Python 数据分析(PYDA)第三版(七)
原文:
wesmckinney.com/book/译者:飞龙
协议:CC BY-NC-SA 4.0
附录
附录 A:高级 NumPy
原文:
wesmckinney.com/book/advanced-numpy译者:飞龙
协议:CC BY-NC-SA 4.0
此开放访问网络版本的《Python 数据分析第三版》现已作为印刷版和数字版的伴侣提供。如果您发现任何勘误,请在此处报告。请注意,由 Quarto 生成的本站点的某些方面与 O’Reilly 的印刷版和电子书版本的格式不同。
如果您发现本书的在线版本有用,请考虑订购纸质版或无 DRM 的电子书以支持作者。本网站的内容不得复制或再生产。代码示例采用 MIT 许可,可在 GitHub 或 Gitee 上找到。
在这个附录中,我将深入探讨 NumPy 库的数组计算。这将包括有关 ndarray 类型的更多内部细节以及更高级的数组操作和算法。
这个附录包含各种主题,不一定需要按顺序阅读。在各章节中,我将为许多示例生成随机数据,这些示例将使用numpy.random模块中的默认随机数生成器:
In [11]: rng = np.random.default_rng(seed=12345)
A.1 ndarray 对象内部
NumPy ndarray 提供了一种将块状同类型数据(连续或分步)解释为多维数组对象的方法。数据类型,或dtype,决定了数据被解释为浮点数、整数、布尔值或我们一直在查看的其他类型之一。
ndarray 灵活的部分之一是每个数组对象都是对数据块的步进视图。例如,您可能想知道,例如,数组视图arr[::2, ::-1]如何不复制任何数据。原因是 ndarray 不仅仅是一块内存和一个数据类型;它还具有步进信息,使数组能够以不同的步长在内存中移动。更准确地说,ndarray 内部包含以下内容:
-
一个数据指针—即 RAM 中的数据块或内存映射文件
-
描述数组中固定大小值单元的数据类型或 dtype
-
一个指示数组形状的元组
-
一个步长元组—表示在一个维度上前进一个元素所需的字节数
请参见图 A.1 以查看 ndarray 内部的简单模拟。
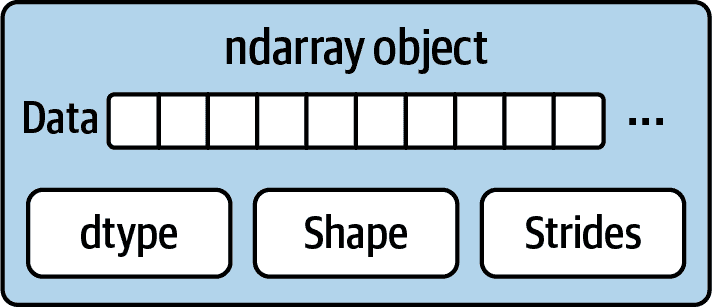
图 A.1:NumPy ndarray 对象
例如,一个 10×5 的数组将具有形状(10, 5):
In [12]: np.ones((10, 5)).shape
Out[12]: (10, 5)
一个典型的(C 顺序)3×4×5 的float64(8 字节)值数组具有步长(160, 40, 8)(了解步长可以是有用的,因为一般来说,特定轴上的步长越大,沿着该轴执行计算的成本就越高):
In [13]: np.ones((3, 4, 5), dtype=np.float64).strides
Out[13]: (160, 40, 8)
虽然典型的 NumPy 用户很少会对数组的步长感兴趣,但它们需要用来构建“零拷贝”数组视图。步长甚至可以是负数,这使得数组可以在内存中“向后”移动(例如,在像obj[::-1]或obj[:, ::-1]这样的切片中)。
NumPy 数据类型层次结构
您可能偶尔需要检查代码是否包含整数、浮点数、字符串或 Python 对象的数组。由于有多种浮点数类型(float16到float128),检查数据类型是否在类型列表中会非常冗长。幸运的是,数据类型有超类,如np.integer和np.floating,可以与np.issubdtype函数一起使用:
In [14]: ints = np.ones(10, dtype=np.uint16)
In [15]: floats = np.ones(10, dtype=np.float32)
In [16]: np.issubdtype(ints.dtype, np.integer)
Out[16]: True
In [17]: np.issubdtype(floats.dtype, np.floating)
Out[17]: True
您可以通过调用类型的mro方法查看特定数据类型的所有父类:
In [18]: np.float64.mro()
Out[18]:
[numpy.float64,
numpy.floating,
numpy.inexact,
numpy.number,
numpy.generic,
float,
object]
因此,我们还有:
In [19]: np.issubdtype(ints.dtype, np.number)
Out[19]: True
大多数 NumPy 用户永远不需要了解这一点,但有时会有用。请参见图 A.2 以查看数据类型层次结构和父-子类关系的图表。¹

图 A.2:NumPy 数据类型类层次结构
A.2 高级数组操作
除了花式索引、切片和布尔子集之外,还有许多处理数组的方法。虽然大部分数据分析应用程序的繁重工作由 pandas 中的高级函数处理,但您可能在某个时候需要编写一个在现有库中找不到的数据算法。
重新塑形数组
在许多情况下,您可以将一个数组从一种形状转换为另一种形状而不复制任何数据。为此,将表示新形状的元组传递给 reshape 数组实例方法。例如,假设我们有一个希望重新排列成矩阵的值的一维数组(这在图 A.3 中有说明):
In [20]: arr = np.arange(8)
In [21]: arr
Out[21]: array([0, 1, 2, 3, 4, 5, 6, 7])
In [22]: arr.reshape((4, 2))
Out[22]:
array([[0, 1],
[2, 3],
[4, 5],
[6, 7]])

图 A.3:按 C(行主要)或 FORTRAN(列主要)顺序重新塑形
多维数组也可以被重新塑形:
In [23]: arr.reshape((4, 2)).reshape((2, 4))
Out[23]:
array([[0, 1, 2, 3],
[4, 5, 6, 7]])
传递的形状维度中可以有一个为 -1,在这种情况下,该维度的值将从数据中推断出来:
In [24]: arr = np.arange(15)
In [25]: arr.reshape((5, -1))
Out[25]:
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11],
[12, 13, 14]])
由于数组的 shape 属性是一个元组,它也可以传递给 reshape:
In [26]: other_arr = np.ones((3, 5))
In [27]: other_arr.shape
Out[27]: (3, 5)
In [28]: arr.reshape(other_arr.shape)
Out[28]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
从一维到更高维的 reshape 的相反操作通常称为 展平 或 raveling:
In [29]: arr = np.arange(15).reshape((5, 3))
In [30]: arr
Out[30]:
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11],
[12, 13, 14]])
In [31]: arr.ravel()
Out[31]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
如果结果中的值在原始数组中是连续的,ravel 不会生成基础值的副本。
flatten 方法的行为类似于 ravel,只是它总是返回数据的副本:
In [32]: arr.flatten()
Out[32]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
数据可以以不同的顺序被重新塑形或展开。这对于新的 NumPy 用户来说是一个略微微妙的主题,因此是下一个子主题。
C 与 FORTRAN 顺序
