完结,从零开始学python(十八)想成为一名APP逆向工程师,需要掌握那些技术点?
作为从零学python的最后一篇文章,我们来简单的回顾一下内容
1.编程语法
- 语法编程
- 并发编程
- 网络编程
- 多线程/多进程/协程
- 数据库编程
- MySQL
- Redis
- MongoDB
2.机器学习
3.全栈开发
4.数据分析
- Numpy+pandas+Matplotlib
- Hadoop
- Spark
5.爬虫工程师养成
- 采集功底
- 自动化和抓包
- 框架源码
- scrapy
- feapder
- 爬虫集群部署
- JS逆向

适用于零基础学习和进阶人群的python资源:
① 腾讯认证python完整项目实战教程笔记PDF
② 十几个大厂python面试专题PDF
③ python全套视频教程(零基础-高级进阶JS逆向)
④ 百个项目实战+源码+笔记
⑤ 编程语法-机器学习-全栈开发-数据分析-爬虫-APP逆向等全套项目+文档
APP逆向工程
一丶java语法编程
一.java环境搭建
作为一个APP逆向工程师,你需要搭建Java开发环境来进行Java语法编程。下面是详细的Java环境搭建步骤:
下载Java开发工具包(JDK):
下载适用于你的操作系统的JDK版本。选择适合你的操作系统和系统架构的版本,并下载安装文件。
安装JDK:
执行下载的JDK安装文件,并按照安装向导的指示进行安装。在安装过程中,你可以自定义安装路径,也可以使用默认路径。
配置环境变量(Windows系统):
- 打开“控制面板” -> “系统与安全” -> “系统”,点击左侧的“高级系统设置”。
- 在打开的对话框中,点击“环境变量”按钮。
- 在用户变量部分,点击“新建”按钮,添加以下两个环境变量:
- 变量名:JAVA_HOME,变量值:JDK的安装路径(例如:C:\Program Files\Java\jdk-11.0.12)
- 变量名:PATH,变量值:%JAVA_HOME%\bin
- 点击“确定”保存设置。
配置环境变量(macOS和Linux系统):
- 打开终端并编辑~/.bash_profile文件,可以使用任何文本编辑器。
- 添加以下行到文件末尾:
export JAVA_HOME=/Library/Java/JavaVirtualMachines/{jdk版本}/Contents/Home
export PATH=$JAVA_HOME/bin:$PATH
将{jdk版本}替换为你安装的JDK版本的文件夹名称(例如:jdk-11.0.12)。
- 保存文件并执行以下命令使配置生效:
source ~/.bash_profile
验证安装:
打开终端或命令行界面,输入以下命令检查是否成功安装和配置Java环境:
java -version
如果看到类似于以下输出的版本信息,则说明Java环境已成功搭建:
java version "11.0.12" 2021-07-20 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.12+8-LTS-237)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.12+8-LTS-237, mixed mode)
现在你已经成功搭建了Java开发环境,可以开始使用Java语言进行APP逆向工程的编程任务了。你可以使用Java开发工具(如Eclipse、IntelliJ IDEA等)来编写和运行Java程序。
二.java基础语法和数据类型
当进行APP逆向工程时,了解Java的基础语法和数据类型是非常重要的。以下是Java的基础语法和数据类型的详细解释:
标识符:在Java中,标识符是用来命名变量、类、方法等的名称。标识符必须以字母、下划线或美元符号开头,后面可以是字母、数字、下划线或美元符号的组合。
注释:注释用于向代码添加注解或解释。在Java中,有三种类型的注释:
- 单行注释:以双斜线(//)开头,注释内容在该行的末尾。
- 多行注释:以斜线加星号(/)开头,以星号加斜线(/)结尾,可以跨越多行。
- 文档注释:以斜线加两个星号(/**)开头,以星号加斜线(*/)结尾,用于生成文档。
关键字:Java有一些保留的关键字,用于表示特定的含义或功能。一些常用的关键字包括class、public、private、static、void等。
数据类型:Java中的数据类型分为两种:
- 基本数据类型:包括整数类型(byte、short、int、long)、浮点数类型(float、double)、字符类型(char)、布尔类型(boolean)。
- 引用数据类型:包括类、接口、数组等。
变量:在Java中,变量用于存储数据。声明变量时需要指定数据类型,然后可以给变量赋值。变量可以是基本数据类型或引用数据类型。
运算符:Java中有多种类型的运算符,包括算术运算符(+、-、*、/、%)、赋值运算符(=、+=、-=等)、比较运算符(==、!=、>、<等)、逻辑运算符(&&、||、!等)等。
控制流语句:Java提供了几种控制流语句,用于控制程序的执行流程。
- 条件语句:if语句、switch语句。
- 循环语句:for循环、while循环、do-while循环。
- 分支语句:break语句、continue语句、return语句。
数组:数组是一种可以容纳多个相同类型元素的数据结构。在Java中,数组的大小在创建时指定,并且不能改变。可以通过索引访问数组中的元素。
这些是Java的基础语法和数据类型的主要内容。熟悉这些概念可以帮助你理解和编写Java代码,包括在进行APP逆向工程时对Java代码的分析和修改。
三.java控制流程
Java控制流程是指程序在执行过程中,根据不同的条件或情况,选择不同的执行路径。Java中的控制流程主要包括条件语句和循环语句。
1.条件语句
条件语句用于根据不同的条件选择不同的执行路径。Java中的条件语句包括if语句、if-else语句、if-else if语句和switch语句。
if语句:
if语句用于判断一个条件是否成立,如果成立则执行一段代码块。
语法格式:
if (条件) {
// 执行代码块
}
示例代码:
int a = 10;
if (a > 5) {
System.out.println("a大于5");
}
if-else语句:
if-else语句用于判断一个条件是否成立,如果成立则执行一段代码块,否则执行另一段代码块。
语法格式:
if (条件) {
// 执行代码块1
} else {
// 执行代码块2
}
示例代码:
int a = 3;
if (a > 5) {
System.out.println("a大于5");
} else {
System.out.println("a小于等于5");
}
if-else if语句:
if-else if语句用于判断多个条件,如果第一个条件成立则执行第一个代码块,否则判断第二个条件,以此类推。
语法格式:
if (条件1) {
// 执行代码块1
} else if (条件2) {
// 执行代码块2
} else {
// 执行代码块3
}
示例代码:
int a = 3;
if (a > 5) {
System.out.println("a大于5");
} else if (a > 0) {
System.out.println("a大于0,小于等于5");
} else {
System.out.println("a小于等于0");
}
switch语句:
switch语句用于根据不同的条件选择不同的执行路径,与if-else if语句类似,但是switch语句只能判断整型、字符型和枚举类型。
语法格式:
switch (表达式) {
case 值1:
// 执行代码块1
break;
case 值2:
// 执行代码块2
break;
...
