【和鲸社区活动】医疗问诊平台会员续费分析实战项目
【和鲸社区活动】医疗问诊平台会员续费分析实战项目
文章目录
- 【和鲸社区活动】医疗问诊平台会员续费分析实战项目
-
- 1 背景
- 2 分析步骤
- 3 数据清洗与预处理
- 4 探索性数据分析(EDA)
-
- 4.1 用户的基本统计信息展示
- 4.2 订单数据的基本统计信息
- 4.3 问诊数据的基本统计信息
- 4.4 用户行为分析
- 4.5 订单分析
- 4.6 问诊数据分析
- 5 深入分析
-
- 5.1 用户留存分析
- 5.2 续费率分析
- 5.3 地域分析
- 5.4 年龄和性别分析
- 6 提出改进建议
- 6 提出改进建议
本项目很荣幸获得了活动第一名,得到了指导老师的认可,完整可下载的项目已经挂在了我的和鲸主页,感兴趣的朋友可以去fork,点赞,评论,谢谢支持!
1 背景
近年来,互联网医疗市场发展迅速,越来越多的人选择在线上寻求医疗服务。作为一家互联网问诊平台,为付费会员提供医疗问诊、买药等医疗类服务,如何提高会员续费率是一个重要的问题。数据分析师可以通过分析平台会员续费数据,了解用户的行为、需求和偏好,从而提出针对性的续费策略,帮助企业提升收益和用户满意度。
假如你是一家互联网问诊平台的数据分析师,现为了提高会员续费率,需要你根据数据提出针对性的续费策略并产出一份数据分析报告,提升平台用户留存率和盈利能力。本次活动从互联网医疗平台实际业务场景出发,充分体现数据分析的价值,在完成分析项目的过程中,将培养思考数据分析意义的能力,并开始深入理解数据驱动决策的实质。
2 分析步骤
- 数据清洗与预处理
- 加载数据集(
consult-test.csv,order-test.csv,user-test.csv)。 - 检查并处理缺失值、异常值。
- 确认并转换数据类型。
- 删除或修正无用字段。
- 加载数据集(
- 探索性数据分析(EDA)
- 描述性统计分析:了解数据集的基本统计特征,如平均值、中位数、极值等。
- 用户行为分析:用户使用平台的频率、偏好等。
- 订单数据分析:平均订单金额、订单数量等。
- 会员与非会员行为对比:查看会员与非会员在使用平台上的差异。
- 深入分析
- 用户留存分析:分析用户的留存率,特别是会员的留存情况。
- 续费率分析:分析会员的续费率,找出影响续费的关键因素。
- 地域分析:根据用户的地理位置(国家、省份、城市等)分析用户行为。
- 年龄和性别分析:查看这些人口统计特征如何影响用户行为和续费率。
- 提出改进建议
- 基于上述分析结果,提出具体的运营优化建议。
- 针对不同用户群体制定差异化策略。
- 提出提高用户满意度和留存率的措施。
3 数据清洗与预处理
import pandas as pd
consult_data_path = '/home/mw/input/mdVIP7851/consult-test.csv'
order_data_path = '/home/mw/input/mdVIP7851/Order-test.csv'
user_data_path = '/home/mw/input/mdVIP7851/user—test.csv'
# 读取数据集
try:
consult_data = pd.read_csv(consult_data_path, encoding='gbk')
order_data = pd.read_csv(order_data_path, encoding='gbk')
user_data = pd.read_csv(user_data_path, encoding='gbk')
# 显示数据的前几行以进行初步检查
consult_head = consult_data.head()
order_head = order_data.head()
user_head = user_data.head()
load_error = None
except Exception as e:
consult_head, order_head, user_head = None, None, None
load_error = str(e)
consult_head
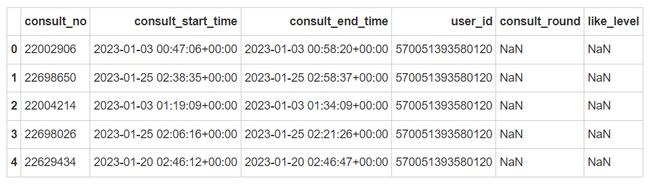
order_head

user_head
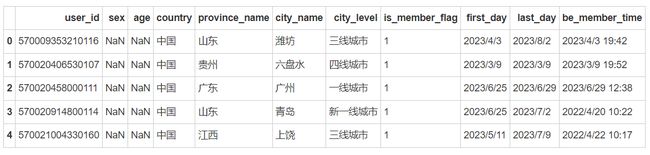
我们已经成功加载了数据集,并且可以看到每个数据集的前几行,现在我们将进行数据清洗和预处理,接下来的操作包括检查和处理缺失值、异常值,转换数据类型,以及删除或修正无用字段。
接下来我们将分别处理这三个数据集文件
# 处理consult-test(问诊数据)
# 删除无用字段
consult_data_clean = consult_data.drop(columns=['consult_round'])
# 转换日期时间类型
consult_data_clean['consult_start_time'] = pd.to_datetime(consult_data_clean['consult_start_time'])
consult_data_clean['consult_end_time'] = pd.to_datetime(consult_data_clean['consult_end_time'])
# 处理order-test(订单数据)
# 转换日期时间类型
order_data['order_time'] = pd.to_datetime(order_data['order_time'])
# 处理user-test(用户数据)
# 转换日期时间类型
user_data['first_day'] = pd.to_datetime(user_data['first_day'])
user_data['last_day'] = pd.to_datetime(user_data['last_day'])
user_data['be_member_time'] = pd.to_datetime(user_data['be_member_time'])
