论文阅读-基于计算网格的并行工作负载预测的作业调度算法
原文:A job scheduling algorithm based on parallel workload prediction on computational grid
概述
一般来说,计算网格由大量的计算节点组成,其中一些由于计算需求的地理分布不均而处于空闲状态。这可能会导致工作负载不平衡问题,影响大规模计算网格的性能。为了平衡计算需求和计算节点,我们提出了一种基于计算节点工作负载预测的作业调度算法。我们首先分析了工作负载不平衡的原因和重新分配计算资源的可行性。其次,我们通过结合先前设计的工作负载预测模型,设计了一种应用和工作负载感知的调度算法(AWAS)。为了降低AWAS算法的复杂性,我们提出了一种基于计算节点工作负载预测的并行作业调度方法。实验表明,AWAS算法可以在真实数据集上平衡不同计算节点之间的工作负载。此外,我们从内部结构和数据集的角度提出了工作负载预测模型的并行化,以使AWAS适用于更多大规模计算网格的计算节点。实验结果表明,两者的结合可以实现令人满意的加速效率。
1.引言
随着互联网的快速发展,计算网格已成为处理计算密集型问题的新型计算模式。计算网格利用互联网将分布在不同地理位置的计算资源组织成一个虚拟的大型计算机[6,24]。当高科技领域和前沿技术研究面临大规模计算问题时,这个虚拟计算机可以提供所需的计算速度和存储容量。近年来,计算网格已广泛应用于基因组学、分子动力学、量子化学等科研领域[8,24,30]。
在本文中,中国国家网格由七个国家级超级计算中心和大学高性能计算中心组成,为社会经济各领域的计算需求提供硬件和软件支持[1,20]。中国国家网格在每个计算节点上部署了诸如Gaussian、LAMMPS(大规模原子/分子并行模拟器)、VASP(Vienna Ab-initio Simulation Package)等软件。用户将计算需求打包成作业,并通过虚拟专用网络提交给中国国家网格。中国国家网格在固定时间间隔内统一收集作业,然后将它们调度到每个计算节点进行计算。
然而,在现有的调度策略中,具有相同功能的计算节点之间的工作负载不平衡。例如,2019年1月5日,上海超级计算中心的利用率为91.2%,而其中一个节点仅为4.3%。超级计算机的空闲计算资源必然会导致电力资源的浪费和环境的恶化,这不是设计师和投资者所期望的结果[4]。更好的解决方案是预测网格计算节点的工作负载,并根据预测结果优化作业调度。
在我们之前的工作中,我们设计了一个工作负载预测模型,用于捕捉上海超级计算中心的时间和日期的二维负载特征[22],其性能令人满意。为了解决上述提到的工作负载不平衡问题,我们将使用工作负载预测模型生成一个调度算法。然而,不同的计算节点具有不同的时间和日期特征。工作负载预测模型需要通过不同节点的数据进行训练,然后才能应用于每个节点。根据从2014年9月17日到2021年3月30日的统计数据,Sugon TC4600超级计算机有2,668,627个计算数据。对于包括在中国国家网格中的所有计算节点来说,使用它们自己的时间和日期特征训练工作负载预测模型是一项耗时的挑战。更重要的是,中国国家网格有一个严格的作业调度机制[24]。我们的调度算法必须遵循这个机制,因此在使用资源预测模型预测节点的工作负载时,我们必须始终注意其时间消耗[17,32]。
受到这些挑战的启发,我们为中国国家网格设计和评估了一种应用和工作负载感知的作业调度算法(AWAS)。本文的主要贡献可以总结如下:
- 我们首先介绍了中国国家网格的作业调度方法,并详细分析了资源负载不平衡的原因。
- 其次,我们从内部结构和数据集的角度提出了工作负载预测模型的并行性。
- 第三,我们将网格计算节点工作负载预测模型与生成应用程序和工作负载感知的作业调度算法相结合。我们还对这个算法进行了并行化处理,以减少时间复杂度。
- 最后,我们通过负载平衡标准和实际调度效果评估了所提出的AWAS算法。