default:
// 执行代码块n
break;
}
示例代码:
int a = 2;
switch (a) {
case 1:
System.out.println("a等于1");
break;
case 2:
System.out.println("a等于2");
break;
default:
System.out.println("a不等于1或2");
break;
}
2.循环语句
循环语句用于重复执行一段代码块,Java中的循环语句包括for循环、while循环和do-while循环。
for循环:
for循环用于重复执行一段代码块,可以指定循环次数。
语法格式:
for (初始化; 条件; 更新) {
// 执行代码块
}
示例代码:
for (int i = 0; i < 5; i++) {
System.out.println("i的值为:" + i);
}
while循环:
while循环用于重复执行一段代码块,只要条件成立就一直执行。
语法格式:
while (条件) {
// 执行代码块
}
示例代码:
int i = 0;
while (i < 5) {
System.out.println("i的值为:" + i);
i++;
}
do-while循环:
do-while循环用于重复执行一段代码块,先执行一次代码块,然后判断条件是否成立,如果成立则继续执行,否则退出循环。
语法格式:
do {
// 执行代码块
} while (条件);
示例代码:
int i = 0;
do {
System.out.println("i的值为:" + i);
i++;
} while (i < 5);
四丶java数据类型
Java是一种强类型语言,这意味着在编写代码时必须指定变量的数据类型。Java中的数据类型可以分为两类:基本数据类型和引用数据类型。
1.基本数据类型
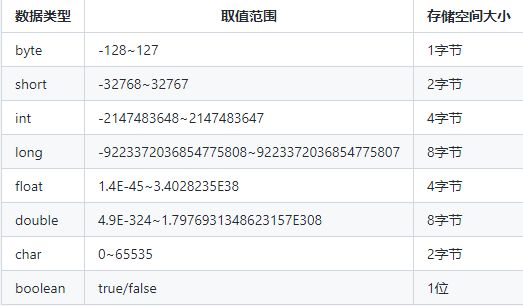
Java中的基本数据类型包括:
- 整型:byte、short、int、long
- 浮点型:float、double
- 字符型:char
- 布尔型:boolean
这些数据类型的取值范围和存储空间大小不同,具体如下:
2.引用数据类型
Java中的引用数据类型包括:
- 类
- 接口
- 数组
引用数据类型的变量存储的是对象的引用,而不是对象本身。对象本身存储在堆内存中,而引用存储在栈内存中。
3.自动类型转换和强制类型转换
在Java中,如果两个数据类型不同,可以进行自动类型转换或强制类型转换。
自动类型转换是指将一个数据类型的值赋给另一个数据类型的变量时,Java会自动将其转换为目标类型。例如,将一个int类型的值赋给一个double类型的变量时,Java会自动将int类型转换为double类型。
强制类型转换是指将一个数据类型强制转换为另一个数据类型。例如,将一个double类型的值强制转换为int类型时,需要使用强制类型转换符“()”。
4.字符串类型
Java中的字符串类型是引用数据类型,但是Java提供了一种特殊的语法来创建字符串,即使用双引号将一段文本括起来。例如:
String str = "Hello, world!";
字符串类型还提供了一些常用的方法,例如:
- length():返回字符串的长度
- charAt(int index):返回指定位置的字符
- substring(int beginIndex, int endIndex):返回指定范围内的子字符串
- equals(String str):比较两个字符串是否相等
5.数组类型
Java中的数组是一种引用数据类型,可以存储多个相同类型的值。数组的声明方式如下:
数据类型[] 数组名 = new 数据类型[数组长度];
例如,声明一个长度为5的int类型数组:
int[] arr = new int[5];
数组的访问方式是通过下标来访问,下标从0开始。例如,访问数组中的第一个元素:
int first = arr[0];
数组还提供了一些常用的方法,例如:
- length:返回数组的长度
- sort:对数组进行排序
- toString:将数组转换为字符串
五丶java数据结构
Java是一种面向对象的编程语言,因此它提供了许多数据结构来处理和组织数据。以下是Java中常用的数据结构:
-
数组(Array):数组是一组相同类型的数据元素的集合。它们在内存中是连续存储的,并且可以通过索引访问。Java中的数组可以是一维或多维的。
-
集合(Collection):集合是一组对象的容器,可以动态地增加或减少元素。Java中的集合框架包括List、Set和Map等。
-
列表(List):列表是一种有序的集合,可以包含重复的元素。Java中的ArrayList和LinkedList是常用的列表实现。
-
集(Set):集是一种不允许重复元素的集合。Java中的HashSet和TreeSet是常用的集实现。
-
映射(Map):映射是一种键值对的集合。Java中的HashMap和TreeMap是常用的映射实现。
-
栈(Stack):栈是一种后进先出(LIFO)的数据结构。Java中的Stack类实现了栈的基本操作。
-
队列(Queue):队列是一种先进先出(FIFO)的数据结构。Java中的LinkedList类实现了队列的基本操作。
-
树(Tree):树是一种层次结构,每个节点可以有多个子节点。Java中的TreeSet和TreeMap是基于树的集和映射实现。
-
图(Graph):图是一种由节点和边组成的数据结构。Java中没有内置的图实现,但可以使用第三方库来实现。
以上是Java中常用的数据结构,了解它们的特点和用法可以帮助我们更好地处理和组织数据。
六丶java面向对象
作为APP逆向工程师,理解Java的面向对象编程是至关重要的。面向对象编程(Object-Oriented Programming,简称OOP)是一种编程范式,它将程序中的对象作为基本单元,通过对象之间的交互来完成任务。以下是Java面向对象编程的详细解释:
-
类和对象:类是定义对象的蓝图或模板,而对象是类的实例。类中包含了对象的属性(字段/成员变量)和行为(方法/成员函数)。通过创建类的实例(对象),我们可以调用类中定义的方法来操作对象。
-
封装:封装是一种将数据和方法组合在一起的概念,目的是隐藏数据的具体实现细节并提供公共的接口访问数据。通过访问器(getter)和修改器(setter)方法,可以控制对对象内部数据的访问和修改。
-
继承:继承是指一个类(子类/派生类)可以继承另一个类(父类/基类)的属性和方法。子类可以使用父类中的方法,并且可以在其中添加新的属性和方法,或者修改父类的方法。继承有助于实现代码的重用和扩展。
-
多态:多态是指一个对象可以以多种形式出现。通过多态,可以使用父类类型的引用变量来引用子类的实例对象。多态允许调用相同的方法在不同的对象上产生不同的行为,提供了代码的灵活性和扩展性。
-
抽象类:抽象类是指不能被实例化的类,它定义了一组抽象的方法,子类必须实现这些方法才能实例化。抽象类提供了一种模板或约束,用于定义类的通用特性。
-
接口:接口是一种纯粹的抽象类,它只包含方法的声明而没有方法的实现。类可以实现一个或多个接口,从而获得接口中定义的方法。接口提供了一种行为契约,用于实现多态和代码的解耦。
-
构造方法:构造方法是一种特殊的方法,用于创建和初始化对象。它与类同名,并且没有返回类型。通过构造方法,可以设置对象的初始状态和属性。
-
成员变量和局部变量:成员变量是定义在类中的变量,可以被类的所有方法访问。局部变量是定义在方法中的变量,只能在方法内部访问。
通过理解和应用面向对象编程的概念,你可以更好地组织和设计代码,使其更容易理解、扩展和维护。这对于进行APP逆向工程和编写高质量的Java代码都是至关重要的。
七丶java继承关系链
在Java语言中,继承关系是面向对象编程的重要概念之一。继承关系形成一个类的层次结构,被称为继承关系链。让我详细解释一下Java继承关系链的相关概念:
-
类(Class):类是Java中基本的编程单元,用于定义对象的属性和方法。一个类可以作为另一个类的父类或超类,并可以被其他类继承。
-
父类(Superclass)和子类(Subclass):在继承关系中,父类是指被继承的类,子类是指继承父类的类。父类也称为超类或基类,子类也称为派生类。
