pytorch gpu推理、onnxruntime gpu推理、tensorrt gpu推理比较,及安装教程,有详细代码解释
需要下载的测试用的文件
测试图片:
https://upload.wikimedia.org/wikipedia/commons/2/26/YellowLabradorLooking_new.jpg -O dog.jpg
类别文件:
https://raw.githubusercontent.com/Lasagne/Recipes/master/examples/resnet50/imagenet_classes.txt
打包好的也可在这下载:
https://download.csdn.net/download/m0_59156726/88478676
1. pytorch 推理
模型直接使用torchvison里面自带的resnet50,
torchvison 参考 使用PyTorch中的预训练模型进行图像分类
直接看代码就可以了,简单明了。
import time
from torchvision import models, transforms
import torch
from PIL import Image
# 使用resnet50, torchvision 0.13及以后的新版本写法
resnet = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V1)
# 加载类别
with open('imagenet_class/imagenet_class.txt') as f:
classes = [line.strip() for line in f.readlines()]
device = torch.device("cuda:0")
# 加载到gpu
resnet.to(device)
# 推理模式
resnet.eval()
# 图像预处理
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])
# 加载图片
img = Image.open("./imagenet_class/YellowLabradorLooking_new.jpg")
# 处理图片
img_t = transform(img)
# 加载到gpu
img_t = img_t.unsqueeze(0).to(device)
# 循环推理看耗时
for i in range(10):
# infer, size(1,1000)
t1 = time.time()
out = resnet(img_t)
t2 = time.time()
print("time:", t2 - t1)
# size(1,1000)
out_sorted, indices = torch.sort(out, descending=True)
percentage = torch.nn.functional.softmax(out, dim=1)[0] * 100
# 前top5
top5_list = [(classes[idx], percentage[idx].item()) for idx in indices[0][:5]]
# 打印结果及gpu推理时间
print(top5_list)
结果:首次推理时间比较长,后面时间平均10ms,top1概率52.3%,能正确识别类别

2. onnxruntime gpu推理
2.1 环境准备
所有的nv gpu推理都需要使用到cuda cudnn
默认python已安装pytorch gpu版本,因为安装pytorch gpu环境的时候肯定选择cuda和cudnn的安装,如果你没安装,自己找一下安装的攻略,也就一行代码的事情,下面是官方提供的pytorch cuda11.8安装指令,参考:https://pytorch.org/
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
一般安装了pytorch,都会安装cuda和cudnn,查看一下版本即可
print(torch.version)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
然后根据cuda版本下载安装适配的onnxruntime版本
pip install onnxruntime-gpu==xx.xx.xx
不出意外直接 pip install onnxruntime-gpu即可
2.2 模型转换
仍然拿resnet50举例
import time
from torchvision import models, transforms
import torch
from PIL import Image
# 使用resnet50, torchvision 0.13及以后的新版本写法
resnet_ = models.resnet50(weights=models.ResNet50_Weights.IMAGENET1K_V1)
# 模型转换, 详细参数请自行查阅
input_shape = (1,3,224,224)
dummy_input = torch.randn(input_shape)
torch.onnx.export(resnet, dummy_input, "resnet50.onnx", verbose=True, opset_version=11, input_names=["input0"], output_names=["output0"])
2.3 onnxruntime 推理
with open('imagenet_class/imagenet_class.txt') as f:
classes = [line.strip() for line in f.readlines()]
import onnxruntime as ort
# 构建providers
providers = [
('CUDAExecutionProvider', {
'device_id': 0,
'arena_extend_strategy': 'kNextPowerOfTwo',
'gpu_mem_limit': 2 * 1024 * 1024 * 1024,
'cudnn_conv_algo_search': 'EXHAUSTIVE',
'do_copy_in_default_stream': True,
}),
'CPUExecutionProvider',
]
# 加载模型
ort_session = ort.InferenceSession("resnet50.onnx", providers=providers)
# 图像预处理
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])
# 加载图片
img = Image.open("./imagenet_class/YellowLabradorLooking_new.jpg")
# 处理图片
img_t = transform(img)
img_numpy = img_t.numpy()[None,:]
for i in range(10):
t1 = time.time()
input_name = ort_session.get_inputs()[0].name
# size(1,1000)
out = ort_session.run(None, {input_name: img_numpy})[0]
t2 = time.time()
print("time:", t2 - t1)
# size(1,1000) 降序
out = torch.from_numpy(out)
out_sorted, indices = torch.sort(out, descending=True)
percentage = torch.nn.functional.softmax(out, dim=1)[0] * 100
# 前top5
top5_list = [(classes[idx], percentage[idx].item()) for idx in indices[0][:5]]
# 打印结果及gpu推理时间
print(top5_list)
结果:首次推理时间比较长,后面时间平均4ms左右,top1概率52.3%,能正确识别类别。类别识别精度跟pytorch没差,时间比pytorch快了6ms,还是比较快的
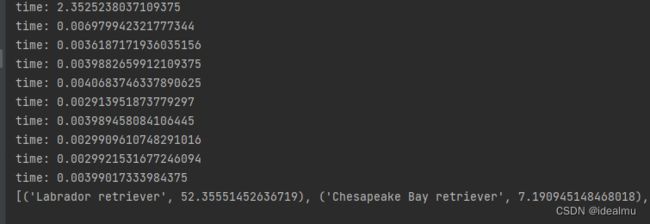
3. tensorrt 推理
3.1 安装准备
根据cuda对应版本下载tensorrt
https://developer.nvidia.com/nvidia-tensorrt-8x-download
详细安装教程参考,可以不用看,看下面的即可
https://blog.csdn.net/hjxu2016/article/details/122868139
我下载的是这个,因为我用的是cuda11.8版本