本文的剩余部分安排如下:第2节回顾相关工作。我们在第3节分析了工作负载不平衡的原因。第4节提出了应用程序和工作负载感知的作业调度算法(AWAS)。第5节提出了工作负载预测模型的并行性。第6节评估了所提出的AWAS算法。最后,我们在第7节总结了本文,并对进一步研究提出了一些建议。
2.相关工作
提高网格服务的质量,加快任务请求的处理速度,确保良好的用户体验都涉及到任务调度。高效的任务调度对于大规模分布式异构计算网格的运行效率至关重要。目前,任务调度已被证明是一个NP困难问题。由于任务调度问题的NP完全性质,许多人尝试使用启发式智能算法来解决大规模计算网格的任务调度问题[6,7,23,28,29]。在论文[6]中,作者将启发式经典GD算法与VND算法相结合,以最小化调度的最长完成时间。S.K. Zaman等人设计了一种启发式调度算法(ExH2LL),通过结合限制处理器容量和任务数量的计算模型来平衡工作负载并减少完成时间[29]。在论文[7]中,作者以云资源的带宽和工作负载为约束条件,结合分而治之的方法来最大化CPU、带宽和内存的利用率。这些研究都使用启发式算法来处理大规模计算网格下的任务调度问题,并取得了良好的结果。因此,在大规模计算网格中使用启发式算法解决任务调度问题是可行的。
作为高性能、高可用性和避免单点故障的最终解决方案,负载均衡受到了研究者的广泛关注。在论文[14]中,作者将任务转化为超图(k阶超图指的是图中的每个边链接了k个点),并使用改进的Dijkstra算法获得最优调度策略,以最小化响应时间和合理分配资源。L. Hung等人通过整合两种基于遗传的算法,在虚拟机和虚拟机主机之间获得最佳负载分配[11]。在论文[19]中,作者提出了RIAL方法,通过动态分配不同权重来避免未来时刻的负载不平衡。关键是实现负载均衡的关键在于准确预测未来可用资源。例如,论文[11]使用基因表达来对虚拟机的未来工作负载进行编程预测。我们的工作将围绕这一点展开。
人工神经网络是启发式算法的重要分支。由于教授及其学生的研究[9,10,27,31],它得到了极大的推广和应用。人工神经网络的优势在于它可以从海量数据中捕捉事物的特征。许多研究者已经将其用于负载预测[2,13,16,26]。在我们之前的工作中,我们使用2DLSTM神经网络对大规模计算系统的负载进行预测[22]。准确预测节点的工作负载对于负载均衡非常有益。然而,由于2DLSTM结构本身的复杂性,使用2DLSTM神经网络必然会增加算法训练和执行的时间。我们在这项工作中尝试并行化这种方法。
并行处理技术是自20世纪60年代以来在微电子、高性能处理器、存储系统、通信渠道、编程环境和应用问题方面的研究和工业发展的产物[3,17,21,25,32]。随着人工智能的浪潮,它与机器学习相结合,在工业和生产生活中得到了广泛应用。最近,越来越多的研究将并行技术应用于神经网络。在论文[3]中,作者从内部结构上并行化了递归神经网络的前向传播和反向传播。在论文[21]中,作者以数学优化的方式巧妙地并行化了卷积神经网络的内部结构。V. Rybalkin等人从硬件角度并行化了2DLSTM[18]。这些方法都取得了良好的并行和预测结果。然而,机器学习训练和预测的过程都是耗时任务。在这项工作中,我们从数据集和内部结构的角度减少了模型训练和预测的时间。
因此,为解决大规模计算网格调度过程中的负载不平衡问题。我们首先使用2DLSTM对大规模计算网格节点的工作负载进行准确预测。为了提高算法的执行效率,我们采用支持CUDA的加速并行2DLSTM来减少多个虚拟机上的预测时间。与相关工作的区别在于,我们的算法针对大规模计算网格的负载均衡,并从数据集和内部结构的角度改善了算法的执行效率。
3.工作负载不平衡
中国国家网格可以收集全国范围内的计算需求。来自全国各地的用户将他们的计算需求打包成作业并通过虚拟专用网络提交给中国国家网格。中国国家网格在固定时间间隔内调度收集到的作业到可用的计算节点上。中国国家网格的结构如图1所示。在这项工作中,我们使用符号TI来表示中国国家网格完成调度的时间。符号JS表示单个TI内收集到的所有作业。符号n表示JS的数量(n≥0)。