-
继承(Inheritance):通过使用关键字extends,一个类可以继承另一个类的属性和方法。子类继承父类的特性,包括字段、方法和构造函数。继承实现了代码的重用和扩展。
-
单继承(Single Inheritance):Java中的类只支持单继承,即一个类只能有一个直接的父类。这是为了避免多继承可能引发的复杂性和冲突问题。
-
多层继承(Multilevel Inheritance):多层继承是指继承关系可以形成多个层次。一个类可以是另一个类的子类,同时作为其他类的父类,形成一个继承关系链。
-
覆盖(Override):子类可以通过定义相同的方法名和参数列表来覆盖父类中已有的方法。当调用子类对象的该方法时,将执行子类中定义的方法而不是父类中的方法。
-
调用父类方法(Superclass Method Invocation):子类可以使用super关键字来调用父类的方法。这通常用于子类想要在覆盖方法中使用父类的实现时。
-
抽象类(Abstract Class):抽象类是不能被实例化的类,它定义了一组抽象的方法。抽象类可以作为父类被其他类继承,子类必须实现抽象类中的抽象方法。
-
接口(Interface):接口是一种纯粹的抽象类,它只包含方法的声明而没有方法的实现。类可以实现一个或多个接口,从而获得接口中定义的方法。
通过继承关系链,我们可以建立不同类之间的层次结构,从而实现代码的重用和扩展。子类可以继承父类的属性和方法,并且可以添加新的属性和方法,或者覆盖父类的方法。这使得代码更加有组织,易于理解和维护。作为APP逆向工程师,了解和应用继承关系链将有助于您分析和修改Java代码。
八丶java包的概念
Java中的包(Package)是一种组织类和接口的机制,它将相关的类和接口组织在一起,以便更好地管理和使用。包可以看作是一个文件夹,其中包含了一组相关的类和接口。
Java中的包有以下几个作用:
-
避免命名冲突:Java中的包可以避免命名冲突,因为不同的包中可以有相同的类名。
-
组织类和接口:Java中的包可以将相关的类和接口组织在一起,方便管理和使用。
-
访问控制:Java中的包可以使用访问修饰符来控制类和接口的访问权限。
-
提供命名空间:Java中的包提供了命名空间,可以避免不同的类和接口之间的命名冲突。
Java中的包的命名规则是使用小写字母,多个单词之间使用点号(.)分隔,例如:com.example.mypackage。
在Java中,使用包的语法是在类的开头使用package语句来声明所属的包,例如:
package com.example.mypackage;
public class MyClass {
// 类的代码
}
在使用其他包中的类时,需要使用import语句来导入该类,例如:
import java.util.ArrayList;
public class MyClass {
public static void main(String[] args) {
ArrayList list = new ArrayList();
// 使用ArrayList类
}
}
需要注意的是,Java中的包是按照文件夹的形式组织的,因此包名和文件夹的名称要保持一致。例如,包名为com.example.mypackage的类应该存放在com/example/mypackage目录下的.java文件中。
NDK开发专题
一丶NDK数据类型
NDK(Native Development Kit)是Android提供的一种开发工具,可以让开发者使用C/C++语言编写Android应用程序。在NDK中,数据类型是非常重要的概念,下面详细介绍一下NDK中的数据类型。
1.基本数据类型
在NDK中,基本数据类型与C/C++语言中的基本数据类型相同,包括int、float、double、char等。这些数据类型在NDK中的使用方法与C/C++语言中的使用方法相同。
2.指针类型
指针类型在NDK中也是非常重要的数据类型,它可以指向任何类型的数据。在NDK中,指针类型的声明方式与C/C++语言中的声明方式相同,例如:
int *p;
3.结构体类型
结构体类型在NDK中也是非常常见的数据类型,它可以将多个不同类型的数据组合在一起。在NDK中,结构体类型的声明方式与C/C++语言中的声明方式相同,例如:
struct Person {
char name[20];
int age;
float height;
};
4.枚举类型
枚举类型在NDK中也是非常常见的数据类型,它可以将一组相关的常量组合在一起。在NDK中,枚举类型的声明方式与C/C++语言中的声明方式相同,例如:
enum Color {
RED,
GREEN,
BLUE
};
5.数组类型
数组类型在NDK中也是非常常见的数据类型,它可以将多个相同类型的数据组合在一起。在NDK中,数组类型的声明方式与C/C++语言中的声明方式相同,例如:
int arr[10];
6.指向函数的指针类型
指向函数的指针类型在NDK中也是非常常见的数据类型,它可以指向任何类型的函数。在NDK中,指向函数的指针类型的声明方式与C/C++语言中的声明方式相同,例如:
int (*p)(int, int);
以上就是NDK中常见的数据类型,开发者在使用NDK进行开发时,需要熟练掌握这些数据类型的使用方法。
二丶java反射和NDK结合
Java反射和NDK结合可以实现一些高级的功能,比如在NDK层面调用Java类的方法或者获取Java类的属性值。下面详细介绍一下Java反射和NDK结合的实现方法。
1.在Java层面定义需要调用的方法或属性
首先,在Java层面定义需要调用的方法或属性,例如:
public class Test {
private int value;
public Test(int value) {
this.value = value;
}
public int getValue() {
return value;
}
public void setValue(int value) {
this.value = value;
}
}
2.使用反射获取Java类的Class对象
在NDK层面,需要使用反射获取Java类的Class对象,例如:
jclass clazz = env->FindClass("com/example/Test");
3.获取Java类的构造方法
使用反射获取Java类的构造方法,例如:
jmethodID constructor = env->GetMethodID(clazz, "", "(I)V");
4.创建Java对象
使用反射创建Java对象,例如:
jobject obj = env->NewObject(clazz, constructor, 10);
5.获取Java类的方法
使用反射获取Java类的方法,例如:
jmethodID getValueMethod = env->GetMethodID(clazz, "getValue", "()I");
jmethodID setValueMethod = env->GetMethodID(clazz, "setValue", "(I)V");
6.调用Java类的方法
使用反射调用Java类的方法,例如:
int value = env->CallIntMethod(obj, getValueMethod);
env->CallVoidMethod(obj, setValueMethod, 20);
7.获取Java类的属性值
使用反射获取Java类的属性值,例如:
jfieldID valueField = env->GetFieldID(clazz, "value", "I");
int value = env->GetIntField(obj, valueField);
8.设置Java类的属性值
使用反射设置Java类的属性值,例如:
env->SetIntField(obj, valueField, 30);
三丶JNI调用java函数对象和访问java方法和类
一.JNI调用java函数对象
在JNI中,可以通过JNIEnv对象调用Java中的方法。JNIEnv对象是一个指向JNI环境的指针,它提供了一组函数,可以用来访问Java对象和调用Java方法。