# 然后我们再检查每个数据集的缺失值情况
missing_values = {
"consult_data": consult_data_clean.isnull().sum(),
"order_data": order_data.isnull().sum(),
"user_data": user_data.isnull().sum()
}
missing_values
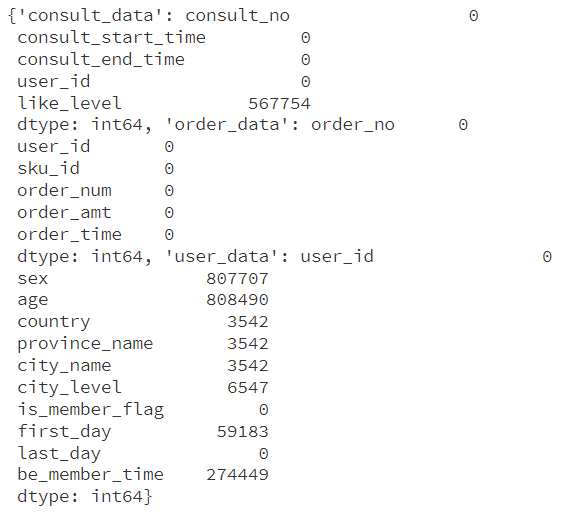
从我们查看缺失值的情况我们可以看出,我们需要对每个数据集进行相应的处理:
1、问诊数据
- 其中
like_level字段有大量缺失值,这是用户评价,其中的缺失值可能意味着用户未进行评价,我们可以将其保留,以便后续分析用户满意度。
2、 订单数据
- 其中没有缺失值,所以我们无需特别处理。
3、 用户数据
对于用户数据里面存在大量的缺失值,它们包括:
sex和age字段有大量缺失值,这些是关键的人口统计信息,可能需要进一步分析缺失原因。country,province_name,city_name,city_level有部分缺失值,这些地理信息对于地域分析很重要。first_day有一些缺失值,这可能影响用户行为的时间序列分析。be_member_time有较多缺失值,这是关键字段,因为它影响分析用户成为会员的时间。
针对上述各个数据集中各缺失值字段我们可以分别对其进行特定的处理操作:
- 对于sex和age,我们可以考虑使用特殊值填充(如未知或中位数),或者在某些分析中忽略这些缺失值。
- 地理信息的缺失值可以用“未知”来填充。
- first_day 和 be_member_time 的缺失值处理较为复杂,可能需要根据业务背景来决定是否填充或删除。
# 对于 sex 和 age,使用特殊值填充
user_data['sex'].fillna('unknown', inplace=True)
user_data['age'].fillna(user_data['age'].median(), inplace=True) # 使用中位数填充
# 地理信息缺失值用“unknown”填充
user_data['country'].fillna('unknown', inplace=True)
user_data['province_name'].fillna('unknown', inplace=True)
user_data['city_name'].fillna('unknown', inplace=True)
user_data['city_level'].fillna('unknown', inplace=True)
# 对于 first_day 和 be_member_time,由于业务重要性,我们先保留缺失值,后续根据分析需求决定处理方式
# 更新后的缺失值情况
updated_missing_values = {
"consult_data": consult_data_clean.isnull().sum(),
"order_data": order_data.isnull().sum(),
"user_data": user_data.isnull().sum()
}
updated_missing_values
当一些必要缺失值处理完成之后(一部分缺失值我们选择保留,方便后续的进一步分析)我们就可以开始进行探索性数据分析了。
4 探索性数据分析(EDA)
4.1 用户的基本统计信息展示
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="whitegrid")
# 用户数据的基本统计信息分析
user_age_distribution = user_data['age'].describe()
sex_distribution = user_data['sex'].value_counts()
# 绘制用户年龄分布图
plt.figure(figsize=(10, 6))
sns.histplot(user_data['age'], bins=30, kde=True)
plt.title('User age distribution')
plt.xlabel('age')
plt.ylabel('Frequency')
plt.xlim(0, 100) # 将年龄范围限制在0到100岁
plt.show()
# 绘制性别分布图
plt.figure(figsize=(8, 5))
sex_distribution.plot(kind='bar')
plt.title('User gender distribution')
plt.xlabel('gender')
plt.ylabel('quantity')
plt.xticks(rotation=0)
plt.show()
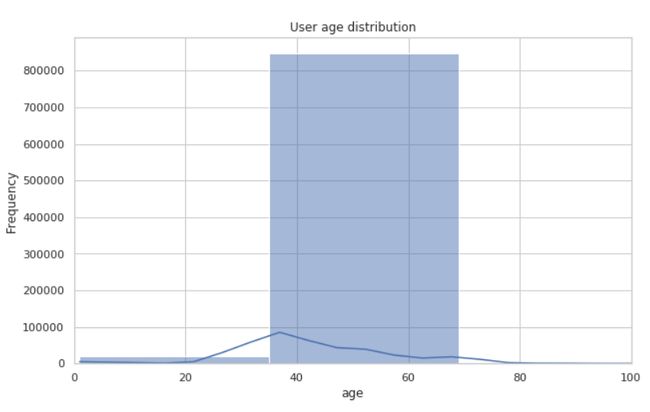
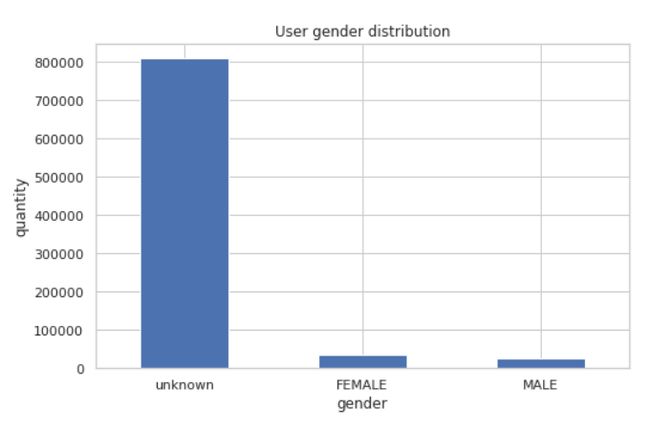
用户数据结果分析
- 年龄分布:
- 问诊人员平均年龄约为 44 岁。
- 而且年龄分布集中在中年段,似乎表明平台用户主要是中年人群。
- 性别分布:
- 大多数用户的性别未知,这可能是数据收集过程中很多用户为了保护隐私不愿意透露自己的性别导致的。
- 在已知性别的用户中,女性用户略多于男性用户。
4.2 订单数据的基本统计信息
# 绘制订单金额分布图
plt.figure(figsize=(10, 6))
sns.histplot(order_data['order_amt'], bins=30, kde=True)
plt.title('Order amount distribution')
plt.xlabel('order amount')
plt.ylabel('Frequency')
plt.xlim(0, 1000)
plt.show()
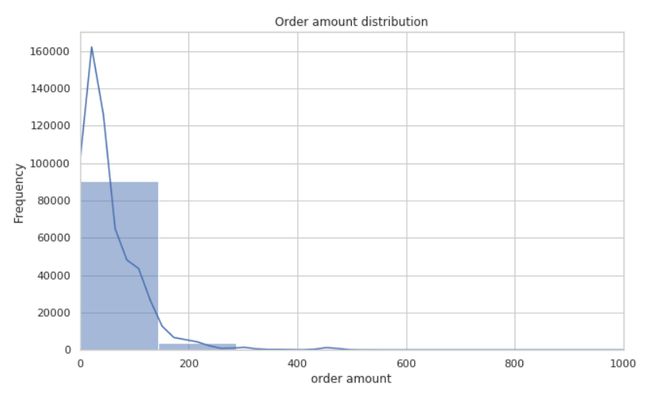
order_amount_distribution = order_data['order_amt'].describe()