作为一个大规模分布式计算网格,中国国家网格没有权力调用每个计算节点的所有计算资源。例如,长沙国家超级计算中心在完成网格调度的同时收集附近的计算需求(图1)。在这种调度中,中国国家网格无法准确获得每个计算节点的工作负载。在这项工作中,我们使用符号NS来表示单个TI内可用节点的集合,符号m表示NS的数量(m>1)。
计算节点的基本属性包括节点名称、频率、最大CPU计数、最小CPU计数、所有核心、部署软件等。我们在表1中列出了其中一些。然而,这些具有基本相似的计算频率、软件部署和核心数限制的计算节点具有不同的利用率。经济发达地区的节点接受更多的直接调度作业。例如,在图2中,SSC和CNIC的执行核心远远多于NSCC和USTC。


此外,计算节点硬件资源的维护和由于网络波动造成的作业分配能力不足也是空闲计算资源的原因。在这里,我们使用AC(NSj)、ACN(NSj)、MaxCL(NSj)、MinCL(NSj)来表示NSj的所有核心、可用核心数、最大CPU限制、最小CPU限制、NSj的频率限制,符号AV(NSj)表示NSj中软件名称和软件版本的二元组集合。
要解决一些节点的计算资源闲置问题,必须更好地利用资源。选择利用率最低的计算节点以获得更好的负载平衡水平。我们还使用NW来表示节点的工作负载。

在这里,符号AvgNW表示节点之间的平均负载。

遵循标准措施实现节点之间的负载平衡。我们使用NLBL来表示节点的负载平衡水平,其中较大的NLBL表示节点之间的负载更加平衡。

4.应用程序和工作负载感知的作业调度算法
在本节中,我们将提出一种应用程序和工作负载感知的作业调度算法(AWAS)。首先,准确预测![]() 对于实现负载平衡是必要的。在时刻t,收集过去k小时和h天内的NWj,形成一个向量NWVj。这里,h!=0,k!=0,我们让
对于实现负载平衡是必要的。在时刻t,收集过去k小时和h天内的NWj,形成一个向量NWVj。这里,h!=0,k!=0,我们让
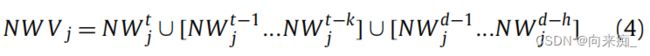
同时结合相应NSj的训练2DLST Mj,预测未来时间t+1的![]() 。NSj'的可用核心数ACN(NSj)可以通过以下方式计算:
。NSj'的可用核心数ACN(NSj)可以通过以下方式计算:
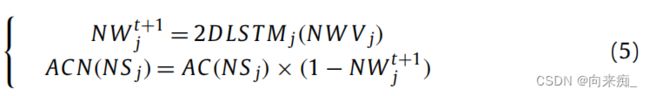
当ACN(NSj)> 0时,合法的JSi应包含以下属性。我们使用CN(JSi),WT(JSi),APP(JSi),VS(JSi)来表示所需的核心数,频率限制,应用程序名称,JSi的应用程序版本,分别列出其中一些在表2中。
JSi需要满足NSj的约束条件,主要包括时间,核心数,应用程序和应用程序版本。我们使用JSN(JSi,NSj)表示JSi是否成功安排给NSj。当JSi满足以下条件JSN(JSi,NSj)时,我们可以通过多个轮询获取RS(JS,NS)对的集合,这将是以下应用程序和工作负载感知作业调度算法的输出。
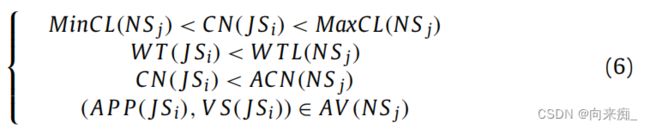
负载均衡意味着具有更多可用核心的NSj将承担更多的JSi。 (CNMin(JS))被选择为ACNMax(NS)以获取RSi(JSi,NSj)。通过轮询,JS,RS和ACNMax(NS)将随之相应更改:
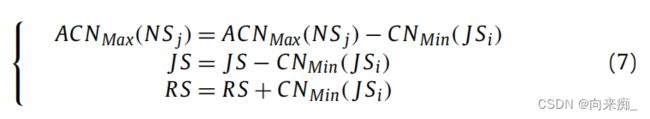
在调度过程中,有些情况是不可避免的。当JSN(JSi,NSj)失败时,JSi将从JS中删除。当ACN(NSj = 0)时,RS不会受到影响,因为JSi可以等待在NSj上。
在中国国家网格调度机制中,我们提出的AWAS算法需要满足以下条件:

其中,符号TC表示时间消耗,Num表示集合中的数字个数,符号δ表示数据传输和分析的时间,在这里我们假设δ = 0。
为了满足公式(8)的第一项,我们需要减少实际执行时间。随着输入节点和作业数量的增加,具有高时间复杂度的调度算法通常表现出较差的性能。可以在算法调度之前完成相应节点的训练。因此,我们仅关注耗时的算法调用。由于2DLSTM本身的复杂结构带来的大量矩阵操作使ACN的推导成为AWAS最耗时的部分。因此,我们如图3所示并行化了2DLSTM的预测。