在调用Java方法之前,需要先获取Java方法的ID。可以通过调用JNIEnv对象的GetMethodID函数来获取Java方法的ID。GetMethodID函数的参数包括Java类的对象、Java方法的名称和Java方法的签名。
获取到Java方法的ID之后,就可以通过调用JNIEnv对象的CallXXXMethod函数来调用Java方法了。其中,XXX表示Java方法的返回值类型,可以是Int、Boolean、Object等。
下面是一个JNI调用Java方法的示例代码:
JNIEXPORT void JNICALL Java_com_example_test_TestJNI_callJavaMethod(JNIEnv *env, jobject obj) {
jclass clazz = env->GetObjectClass(obj);
jmethodID methodId = env->GetMethodID(clazz, "javaMethod", "()V");
env->CallVoidMethod(obj, methodId);
}
在上面的代码中,首先通过GetObjectClass函数获取Java类的对象,然后通过GetMethodID函数获取Java方法的ID,最后通过CallVoidMethod函数调用Java方法。
需要注意的是,JNI调用Java方法时,需要保证Java方法的访问权限是public。否则,在调用Java方法时会抛出IllegalAccessException异常。
二.访问java方法和类
作为APP逆向工程师,掌握Java方法和类的概念是非常重要的。下面我将详细解释Java中方法和类的相关内容:
1.方法(Method):
- 方法是一段可重用的代码块,用于执行特定的动作或完成特定的任务。
- 方法包含方法名、参数列表(可选)、返回类型和方法体。
- 方法名用于唯一识别方法,参数列表是传递给方法的值,返回类型指定了方法返回的值类型。
- 方法可以接受参数并返回一个值,也可以是无参的无返回值方法。
- 方法通过调用(使用方法名和参数列表)来执行。
2.类(Class):
- 类是用于创建对象的模板或蓝图,它定义了对象的属性和行为。
- 类是Java中的基本编程单元,所有对象都是由类实例化而来。
- 类由字段(成员变量)和方法(成员函数)组成。
- 字段是类中的变量,用于存储对象的状态信息。
- 方法是类中定义的行为,用于操作对象的状态。
3.对象(Object):
- 对象是类的实例,通过使用关键字new和类的构造方法来创建。
- 对象具有类定义的属性和行为,可以访问和操作对象的字段和方法。
- 对象可以独立地存在、具有唯一的状态,并且可以与其他对象进行交互。
4.构造方法(Constructor):
- 构造方法是一种特殊的方法,用于创建和初始化对象。
- 构造方法具有与类相同的名称,但没有返回类型。
- 构造方法在使用new关键字创建对象时被调用,用于初始化对象的状态。
- Java中可以定义多个构造方法,通过不同的参数列表来区分。
5.静态方法(Static Method):
- 静态方法是类级别的方法,不需要创建类的实例即可调用。
- 静态方法使用关键字static修饰,并且只能访问静态成员变量和调用其他静态方法。
- 静态方法通常用于实用功能和工具方法,不需要依赖于特定的对象。
6.封装(Encapsulation):
- 封装是将数据和方法组合在一个单元中,用于数据隐藏和访问控制。
- 封装通过使用访问修饰符(如private、public等)来限制对类的字段和方法的访问。
7.继承(Inheritance):
- 继承是一种面向对象的概念,允许一个类继承另一个类的属性和方法。
- 继承通过使用关键字extends来实现,子类继承父类的特性并可以添加自己的功能。
- 继承提供了代码重用和扩展的机制,实现了类之间的层次结构。
8.多态(Polymorphism):
- 多态是面向对象编程的一个重要概念,允许使用一个对象以多种不同的方式呈现。
- 多态通过使用父类类型的引用变量来引用子类的对象来实现。
- 多态提供了灵活性和可扩展性,通过方法的动态绑定,可以在运行时决定调用哪个方法。
掌握方法和类的概念是进行APP逆向工程的关键。了解如何创建和使用方法,如何定义和实例化类以及如何使用封装、继承和多态等概念,将使您能够更好地分析和修改Java代码。
三丶Hook框架专题
Frida Hook
Frida是一款强大的动态分析工具,可以用于APP逆向工程、安全测试、漏洞挖掘等方面。本文将从Frida开发和调试环境搭建、Frida构造数组-对象、Frida与脱壳、Frida Hook壳与插件dex、Frida编译源码、Frida检测反调试等六个方向展开详细讲解。
一、Frida开发和调试环境搭建
1.安装Frida
Frida支持Windows、macOS、Linux等多个平台,可以在官网下载对应平台的安装包进行安装。安装完成后,可以在命令行中输入frida -version命令来检查Frida是否安装成功。
2.安装Frida-Server
Frida-Server是Frida的核心组件,它运行在目标设备上,与Frida客户端进行通信。在使用Frida进行APP逆向工程时,需要将Frida-Server安装到目标设备上。Frida-Server的安装方法可以参考官方文档。
3.安装Frida-Tools
Frida-Tools是Frida的一组工具,包括frida-ps、frida-trace、frida-discover等。这些工具可以帮助我们更方便地使用Frida进行动态分析。可以在命令行中输入pip install frida-tools命令来安装Frida-Tools。
二、Frida构造数组-对象
在使用Frida进行APP逆向工程时,经常需要构造一些数组和对象来进行数据操作。下面介绍一些常用的构造方法。
1.构造数组
可以使用Frida提供的Java.array()方法来构造数组。例如,构造一个长度为3的int数组:
var arr = Java.array("int", [1, 2, 3]);
2.构造对象
可以使用Frida提供的Java.use()方法来构造对象。例如,构造一个java.lang.String对象:
var str = Java.use("java.lang.String").$new("hello");
三、Frida与脱壳
在进行APP逆向工程时,经常需要对APP进行脱壳操作,以便更好地进行分析。下面介绍一些常用的脱壳方法。
1.使用Frida-Objection进行脱壳
Frida-Objection是一款基于Frida的移动设备安全测试框架,可以用于APP脱壳、数据泄露检测、SSL Pinning绕过等方面。可以在命令行中输入pip install objection命令来安装Frida-Objection。
使用Frida-Objection进行脱壳的步骤如下:
- 1)启动Frida-Server
在目标设备上启动Frida-Server。
- 2)启动Frida-Objection
在命令行中输入objection explore命令来启动Frida-Objection。
- 3)进入APP
在Frida-Objection的命令行中输入android jailbreak命令来进入APP。
- 4)脱壳
在Frida-Objection的命令行中输入dump -h命令来进行脱壳操作。
2.使用Frida进行脱壳
可以使用Frida提供的Java.perform()方法来进行脱壳操作。下面是一个简单的脱壳脚本示例:
Java.perform(function () {
var BaseDexClassLoader = Java.use("dalvik.system.BaseDexClassLoader");
var DexFile = Java.use("dalvik.system.DexFile");
var PathClassLoader = Java.use("dalvik.system.PathClassLoader");
var DexClassLoader = Java.use("dalvik.system.DexClassLoader");
var File = Java.use("java.io.File");