NumPy 能够适应内存中数据的许多不同布局。默认情况下,NumPy 数组是按 行主要 顺序创建的。从空间上讲,这意味着如果您有一个二维数据数组,数组中每行的项都存储在相邻的内存位置上。与行主要顺序相反的是 列主要 顺序,这意味着数据中每列的值都存储在相邻的内存位置上。
出于历史原因,行和列主要顺序也被称为 C 和 FORTRAN 顺序。在 FORTRAN 77 语言中,矩阵都是列主要的。
像 reshape 和 ravel 这样的函数接受一个 order 参数,指示数组中使用数据的顺序。在大多数情况下,这通常设置为 'C' 或 'F'(还有一些不常用的选项 'A' 和 'K';请参阅 NumPy 文档,并参考图 A.3 以了解这些选项的说明):
In [33]: arr = np.arange(12).reshape((3, 4))
In [34]: arr
Out[34]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
In [35]: arr.ravel()
Out[35]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
In [36]: arr.ravel('F')
Out[36]: array([ 0, 4, 8, 1, 5, 9, 2, 6, 10, 3, 7, 11])
使用超过两个维度的数组进行重新塑形可能有点令人费解(参见图 A.3)。C 和 FORTRAN 顺序之间的关键区别在于维度的遍历方式:
C/行主要顺序
在遍历更高维度时,首先 遍历(例如,先在轴 1 上再在轴 0 上前进)。
FORTRAN/列主要顺序
在遍历更高维度时,最后 遍历(例如,先在轴 0 上再在轴 1 上前进)。
连接和分割数组
numpy.concatenate 接受一个数组序列(元组,列表等),并按顺序沿着输入轴连接它们:
In [37]: arr1 = np.array([[1, 2, 3], [4, 5, 6]])
In [38]: arr2 = np.array([[7, 8, 9], [10, 11, 12]])
In [39]: np.concatenate([arr1, arr2], axis=0)
Out[39]:
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]])
In [40]: np.concatenate([arr1, arr2], axis=1)
Out[40]:
array([[ 1, 2, 3, 7, 8, 9],
[ 4, 5, 6, 10, 11, 12]])
有一些便利函数,如 vstack 和 hstack,用于常见类型的连接。前面的操作可以表示为:
In [41]: np.vstack((arr1, arr2))
Out[41]:
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]])
In [42]: np.hstack((arr1, arr2))
Out[42]:
array([[ 1, 2, 3, 7, 8, 9],
[ 4, 5, 6, 10, 11, 12]])
另一方面,split 将数组沿着一个轴分割成多个数组:
In [43]: arr = rng.standard_normal((5, 2))
In [44]: arr
Out[44]:
array([[-1.4238, 1.2637],
[-0.8707, -0.2592],
[-0.0753, -0.7409],
[-1.3678, 0.6489],
[ 0.3611, -1.9529]])
In [45]: first, second, third = np.split(arr, [1, 3])
In [46]: first
Out[46]: array([[-1.4238, 1.2637]])
In [47]: second
Out[47]:
array([[-0.8707, -0.2592],
[-0.0753, -0.7409]])
In [48]: third
Out[48]:
array([[-1.3678, 0.6489],
[ 0.3611, -1.9529]])
传递给 np.split 的值 [1, 3] 指示在哪些索引处将数组分割成片段。
请参见表 A.1 以获取所有相关连接和分割函数的列表,其中一些仅作为非常通用的 concatenate 的便利。
表 A.1:数组连接函数
| 函数 | 描述 |
|---|---|
concatenate |
最通用的函数,沿一个轴连接数组集合 |
vstack, row_stack |
按行堆叠数组(沿轴 0) |
hstack |
按列堆叠数组(沿轴 1) |
column_stack |
类似于hstack,但首先将 1D 数组转换为 2D 列向量 |
dstack |
按“深度”(沿轴 2)堆叠数组 |
split |
沿特定轴在传递位置分割数组 |
hsplit/vsplit |
在轴 0 和 1 上分割的便利函数 |
堆叠助手:r_ 和 c_
NumPy 命名空间中有两个特殊对象,r_和c_,使堆叠数组更简洁:
In [49]: arr = np.arange(6)
In [50]: arr1 = arr.reshape((3, 2))
In [51]: arr2 = rng.standard_normal((3, 2))
In [52]: np.r_[arr1, arr2]
Out[52]:
array([[ 0. , 1. ],
[ 2. , 3. ],
[ 4. , 5. ],
[ 2.3474, 0.9685],
[-0.7594, 0.9022],
[-0.467 , -0.0607]])
In [53]: np.c_[np.r_[arr1, arr2], arr]
Out[53]:
array([[ 0. , 1. , 0. ],
[ 2. , 3. , 1. ],
[ 4. , 5. , 2. ],
[ 2.3474, 0.9685, 3. ],
[-0.7594, 0.9022, 4. ],
[-0.467 , -0.0607, 5. ]])
这些还可以将切片转换为数组:
In [54]: np.c_[1:6, -10:-5]
Out[54]:
array([[ 1, -10],
[ 2, -9],
[ 3, -8],
[ 4, -7],
[ 5, -6]])
查看文档字符串以了解您可以使用c_和r_做什么。
重复元素:tile 和 repeat
用于重复或复制数组以生成更大数组的两个有用工具是repeat和tile函数。repeat将数组中的每个元素重复若干次,生成一个更大的数组:
In [55]: arr = np.arange(3)
In [56]: arr
Out[56]: array([0, 1, 2])
In [57]: arr.repeat(3)
Out[57]: array([0, 0, 0, 1, 1, 1, 2, 2, 2])
注意
需要复制或重复数组的情况在 NumPy 中可能不像其他数组编程框架(如 MATLAB)中那样常见。其中一个原因是广播通常更好地满足这种需求,这是下一节的主题。
默认情况下,如果传递一个整数,每个元素将重复该次数。如果传递一个整数数组,每个元素可以重复不同次数:
In [58]: arr.repeat([2, 3, 4])
Out[58]: array([0, 0, 1, 1, 1, 2, 2, 2, 2])
多维数组可以沿特定轴重复其元素:
In [59]: arr = rng.standard_normal((2, 2))
In [60]: arr
Out[60]:
array([[ 0.7888, -1.2567],
[ 0.5759, 1.399 ]])
In [61]: arr.repeat(2, axis=0)
Out[61]:
array([[ 0.7888, -1.2567],
[ 0.7888, -1.2567],
[ 0.5759, 1.399 ],