应用程序和工作负载感知作业调度算法概述如算法1所示。最初,我们初始化网格调度期间的参数,例如作业集(JS),节点集(NS),节点工作负载(NW)。然后,使用支持CUDA的并行2DLSTM神经网络来预测未来时刻的节点工作负载。接下来,利用以下步骤来识别最佳作业-节点匹配对。
算法的主要步骤如下:
- 记录时间TB。
- 在TI时刻,收集和初始化节点集合NS和作业集合JS。
- 使用支持CUDA的并行2DLSTM模型来训练与节点工作负载对应的预测模型。
- 对于每个作业JSi(从1到n),进行以下操作: a. 从节点工作负载NW中生成NWVj。 b. 根据2DLSTM j预测的节点工作负载,计算节点资源容量ACN(NSj)。
- 对于每个作业JSi(从0到n),对于每个作业节点NSj(从0到m),进行以下操作:
- a. 如果JSN(CNMin(JS),ACNMax(NS))成功,则表示作业JSi能够分配给节点NSj。将JSi添加到结果集RS中。
- b. 如果JSN(CNMin(JS),ACNMax(NS))失败,则表示作业JSi无法分配给节点NSj。从作业集合JS中删除JSi。更新节点资源容量ACNMax(NSj)和作业集合JS。
- 统计结果集RS中作业数量Num(RS)并减少作业集合JS中的作业数量Num(JS)。
- 记录时间TE。
- 如果TE-TB < TI且结果集RS中作业数量等于n,则返回结果集RS;否则保持现有调度。

5.并行工作负载预测方法
5.1. 2DLSTM方案的基本理念
在本节中,我们回顾了2DLSTM的前向传播和反馈过程。在隐藏层中,将上一时刻和上一天的输出与当前输入结合起来完成预测是其最大的特点。2DLSTM单元结构将在时间和日期轴上进行反馈。
2DLSTM的单元结构如图4所示。与传统的LSTM类似,它主要由门结构组成。这四个门以以下方式处理上一层的输出和当前时刻的输入。

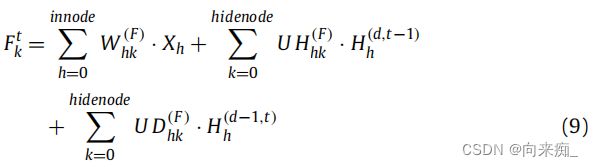
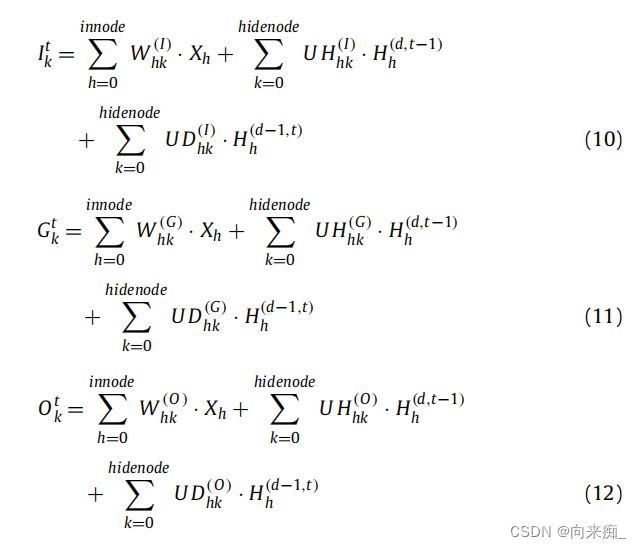
在单元结构中,层的状态值![]() 是通过以下方式由
是通过以下方式由![]() 、
、![]() 和
和![]() 生成的,其中tanh是双曲正切函数:
生成的,其中tanh是双曲正切函数:
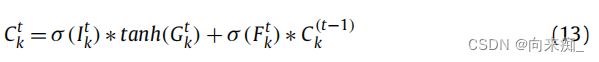
隐藏层状态![]() 通过以下方式与输出门
通过以下方式与输出门![]() 结合,生成隐藏层输出
结合,生成隐藏层输出![]() :
:

显然,![]() 并不是2DLSTM的最终结果。隐藏层输出
并不是2DLSTM的最终结果。隐藏层输出![]() 需要通过以下方式完成对实际结果
需要通过以下方式完成对实际结果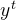 的映射:
的映射:

2DLSTM采用逐层监督学习方法,通过梯度下降来最小化ε(t),其中表示时间t的实际输出值。
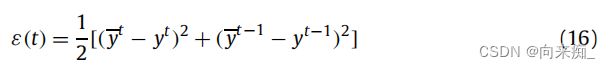
5.2. 2DLSTM的结构并行性
以上是2DLSTM的前向传导过程。接下来,获取ε(t)对所有单元结构中的矩阵的梯度。为了方便计算,首先计算ε(t)相对于![]() 、
、![]() 和
和![]() 的偏导数。2DLSTM的并行性包含在前向传导和反馈中 [18]。
的偏导数。2DLSTM的并行性包含在前向传导和反馈中 [18]。
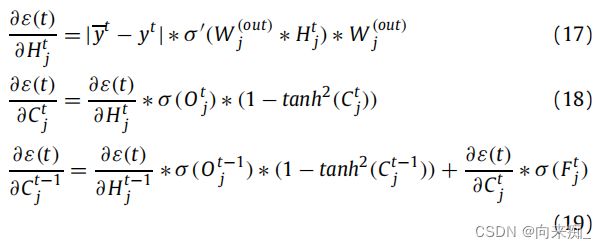
对于所有的矩阵,新的权重![]() 是通过以下方式生成的。其中α是学习率,
是通过以下方式生成的。其中α是学习率,![]() 是上一个时刻的权重,是ε(t)相对于
是上一个时刻的权重,是ε(t)相对于![]() 的偏导数:
的偏导数:

由于在单元结构中获取梯度的方法类似,这里就不再重复了。以![]() 为例,我们结合方程(9)、方程(13)、方程(14)、方程(15)、方程(16)来计算其梯度,如方程(21)所示。
为例,我们结合方程(9)、方程(13)、方程(14)、方程(15)、方程(16)来计算其梯度,如方程(21)所示。
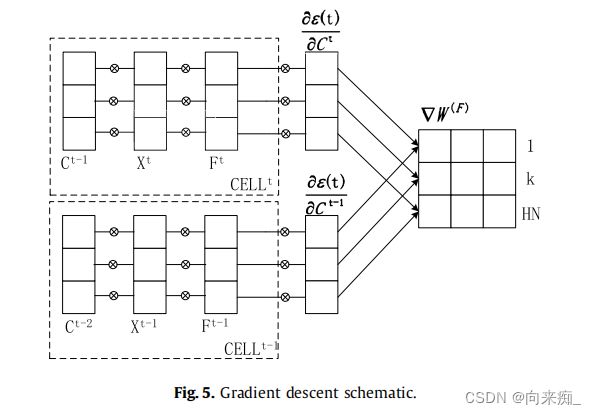
在这一点上,方程(21)中的所有项都被计算出来了,这使得并行训练成为可能。如上所述,当某个矩阵经历梯度下降时,当前时刻的矩阵梯度是根据当前时刻和上一个时刻获得的量来确定的[5]。 仍然以![]() 为例,如图5所示。当前时刻的
为例,如图5所示。当前时刻的![]() 由细胞结构中时刻t处的已知向量
由细胞结构中时刻t处的已知向量![]() 、
、![]() 、
、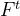 所决定。并行化上述所有向量的组件,它们都是图5中连接部分,计算速度可能会增加。需要经历梯度下降的矩阵不仅仅是
所决定。并行化上述所有向量的组件,它们都是图5中连接部分,计算速度可能会增加。需要经历梯度下降的矩阵不仅仅是![]() ,而是具有与
,而是具有与![]() 相同形状的矩阵,
相同形状的矩阵,![]() 、
、![]() 、
、![]() 具有类似的梯度下降方法。然后,我们将同一形状的不同矩阵组合起来进行并行处理的组件,将使并行块变得更大,这是期望的结果。
具有类似的梯度下降方法。然后,我们将同一形状的不同矩阵组合起来进行并行处理的组件,将使并行块变得更大,这是期望的结果。
5.3. 2DLSTM的数据并行性
在神经网络的分布式训练中,仅仅进行结构上的并行化是不够的。接下来,对数据进行分区,并探索数据收集的并行性[18]。图6显示了之前的2DLSTM训练过程。从t0开始,隐藏层输出沿着时间轴和日期轴传输。这种训练的优点是每个时间节点可以更好地保留先前的隐藏层输出状态。缺点是每个时刻的训练受到先前隐藏层输出的限制,难以并行化。根据不同计算节点的特性划分训练子任务将成为解决这个问题的方法。