var System = Java.use("java.lang.System");
var Runtime = Java.use("java.lang.Runtime");
var Process = Java.use("android.os.Process");
var String = Java.use("java.lang.String");
var Arrays = Java.use("java.util.Arrays");
var classLoader = Java.classFactory.loader;
var dexFile = DexFile.$new("/data/app/com.example.app-1/base.apk");
var dexElements = BaseDexClassLoader.getDeclaredField("dexElements");
dexElements.setAccessible(true);
var elements = dexElements.get(classLoader);
var newElements = Arrays.copyOf(elements, elements.length);
var dex = DexFile.$new(File.$new("/data/data/com.example.app/files/1.dex"));
var newElement = DexClassLoader.$new("/data/data/com.example.app/files", null, null, classLoader).findClass("com.example.app.MainActivity").getDeclaredMethod("main", String.arrayOf(String));
newElements[newElements.length - 1] = newElement.invoke(null, null);
dexElements.set(classLoader, newElements);
System.loadLibrary("native-lib");
var handle = Runtime.getRuntime().exec("su");
var outputStream = handle.getOutputStream();
outputStream.write(("kill " + Process.myPid() + "\n").getBytes());
outputStream.flush();
outputStream.close();
});
四、Frida Hook壳与插件dex
在进行APP逆向工程时,经常需要Hook一些壳和插件dex,以便更好地进行分析。下面介绍一些常用的Hook方法。
1.Hook壳
可以使用Frida提供的Java.use()方法来Hook壳。下面是一个简单的Hook壳脚本示例:
Java.perform(function () {
var BaseDexClassLoader = Java.use("dalvik.system.BaseDexClassLoader");
var DexFile = Java.use("dalvik.system.DexFile");
var PathClassLoader = Java.use("dalvik.system.PathClassLoader");
var DexClassLoader = Java.use("dalvik.system.DexClassLoader");
var File = Java.use("java.io.File");
var System = Java.use("java.lang.System");
var Runtime = Java.use("java.lang.Runtime");
var Process = Java.use("android.os.Process");
var String = Java.use("java.lang.String");
var Arrays = Java.use("java.util.Arrays");
var classLoader = Java.classFactory.loader;
var dexFile = DexFile.$new("/data/app/com.example.app-1/base.apk");
var dexElements = BaseDexClassLoader.getDeclaredField("dexElements");
dexElements.setAccessible(true);
var elements = dexElements.get(classLoader);
var newElements = Arrays.copyOf(elements, elements.length);
var dex = DexFile.$new(File.$new("/data/data/com.example.app/files/1.dex"));
var newElement = DexClassLoader.$new("/data/data/com.example.app/files", null, null, classLoader).findClass("com.example.app.MainActivity").getDeclaredMethod("main", String.arrayOf(String));
newElements[newElements.length - 1] = newElement.invoke(null, null);
dexElements.set(classLoader, newElements);
System.loadLibrary("native-lib");
var handle = Runtime.getRuntime().exec("su");
var outputStream = handle.getOutputStream();
outputStream.write(("kill " + Process.myPid() + "\n").getBytes());
outputStream.flush();
outputStream.close();
});
2.Hook插件dex
可以使用Frida提供的Java.use()方法来Hook插件dex。下面是一个简单的Hook插件dex脚本示例:
Java.perform(function () {
var classLoader = Java.classFactory.loader;
var dexFile = Java.use("dalvik.system.DexFile").$new("/data/data/com.example.app/files/1.dex");
var dexElements = Java.cast(classLoader, Java.use("dalvik.system.BaseDexClassLoader")).pathList.dexElements;
var newElements = Java.array("dalvik.system.DexFile$Element", [dexFile.entries()[0]]);
var elements = Java.array("dalvik.system.DexFile$Element", dexElements);
var allElements = Java.array("dalvik.system.DexFile$Element", [newElements[0], elements[0]]);
Java.cast(classLoader, Java.use("dalvik.system.BaseDexClassLoader")).pathList.dexElements = allElements;
});
五、Frida编译源码
在进行APP逆向工程时,经常需要编译一些源码,以便更好地进行分析。下面介绍一些常用的编译方法。
1.使用dex2jar进行编译