[ 0.5759, 1.399 ]])
请注意,如果没有传递轴,数组将首先被展平,这可能不是您想要的。同样,当重复多维数组以不同次数重复给定切片时,可以传递整数数组:
In [62]: arr.repeat([2, 3], axis=0)
Out[62]:
array([[ 0.7888, -1.2567],
[ 0.7888, -1.2567],
[ 0.5759, 1.399 ],
[ 0.5759, 1.399 ],
[ 0.5759, 1.399 ]])
In [63]: arr.repeat([2, 3], axis=1)
Out[63]:
array([[ 0.7888, 0.7888, -1.2567, -1.2567, -1.2567],
[ 0.5759, 0.5759, 1.399 , 1.399 , 1.399 ]])
另一方面,tile是一个沿轴堆叠数组副本的快捷方式。在视觉上,您可以将其视为类似于“铺设瓷砖”:
In [64]: arr
Out[64]:
array([[ 0.7888, -1.2567],
[ 0.5759, 1.399 ]])
In [65]: np.tile(arr, 2)
Out[65]:
array([[ 0.7888, -1.2567, 0.7888, -1.2567],
[ 0.5759, 1.399 , 0.5759, 1.399 ]])
第二个参数是瓷砖的数量;对于标量,瓦片是按行而不是按列进行的。tile的第二个参数可以是一个元组,指示“瓦片”的布局:
In [66]: arr
Out[66]:
array([[ 0.7888, -1.2567],
[ 0.5759, 1.399 ]])
In [67]: np.tile(arr, (2, 1))
Out[67]:
array([[ 0.7888, -1.2567],
[ 0.5759, 1.399 ],
[ 0.7888, -1.2567],
[ 0.5759, 1.399 ]])
In [68]: np.tile(arr, (3, 2))
Out[68]:
array([[ 0.7888, -1.2567, 0.7888, -1.2567],
[ 0.5759, 1.399 , 0.5759, 1.399 ],
[ 0.7888, -1.2567, 0.7888, -1.2567],
[ 0.5759, 1.399 , 0.5759, 1.399 ],
[ 0.7888, -1.2567, 0.7888, -1.2567],
[ 0.5759, 1.399 , 0.5759, 1.399 ]])
花式索引等效:take 和 put
正如您可能从 Ch 4:NumPy 基础:数组和矢量化计算中记得的那样,通过使用整数数组进行花式索引来获取和设置数组的子集是一种方法:
In [69]: arr = np.arange(10) * 100
In [70]: inds = [7, 1, 2, 6]
In [71]: arr[inds]
Out[71]: array([700, 100, 200, 600])
在仅在单个轴上进行选择的特殊情况下,有一些替代的 ndarray 方法是有用的:
In [72]: arr.take(inds)
Out[72]: array([700, 100, 200, 600])
In [73]: arr.put(inds, 42)
In [74]: arr
Out[74]: array([ 0, 42, 42, 300, 400, 500, 42, 42, 800, 900])
In [75]: arr.put(inds, [40, 41, 42, 43])
In [76]: arr
Out[76]: array([ 0, 41, 42, 300, 400, 500, 43, 40, 800, 900])
要在其他轴上使用take,可以传递axis关键字:
In [77]: inds = [2, 0, 2, 1]
In [78]: arr = rng.standard_normal((2, 4))
In [79]: arr
Out[79]:
array([[ 1.3223, -0.2997, 0.9029, -1.6216],
[-0.1582, 0.4495, -1.3436, -0.0817]])
In [80]: arr.take(inds, axis=1)
Out[80]:
array([[ 0.9029, 1.3223, 0.9029, -0.2997],
[-1.3436, -0.1582, -1.3436, 0.4495]])
put不接受axis参数,而是索引到数组的展平(一维,C 顺序)版本。因此,当您需要使用索引数组在其他轴上设置元素时,最好使用基于[]的索引。
A.3 广播
广播规定了不同形状数组之间的操作方式。它可以是一个强大的功能,但即使对于有经验的用户也可能会引起混淆。广播的最简单示例是将标量值与数组组合时发生:
In [81]: arr = np.arange(5)
In [82]: arr
Out[82]: array([0, 1, 2, 3, 4])
In [83]: arr * 4
Out[83]: array([ 0, 4, 8, 12, 16])
在这里,我们说标量值 4 已经广播到乘法操作中的所有其他元素。
例如,我们可以通过减去列均值来对数组的每一列进行去均值处理。在这种情况下,只需要减去包含每列均值的数组即可:
In [84]: arr = rng.standard_normal((4, 3))
In [85]: arr.mean(0)
Out[85]: array([0.1206, 0.243 , 0.1444])
In [86]: demeaned = arr - arr.mean(0)
In [87]: demeaned
Out[87]:
array([[ 1.6042, 2.3751, 0.633 ],
[ 0.7081, -1.202 , -1.3538],
[-1.5329, 0.2985, 0.6076],
[-0.7793, -1.4717, 0.1132]])
In [88]: demeaned.mean(0)
Out[88]: array([ 0., -0., 0.])
请参见图 A.4 以了解此操作的示例。将行作为广播操作去均值需要更多的注意。幸运的是,跨任何数组维度广播潜在较低维值(例如从二维数组的每列中减去行均值)是可能的,只要遵循规则。
这将我们带到了广播规则。
两个数组在广播时兼容,如果对于每个尾部维度(即,从末尾开始),轴的长度匹配,或者长度中的任何一个为 1。然后在缺失或长度为 1 的维度上执行广播。

图 A.4:在 1D 数组的轴 0 上进行广播
即使作为一个经验丰富的 NumPy 用户,我经常发现自己在思考广播规则时不得不停下来画图。考虑最后一个示例,假设我们希望减去每行的平均值。由于arr.mean(0)的长度为 3,它在轴 0 上是兼容的进行广播,因为arr中的尾部维度为 3,因此匹配。根据规则,要在轴 1 上进行减法(即,从每行减去行均值),较小的数组必须具有形状(4, 1):
In [89]: arr
Out[89]:
array([[ 1.7247, 2.6182, 0.7774],
[ 0.8286, -0.959 , -1.2094],
[-1.4123, 0.5415, 0.7519],
[-0.6588, -1.2287, 0.2576]])
In [90]: row_means = arr.mean(1)
In [91]: row_means.shape
Out[91]: (4,)
In [92]: row_means.reshape((4, 1))
Out[92]:
array([[ 1.7068],
[-0.4466],
[-0.0396],
[-0.5433]])
In [93]: demeaned = arr - row_means.reshape((4, 1))
In [94]: demeaned.mean(1)
Out[94]: array([-0., 0., 0., 0.])
