猿人学2022安卓逆向对抗比赛第一题分析
整体的笔记为自己分析的流程,大佬勿喷
第一步 准备工具
- charles 抓包工具
- pixelxl 真机
- jadx
- 本机安装 python 和 frida
第二步 安装app 查壳 和 抓包
通过 GDA 可以 了解到 app 没有任何的壳
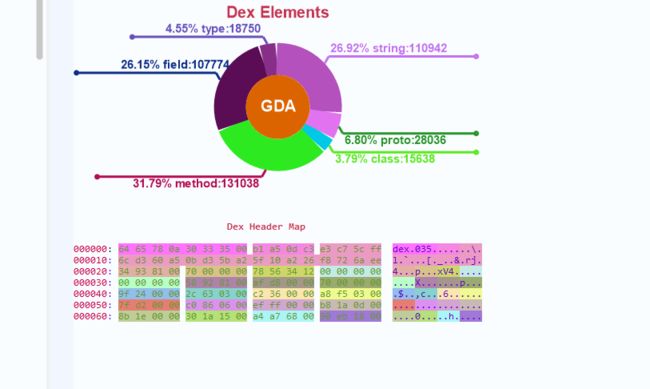
防止app 有可能不走代理,所以通过 charles + postern 进行 sock转发
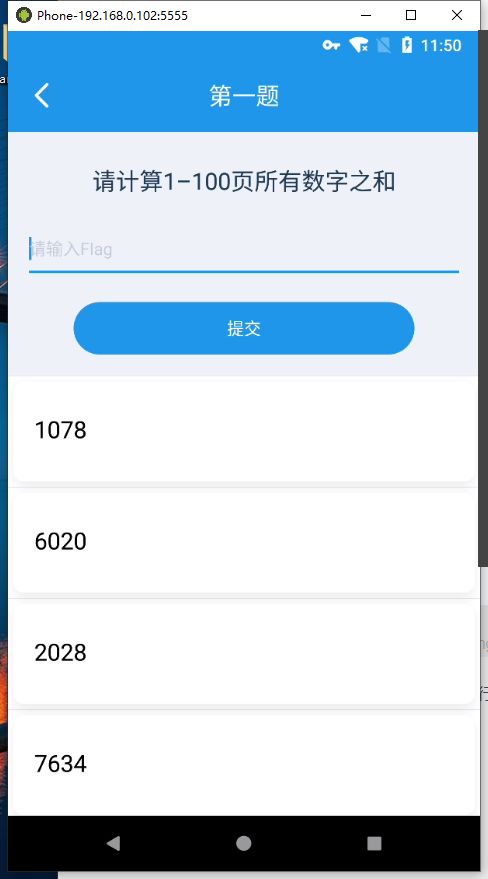
通过 注册后 进入 第一题
** 计算1~100页所有数字之和**
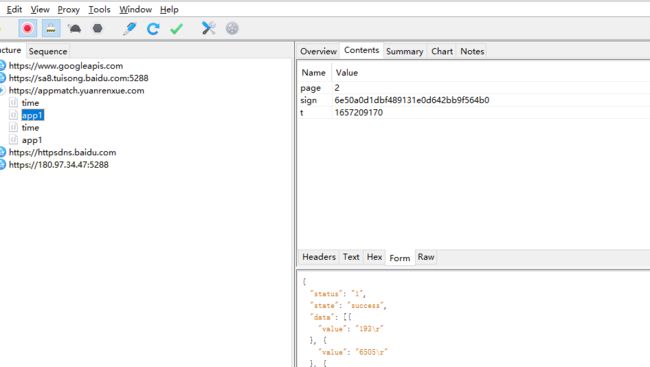
Charles 中 可以看到 post 请求 有三个参数 ,请求的结果为 每页需要计算的数字
第一个是 page 页数 很明显
第二个是 sign 值 为加密流程
第三个 是 t 可以通过 上面的time 请求 了解到是时间戳
那么整体就是分析sign值 是如何产生的 ,是否和page页数和t时间戳相关
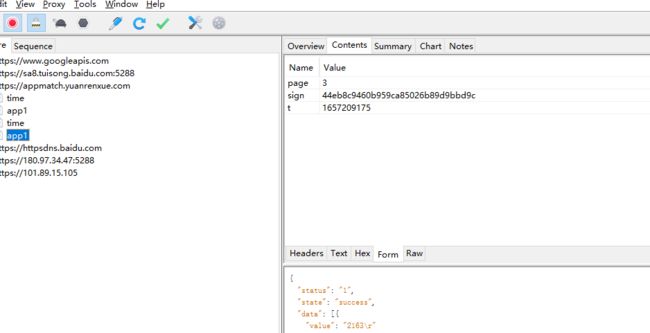
通过jdax 寻找 post 数据 发送点,找到sign 生成的地方
打开jadx 拖app包进入,发现内容是被混淆过的,