2DLSTM单元中的更新方法如方程(20)所示。作为反向传播过程中最耗时的部分,具体的计算方法如下所示:
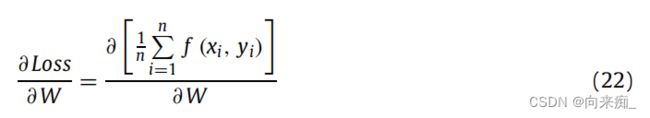
其中n是样本集合的数量。f(xi, yi)是将样本输入xi映射为预测结果yi的函数。我们将方程(22)展开为:
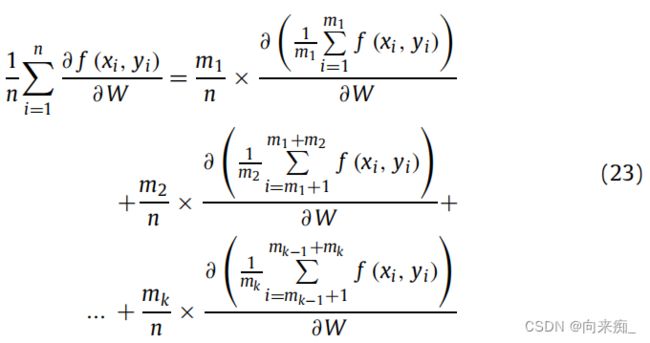
等式(23)可以抽象为:

显然,当m1=m2=…=mk=![]() 方程(22)可以转换为:
方程(22)可以转换为:
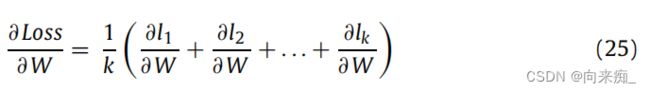
其中,mk是训练集的m部分,被分成k个点。
方程(25)表示将包含n个样本的数据集均匀分割为k个处理器后的结果组合方式。上述推论是在理想条件下进行的,即处理器在相同的数据集上以相同的速度运行。
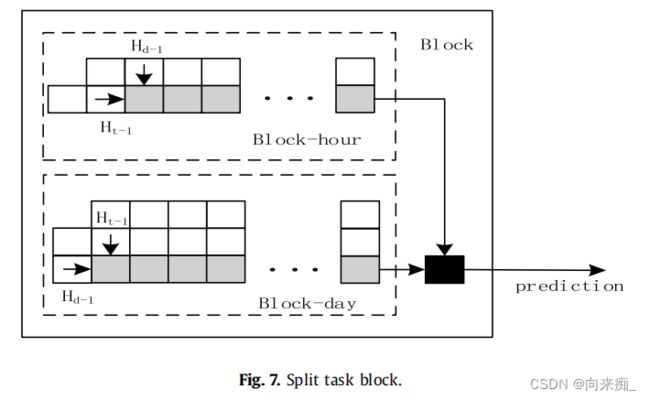
在我们之前的工作中,发现不同计算节点的负载在日期和时间轴上是有规律的。例如,上海超级计算中心节点的负载在日期轴上呈现7个周期的规律变化,在时间轴上呈现24个周期的规律变化[22]。根据这个规律将子任务进行划分,如图7所示。块被用于训练的输入,块内部被划分为时间块和数据块。每个方格代表图4中所示的单元。以上海超级计算中心为例,块-t中灰色方格的数量为24,块-d中灰色方格的数量为7。其余的白色方格只提供灰色方格训练所需的状态值和梯度下降过程中ε(t)的计算。块-t和块-d也可以并行计算。
6.性能分析
6.1.实验平台
为了测试我们提出的AWAS算法的性能,我们在一台配备有八个Intel® Xeon® bronze 3204核心的x64服务器上进行了实验。图形卡、视频内存和计算频率分别为Quadro RTX 5000、12G、1.90 GHz。我们建立了类似于中国国家网格的调度器,使用C++语言实现。实验数据来自2019年4月18日至6月4日的中国国家网格实际调度日志。由于部分日志的权限问题和计算节点的维护升级,数据集中在5月4日附近,其中TI = 600,Num(NS)= 46。
6.2.资源预测评估
加速比是单处理器系统和并行处理器系统中运行相同任务所消耗时间的比值,用于衡量并行系统或程序并行化的性能和效果。为了提高计算加速比的准确性,并更直观地感受到并行改进的程度,引入一个概念,即时钟周期。时钟周期也称为振荡周期,定义为时钟频率的倒数。在一个时钟周期内,CPU只完成最基本的动作之一。
计算公式如下:

在相同的实验环境下,CPU的周期频率始终保持不变。此时,加速比公式可以转化为:
为了评估上述提出的并行策略,使用CUDA流来模拟不同多处理器组合的并行加速[15],如图8(a)所示。