查看图 A.5 以了解此操作的示例。

图 A.5:在 2D 数组的轴 1 上进行广播
查看图 A.6 以获得另一个示例,这次是在轴 0 上将二维数组添加到三维数组中。
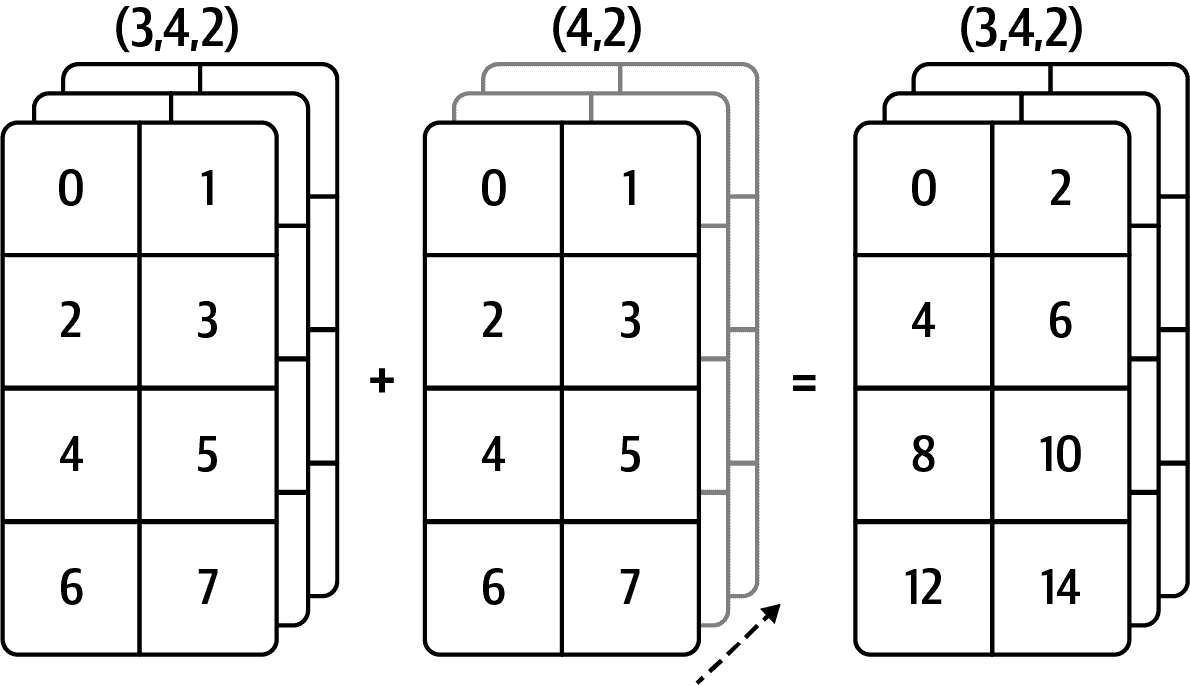
图 A.6:在 3D 数组的轴 0 上进行广播
在其他轴上进行广播
使用更高维度数组进行广播可能看起来更加令人费解,但实际上只是遵循规则的问题。如果不遵循规则,就会出现如下错误:
In [95]: arr - arr.mean(1)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-95-8b8ada26fac0> in <module>
----> 1 arr - arr.mean(1)
ValueError: operands could not be broadcast together with shapes (4,3) (4,)
通常希望使用低维数组在轴 0 以外的轴上执行算术运算是很常见的。根据广播规则,“广播维度”在较小数组中必须为 1。在这里显示的行减均值示例中,这意味着将行重塑为形状(4, 1)而不是(4,):
In [96]: arr - arr.mean(1).reshape((4, 1))
Out[96]:
array([[ 0.018 , 0.9114, -0.9294],
[ 1.2752, -0.5124, -0.7628],
[-1.3727, 0.5811, 0.7915],
[-0.1155, -0.6854, 0.8009]])
在三维情况下,沿着任何三个维度进行广播只是将数据重塑为兼容形状的问题。图 A.7 很好地可视化了广播到三维数组的每个轴所需的形状。
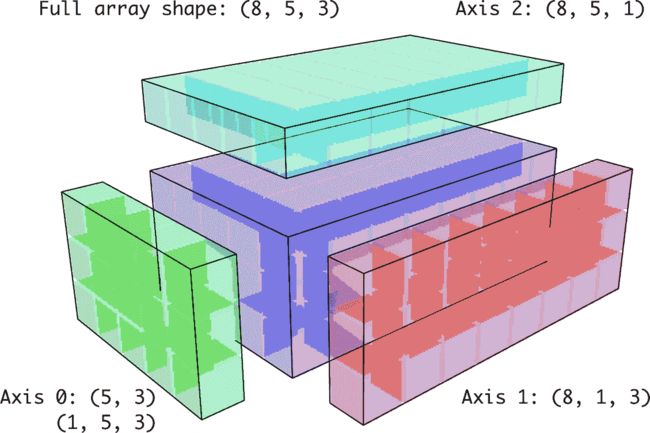
图 A.7:广播到 3D 数组上的兼容 2D 数组形状
因此,一个常见的问题是需要添加一个新的长度为 1 的新轴,专门用于广播目的。使用reshape是一种选择,但插入轴需要构造一个指示新形状的元组。这通常是一项繁琐的工作。因此,NumPy 数组提供了一种特殊的语法,通过索引插入新轴。我们使用特殊的np.newaxis属性以及“full”切片来插入新轴:
In [97]: arr = np.zeros((4, 4))
In [98]: arr_3d = arr[:, np.newaxis, :]
In [99]: arr_3d.shape
Out[99]: (4, 1, 4)
In [100]: arr_1d = rng.standard_normal(3)
In [101]: arr_1d[:, np.newaxis]
Out[101]:
array([[ 0.3129],
[-0.1308],
[ 1.27 ]])
In [102]: arr_1d[np.newaxis, :]
Out[102]: array([[ 0.3129, -0.1308, 1.27 ]])
因此,如果我们有一个三维数组并且希望减去轴 2 的均值,我们需要编写:
In [103]: arr = rng.standard_normal((3, 4, 5))
In [104]: depth_means = arr.mean(2)
In [105]: depth_means
Out[105]:
array([[ 0.0431, 0.2747, -0.1885, -0.2014],
[-0.5732, -0.5467, 0.1183, -0.6301],
[ 0.0972, 0.5954, 0.0331, -0.6002]])
In [106]: depth_means.shape
Out[106]: (3, 4)
In [107]: demeaned = arr - depth_means[:, :, np.newaxis]
In [108]: demeaned.mean(2)
Out[108]:
array([[ 0., -0., 0., -0.],
[ 0., -0., -0., -0.],
[ 0., 0., 0., 0.]])