尝试通过post 发送的 参数的 关键词 进行定位,选择sign 关键词进行搜索。

发现匹配到的数据太多,更换思路,通过发包的url 中的 /app1 路径 进行搜索

发现 精准匹配到一处,直接双击进入,查看

发现匹配正确,然后通过右键查找用例去查找调用这个接口的地方
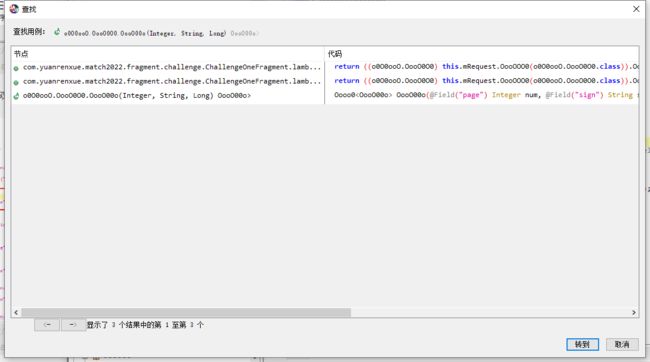
匹配到三个 发现前面两个是一样的,直接随便点击进入一个

可以简单名了的看到,页数 和 时间戳的定义的地方,并且在 return 的地方可以看到 sign 的函数 ,点击进入sign 瞅一眼

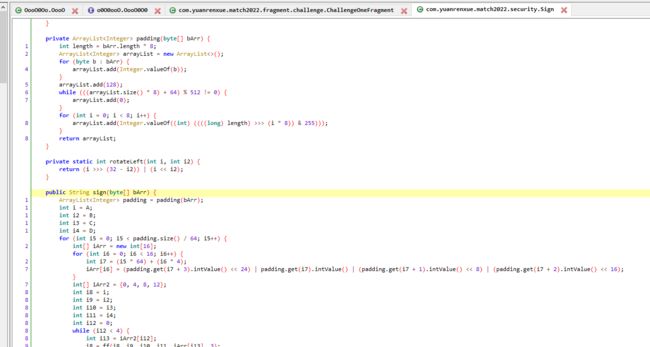
进入com.yuanrenxue.match2022.security.Sign 类中 可以看到整体就是加密库
那么可以直接 hook sign 方法 看看
frida 代码如下
function main(){
console.log("Hooking.......")
Java.perform(function(){
var sign = Java.use("com.yuanrenxue.match2022.security.Sign");
sign.sign.implementation = function(arg){
console.log("sign_arg=>",(arg));
var result = this.sign(arg);
console.log("sign=>",result)
return result;
}
});
}
setImmediate(main);
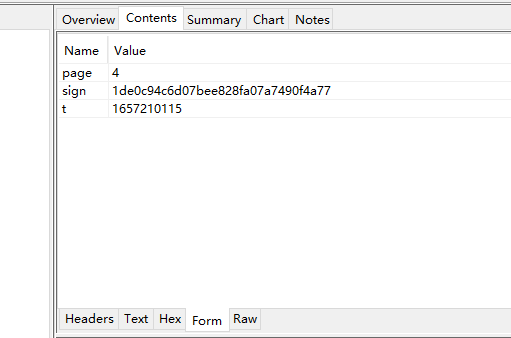
抓包的数据
hook的数据
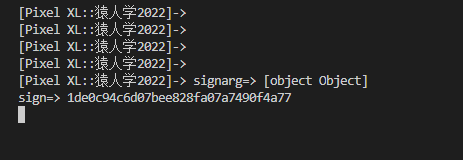
可以看到sign 值是可以对应到的。但是获取到传入sign方法的数据的为啥是对象数据嘞。。。
看了一下sign方法,哦,原来传入的数据是 byte 数据 ,那就 搜索一下 js 字节集转字符串的代码
代码如下
function stringToByte(str) {
var bytes = new Array();
var len, c;
len = str.length;
for(var i = 0; i < len; i++) {
c = str.charCodeAt(i);
if(c >= 0x010000 && c <= 0x10FFFF) {
bytes.push(((c >> 18) & 0x07) | 0xF0);
bytes.push(((c >> 12) & 0x3F) | 0x80);
bytes.push(((c >> 6) & 0x3F) | 0x80);
bytes.push((c & 0x3F) | 0x80);
} else if(c >= 0x000800 && c <= 0x00FFFF) {
bytes.push(((c >> 12) & 0x0F) | 0xE0);
bytes.push(((c >> 6) & 0x3F) | 0x80);
bytes.push((c & 0x3F) | 0x80);
} else if(c >= 0x000080 && c <= 0x0007FF) {
bytes.push(((c >> 6) & 0x1F) | 0xC0);
bytes.push((c & 0x3F) | 0x80);
} else {
bytes.push(c & 0xFF);
}
}
return bytes;
}
//字节集转字符串
function byteToString(arr) {
if(typeof arr === 'string') {
return arr;
}
var str = '',
_arr = arr;
for(var i = 0; i < _arr.length; i++) {
var one = _arr[i].toString(2),
v = one.match(/^1+?(?=0)/);
if(v && one.length == 8) {
var bytesLength = v[0].length;
var store = _arr[i].toString(2).slice(7 - bytesLength);
for(var st = 1; st < bytesLength; st++) {
store += _arr[st + i].toString(2).slice(2);
}
str += String.fromCharCode(parseInt(store, 2));
i += bytesLength - 1;
} else {
str += String.fromCharCode(_arr[i]);
}
}
return str;
}
所以重新修改一下hook的代码,如下:
function main(){
console.log("Hooking.......")
Java.perform(function(){
var sign = Java.use("com.yuanrenxue.match2022.security.Sign");
sign.sign.implementation = function(arg){
console.log("sign_arg=>",byteToString(arg));
var result = this.sign(arg);
console.log("sign=>",result)
return result;
}
});
}
setImmediate(main);
hook到的传入数据就可以正常显示了