order_amount_distribution

订单数据结果分析
- 订单金额
- 订单金额的平均值约为 60.59 元。
- 订单金额的分布范围广泛,最高达到 4300 元。
4.3 问诊数据的基本统计信息
consult_data_clean['consult_start_time'] = pd.to_datetime(consult_data_clean['consult_start_time'])
consult_data_clean['consult_end_time'] = pd.to_datetime(consult_data_clean['consult_end_time'])
# 计算问诊时长(分钟)
consult_data_clean['consult_duration'] = (consult_data_clean['consult_end_time'] - consult_data_clean['consult_start_time']).dt.total_seconds() / 60
# 移除极端的长尾异常值,仅保留5%到95%分位数之间的数据
lower_bound = consult_data_clean['consult_duration'].quantile(0.05)
upper_bound = consult_data_clean['consult_duration'].quantile(0.95)
filtered_consult_duration = consult_data_clean[(consult_data_clean['consult_duration'] >= lower_bound) & (consult_data_clean['consult_duration'] <= upper_bound)]
# 问诊时长的描述性统计
consult_duration_stats = filtered_consult_duration['consult_duration'].describe()
# 绘制问诊时长分布图
plt.figure(figsize=(10, 6))
sns.histplot(filtered_consult_duration['consult_duration'], bins=50, kde=True)
plt.title('Distribution of consultation time')
plt.xlabel('Duration (minutes)')
plt.ylabel('Frequency')
plt.show()
consult_duration_stats
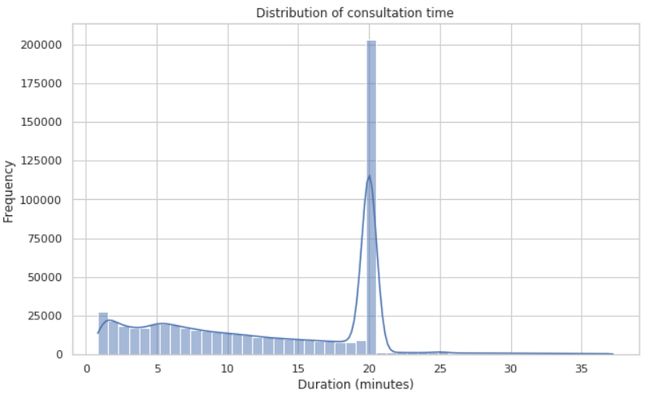

问诊时长数据分析结果
- 问诊记录统计:
- 上述数据显示总共记录了 662,158 次问诊。
- 其中平均问诊时长约为 15.75 分钟,这表明一般问诊并不耗时。
- 问诊时长波动性:
- 问诊时长的标准差为 103.23 分钟,说明个别问诊时长远长于平均值,存在较大波动。
- 最长的一次问诊记录为 30 天,这极有可能是数据录入错误。
- 问诊时长分布:
- 大部分问诊时长较短,25%的问诊在 5.55 分钟内完成,中位数为 13.97 分钟。
- 只有25%的问诊时长超过 20.02 分钟,表明多数问诊都能在较短时间内处理。
4.4 用户行为分析
接下来我将重心转移到用户行为分析上面,我们将重点关注以下几个方面:
- 访问频率:分析用户使用平台的频率,例如平均每个用户的访问次数。
- 服务类型偏好:分析用户更倾向于使用哪些类型的服务(如问诊或购药)。
- 会员与非会员行为差异:对比会员和非会员在使用平台上的行为差异。
# 合并用户数据和问诊数据
user_consult_data = pd.merge(user_data, consult_data_clean, on='user_id', how='left')
# 合并用户数据和订单数据
user_order_data = pd.merge(user_data, order_data, on='user_id', how='left')
# 分析访问频率
# 用户的问诊次数
user_consult_counts = user_consult_data.groupby('user_id')['consult_no'].count()
# 用户的订单次数
user_order_counts = user_order_data.groupby('user_id')['order_no'].count()
# 计算平均访问次数
avg_consult_per_user = user_consult_counts.mean()
avg_order_per_user = user_order_counts.mean()
(avg_consult_per_user, avg_order_per_user)
# 在合并后的数据集中进行分组统计以分析会员与非会员行为差异
member_consult_counts = user_consult_data.groupby('is_member_flag')['consult_no'].count()
member_order_counts = user_order_data.groupby('is_member_flag')['order_no'].count()
# 获取会员和非会员的用户数
member_user_counts = user_data['is_member_flag'].value_counts()
# 计算每类用户的平均问诊次数和订单次数
avg_consult_per_member = member_consult_counts / member_user_counts
avg_order_per_member = member_order_counts / member_user_counts
(avg_consult_per_member, avg_order_per_member)

用户行为分析结果
- 平均访问频率:
- 用户平均问诊次数约为 0.76 次/用户。
