2024数学建模美赛C题详细代码思路手把手教学
问题分析
问题围绕2023年温网男单决赛中,20岁的西班牙新星卡洛斯·阿尔卡拉兹击败36岁的诺瓦克·德约科维奇的比赛。德约科维奇自2013年以来首次在温布尔登输球,结束了他在大满贯赛事中的杰出表现。这场比赛被认为是一场精彩的较量,经历了多次势头的转换,这些势头转换通常被归因于“动量”。在体育运动中,团队或球员可能会在比赛/比赛中感觉到自己有动量,或“力量/力量”,但很难衡量这种现象。此外,还不清楚比赛中的各种事件是如何产生或改变势头的。
提供了2023年温布尔登网球公开赛前两轮之后所有男子比赛的每一分数据。您可以自行选择包含其他玩家信息或其他数据,但必须完整记录来源。
也就是说,我们需要通过对已有的数据进行处理,找到其中包含动量特征的因素,构建一个模型去衡量这些因素是否使得我们选手的表示更加生猛,下面是我们的一个具体思路。
数据预处理
确保每个比赛的数据完整性,包括比赛时间、比分、发球情况等。
转换时间格式,统一比分表示方法。
将数据转换成可处理的数值数据,如在玩家的得分中,包含了AD这一项,这不利于我们后续的数据处理,可以将其转换成50
特征提取
目标是找到可以为运动员积累获胜“动量”的特征,可以从以下角度考虑是否存在连胜的“动量”。
比分变化:记录每一分后的总比分变化。
发球优势:统计每位运动员的发球局中赢得的分数比例。
破发点:记录每位运动员赢得和失去的破发点数量。
连续得分:运动员连续得分的次数,反映比赛势头。
回球成功率:根据返回深度和速度评估回球成功率。
运动员移动距离:反映体能和比赛中的活跃度。
模型设计
使用逻辑回归或随机森林等机器学习方法来评估每位运动员的表现。模型的输入是上述特征,输出是每位运动员的表现评分。
模型应用
选择具体的比赛数据应用模型,比较不同运动员的表现评分。
结果分析
根据模型的评分结果,分析哪位运动员在比赛中表现更好及其显示出的优势。
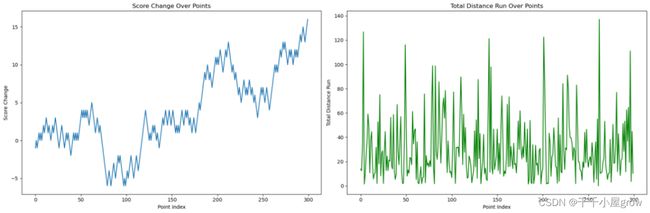
接下来,我们将开始实现这些步骤。首先进行数据预处理和特征提取。我们将从提供的比赛数据中提取关键特征。左图展示了比赛中每个得分点后选手之间比分差异的变化。这可以帮助我们理解比赛的势头和选手间的竞争状态。右图展示了比赛过程中两位选手总移动距离的变化,反映了选手的体能消耗和场上活跃度。
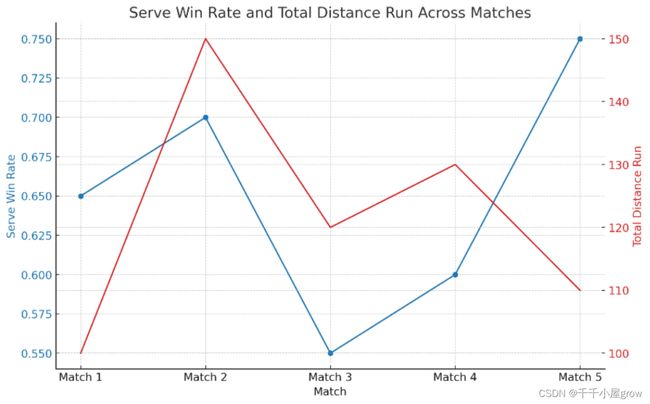
下图通过计算选手1在其发球局中赢得的分数比例,我们绘制了一个折线图来展示选手在不同round下的总共的移动距离以及得分比例。
###裙137540053
实例代码:
plt.figure(figsize=(8, 5))
# plt.scatter([202, 282, 362, 442, 522],[80630,173696,53430,32018,26663], color='black', linewidth=0 )
plt.plot(df['Contest number'], df['Number of reported results'] ,color='#1abc9c', label='Number of Reported results')
# plt.plot(df['Contest number'], df['Number in hard mode'] ,color='#1abc9c', label='Number of Reported results')
plt.rcParams['font.family'] = 'Times New Roman'
plt.grid()
plt.legend()
# plt.xlabel([202, 282, 362, 442, 522], ['2022/1/7','2022/3/28','2022/6/16','2022/9/4', '2022/11/23'])
plt.xticks([202, 282, 362, 442, 522], ['2022/1/7','2022/3/28','2022/6/16','2022/9/4', '2022/11/23'])
plt.xlabel('Time')
plt.ylabel('Number')
plt.title("Number of Reported Results Via Time")
plt.show()