下载解压之后,把lib目录配置到环境变量中,以便程序能找到dll。

pip 安装
找到安装包解压后python的目录,可以看到里面有很多,具体解释
https://docs.nvidia.com/deeplearning/tensorrt/release-notes/index.html


接下来到该目录根据python版本直接安装:
pip install tensorrt-8.6.1-cp38-none-win_amd64.whl
显示成功后,检查安装是否正确
import tensorrt as trt
报错:提示找不到dll,可以博主已经配置了环境变量了啊,原因是因为博主配置环境变量后没有重开IDE,导致IDE没有加载新的环境变量。那就重开一下pycharm,没有报错,安装成功。

3.2 onnx 转tensorrt 模型
使用安装包里面的工具转换, 其他方法自行百度,为了方便也把这个目录加到环境变量中去。

执行一下命令转换, 这里给一个使用参考https://blog.csdn.net/qq_43673118/article/details/123547503,包括一下常用参数。特别说明一下默认精度是fp32
trtexec --onnx=resnet50.onnx --saveEngine=resnet_engine.trt
3.3 tensorrt 推理
官方的推理参考,这里面的API有些老的,会有告警
https://github.com/NVIDIA/TensorRT/blob/main/quickstart/SemanticSegmentation/tutorial-runtime.ipynb
要用到cuda driver 安装一下
pip install pycuda
写一下自己的推理
API参考:
https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/infer/Core/Engine.html
import numpy as np
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import time
# 加载tensort 构建runtime
def load_engine(engine_file_path):
with open(engine_file_path, "rb") as f, trt.Runtime(trt.Logger(trt.Logger.WARNING)) as runtime:
return runtime.deserialize_cuda_engine(f.read())
# 图片预处理
def preprocess(input_file):
# 图像预处理
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
])
# 加载图片
img = Image.open(input_file)
# 处理图片
img_t = transform(img)
# NCHW (1,3,244,244)
return img_t.numpy()[None,:]
def infer(engine, input_file):
input_image = preprocess(input_file)
t1 = time.time()
with engine.create_execution_context() as context:
# 根据输入设置输入的size, 因为只有一个输入,因此只需设置一个即可。这里可以不用设置,
# 由于我们onnx转换的不是动态shape,而是固定1,3,224,224。所以获得的shape必定是(1,3,224,224)这里只是展示set的用法
# input0_shape = context.get_tensor_shape("input0")
# 老API context.set_binding_shape(engine.get_binding_index("input"), img.size())
context.set_input_shape("input0", input_image.shape)
# Allocate host and device buffers, 分配内存 cpu gpu 内存
bindings = []
# 遍历输入输出
for binding in engine:
# binding_idx = engine.get_binding_index(binding)
size = trt.volume(context.get_tensor_shape(binding)) # 1 * 3 * 224 * 224
dtype = trt.nptype(engine.get_tensor_dtype(binding)) # 1 * 3 * 224 * 224
# 老API engine.binding_is_input(binding)
if engine.get_tensor_mode(binding) == trt.TensorIOMode.INPUT:
input_buffer = np.ascontiguousarray(input_image)
input_memory = cuda.mem_alloc(input_image.nbytes)
bindings.append(int(input_memory))
else:
output_buffer = cuda.pagelocked_empty(size, dtype)
output_memory = cuda.mem_alloc(output_buffer.nbytes)
bindings.append(int(output_memory))
# stream
stream = cuda.Stream()
# Transfer input data from CPU to the GPU.
cuda.memcpy_htod_async(input_memory, input_buffer, stream)
# Run inference
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
# Transfer prediction output from GPU to CPU.
cuda.memcpy_dtoh_async(output_buffer, output_memory, stream)
# Synchronize the stream
stream.synchronize()
t2 = time.time()
# 打印top5推理结果
with open('imagenet_class/imagenet_class.txt') as f:
classes = [line.strip() for line in f.readlines()]
out = torch.from_numpy(output_buffer)
out_sorted, indices = torch.sort(out, descending=True)
percentage = torch.nn.functional.softmax(out, dim=0) * 100
# 前top5
top5_list = [(classes[idx], percentage[idx].item()) for idx in indices[:5]]
# 打印结果及gpu推理时间
print("time: ", t2 - t1)
print(top5_list)
def run():
engine_file_path = "resnet_engine.trt"
input_file = "./imagenet_class/YellowLabradorLooking_new.jpg"
class_txt = "./imagenet_class/imagenet_class.txt"
engine = load_engine(engine_file_path)
for i in range(10):
infer(engine, input_file)
run()
结果比onnx差不多,看来tensorrt还是有优势的,这只是一个小模型,想必在其他模型上更有优势