其中,结构并行性(SP)是前面提到的梯度下降中的并行性。数据并行性(DP)是在划分子任务之后,将不同的子任务交给不同的CUDA流进行处理。N表示使用的CUDA流的数量,并且通过嵌套内核函数的方式,比较了N/5、N/10规模与SP结合的加速比。从图表中可以清楚地看到,当CUDA流的数量为50时,SP加速比的斜率开始下降,5/N,SP的加速比超过了SP,而10/N,SP的斜率仍然保持上升趋势。为了防止读写同一个矩阵发生冲突,我们使用内核函数的嵌套来在CUDA环境中并行化数据和结构,而不是将矩阵写入全局内存。当CUDA流较小时,矩阵传输时间占总操作时间的比例会大于并行流较大时的情况。这就是为什么图8(a)中50之前的数据并行化的加速比低于50之后的原因。
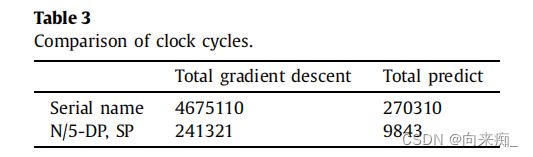
表3是在实际完成5000次训练时,串行和N/5-DP、SP使用的时钟周期数,其中CUDA流的数量为50。通过比较和计算,结构并行性的加速比为19.37%,整体并行加速比为17.09%。可以得出结论,此时数据集的并行优化比例相对较高。在这里,我们将使用训练好的2DLSTM来进行预测。
完成2DLSTM的并行训练后,我们将实际数据与串行训练后的神经网络预测结果和并行训练后的预测结果进行比较。结果如图8(b)所示,串行获得的预测结果通常比并行获得的预测结果更接近实际数据。但在实际的训练过程中,两者的时间成本非常不同。因此,我们将使用不影响AWAS策略的并行数据结果。然后,我们将使用并行训练获得的并行资源预测模型进行预测,并完成AWAS调度实验。
6.3. 探索不同的梯度下降方法
我们比较了原始LSTM、2DLSTM和我们提出的SP-2DLSTM的平均轮次时间(AvgET)和平均绝对百分误差(MAPE)值,以进一步验证我们提出的并行架构的有效性。其中,MAPE值的定义为:
其中n是样本集的数量,yi是第i个样本的真实结果,yi是神经网络的预测结果。MAPE通常用于比较在相同数据集上不同模型的准确性。
我们在线程计算后同步结果,并将平均值更新到主线程。这种方法称为同步梯度下降(SGD)。我们也可以在处理器计算出样本子集的结果后立即将其更新到主节点,而无需同步。这种方法称为异步随机梯度下降(ASGD)。在第6.2节中,我们使用了同步梯度下降方法,并在本实验中添加了异步梯度下降方法进行比较。
为确保消融实验中变量的唯一性,我们使用相同的分割数据集(N/5)训练不同的模型,并比较不同更新方法对训练结果的影响。其中,我们将原始LSTM的预测作为基线,CUDA流的数量为40,每个epoch中的数据块数量为55560。
实验结果如表4所示。实验结果表明,2DLSTM在面对二维数据(日期、时间)时的MAPE值比LSTM好9.62%,而单个epoch的时间也比LSTM快455.67分钟。相应地,与2DLSTM相比,我们提出的SP-2DLSTM节省了551.98分钟的时间,加速比约为3。该预测效果仍然优于传统的LSTM。