dex2jar是一款将dex文件转换为jar文件的工具,可以用于将APP的dex文件转换为可读的jar文件。可以在命令行中输入dex2jar.sh命令来使用dex2jar进行编译。
2.使用apktool进行编译
apktool是一款反编译和重新打包APK的工具,可以用于对APP进行反编译和重新打包。可以在命令行中输入apktool d命令来对APP进行反编译,输入apktool b命令来重新打包APP。
六、Frida检测反调试
在进行APP逆向工程时,经常需要检测APP是否被反调试。下面介绍一些常用的检测方法。
1.Hook反调试方法
可以使用Frida提供的Java.use()方法来Hook反调试方法。下面是一个简单的Hook反调试方法脚本示例:
Java.perform(function () {
var Debug = Java.use("android.os.Debug");
Debug.isDebuggerConnected.implementation = function () {
return false;
};
});
2.Hook反调试变量
可以使用Frida提供的Java.use()方法来Hook反调试变量。下面是一个简单的Hook反调试变量脚本示例:
Java.perform(function () {
var ActivityThread = Java.use("android.app.ActivityThread");
ActivityThread.currentApplication.implementation = function () {
var app = this.currentApplication();
var packageName = app.getPackageName();
if (packageName.indexOf("com.example.app") != -1) {
return null;
} else {
return app;
}
};
});
以上就是Frida HOOk专题的详细讲解,希望对APP逆向工程爱好者有所帮助。
APP壳处理
一丶APP加固原理讲解
APP加固是指对移动应用程序进行安全性加固处理,以提高其防护能力,防止被攻击者进行逆向工程、篡改、数据泄露等恶意行为。下面是APP加固的原理详解:
-
代码混淆:代码混淆是通过对源代码进行修改和优化,使得代码结构和逻辑变得复杂和难以理解,从而增加攻击者对应用程序的逆向分析难度。通过重命名变量和函数名、添加冗余代码、修改控制流程等手段,使得攻击者很难理解代码的含义和执行流程,从而降低逆向工程的成功率。
-
加密保护:加密保护是将敏感数据或关键代码进行加密处理,以防止攻击者直接获取和修改数据。常见的加密手段包括对字符串、配置文件、算法、网络通信等进行加密处理,使用对称加密或非对称加密算法来保护数据的机密性和完整性。
-
安全存储:安全存储是指将应用程序的敏感数据(如用户凭证、密钥、证书等)存储在加密容器中,防止被恶意应用或攻击者获取。加固工具可以提供安全存储功能,对敏感数据进行加密处理,并使用密钥保护数据的安全。
-
反调试与反动态分析:为了防止攻击者对应用程序进行调试和动态分析以获取关键信息,加固工具可以采用反调试和反动态分析的技术手段。例如,检测调试器的存在、监控运行环境的变化、阻止动态加载库的注入等方法,来防止应用程序被攻击者分析和修改。
-
安全认证与防篡改:为了确保应用程序的合法性和完整性,加固工具可以通过数字签名、摘要校验、代码完整性校验等方式进行安全认证。这些技术可以防止应用程序被篡改、植入恶意代码或被恶意应用替换。
-
运行时保护:针对应用程序在运行过程中的安全问题,加固工具可以提供运行时保护机制。例如,检测和阻止内存溢出、缓冲区溢出、代码注入、动态加载库的非法调用等运行时攻击行为,以提高应用程序的安全性。
需要注意的是,虽然APP加固可以提高应用程序的安全性,但并不能完全消除所有的安全风险。攻击者可能利用高级的逆向工程技术和漏洞来攻击加固后的应用程序。因此,开发人员和安全团队应综合使用多种安全技术和策略,以实现全面的应用程序安全保护。
二丶如何识别APP是否加壳
要识别一个APP是否加壳,可以考虑以下几个方法:
-
静态分析:通过对APP进行静态分析,查看APP的文件结构和内容,可以初步判断是否存在加壳情况。加壳通常会在原始二进制文件中插入一段代码用于解壳,因此可以尝试查找类似解壳代码的特征。
-
动态调试:使用调试工具对APP进行动态调试,观察其行为和运行过程,可以获取更多的信息来判断是否加壳。例如,检测是否有解壳行为、查看内存中的解壳代码、监控应用程序加载的动态库等。
-
反编译分析:将APP进行反编译,还原出源代码或近似源代码,可以通过分析反编译后的代码来判断是否经过加壳处理。加壳工具通常会在代码中插入一些特殊的指令和函数调用,或者对代码进行重写、重构,这些都可以通过反编译分析来判断。
-
使用专用工具:有一些专门用于检测和识别加壳的工具可以辅助进行判断。例如,AndroGuard、Frida、IDA Pro等工具都具有一定的能力来分析和识别加壳情况。
需要注意的是,加壳技术不断发展和演进,新的加壳方式可能会绕过某些常规的识别方法。因此,识别加壳是一个持续的挑战,需要结合多种方法和工具,并不依赖于单一的判断依据。
三丶frida-dump脱壳技巧
Frida-dump是基于Frida框架开发的一种用于脱壳(dump)加壳应用程序的工具。它可以在运行时对应用程序进行动态注入,绕过加固防护措施,提取应用程序的解密后的内存镜像。下面是对Frida-dump脱壳技巧的详细解释:
-
Frida环境搭建:首先需要在计算机上安装Frida框架,并配置好运行环境。具体可以参考Frida官方文档提供的安装和配置指南。
-
定位加固点:在使用Frida-dump之前,需要了解目标应用程序所使用的加固方案。对于不同的加固方案,可能需要使用特定的Frida脚本来绕过保护机制。对于常见的加固方案如DEX加密、函数解密等,可以通过静态分析或调试等手段来确认加固点的位置。
-
编写Frida脚本:根据目标应用程序的加固方案,可以编写自定义的Frida脚本,用于在应用程序运行时定位和绕过加固点。Frida脚本使用JavaScript编写,可以利用Frida提供的API来进行代码注入和动态调试。
-
动态注入和脱壳:使用编写好的Frida脚本,运行目标应用程序,并将脚本注入到应用程序的进程中。脚本会在应用程序运行时自动执行,通过监控内存访问来定位解密后的内存区域,并将其导出到本地文件系统中,完成脱壳操作。
需要注意的是,使用Frida-dump进行脱壳是一项高级技术,需要对移动应用程序的内部结构和加固机制有一定的了解。此外,脱壳行为可能涉及到法律和道德问题,因此应谨慎使用,并仅用于合法的安全评估和研究目的。此外,使用Frida-dump等脱壳工具进行脱壳操作也有可能触发应用程序自身的反调试和反破解机制,导致脱壳失败或应用程序异常终止。
smail语法
当进行APP逆向工程时,了解smali语法是非常重要的。下面我将详细介绍smali语法中的数据类型、常量声明语法、方法函数的声明、构造函数的声明、静态代码块的声明以及基于接口的调用。
一丶数据类型:
smali支持以下数据类型:
- Z: boolean类型
- B: byte类型
- S: short类型
- C: char类型
- I: int类型
- J: long类型
- F: float类型
- D: double类型
L 类名 ;: 引用类型
例如,I 表示int类型,Ljava/lang/String; 表示引用类型为 java.lang.String。
二丶常量声明语法:
常量声明使用 const 指令,语法如下:
const 寄存器, 常量值
例如,const v0, 10 表示将寄存器 v0 设置为整数常量值 10。
三丶方法函数的声明:
方法函数的声明使用 method 关键字,语法如下:
.method 修饰符 返回类型 方法名(参数列表) [异常列表]
方法体
.end method
修饰符包括:public、private、protected、abstract、static 等。
返回类型可以是任意的数据类型,使用上述提到的数据类型表示。
参数列表使用逗号分隔,每个参数由类型和变量名组成。
例如,
.method public static add(II)I
...