- 用户平均订单次数约为 0.11 次/用户。
- 会员与非会员行为差异:
- 会员用户的平均问诊次数为 1.03 次/会员,非会员为 0.17 次/非会员。
- 会员用户的平均订单次数为 0.11 次/会员,非会员为 0.12 次/非会员。
根据数据信息的反映,我们不难看出会员用户比非会员用户更频繁地使用问诊服务,但在订单数量方面,会员和非会员差异不大,这表明虽然会员用户更倾向于使用平台提供的问诊服务,但在购药方面的活跃度并没有显著提高。
import numpy as np
plt.figure(figsize=(12, 6))
# 可视化平均问诊次数和订单次数
plt.subplot(1, 2, 1)
plt.bar(['Average number of consultations/user', 'Average number of orders/user'], [avg_consult_per_user, avg_order_per_user], color=['blue', 'green'])
plt.title('Average number of consultations and orders')
plt.ylabel('frequency')
# 可视化会员与非会员的平均问诊次数和订单次数
plt.subplot(1, 2, 2)
bar_width = 0.35
index = np.arange(2)
bar1 = plt.bar(index, avg_consult_per_member, bar_width, label='Number of consultations', color='b')
bar2 = plt.bar(index + bar_width, avg_order_per_member, bar_width, label='Number of orders', color='g')
plt.xlabel('user type')
plt.ylabel('frequency')
plt.title('Average number of consultations and orders between members and non-members')
plt.xticks(index + bar_width / 2, ('Non-members', 'member'))
plt.legend()
plt.tight_layout()
plt.show()
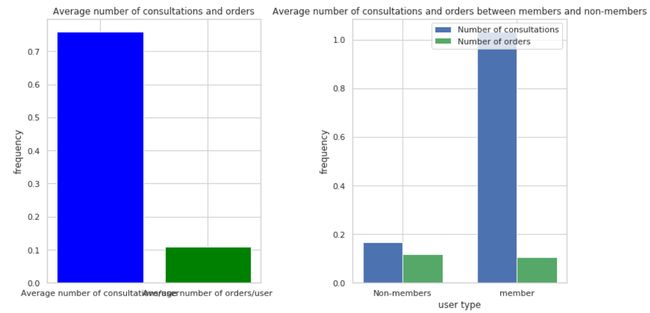
我们将上述数据信息进行可视化展示,更加直观的可以看出其中的联系。
左图:显示了用户的平均问诊次数和平均订单次数,可以看到平均问诊次数略高于平均订单次数。
右图:展示了会员与非会员的平均问诊次数和订单次数,从图中可以看出会员用户的平均问诊次数明显高于非会员,而在订单次数方面两者差异不大。
4.5 订单分析
接下来我们将进行订单分析,我们重点关注以下两个方面:
- 订单数量和订单金额的时间序列趋势:识别订单活动的高峰期和低谷期。
- 不同商品(SKU)的销售情况:分析各个商品的销售表现。
# 订单数量和订单金额的时间序列趋势
# 提取日期信息
order_data['order_date'] = order_data['order_time'].dt.date
# 按日期聚合数据,计算每天的订单数量和订单金额
order_trend = order_data.groupby('order_date').agg({'order_no': 'count', 'order_amt': 'sum'})
# 绘制订单数量和订单金额随时间的变化趋势图
plt.figure(figsize=(15, 6))
plt.subplot(1, 2, 1)
order_trend['order_no'].plot(kind='line', color='blue')
plt.title('Daily order quantity trend')
plt.xlabel('date')
plt.ylabel('quantity of order')
plt.xticks(rotation=45)
plt.subplot(1, 2, 2)
order_trend['order_amt'].plot(kind='line', color='green')
plt.title('Daily order amount trend')
plt.xlabel('date')
plt.ylabel('order amount')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
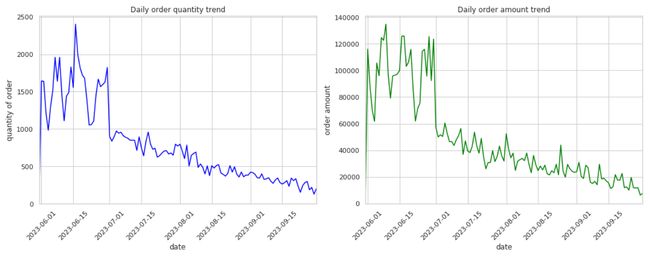
# 不同商品(SKU)的销售情况
# 按SKU聚合数据,计算每个SKU的订单数量和订单金额
sku_sales = order_data.groupby('sku_id').agg({'order_no': 'count', 'order_amt': 'sum'}).sort_values(by='order_no', ascending=False)
# 显示销售最好的前10个SKU
top_10_sku = sku_sales.head(10)
top_10_sku
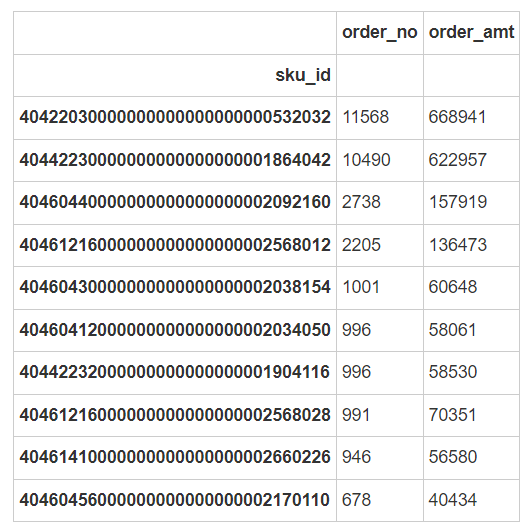
订单分析结果
-
订单数量和订单金额的时间序列趋势
- 每日订单数量趋势(左图): 订单数量随时间的变化显示了一定的波动性,但没有明显的长期趋势,可能需要更详细的数据来识别特定的高峰期或低谷期。
- 每日订单金额趋势(右图): 与订单数量类似,订单金额也显示出波动性,这可能与特定活动、节假日或促销有关。
-
不同商品(SKU)的销售情况
- 我们列出了销售最好的前10个SKU(根据订单数量排序),可以看到某些SKU的订单数量明显高于其他SKU,这可能表明这些商品更受欢迎或更频繁地被购买。
4.6 问诊数据分析
接下来我们将对问诊数据进行分析,重点关注以下两个方面:
- 问诊频率和用户满意度分析:评估问诊服务的使用频率以及用户满意度(基于评价星级)。
- 用户评价与其他因素的关系分析:探究用户评价与问诊时长、购药历史等因素之间的关系。
# 问诊频率和用户满意度分析
total_consults = consult_data_clean['consult_no'].count()
average_like_level = consult_data_clean['like_level'].mean()
like_level_distribution = consult_data_clean['like_level'].value_counts().sort_index()
# 用户评价与其他因素的关系分析
consult_data_clean['consult_duration'] = (consult_data_clean['consult_end_time'] - consult_data_clean['consult_start_time']).dt.total_seconds() / 60
consult_order_merged = pd.merge(consult_data_clean, order_data, on='user_id', how='left')
like_duration_relation = consult_data_clean.groupby('like_level')['consult_duration'].mean()
consult_order_merged['has_order'] = consult_order_merged['order_no'].notnull()
like_order_relation = consult_order_merged.groupby('like_level')['has_order'].mean()
(total_consults, average_like_level, like_level_distribution, like_duration_relation, like_order_relation)
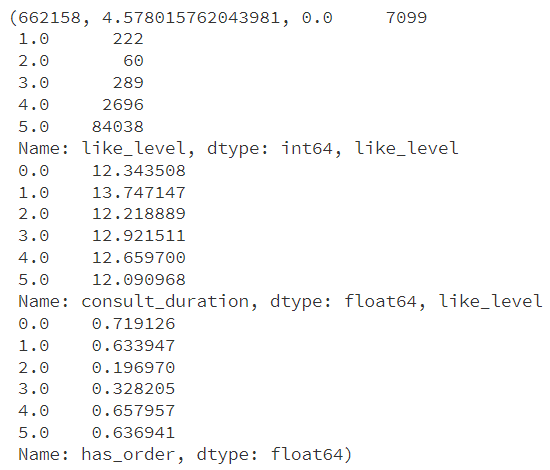
问诊数据分析结果
- 问诊频率和用户满意度:
- 此平台共完成了662,158次问诊服务。
- 用户对问诊服务的平均满意度评分为4.58分(满分为5分),整体来看平台满意程度非常高,用户非常满意平台的服务。
- 满意度评分分布:
- 评分为0的问诊有7,099次,可能反映出一部分用户的极度不满或者故意打低分,或者是竞争对手请的水军刷评分。
- 评分为1的有222次,评分为2的有60次,这些较低评分需要进一步分析其原因。
- 评分为3的有289次,显示一定程度的满意。
- 评分为4的较多,达到2,696次,而高分评价(5分)有84,038次,说明大多数用户对服务质量相对满意。
用户评价与其他因素的关系
- 评价星级与问诊时长的关系:不同的评价星级对应的平均问诊时长有轻微差异,但总体来说变化不显著。
- 评价星级与购药历史的关系:拥有购药历史的用户更倾向于给出较高的评价星级,这表明购药服务可能增加用户的整体满意度。
另外对于获得0到2星评价的问诊,我们应该详细了解其背后的具体原因,以便在未来改进服务,我们还可以探索问诊时长和购药历史与用户满意度之间的联系,着手提供更加个性化和高效的服务,以提升用户的整体满意度。
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="whitegrid")
plt.figure(figsize=(18, 6))
# 可视化用户满意度评分分布
plt.subplot(1, 3, 1)
like_level_distribution.plot(kind='bar')
plt.title('User satisfaction score distribution')
plt.xlabel('Rating star')
plt.ylabel('frequency')
# 可视化评价星级与问诊时长的关系
plt.subplot(1, 3, 2)
like_duration_relation.plot(kind='bar', color='orange')
plt.title('The relationship between rating stars and consultation time')
plt.xlabel('Rating star')
plt.ylabel('Average consultation time (minutes)')
# 可视化评价星级与购药历史的关系
plt.subplot(1, 3, 3)
like_order_relation.plot(kind='bar', color='green')
plt.title('The relationship between rating stars and drug purchase history')
plt.xlabel('Rating star')
plt.ylabel('Proportion of users with a history of purchasing medicines')
plt.tight_layout()
plt.show()
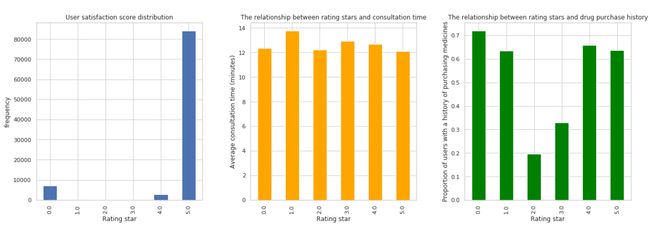
根据上述问诊数据的可视化图表,下面是分析结果:
- 用户满意度评分分布:这张图展示了不同评分等级的分布情况,可以看到大多数用户给出了较高的评分(4分和5分)。
- 评价星级与问诊时长的关系:这张图展示了不同评价星级的平均问诊时长,平均时长在各个评分等级之间的差异不大。
- 评价星级与购药历史的关系:这张图展示了不同评价星级的用户中,拥有购药历史的用户比例,可以看出评分较高的用户更可能有购药历史。
这些可视化结果有助于更直观地理解用户对问诊服务的满意度以及其他相关因素的影响。
5 深入分析
5.1 用户留存分析
为了进行用户留存分析,我们需要计算特定时间段内新注册用户的留存率,通常留存率是通过在不同时间点(如30天、60天、90天后)跟踪用户来计算的,根据我们所用数据集情况,我们可以使用first_day和last_day字段来评估用户的留存情况。
