.条件判断
awk 选项 '模式 {actions}'
条件判断写在 actions里
格式:
if语句:awk的if语句也分为单分支、双分支和多分支
单分支为if(判断条件){执行语句}
双分支为if(判断条件){执行语句}else{执行语句}
多分支为if(判断条件){执行语句}else if(判断条件){执行语句}else if(判断条件){执行语句}else if(判断条件){执行语句}

awk -F: '{if($3>1000){print $1,$3}else{print $3}}' /etc/passwd条件判断的格式为: '{if(条件判断){命令序列1}else{命令序列2}}'
7. 循环 for | while
awk求1到100的和

awk还支持for循环、while循环、函数、数组等
8.数组
1.awk数组特性:
-
awk的数组是关联数组(即key/value方式的hash数据结构),索引下标可为数值(甚至是负数、小数等),也可为字符串
-
在内部,awk数组的索引全都是字符串,即使是数值索引在使用时内部也会转换成字符串
-
awk的数组元素的顺序和元素插入时的顺序很可能是不相同的
-
awk数组支持数组的数组
2.访问、赋值数组元素
索引可以是整数、负数、0、小数、字符串。如果是数值索引,会按照CONVFMT变量指定的格式先转换成字符串
[root@localhost ~]#awk 'BEGIN{a[1]="people";print a[1]}'
people
[root@localhost ~]#awk 'BEGIN{weekdays["mon"]="Monday";weekdays["tue"]="Tuesday";print weekdays["mon"]}'
Monday

下回分析