您可能想知道是否有一种方法可以在不牺牲性能的情况下推广沿轴的减均值操作。有,但需要一些索引技巧:
def demean_axis(arr, axis=0):
means = arr.mean(axis)
# This generalizes things like [:, :, np.newaxis] to N dimensions
indexer = [slice(None)] * arr.ndim
indexer[axis] = np.newaxis
return arr - means[indexer]
通过广播设置数组值
控制算术运算的相同广播规则也适用于通过数组索引设置值。在简单情况下,我们可以做如下操作:
In [109]: arr = np.zeros((4, 3))
In [110]: arr[:] = 5
In [111]: arr
Out[111]:
array([[5., 5., 5.],
[5., 5., 5.],
[5., 5., 5.],
[5., 5., 5.]])
但是,如果我们有一个要设置到数组列中的值的一维数组,只要形状兼容,我们就可以这样做:
In [112]: col = np.array([1.28, -0.42, 0.44, 1.6])
In [113]: arr[:] = col[:, np.newaxis]
In [114]: arr
Out[114]:
array([[ 1.28, 1.28, 1.28],
[-0.42, -0.42, -0.42],
[ 0.44, 0.44, 0.44],
[ 1.6 , 1.6 , 1.6 ]])
In [115]: arr[:2] = [[-1.37], [0.509]]
In [116]: arr
Out[116]:
array([[-1.37 , -1.37 , -1.37 ],
[ 0.509, 0.509, 0.509],
[ 0.44 , 0.44 , 0.44 ],
[ 1.6 , 1.6 , 1.6 ]])
A.4 高级 ufunc 用法
虽然许多 NumPy 用户只会使用通用函数提供的快速逐元素操作,但偶尔一些附加功能可以帮助您编写更简洁的代码,而无需显式循环。
ufunc 实例方法
NumPy 的每个二进制 ufunc 都有特殊的方法来执行某些特定类型的特殊向量化操作。这些方法在表 A.2 中进行了总结,但我将给出一些具体示例来说明它们的工作原理。
reduce接受一个数组并通过执行一系列二进制操作(可选地沿轴)来聚合其值。例如,在数组中求和元素的另一种方法是使用np.add.reduce:
In [117]: arr = np.arange(10)
In [118]: np.add.reduce(arr)
Out[118]: 45
In [119]: arr.sum()
Out[119]: 45
起始值(例如,add的 0)取决于 ufunc。如果传递了轴,将沿着该轴执行减少。这使您能够以简洁的方式回答某些类型的问题。作为一个不那么平凡的例子,我们可以使用np.logical_and来检查数组的每一行中的值是否已排序:
In [120]: my_rng = np.random.default_rng(12346) # for reproducibility
In [121]: arr = my_rng.standard_normal((5, 5))
In [122]: arr
Out[122]:
array([[-0.9039, 0.1571, 0.8976, -0.7622, -0.1763],
[ 0.053 , -1.6284, -0.1775, 1.9636, 1.7813],
[-0.8797, -1.6985, -1.8189, 0.119 , -0.4441],
[ 0.7691, -0.0343, 0.3925, 0.7589, -0.0705],
[ 1.0498, 1.0297, -0.4201, 0.7863, 0.9612]])
In [123]: arr[::2].sort(1) # sort a few rows
In [124]: arr[:, :-1] < arr[:, 1:]
Out[124]:
array([[ True, True, True, True],
[False, True, True, False],
[ True, True, True, True],
[False, True, True, False],
[ True, True, True, True]])
In [125]: np.logical_and.reduce(arr[:, :-1] < arr[:, 1:], axis=1)
Out[125]: array([ True, False, True, False, True])
请注意,logical_and.reduce等同于all方法。
accumulate ufunc 方法与reduce相关,就像cumsum与sum相关一样。它生成一个与中间“累积”值大小相同的数组:
In [126]: arr = np.arange(15).reshape((3, 5))
In [127]: np.add.accumulate(arr, axis=1)
Out[127]:
array([[ 0, 1, 3, 6, 10],
[ 5, 11, 18, 26, 35],
[10, 21, 33, 46, 60]])
outer在两个数组之间执行成对的叉积:
In [128]: arr = np.arange(3).repeat([1, 2, 2])
In [129]: arr
Out[129]: array([0, 1, 1, 2, 2])
In [130]: np.multiply.outer(arr, np.arange(5))
Out[130]:
array([[0, 0, 0, 0, 0],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 2, 4, 6, 8],
[0, 2, 4, 6, 8]])
outer的输出将具有输入维度的连接:
In [131]: x, y = rng.standard_normal((3, 4)), rng.standard_normal(5)
In [132]: result = np.subtract.outer(x, y)
In [133]: result.shape
Out[133]: (3, 4, 5)
最后一个方法,reduceat,执行“本地减少”,本质上是一个数组“分组”操作,其中数组的切片被聚合在一起。它接受指示如何拆分和聚合值的“bin 边缘”序列:
In [134]: arr = np.arange(10)
In [135]: np.add.reduceat(arr, [0, 5, 8])
Out[135]: array([10, 18, 17])
结果是在arr[0:5],arr[5:8]和arr[8:]上执行的减少(这里是求和)。与其他方法一样,您可以传递一个axis参数:
In [136]: arr = np.multiply.outer(np.arange(4), np.arange(5))
In [137]: arr
Out[137]:
array([[ 0, 0, 0, 0, 0],
[ 0, 1, 2, 3, 4],
[ 0, 2, 4, 6, 8],
[ 0, 3, 6, 9, 12]])
In [138]: np.add.reduceat(arr, [0, 2, 4], axis=1)
Out[138]:
array([[ 0, 0, 0],
[ 1, 5, 4],
[ 2, 10, 8],
[ 3, 15, 12]])
请参见表 A.2 以获取 ufunc 方法的部分列表。
表 A.2:ufunc 方法
| 方法 | 描述 |
|---|---|
accumulate(x) |
聚合值,保留所有部分聚合。 |
at(x, indices, b=None) |
在指定的索引处对x执行操作。参数b是需要两个数组输入的 ufunc 的第二个输入。 |
reduce(x) |
通过连续应用操作来聚合值。 |
reduceat(x, bins) |
“本地”减少或“分组”;减少数据的连续切片以生成聚合数组。 |
outer(x, y) |
将操作应用于x和y中所有元素对;生成的数组形状为x.shape + y.shape。 |
用 Python 编写新的 ufuncs
有许多创建自己的 NumPy ufuncs 的方法。最通用的方法是使用 NumPy C API,但这超出了本书的范围。在本节中,我们将看一下纯 Python ufuncs。
numpy.frompyfunc接受一个 Python 函数以及输入和输出数量的规范。例如,一个简单的逐元素相加的函数将被指定为:
In [139]: def add_elements(x, y):
.....: return x + y
In [140]: add_them = np.frompyfunc(add_elements, 2, 1)
In [141]: add_them(np.arange(8), np.arange(8))
Out[141]: array([0, 2, 4, 6, 8, 10, 12, 14], dtype=object)
使用frompyfunc创建的函数始终返回 Python 对象的数组,这可能不方便。幸运的是,还有一种替代(但功能稍逊一筹)的函数numpy.vectorize,允许您指定输出类型:
In [142]: add_them = np.vectorize(add_elements, otypes=[np.float64])
In [143]: add_them(np.arange(8), np.arange(8))
Out[143]: array([ 0., 2., 4., 6., 8., 10., 12., 14.])