import datetime as dt
# 转换日期字段
user_data['first_day'] = pd.to_datetime(user_data['first_day'])
user_data['last_day'] = pd.to_datetime(user_data['last_day'])
# 计算用户的留存期(天)
user_data['retention_days'] = (user_data['last_day'] - user_data['first_day']).dt.days
# 分析会员和非会员的留存期分布
member_retention = user_data[user_data['is_member_flag'] == 1]['retention_days'].describe()
non_member_retention = user_data[user_data['is_member_flag'] == 0]['retention_days'].describe()
(member_retention, non_member_retention)
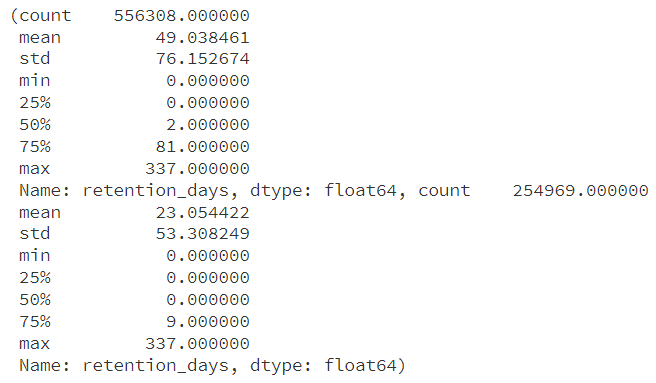
用户留存分析结果
- 会员用户留存
- 会员用户的平均留存为49天,这个数字显示了会员用户在加入后的稳定活跃期。
- 多数会员用户的留存天数是2天,表明部分用户可能仅试用服务后便停止活跃。
- 会员用户的留存期最长可达337天,显示了潜在的长期用户群体。
- 非会员用户留存
- 非会员用户的平均留存较低,仅为23天,反映了非会员用户较低的平台黏性。
- 中位数留存为0天,暗示有相当一部分非会员用户注册后并未活跃使用。
- 非会员用户留存同样可达337天,说明即使非会员也有可能长期保持活跃。
深入用户留存情况的解读
看来成为会员的用户通常会在平台上停留更长时间,这一发现通过会员平均留存天数得到了证实,这表明会员服务在保持用户活跃度方面起着关键作用,但另一方面,会员用户的留存天数中位数相对较低,这也揭示了一些会员可能仅在短暂尝试平台服务后选择离开,这种情况的出现说明,尽管提供会员服务是提高用户留存的有效策略,但我们还需要探索如何更好地维持用户的长期兴趣和参与度。
行动与建议以提高用户留存
要提升用户留存,我们必须更细致地分析哪些因素最能影响用户选择留下或离开,特别是用户的使用模式和对我们服务的满意程度都是值得研究的关键点,对于那些注册后不久就离开的用户,我们需要详细了解他们的反馈,哪些服务未能满足他们的需求,或者哪些服务体验需要改进,通过这些反馈,我们可以采取有针对性的措施来提升用户体验,鼓励用户继续使用平台。同时,我们也要关注那些长期留存的用户,理解他们的需求和喜好,定制个性化服务,以此加强他们对平台的忠诚和依赖。
5.2 续费率分析
然后我们来进行企业比较关注的续费率方面分析,续费率分析的目标是确定会员用户是否在会员到期后进行了续费,如果用户的会员到期时间早于他们的最近一次访问时间,则可以认为用户进行了续费。
# 转换会员到期时间为日期类型
user_data['be_member_time'] = pd.to_datetime(user_data['be_member_time'])
# 定义函数判断用户是否续费
def is_renewed(row):
if row['is_member_flag'] == 1 and row['be_member_time'] < row['last_day']:
return 1 # 续费
return 0 # 未续费或非会员
# 应用函数判断每个会员是否续费
user_data['renewed'] = user_data.apply(is_renewed, axis=1)
# 计算续费率
total_members = user_data['is_member_flag'].sum()
total_renewed = user_data['renewed'].sum()
renewal_rate = total_renewed / total_members
# 分析续费用户与未续费用户的特征差异
renewed_users = user_data[user_data['renewed'] == 1]
non_renewed_users = user_data[user_data['renewed'] == 0]
# 计算续费用户和未续费用户的平均留存天数
avg_retention_renewed = renewed_users['retention_days'].mean()
avg_retention_non_renewed = non_renewed_users['retention_days'].mean()
(renewal_rate, avg_retention_renewed, avg_retention_non_renewed)
# 可视化续费率
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
# 绘制会员和非会员的留存期分布图
plt.hist([renewed_users['retention_days'], non_renewed_users['retention_days']], bins=30, label=['Renew user', 'Unrenewed users'])
plt.title('Retention period distribution of members and non-members')
plt.xlabel('Retention period (days)')
plt.ylabel('amount of users')
plt.legend()
plt.subplot(1, 2, 2)
plt.bar(['Renew user', 'Unrenewed users'], [avg_retention_renewed, avg_retention_non_renewed])