.end method
表示一个名为 add 的公开静态方法,接受两个 int 类型的参数,并返回一个 int 类型的值。
四丶构造函数的声明:
构造函数的声明使用 constructor 关键字,语法如下:
.constructor 修饰符(参数列表) [异常列表]
构造函数体
.end constructor
构造函数和方法函数的声明类似,但没有返回类型。
例如,
.constructor public ()V
...
.end constructor
表示一个公开的无参数构造函数。
五丶静态代码块的声明:
静态代码块的声明使用 clinit 关键字,语法如下:
.clinit
静态代码块体
.end clinit
静态代码块在类加载时执行,并且只会执行一次。
例如,
.clinit
# 执行静态代码块的操作
.end clinit
表示一个静态代码块。
六丶基于接口的调用:
在smali中,使用 invoke-interface 指令来调用接口的方法。语法如下:
invoke-interface {参数列表}, 接口类型->方法签名
其中,参数列表 是传递给方法的参数,接口类型 是要调用的接口类型,方法签名 是要调用的方法的描述符。
例如,
invoke-interface {v0}, Ljava/util/Iterator;->next()Ljava/lang/Object;
表示调用 java.util.Iterator 接口的 next 方法。
这些是smali语法中关于数据类型、常量声明、方法函数声明、构造函数声明、静态代码块声明和基于接口的调用的详细介绍。通过理解这些语法规则,你可以更好地分析和修改逆向工程中的smali代码。记住,smali语法是庞大而复杂的,需要不断实践和探索才能熟练掌握。
APP RPC专题
一丶frida rpc插件编写
Frida是一款强大的动态分析工具,可以用于对移动应用程序进行逆向分析和调试。其中,RPC(Remote Procedure Call)是Frida的一个重要功能,可以让我们在Frida客户端和Frida服务器之间进行通信,从而实现更加灵活和高效的动态分析。
在本文中,我们将介绍如何编写Frida RPC插件,以便在Frida客户端和Frida服务器之间进行通信。
1.创建Frida RPC插件
首先,我们需要创建一个Frida RPC插件。在Frida中,RPC插件是一个JavaScript文件,可以通过Frida客户端和Frida服务器之间的RPC通信进行加载和执行。
下面是一个简单的Frida RPC插件示例:
rpc.exports = {
add: function (a, b) {
return a + b;
},
sub: function (a, b) {
return a - b;
}
};
在这个示例中,我们定义了两个函数add和sub,它们分别实现了加法和减法运算。这些函数可以通过Frida客户端和Frida服务器之间的RPC通信进行调用。
2.加载Frida RPC插件
一旦我们创建了Frida RPC插件,我们就可以将其加载到Frida客户端和Frida服务器之间进行通信。在Frida客户端中,我们可以使用以下代码加载Frida RPC插件:
const rpc = new frida.Rpc(peer);
const plugin = rpc.use("path/to/plugin.js");
在这个示例中,我们首先创建了一个Frida RPC对象rpc,然后使用use方法加载了Frida RPC插件。peer参数指定了Frida服务器的地址和端口号。
3.调用Frida RPC插件
一旦我们加载了Frida RPC插件,我们就可以通过Frida客户端和Frida服务器之间的RPC通信调用其中定义的函数。在Frida客户端中,我们可以使用以下代码调用Frida RPC插件中的函数:
const result = await plugin.add(1, 2);
console.log(result);
在这个示例中,我们调用了Frida RPC插件中的add函数,并传递了两个参数1和2。调用结果将被存储在result变量中,并打印到控制台上。
4.总结
在本文中,我们介绍了如何编写Frida RPC插件,并在Frida客户端和Frida服务器之间进行通信。通过使用Frida RPC插件,我们可以实现更加灵活和高效的动态分析,从而更好地理解和保护移动应用程序。
二丶使用frida远程调用java代码
在使用Frida进行远程调用Java代码之前,需要先了解一些基本概念和步骤。
1.什么是Frida?
Frida是一款基于JavaScript的动态代码注入工具,可以用于对Android和iOS应用进行动态分析和修改。Frida可以在运行时修改应用程序的行为,包括函数调用、参数传递、返回值等。
2.什么是RPC?
RPC(Remote Procedure Call)是一种远程过程调用协议,可以让客户端调用远程服务器上的函数,就像调用本地函数一样。RPC可以让应用程序在不同的计算机上进行通信,实现分布式计算。
3.如何使用Frida进行RPC?