这些函数提供了一种创建类似 ufunc 函数的方法,但它们非常慢,因为它们需要调用 Python 函数来计算每个元素,这比 NumPy 的基于 C 的 ufunc 循环慢得多:
In [144]: arr = rng.standard_normal(10000)
In [145]: %timeit add_them(arr, arr)
1.18 ms +- 14.8 us per loop (mean +- std. dev. of 7 runs, 1000 loops each)
In [146]: %timeit np.add(arr, arr)
2.8 us +- 64.1 ns per loop (mean +- std. dev. of 7 runs, 100000 loops each)
在本附录的后面,我们将展示如何使用Numba 库在 Python 中创建快速的 ufuncs。
A.5 结构化和记录数组
到目前为止,您可能已经注意到 ndarray 是一个同质数据容器;也就是说,它表示一个内存块,其中每个元素占据相同数量的字节,由数据类型确定。表面上,这似乎不允许您表示异构或表格数据。结构化数组是一个 ndarray,其中每个元素可以被视为表示 C 中的struct(因此称为“结构化”名称)或 SQL 表中具有多个命名字段的行:
In [147]: dtype = [('x', np.float64), ('y', np.int32)]
In [148]: sarr = np.array([(1.5, 6), (np.pi, -2)], dtype=dtype)
In [149]: sarr
Out[149]: array([(1.5 , 6), (3.1416, -2)], dtype=[('x', '), ('y', ')])
有几种指定结构化数据类型的方法(请参阅在线 NumPy 文档)。一种典型的方法是作为具有(field_name, field_data_type)的元组列表。现在,数组的元素是类似元组的对象,其元素可以像字典一样访问:
In [150]: sarr[0]
Out[150]: (1.5, 6)
In [151]: sarr[0]['y']
Out[151]: 6
字段名称存储在dtype.names属性中。当您访问结构化数组上的字段时,会返回数据的跨度视图,因此不会复制任何内容:
In [152]: sarr['x']
Out[152]: array([1.5 , 3.1416])
嵌套数据类型和多维字段
在指定结构化数据类型时,您还可以传递一个形状(作为 int 或元组):
In [153]: dtype = [('x', np.int64, 3), ('y', np.int32)]
In [154]: arr = np.zeros(4, dtype=dtype)
In [155]: arr
Out[155]:
array([([0, 0, 0], 0), ([0, 0, 0], 0), ([0, 0, 0], 0), ([0, 0, 0], 0)],
dtype=[('x', ', (3,)), ('y', ')])
在这种情况下,x字段现在指的是每个记录的长度为 3 的数组:
In [156]: arr[0]['x']
Out[156]: array([0, 0, 0])
方便的是,访问arr['x']然后返回一个二维数组,而不是像之前的例子中那样返回一个一维数组:
In [157]: arr['x']
Out[157]:
array([[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
这使您能够将更复杂的嵌套结构表达为数组中的单个内存块。您还可以嵌套数据类型以创建更复杂的结构。这里是一个例子:
In [158]: dtype = [('x', [('a', 'f8'), ('b', 'f4')]), ('y', np.int32)]
In [159]: data = np.array([((1, 2), 5), ((3, 4), 6)], dtype=dtype)
In [160]: data['x']
Out[160]: array([(1., 2.), (3., 4.)], dtype=[('a', '), ('b', ')])
In [161]: data['y']
Out[161]: array([5, 6], dtype=int32)
In [162]: data['x']['a']
Out[162]: array([1., 3.])
pandas DataFrame 并不以相同的方式支持这个特性,尽管它类似于分层索引。
为什么使用结构化数组?