plt.title('Average retention period of renewing and non-renewing users')
plt.xlabel('user type')
plt.ylabel('Average retention period (days)')
plt.tight_layout()
plt.show()
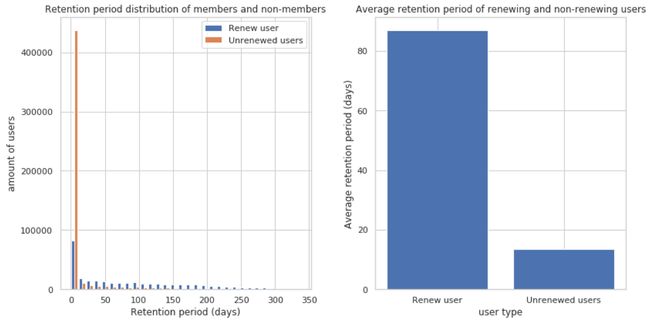
续费率分析结果
观察会员用户的行为表明,超半数的用户在会员期满后选择了续费,具体续费率达到了54.89%,这个比例让我们看到了服务对用户的吸引力,以及用户对平台的信任和依赖,令人欣慰的是,那些选择续费的用户平均留存时间为87.06天,相较于未续费用户的平均留存时间13.44天,显著更长,这揭示了续费用户在平台上的深度参与。
对续费行为的深入理解
这样的续费率和留存天数对比给我们带来了积极的信号:用户对我们的服务有着良好的接受度,并且服务在一定程度上满足了他们的需求。然而我们也看到了续费意愿与留存天数之间的正相关关系,提示我们,那些最终选择留下的用户,往往是更加积极参与的用户。
提高续费率的策略
为了进一步提升续费率,我们需要深入挖掘和理解用户的具体需求和续费背后的动因,是否是我们的服务质量、会员专属福利,还是我们的价格策略,这些都可能是影响用户做出续费决定的关键因素,对于那些没有选择续费的用户,我们需要分析他们的反馈和行为,找出潜在的不满意点,制定相应的改进措施,以促进用户转化为长期忠实的顾客。
5.3 地域分析
紧接着我们将进行地域分析,探索用户行为与其地理位置之间的关系,这个分析将帮助我们了解不同地域的用户特征和行为模式,从而为针对性的市场策略提供支持。
# 分析用户在不同国家、省份、城市的分布情况
country_distribution = user_data['country'].value_counts()
province_distribution = user_data['province_name'].value_counts()
city_distribution = user_data['city_name'].value_counts()
top_countries = country_distribution.head(5)
top_provinces = province_distribution.head(5)
top_cities = city_distribution.head(5)
# 分析地域与用户行为的关系
# 例如,分析不同省份的用户续费率
province_renewal_rate = user_data.groupby('province_name')['renewed'].mean().sort_values(ascending=False).head(5)
(top_countries, top_provinces, top_cities, province_renewal_rate)
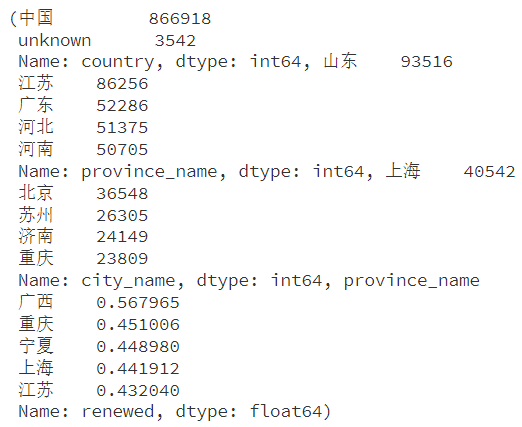
plt.figure(figsize=(18, 6))
# 可视化用户地域分布
plt.subplot(1, 3, 1)
top_countries.plot(kind='bar')
plt.title('User geographical distribution')
plt.xlabel('country')
plt.ylabel('amount of users')
# 可视化用户地域与续费率的关系
plt.subplot(1, 3, 2)
province_renewal_rate.plot(kind='bar', color='orange')
plt.title('The relationship between user region and renewal rate')
plt.xlabel('province')
plt.ylabel('Renewal rate')
# 可视化用户地域与续费率的关系
plt.subplot(1, 3, 3)
top_cities.plot(kind='bar', color='green')
plt.title('User geographical distribution')
plt.xlabel('City')
plt.tight_layout()
plt.show()

用户分布与地域特性分析结果
我们的数据显示,用户主要集中在中国,特别是在山东、江苏、广东、河北和河南这五个省份。城市层面上,上海、北京、苏州、济南和重庆是用户最密集的地区。这种分布可能与这些地区的互联网普及率、人口密度和经济发展水平密切相关。
地域因素与用户续费率的联系
值得关注的是,广西、重庆、宁夏、上海和江苏等地区的用户展现出了较高的续费率。这暗示着地域特性,如经济条件、医疗资源分布和用户对数字医疗服务的接受度,可能对用户的续费决策产生显著影响。
深入地域特性以优化服务
针对上述发现,我们建议:
- 在用户密集的地区深入分析用户行为模式和需求,以发现潜在的服务机会,并提供更加个性化的服务。
- 详细研究续费率较高的省份,探究其背后的成功因素,例如可能的政策支持、用户偏好或服务特色,以便在其他地区复制类似的成功经验。
- 针对那些续费率较低的省份,了解用户对当前服务的不满意点,探索如何通过改善服务质量、调整价格策略或增加用户参与度来提升用户满意度和续费率。
通过这些策略,我们可以更好地适应不同地区的市场需求,提升整体服务水平和用户满意度。
5.4 年龄和性别分析
最后我们将进行年龄和性别分析,以了解这些人口统计特征如何影响用户行为和续费率,这个分析将帮助我们更好地理解不同人群的需求和偏好,从而为针对性的市场策略和服务提供支持。
# 分析不同年龄段和性别的用户行为
age_bins = [0, 18, 30, 40, 50, 60, 100]
user_data['age_group'] = pd.cut(user_data['age'], bins=age_bins)
