手写数字生成——基于pytorch对抗生成网络GAN
手写数字生成——基于pytorch对抗生成网络GAN
- 1.任务目的
- 2.导包
- 3.下载数据集
- 4.网络组成
-
- 1.生成器
- 2.判别器
- 3.损失函数BCEloss
- 5.参数设定
- 6.训练模型
- 7.查看效果
1.任务目的
基于minist数据集,通过对抗生成网络,由AI自动生成手写数字图片。
2.导包
import torch
import torch.nn as nn
import numpy as np
import os
from torch.utils.data import DataLoader
from torchvision import datasets
import torchvision.transforms as transforms
from torchvision.utils import save_image
3.下载数据集
#载入minist数据集
os.makedirs("./data/mnist", exist_ok=True)
batch_size=128
#构建迭代器,每次可从minist训练集中随机拿出128张处理后的图片,返回值其图像和标签
dataloader = DataLoader(
datasets.MNIST(
"./data/mnist",train=True, download=True,
transform=transforms.Compose(
[transforms.Resize(28,28),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5],std= [0.5])])),
batch_size=batch_size,shuffle=True)
4.网络组成
1.生成器
#使随机生成的一批向量,经过一系列处理后转化成一批标准形状的图像张量
#本实验随机生成的向量形状为[batch_size,100],标准图像形状为[1,28,28]
latent_dim=100
img_shape=(1,28,28)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat):
layers = [nn.Linear(in_feat, out_feat)]
#对2D或者3D输入用BatchNorm1d
# (a mini-batch of 1D inputs with optional additional channel dimension)
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(latent_dim, 128),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
#int(np.prod(img_shape)为img三个尺度的乘积,即1*28*28=784
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
#z形状为[batch_size,100]
imgs= self.model(z)
#imgs形状为[batch_size,1*28*28]
gen_imgs = imgs.view(imgs.size(0), *img_shape)
#gen_imgs形状为[batch_size,1,28,28]
return gen_imgs
2.判别器
#判别器
#将输入图片经过转化后变成二分类结果为1的概率值
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
#sigmoid函数将输出转换为二分类结果为1的概率值
nn.Sigmoid(),
)
def forward(self, img):
#img形状为[batch_size,1,28,28]
img_flat = img.view(img.size(0), -1)
#img_falt形状为[batch_size,1*28*28]
validity = self.model(img_flat)
#validity形状为[batch_size,1]
return validity
3.损失函数BCEloss
Binary CrossEntropy Loss
在二分类中,我们只有两种样本(正样本和负样本),一般正样本的标签y=1,负样本的标签y=0。
设o_start为预测值,t为真实值。
o_start中预测的值可能为任意向量,如随机生成的满足标准正态分布的2*2向量:
import torch
o_start=torch.randn(2,2)
print(o_start)
tensor([[ 1.8047, -0.8064],
[ 0.3579, 0.6943]])
通常o_start经过sigmoid函数激活后,可转化为范围在(0,1)之间的概率值o,每个概率值可表示预测为正样本(=1)的概率,如下图o[0][0]=0.8587表示第一组的第一个样本预测为正样本1的概率为0.8587
```python
o=torch.sigmoid(o_start)
print(o)
tensor([[0.8587, 0.3087],
[0.5885, 0.6669]])
假设真实值t如下:
t = torch.FloatTensor([[0,1],[1,1]])
print(t)
tensor([[0., 1.],
[1., 0.]])
之后将o与t代入BCEloss公式进行计算:
公式

import math
loss00=-(0*math.log(0.8587)+(1-0)*math.log(1-0.8587))
loss01=-(1*math.log(0.3087)+(1-1)*math.log(1-0.3087))
loss10=-(1*math.log(0.5885)+(1-1)*math.log(1-0.5885))
loss11=-(1*math.log(0.6669)+(1-1)*math.log(1-0.6669))
print(loss00,loss01,loss10,loss11)
1.9568699892916555 1.1753853474740235
0.5301783522818057 0.40511516934387637
最后求均值则为BCEloss值。
初步分析:
o[0][0]预测成1的概率很大,为0.8587,实际上真实值为0,预测错误,严重相反,预测偏差很大,单个损失值也很大。
o[0][1]预测成1的概率小,为0.3087,实际上真实值为1,预测错误,很相反,预测偏差大,单个损失值也大。
o[1][0]预测成1的概率不大,为0.5885,实际上真实值为1,预测正确但是不够精准(预测概率应该越趋近于1越准确),预测偏差较小,单个损失值不大
o[1][1]预测成1的概率较高,为0.6669,实际上真实值为1,预测正确且较为精准,预测偏差小,单个损失值小
还有其他情况,可自行生成不同向量进行试验。总体给人的直观印象如下:
真实值为1时:
预测值越大,表示预测成1的概率越大,越准确,造成的损失越小;
预测值越小,表示预测成1的概率越小,越不准确,造成的损失越大。
真实值为0时:
预测值越大,表示预测成1的概率越大,越不准确,造成的损失越大;
预测值越小,表示预测成1的概率越小,越准确,造成的损失越小;
函数分析
![]()
单独看这一块,若预测值t[i]为1,则只剩前半部分:

o[i]越大(越趋近于1),-log(o[i])越小越趋于0(注意原函数最前方还有个负号),损失越小。