对应到抓包的数据可以看出,sign 的值的数据 是通过 page的标识和值+t的值 然后通过sign()方法进行计算的出来的
进行主动调用
知道sign值的传入值 ,我们可以手动赋值,那么就可以进行hook 主动调用
代码如下
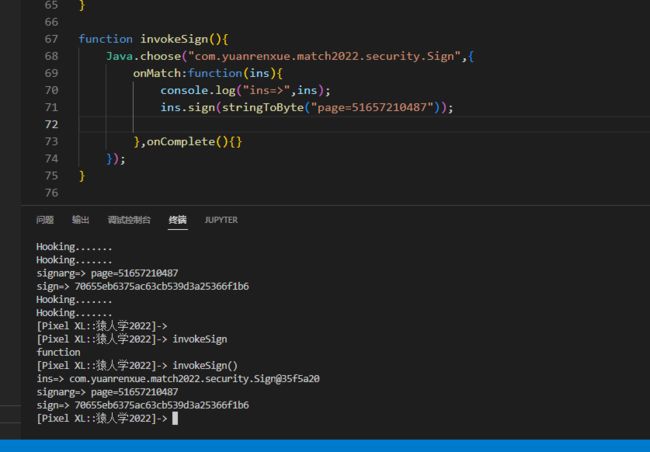
function invokeSign(){
Java.choose("com.yuanrenxue.match2022.security.Sign",{
onMatch:function(ins){
console.log("ins=>",ins);
ins.sign(stringToByte("page=51657210487"));
},onComplete(){}
});
}
hook获取的效果如下,和上面的 获取的sign值一样
如何进行1~100页的调用?
如何 一次性自动化的 获取到 1~100页的 sign值 ,并且进行100次的请求,然后获取到 response 中 返回的数据 进行sum 计算?
抽了一根烟,想了一下,既然都用主动调用了,那么就直接frida rpc 通过python 请求一下就行

搞了半天,最终成了!!!

附上代码
import time
import frida
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
def my_message_handler(message, payload):
print("message=>",message)
print("payloa=>d",payload)
# connect wifiadb
device = frida.get_device_manager().add_remote_device("192.168.0.102:8888")
print('设备=>',device)
session = device.attach("com.yuanrenxue.match2022")
print('session=>',session)
#load script
with open("app1.js") as f:
script = session.create_script(f.read())
script.on("message", my_message_handler)
script.load()
# script.exports.invokesign('page=121657216931')
def get_url():
num = 0
for i in range(1,101):
url = 'https://appmatch.yuanrenxue.com/app1'
headers = {
'accept-language': 'zh-CN,zh;q=0.8',
'user-agent': 'Mozilla/5.0 (Linux; U; Android 8.1.0; zh-cn; Pixel XL Build/OPM1.171019.011) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30',
'content-type': 'application/x-www-form-urlencoded',
'accept-encoding': 'gzip',
'cache-control': 'no-cache'
}
data = {
'page':str(i),
't': str(int(time.time()))
}
data['sign'] = script.exports.invokesign('page='+data['page']+data['t'])
print(data)
response = requests.post(url,headers=headers,data=data,verify=False)
print(response.json())
value_data = response.json()
for value in value_data['data']:
num += int(value['value'])
print(num)
time.sleep(1)
# print(num)
if __name__ == '__main__':
get_url()
总结
在这里 学习了使用frida rpc 进行主动调用 然后进行 获取sign 值 在通过python 进行 post请求
还有需要注意的是 ,需要进行一次 sign 的实例化才可以进行调用,不然会报错!
自己其实是一个初学者,对frida其实并不了解多少,rpc是第一次使用,发现这个功能很nice,省去扣加密算法流程
针对一些app的算法,如果混淆厉害的话,后续可以直接使用这个,不需要硬刚算法了。很棒!