age_group_behavior = user_data.groupby(['age_group', 'sex']).size().unstack()
# 分析不同年龄段和性别的用户续费率
age_group_renewal_rate = user_data.groupby(['age_group', 'sex'])['renewed'].mean().unstack()
(age_group_behavior, age_group_renewal_rate)
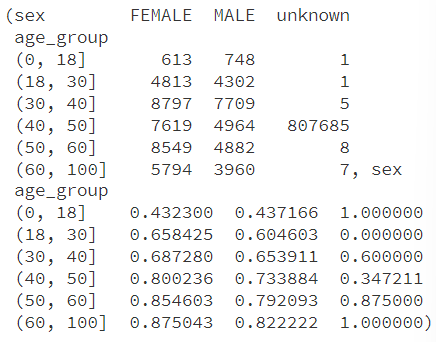
plt.figure(figsize=(18, 6))
# 可视化不同年龄段和性别的用户行为
plt.subplot(1, 2, 1)
age_group_behavior.plot(kind='bar', ax=plt.gca())
plt.title('User behavior by age group and gender')
plt.xlabel('generation')
plt.ylabel('amount of users')
plt.legend(title='gender')
# 可视化不同年龄段和性别的用户续费率
plt.subplot(1, 2, 2)
age_group_renewal_rate.plot(kind='bar', ax=plt.gca())
plt.title('User renewal rates for different age groups and genders')
plt.xlabel('generation')
plt.ylabel('Renewal rate')
plt.legend(title='gender')
plt.tight_layout()
plt.show()
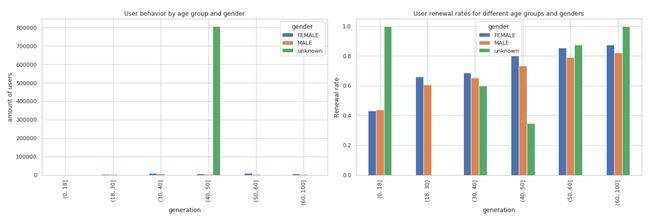
年龄和性别对用户行为的影响
根据我们的数据分析,可以明显看出用户的年龄和性别在一定程度上影响着他们的行为和续费决策。
用户行为分析
- 在年轻的用户群体(0-18岁)中,男性用户略多于女性用户。
- 随着年龄增长,女性用户的数量开始超过男性用户,尤其在30-60岁的年龄段中。
- 在60岁以上的群体中,女性用户数量继续保持领先。
续费率分析
- 续费率随年龄增长而上升,显示出年龄较大的用户群体更倾向于续费。
- 在所有年龄段中,女性用户的续费率普遍高于男性。
- 40岁以上的用户群体显示出尤其高的续费率,特别是在女性用户中。
用户在年龄和性别上的不同表现,提示我们在制定市场策略和优化服务时需要考虑到这些差异,年轻用户群体可能需要更多的激励和创新服务来提高他们的续费率,而年长的用户则可能更注重服务的质量和稳定性。
针对不同群体的策略建议
- 对年轻用户群体,尤其是男性用户,可以提供更多创新和互动性强的服务来吸引他们。
- 对于年龄较大的用户群体,特别是女性用户,应提供更加贴心和个性化的服务,以满足他们对高质量服务的需求。
- 考虑开展针对性的营销活动,以吸引不同年龄和性别的用户,特别是那些续费率较低的群体。
通过深入理解不同年龄段和性别用户的特点和需求,我们可以更有效地提升用户满意度和忠诚度,进而提高续费率和整体业务的成功率。
6 提出改进建议
综合分析与运营策略建议
基于对用户行为、留存率和续费情况的深入分析,我们可以制定以下针对性的运营优化和差异化策略,以提高用户满意度和平台的整体表现。
运营优化建议
- 提升服务质量:优化问诊流程,比如简化预约步骤和缩短响应时间,以提高用户体验和满意度。
- 增强会员福利:为会员提供额外服务,如优先问诊和个性化健康建议,以提高会员用户的忠诚度和留存率。
- 加强客户支持:建立高效的客户服务体系,快速解决用户问题,提升用户对平台的信赖。
面向不同用户群体的策略
- 基于年龄和性别的个性化服务:根据用户的年龄和性别差异,提供定制化的健康咨询和服务,比如为中老年人提供慢性病管理,为年轻人提供生活方式指导。
- 地区特定的服务策略:针对不同地区用户的特点和需求,提供相应的定制化服务和优惠活动,如在用户密集的地区增加健康宣教活动,提高续费率较高地区的高端服务选项。
提升用户满意度和留存率的措施
- 强化个性化体验:根据用户的历史行为和偏好提供个性化的服务建议,增强用户满意度。
- 用户教育与指导:通过教育内容和指南帮助用户更好地理解和利用平台,提升使用体验。
- 积极的反馈机制:建立系统的用户反馈通道,收集并响应用户的意见,持续优化服务质量。
- 忠诚度激励计划:为长期和活跃用户提供奖励或优惠,鼓励他们持续使用服务并续费。
深入理解不同年龄段和性别用户的特点和需求,我们可以更有效地提升用户满意度和忠诚度,进而提高续费率和整体业务的成功率。
6 提出改进建议
综合分析与运营策略建议
基于对用户行为、留存率和续费情况的深入分析,我们可以制定以下针对性的运营优化和差异化策略,以提高用户满意度和平台的整体表现。
运营优化建议
- 提升服务质量:优化问诊流程,比如简化预约步骤和缩短响应时间,以提高用户体验和满意度。
- 增强会员福利:为会员提供额外服务,如优先问诊和个性化健康建议,以提高会员用户的忠诚度和留存率。
- 加强客户支持:建立高效的客户服务体系,快速解决用户问题,提升用户对平台的信赖。
面向不同用户群体的策略
- 基于年龄和性别的个性化服务:根据用户的年龄和性别差异,提供定制化的健康咨询和服务,比如为中老年人提供慢性病管理,为年轻人提供生活方式指导。
- 地区特定的服务策略:针对不同地区用户的特点和需求,提供相应的定制化服务和优惠活动,如在用户密集的地区增加健康宣教活动,提高续费率较高地区的高端服务选项。
提升用户满意度和留存率的措施
- 强化个性化体验:根据用户的历史行为和偏好提供个性化的服务建议,增强用户满意度。
- 用户教育与指导:通过教育内容和指南帮助用户更好地理解和利用平台,提升使用体验。
- 积极的反馈机制:建立系统的用户反馈通道,收集并响应用户的意见,持续优化服务质量。
- 忠诚度激励计划:为长期和活跃用户提供奖励或优惠,鼓励他们持续使用服务并续费。
通过这些综合性策略的实施,我们能够更好地满足用户的需求,提升用户的满意度和忠诚度,从而促进平台的持续健康成长和发展。