与 pandas DataFrame 相比,NumPy 结构化数组是一个更低级别的工具。它们提供了一种将内存块解释为具有嵌套列的表格结构的方法。由于数组中的每个元素在内存中表示为固定数量的字节,结构化数组提供了一种有效的方式来将数据写入磁盘(包括内存映射)、通过网络传输数据以及其他类似用途。结构化数组中每个值的内存布局基于 C 编程语言中 struct 数据类型的二进制表示。
作为结构化数组的另一个常见用途,将数据文件写为固定长度记录字节流是在工业中的遗留系统中有时会发现的一种序列化数据的常见方式。只要文件的格式已知(每个记录的大小以及每个元素的顺序、字节大小和数据类型),数据就可以通过np.fromfile读入内存。像这样的专用用途超出了本书的范围,但值得知道这样的事情是可能的。
A.6 更多关于排序的内容
与 Python 内置列表类似,ndarray 的sort实例方法是一种原地排序,这意味着数组内容会被重新排列而不会产生新数组:
In [163]: arr = rng.standard_normal(6)
In [164]: arr.sort()
In [165]: arr
Out[165]: array([-1.1553, -0.9319, -0.5218, -0.4745, -0.1649, 0.03 ])
在原地对数组进行排序时,请记住,如果数组是对不同 ndarray 的视图,则原始数组将被修改:
In [166]: arr = rng.standard_normal((3, 5))
In [167]: arr
Out[167]:
array([[-1.1956, 0.4691, -0.3598, 1.0359, 0.2267],
[-0.7448, -0.5931, -1.055 , -0.0683, 0.458 ],
[-0.07 , 0.1462, -0.9944, 1.1436, 0.5026]])
In [168]: arr[:, 0].sort() # Sort first column values in place
In [169]: arr
Out[169]:
array([[-1.1956, 0.4691, -0.3598, 1.0359, 0.2267],
[-0.7448, -0.5931, -1.055 , -0.0683, 0.458 ],
[-0.07 , 0.1462, -0.9944, 1.1436, 0.5026]])
另一方面,numpy.sort会创建一个新的、排序后的数组副本。否则,它接受与 ndarray 的sort方法相同的参数(如kind):
In [170]: arr = rng.standard_normal(5)
In [171]: arr
Out[171]: array([ 0.8981, -1.1704, -0.2686, -0.796 , 1.4522])
In [172]: np.sort(arr)
Out[172]: array([-1.1704, -0.796 , -0.2686, 0.8981, 1.4522])
In [173]: arr
Out[173]: array([ 0.8981, -1.1704, -0.2686, -0.796 , 1.4522])
所有这些排序方法都接受一个轴参数,用于独立地对沿传递的轴的数据部分进行排序:
In [174]: arr = rng.standard_normal((3, 5))
In [175]: arr
Out[175]:
array([[-0.2535, 2.1183, 0.3634, -0.6245, 1.1279],
[ 1.6164, -0.2287, -0.6201, -0.1143, -1.2067],
[-1.0872, -2.1518, -0.6287, -1.3199, 0.083 ]])
In [176]: arr.sort(axis=1)
In [177]: arr
Out[177]:
array([[-0.6245, -0.2535, 0.3634, 1.1279, 2.1183],
[-1.2067, -0.6201, -0.2287, -0.1143, 1.6164],
[-2.1518, -1.3199, -1.0872, -0.6287, 0.083 ]])
您可能会注意到,所有排序方法都没有选项以降序排序。这在实践中是一个问题,因为数组切片会产生视图,因此不会产生副本或需要任何计算工作。许多 Python 用户熟悉“技巧”,即对于values列表,values[::-1]返回一个反向排序的列表。对于 ndarrays 也是如此:
In [178]: arr[:, ::-1]
Out[178]:
array([[ 2.1183, 1.1279, 0.3634, -0.2535, -0.6245],
[ 1.6164, -0.1143, -0.2287, -0.6201, -1.2067],
[ 0.083 , -0.6287, -1.0872, -1.3199, -2.1518]])
间接排序:argsort 和 lexsort
在数据分析中,您可能需要按一个或多个键重新排序数据集。例如,关于一些学生的数据表可能需要按姓氏排序,然后按名字排序。这是一个间接排序的例子,如果您已经阅读了与 pandas 相关的章节,您已经看到了许多更高级的例子。给定一个键或键(一个值数组或多个值数组),您希望获得一个整数索引数组(我口头上称之为索引器),告诉您如何重新排序数据以使其按排序顺序排列。这种情况下的两种方法是argsort和numpy.lexsort。例如:
In [179]: values = np.array([5, 0, 1, 3, 2])
In [180]: indexer = values.argsort()
In [181]: indexer
Out[181]: array([1, 2, 4, 3, 0])
In [182]: values[indexer]
Out[182]: array([0, 1, 2, 3, 5])
作为一个更复杂的例子,这段代码通过其第一行重新排序一个二维数组:
In [183]: arr = rng.standard_normal((3, 5))
In [184]: arr[0] = values
In [185]: arr
Out[185]:
array([[ 5. , 0. , 1. , 3. , 2. ],
[-0.7503, -2.1268, -1.391 , -0.4922, 0.4505],
[ 0.8926, -1.0479, 0.9553, 0.2936, 0.5379]])
In [186]: arr[:, arr[0].argsort()]
Out[186]:
array([[ 0. , 1. , 2. , 3. , 5. ],
[-2.1268, -1.391 , 0.4505, -0.4922, -0.7503],
[-1.0479, 0.9553, 0.5379, 0.2936, 0.8926]])
lexsort类似于argsort,但它对多个关键数组执行间接的*词典排序。假设我们想要按名字和姓氏对一些数据进行排序:
In [187]: first_name = np.array(['Bob', 'Jane', 'Steve', 'Bill', 'Barbara'])
In [188]: last_name = np.array(['Jones', 'Arnold', 'Arnold', 'Jones', 'Walters'])
In [189]: sorter = np.lexsort((first_name, last_name))
In [190]: sorter
Out[190]: array([1, 2, 3, 0, 4])
In [191]: list(zip(last_name[sorter], first_name[sorter]))
Out[191]:
[('Arnold', 'Jane'),
('Arnold', 'Steve'),
('Jones', 'Bill'),
('Jones', 'Bob'),
('Walters', 'Barbara')]
第一次使用lexsort可能会有点困惑,因为用于对数据排序的键的顺序是从传递的最后数组开始的。在这里,last_name在first_name之前使用。
替代排序算法
稳定排序算法保留相等元素的相对位置。这在相对排序有意义的间接排序中尤为重要:
In [192]: values = np.array(['2:first', '2:second', '1:first', '1:second',
.....: '1:third'])
In [193]: key = np.array([2, 2, 1, 1, 1])
In [194]: indexer = key.argsort(kind='mergesort')
In [195]: indexer
Out[195]: array([2, 3, 4, 0, 1])
In [196]: values.take(indexer)
Out[196]:
array(['1:first', '1:second', '1:third', '2:first', '2:second'],
dtype=')
唯一可用的稳定排序是mergesort,它保证了O(n log n)的性能,但其性能平均而言比默认的 quicksort 方法差。请参见表 A.3 以获取可用方法及其相对性能(和性能保证)的摘要。这不是大多数用户需要考虑的事情,但知道它存在是有用的。
表 A.3:数组排序方法
| 类型 | 速度 | 稳定性 | 工作空间 | 最坏情况 |
|---|---|---|---|---|
'quicksort' |
1 | 否 | 0 | O(n²) |
'mergesort' |
2 | 是 | n / 2 |
O(n log n) |
'heapsort' |
3 | 否 | 0 | O(n log n) |
部分排序数组
排序的目标之一可以是确定数组中最大或最小的元素。NumPy 有快速方法numpy.partition和np.argpartition,用于围绕第k个最小元素对数组进行分区:
In [197]: rng = np.random.default_rng(12345)
In [198]: arr = rng.standard_normal(20)