当我们添加数据并行SGD梯度下降时,所有三种模型的训练时间都大大缩短。然而,传统LSTM的MAPE值接近17%,不再适用于精确预测。此时,SP-2DLSTM的预测准确度已经超过了2DLSTM,证明了两个并行方法嵌套的有效性。
由于输出层中存在sigmoid函数,输出值被控制在(0,1)之间。因此,MAPE大于20%通常被认为在这个数据集上是不收敛的。然而,在使用ASGD下降方法时,上述三个模型都不收敛。可以看出,ASGD方法在面对具有复杂结构和单个节点长操作时间的网络模型时表现不佳。这是因为我们无法控制每个节点的运行速度,但必须接受它给出的更新值。
相比之下,SP-2DLSTM在SGD中具有很好的数据并行性能,并且速度提升比也随着少量精度损失而增加。这是因为同步情况下,使用结构化并行2DLSTM单元在单个节点上操作也会产生快速结果。
6.4. 调度算法评估
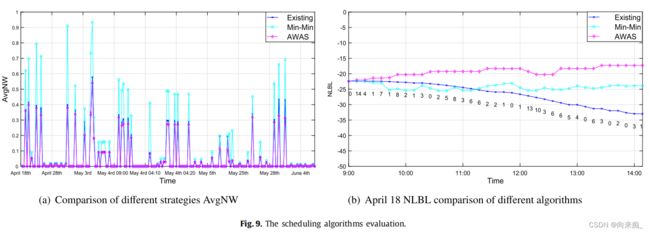
在本节中,我们将我们提出的AWAS与传统的Min-Min和现有的调度算法进行比较。结果如图9所示。根据理论分析,MIN-MIN和现有的调度算法在平均值和NLBL值方面都落后于我们提出的AWAS算法。
实际上,AWAS算法始终将作业调度到资源最多的节点,以确保整体负载平衡。ACN是AWAS考虑的主要因素。当单个作业面对多个具有相同NW的NSj时,AWAS将其调度到具有更大ACN的NSj上。根据公式(1)和(2),AvgNW的增加将是最小的。因此,通过AWAS调度的AvgNW将小于Min-Min策略和现有调度策略在实际调度过程中的AvgNW。我们比较了三种不同调度策略之间的AvgNW。
在总核心数相同的理想情况下,平均值确实不是负载平衡指数的度量。实际情况是,不同计算节点的总核心数、存储容量和计算速度都不同。AWAS算法通过工作负载确定工作和节点对。当通过轮询获取适合调度的节点集时,AWAS算法将优先选择负载较小的节点,而负载较小的节点通常是具有大量可用核心的节点,因此工作负载值的增加量减少,整体的平均增加量也会减少。因此,在这种情况下,平均值可以用作参考标准。实验结果表明,AWAS策略比现有调度策略低12.27%,比Min-Min调度策略低93.24%(图9(a))。较小的AvgNW意味着更合理的资源分配。
从图9(b)的结果可以看出,横坐标表示作业提交时间,纵坐标表示节点的NLBL。虚线下的数字表示nt。当TI = 600时,AWAS每小时调度六次。NLBL越大,节点之间的负载平衡越好。实验结果证明,现有调度和Min-Min策略的NLBL值随着作业调度而不断降低。节点之间的资源分配变得越来越不均衡。 AWAS算法在调度过程中的NLBL值呈上升趋势,并且始终优于其他两种调度策略的单个调度。基于实验结果,我们可以得出结论,AWAS可以有效地解决这种情况下不平衡的资源负载问题。
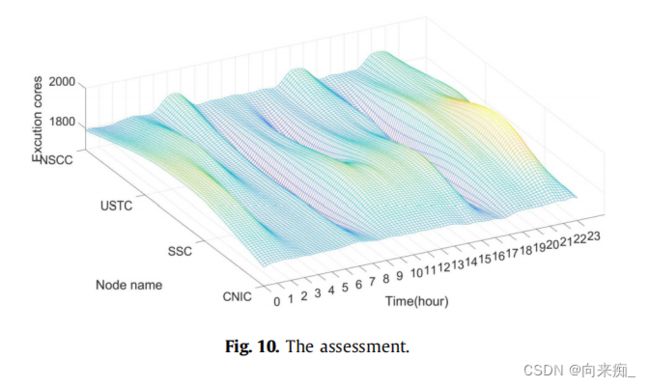
在此时,它对应于图2。在AWAS调度下,2019年5月1日,四个节点的活动核心数如图10所示。图表越浅,值的差异越大。图10中浅色部分的面积比图2小,这表明在AWAS算法的调度优化之后,每个节点的活动核心数之间的差异减小了。从Z轴的值范围可以更直观地观察到这一现象。图2中的活动核心数分布在0到4000之间,而图10中的活动核心数分布在0到2000之间。最后但并非最不重要的,从图形的平滑程度来看,图10的平滑程度优于图2。原本集中在SSC节点上的作业被分配到其他节点上。所有这些现象都意味着计算资源得到了合理的分配。
7.结论与未来工作
本文首先研究了重新分配计算资源的可行性,并将其与先前设计的工作负载预测模型相结合,生成了一种应用和网格计算节点工作负载感知的调度策略。然而,在实际使用中发现,该策略的执行效率并不高。因此,我们对其调度过程进行了并行化处理。实验结果表明,我们提出的AWAS算法优于现有的调度策略和Min-Min算法。中国国家网格提供的真实数据实验证明,我们提出的应用和网格计算节点工作负载感知调度策略可以在大规模网格上实现良好的工作负载平衡。为了使作业调度策略能够应用于更多的大规模计算网格的计算资源,我们从内部结构和数据集的角度对其中包含的二维长短期记忆神经网络进行了并行化处理。实验表明,两者的结合可以实现令人满意的加速效率。
通过对我们的研究进行系统回顾,我们将来会朝着以下方向发展:
- 尽管通过并行训练得到的2DLSTM预测结果引起的误差在可接受范围内,但我们是否可以采取一些措施对其进行优化,以提高并行精度。
- 目前,我们获取的数据仅支持我们对软件负载的研究,所以如果将来包括硬件资源和开销的信息,我们的调度策略将如何改进。