o[i]越小(越趋近于0),-log(o[i])越大(注意原函数最前方还有个负号),损失越大。
t[i]为0时相似,不多赘述。
最后将所有损失值相加求均值,即为BCEloss值。
注意:
nn.BCELoss(o,t)的输入o应该为范围在(0,1)之间的概率向量。
nn.BCEWithLogitsLoss(o_start,t)的输入o_start可为任意值,函数后续会对自动输入的o_start进行sigmoid激活,转化成范围在(0,1)之间的概率向量,然后进行BCEloss的计算流程。
5.参数设定
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
criterion=nn.BCELoss().to(device)
generator = Generator().to(device)
discriminator = Discriminator().to(device)
learning_rate=0.0001
optimizer_G = torch.optim.Adam(generator.parameters(),
lr=learning_rate)
optimizer_D = torch.optim.Adam(discriminator.parameters(),
lr=learning_rate)
num_epochs=100
#用于保存图片
os.makedirs("./data/images", exist_ok=True)
6.训练模型
for epoch in range(num_epochs):
gen_losses=[]
discr_losses=[]
for i,(imgs,labels) in enumerate(dataloader):
#构建均为0或1的列向量,作为假值或真值标的签值
real =torch.ones((imgs.size(0),1), requires_grad=False).to(device)
fake =torch.zeros((imgs.size(0),1), requires_grad=False).to(device)
#随机生成一批向量作为输入,经过生成器处理加工成标准形状的图像
input=torch.randn(imgs.size(0),latent_dim).to(device)
gen_imgs=generator(input)
#训练生成器
optimizer_G.zero_grad()
#将生成图片放入判别器进行判断
#判断器将其判别为真值的概率越大,说明生成器效果越好
gen_loss=criterion(discriminator(gen_imgs),real)
gen_loss.backward()
optimizer_G.step()
#训练判别器
optimizer_D.zero_grad()
#判别器将minist训练集中图片判断为真实图片的概率越大,判别器效果越好
#注意当转换某个变量为tensor时,尽量使用torch.as_tensor(),而不直接用torch.tensor()
real_imgs=torch.as_tensor(imgs).to(device)
discr_loss_1=criterion(discriminator(real_imgs),real)
# 判别器将生成器生成的图片判断为假的图片的概率越大,判别器效果越好
# 注意.detach()不可少,不然生成器图片梯度会传入判别器内
discr_loss_2=criterion(discriminator(gen_imgs.detach()),fake)
discr_loss=(discr_loss_1+discr_loss_2)/2
discr_loss.backward()
optimizer_D.step()
gen_losses.append(gen_loss.item())
discr_losses.append(discr_loss.item())
#每训练400组数据后,将生成器生成的前25张图片保存
batches_done = epoch * len(dataloader) + i
if batches_done % 400 == 0:
save_image(gen_imgs.data[:25], "./images/%d.png" % batches_done, nrow=5, normalize=True)
if epoch%10==0:
gen_ave_loss=sum(gen_losses)/len(gen_losses)
discr_ave_loss=sum(discr_losses)/len(discr_losses)
print(
"epoch {}:\n".format(epoch+1),
"gen_loss:{:.8f}\n".format(gen_ave_loss),
"discr_loss:{:.8f}\n".format(discr_ave_loss),
"*"*50
)
epoch 1:
gen_loss:1.59786045
discr_loss:0.29797490
**************************************************
epoch 11:
gen_loss:5.08602562
discr_loss:0.07063241
**************************************************
epoch 21:
gen_loss:3.67149027
discr_loss:0.12322565
**************************************************
epoch 31:
gen_loss:4.00452301
discr_loss:0.11535277
**************************************************
epoch 41:
gen_loss:3.94598874
discr_loss:0.10782991
**************************************************
epoch 51:
gen_loss:3.80831797
discr_loss:0.12315087
**************************************************
epoch 61:
gen_loss:4.13731737
discr_loss:0.09399471
**************************************************
epoch 71:
gen_loss:3.76752163
discr_loss:0.16165560
**************************************************
epoch 81:
gen_loss:4.81352300
discr_loss:0.12167450
**************************************************
epoch 91:
gen_loss:4.20987744
discr_loss:0.11422961
**************************************************
进程已结束,退出代码0
7.查看效果
打开images文件查看:

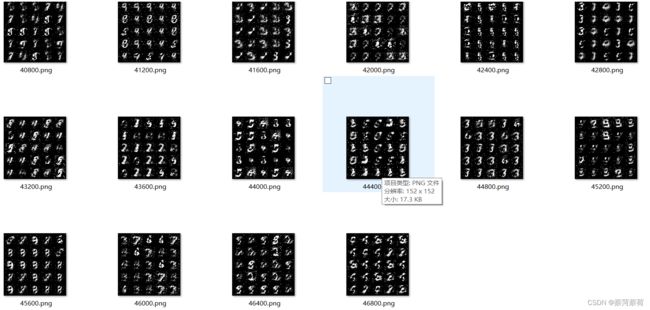
生成图像由一开始的毫无意义的噪音点,经过多次训练后,隐约开始有了手写数字的轮廓,但仍不够清晰,可通过优化生成器、判别器和超参数使其变得更为清晰。