Frida提供了一个RPC机制,可以让JavaScript代码在本地和远程设备之间进行通信。通过RPC,可以在本地设备上编写JavaScript代码,然后在远程设备上执行该代码,实现远程调用Java代码的功能。
下面是使用Frida进行远程调用Java代码的详细步骤:
- 在本地设备上编写JavaScript代码,实现远程调用Java代码的功能。例如,可以使用Java.perform()方法获取Java虚拟机实例,并调用Java类的方法。
Java.perform(function() {
var MainActivity = Java.use("com.example.MainActivity");
MainActivity.sayHello.implementation = function() {
console.log("Hello from Frida!");
return this.sayHello();
}
});
-
将JavaScript代码保存为一个文件,例如rpc.js。
-
在远程设备上安装Frida,并启动Frida服务。可以使用以下命令启动Frida服务:
frida-server -l 0.0.0.0
-
在远程设备上启动目标应用程序,并记录应用程序的进程ID。
-
在本地设备上使用Frida命令行工具连接到远程设备,并加载JavaScript代码。可以使用以下命令连接到远程设备:
frida -U -f com.example.app -l rpc.js
其中,com.example.app是目标应用程序的包名,rpc.js是保存JavaScript代码的文件名。
- 在本地设备上执行JavaScript代码,实现远程调用Java代码的功能。可以使用以下命令在Frida控制台中执行JavaScript代码:
rpc.exports.sayHello();
其中,sayHello()是在JavaScript代码中定义的函数名。
通过以上步骤,就可以使用Frida进行远程调用Java代码了。需要注意的是,Frida的RPC机制只能在本地和远程设备之间进行通信,不能在不同的远程设备之间进行通信。
三丶sekiro框架源码拆解
Sekiro框架是一个基于Netty和SpringBoot的远程调用框架,它可以实现跨进程、跨平台的远程调用。在使用Sekiro框架时,我们需要编写服务端和客户端的代码,其中服务端需要实现SekiroServer接口,客户端需要实现SekiroClient接口。
下面我们来拆解一下Sekiro框架的源码,了解它是如何实现远程调用的。
1.SekiroServer
SekiroServer是Sekiro框架的服务端接口,它定义了如下方法:
public interface SekiroServer {
void start() throws Exception;
void stop() throws Exception;
void registerHandler(String uri, SekiroRequestHandler handler);
}
其中,start()方法用于启动服务端,stop()方法用于停止服务端,registerHandler()方法用于注册请求处理器。
2.SekiroRequestHandler
SekiroRequestHandler是Sekiro框架的请求处理器接口,它定义了如下方法:
public interface SekiroRequestHandler {
void handle(SekiroRequest sekiroRequest, SekiroResponse sekiroResponse);
}
其中,handle()方法用于处理请求,并将处理结果写入响应中。
3.SekiroClient
SekiroClient是Sekiro框架的客户端接口,它定义了如下方法:
public interface SekiroClient {
void start() throws Exception;
void stop() throws Exception;
SekiroResponse invokeSync(String uri, SekiroRequest sekiroRequest) throws Exception;
}
其中,start()方法用于启动客户端,stop()方法用于停止客户端,invokeSync()方法用于同步调用远程服务。
4.SekiroRequest
SekiroRequest是Sekiro框架的请求对象,它包含了请求的URI、请求参数等信息。
5.SekiroResponse
SekiroResponse是Sekiro框架的响应对象,它包含了响应的状态码、响应数据等信息。
6.SekiroServerHandler
SekiroServerHandler是Sekiro框架的服务端处理器,它继承了Netty的SimpleChannelInboundHandler类,用于处理客户端请求。
在SekiroServerHandler中,我们可以看到如下代码:
@Override
protected void channelRead0(ChannelHandlerContext ctx, HttpObject msg) throws Exception {
if (msg instanceof FullHttpRequest) {
FullHttpRequest request = (FullHttpRequest) msg;
String uri = request.uri();
if (uri.startsWith("/api/")) {
handleHttpRequest(ctx, request);
} else {
ctx.fireChannelRead(msg);
}
} else {
ctx.fireChannelRead(msg);
}
}
这段代码用于判断请求的URI是否以“/api/”开头,如果是,则调用handleHttpRequest()方法处理请求,否则将请求传递给下一个处理器。
在handleHttpRequest()方法中,我们可以看到如下代码:
SekiroRequest sekiroRequest = SekiroRequestParser.parse(request);
SekiroResponse sekiroResponse = new SekiroResponse();
sekiroResponse.setRequestId(sekiroRequest.getRequestId());
sekiroResponse.setVersion(sekiroRequest.getVersion());
sekiroResponse.setStatusCode(200);
sekiroResponse.setContentType("application/json;charset=UTF-8");
try {
SekiroRequestHandler handler = handlerMap.get(sekiroRequest.getUri());
if (handler != null) {
handler.handle(sekiroRequest, sekiroResponse);
} else {
sekiroResponse.setStatusCode(404);
sekiroResponse.setContent("{\"message\":\"No handler found for uri: " + sekiroRequest.getUri() + "\"}");
}
} catch (Exception e) {
sekiroResponse.setStatusCode(500);
sekiroResponse.setContent("{\"message\":\"" + e.getMessage() + "\"}");
}
这段代码用于解析请求,创建响应对象,并根据请求的URI查找对应的请求处理器,如果找到,则调用请求处理器处理请求,否则返回404错误。
7.SekiroClientHandler
SekiroClientHandler是Sekiro框架的客户端处理器,它继承了Netty的SimpleChannelInboundHandler类,用于处理服务端响应。
在SekiroClientHandler中,我们可以看到如下代码:
@Override
protected void channelRead0(ChannelHandlerContext ctx, HttpObject msg) throws Exception {
if (msg instanceof FullHttpResponse) {
FullHttpResponse response = (FullHttpResponse) msg;
String content = response.content().toString(CharsetUtil.UTF_8);
SekiroResponse sekiroResponse = JSON.parseObject(content, SekiroResponse.class);
if (sekiroResponse.getStatusCode() == 200) {
promise.setSuccess(sekiroResponse);
} else {
promise.setFailure(new SekiroException(sekiroResponse.getStatusCode(), sekiroResponse.getContent()));
}
} else {
ctx.fireChannelRead(msg);
}
}
这段代码用于判断响应的状态码是否为200,如果是,则将响应转换为SekiroResponse对象,并将其设置为Promise的成功结果,否则将响应内容作为异常信息,设置为Promise的失败结果。
通过以上代码的分析,我们可以了解到Sekiro框架是如何实现远程调用的。在服务端,它通过Netty接收客户端请求,并根据请求的URI查找对应的请求处理器,然后调用请求处理器处理请求,并将处理结果写入响应中。在客户端,它通过Netty发送请求到服务端,并等待服务端的响应,然后将响应转换为SekiroResponse对象,并将其设置为Promise的成功结果或失败结果。
适用于零基础学习和进阶人群的python资源:
① 腾讯认证python完整项目实战教程笔记PDF
② 十几个大厂python面试专题PDF
③ python全套视频教程(零基础-高级进阶JS逆向)
④ 百个项目实战+源码+笔记
⑤ 编程语法-机器学习-全栈开发-数据分析-爬虫-APP逆向等全套项目+文档