In [199]: arr
Out[199]:
array([-1.4238, 1.2637, -0.8707, -0.2592, -0.0753, -0.7409, -1.3678,
0.6489, 0.3611, -1.9529, 2.3474, 0.9685, -0.7594, 0.9022,
-0.467 , -0.0607, 0.7888, -1.2567, 0.5759, 1.399 ])
In [200]: np.partition(arr, 3)
Out[200]:
array([-1.9529, -1.4238, -1.3678, -1.2567, -0.8707, -0.7594, -0.7409,
-0.0607, 0.3611, -0.0753, -0.2592, -0.467 , 0.5759, 0.9022,
0.9685, 0.6489, 0.7888, 1.2637, 1.399 , 2.3474])
调用partition(arr, 3)后,结果中的前三个元素是任意顺序中最小的三个值。numpy.argpartition类似于numpy.argsort,返回重新排列数据为等效顺序的索引:
In [201]: indices = np.argpartition(arr, 3)
In [202]: indices
Out[202]:
array([ 9, 0, 6, 17, 2, 12, 5, 15, 8, 4, 3, 14, 18, 13, 11, 7, 16,
1, 19, 10])
In [203]: arr.take(indices)
Out[203]:
array([-1.9529, -1.4238, -1.3678, -1.2567, -0.8707, -0.7594, -0.7409,
-0.0607, 0.3611, -0.0753, -0.2592, -0.467 , 0.5759, 0.9022,
0.9685, 0.6489, 0.7888, 1.2637, 1.399 , 2.3474])
numpy.searchsorted: 在排序数组中查找元素
searchsorted是一个数组方法,对排序数组执行二分查找,返回值需要插入以保持排序的数组中的位置:
In [204]: arr = np.array([0, 1, 7, 12, 15])
In [205]: arr.searchsorted(9)
Out[205]: 3
您还可以传递一个值数组,以获取一个索引数组:
In [206]: arr.searchsorted([0, 8, 11, 16])
Out[206]: array([0, 3, 3, 5])
您可能已经注意到searchsorted对于0元素返回了0。这是因为默认行为是返回相等值组的左侧的索引:
In [207]: arr = np.array([0, 0, 0, 1, 1, 1, 1])
In [208]: arr.searchsorted([0, 1])
Out[208]: array([0, 3])
In [209]: arr.searchsorted([0, 1], side='right')
Out[209]: array([3, 7])
作为searchsorted的另一个应用,假设我们有一个值在 0 到 10,000 之间的数组,以及一个我们想要用来对数据进行分箱的单独的“桶边缘”数组:
In [210]: data = np.floor(rng.uniform(0, 10000, size=50))
In [211]: bins = np.array([0, 100, 1000, 5000, 10000])
In [212]: data
Out[212]:
array([ 815., 1598., 3401., 4651., 2664., 8157., 1932., 1294., 916.,
5985., 8547., 6016., 9319., 7247., 8605., 9293., 5461., 9376.,
4949., 2737., 4517., 6650., 3308., 9034., 2570., 3398., 2588.,
3554., 50., 6286., 2823., 680., 6168., 1763., 3043., 4408.,
1502., 2179., 4743., 4763., 2552., 2975., 2790., 2605., 4827.,
2119., 4956., 2462., 8384., 1801.])
然后,为了确定每个数据点属于哪个区间(其中 1 表示桶[0, 100)),我们可以简单地使用searchsorted:
In [213]: labels = bins.searchsorted(data)
In [214]: labels
Out[214]:
array([2, 3, 3, 3, 3, 4, 3, 3, 2, 4, 4, 4, 4, 4, 4, 4, 4, 4, 3, 3, 3, 4,
3, 4, 3, 3, 3, 3, 1, 4, 3, 2, 4, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3,
3, 3, 3, 3, 4, 3])
这与 pandas 的groupby结合使用,可以用于对数据进行分箱:
In [215]: pd.Series(data).groupby(labels).mean()
Out[215]:
1 50.000000
2 803.666667
3 3079.741935
4 7635.200000
dtype: float64
使用 Numba 编写快速 NumPy 函数
Numba 是一个开源项目,使用 CPU、GPU 或其他硬件为类似 NumPy 的数据创建快速函数。它使用LLVM Project将 Python 代码转换为编译后的机器代码。
为了介绍 Numba,让我们考虑一个纯 Python 函数,使用for循环计算表达式(x - y).mean():
import numpy as np
def mean_distance(x, y):
nx = len(x)
result = 0.0
count = 0
for i in range(nx):
result += x[i] - y[i]
count += 1
return result / count
这个函数很慢:
In [209]: x = rng.standard_normal(10_000_000)
In [210]: y = rng.standard_normal(10_000_000)
In [211]: %timeit mean_distance(x, y)
1 loop, best of 3: 2 s per loop
In [212]: %timeit (x - y).mean()
100 loops, best of 3: 14.7 ms per loop
NumPy 版本快了 100 多倍。我们可以使用numba.jit函数将此函数转换为编译后的 Numba 函数:
In [213]: import numba as nb
In [214]: numba_mean_distance = nb.jit(mean_distance)
我们也可以将其编写为装饰器:
@nb.jit
def numba_mean_distance(x, y):
nx = len(x)
result = 0.0
count = 0
for i in range(nx):
result += x[i] - y[i]
count += 1
return result / count
结果函数实际上比矢量化的 NumPy 版本更快:
In [215]: %timeit numba_mean_distance(x, y)
100 loops, best of 3: 10.3 ms per loop
Numba 无法编译所有纯 Python 代码,但它支持 Python 的一个重要子集,对于编写数值算法非常有用。
Numba 是一个深度库,支持不同类型的硬件、编译模式和用户扩展。它还能够编译 NumPy Python API 的一个重要子集,而无需显式的for循环。Numba 能够识别可以编译为机器代码的结构,同时替换对 CPython API 的调用,以便编译它不知道如何编译的函数。Numba 的jit函数选项nopython=True将允许的代码限制为可以在没有任何 Python C API 调用的情况下编译为 LLVM 的 Python 代码。jit(nopython=True)有一个更短的别名,numba.njit。
在前面的示例中,我们可以这样写:
from numba import float64, njit
@njit(float64(float64[:], float64[:]))
def mean_distance(x, y):
return (x - y).mean()
我鼓励您通过阅读Numba 的在线文档来了解更多。下一节将展示创建自定义 NumPy ufunc 对象的示例。
使用 Numba 创建自定义 numpy.ufunc 对象
numba.vectorize函数创建了编译后的 NumPy ufuncs,行为类似于内置的 ufuncs。让我们考虑一个numpy.add的 Python 实现:
from numba import vectorize
@vectorize
def nb_add(x, y):
return x + y
现在我们有:
In [13]: x = np.arange(10)
In [14]: nb_add(x, x)
Out[14]: array([ 0., 2., 4., 6., 8., 10., 12., 14., 16., 18.])
In [15]: nb_add.accumulate(x, 0)
Out[15]: array([ 0., 1., 3., 6., 10., 15., 21., 28., 36., 45.])
高级数组输入和输出
在 Ch 4: NumPy 基础:数组和矢量化计算中,我们熟悉了np.save和np.load用于将数组以二进制格式存储在磁盘上。还有一些其他更复杂用途的选项需要考虑。特别是,内存映射还具有额外的好处,使您能够对不适合 RAM 的数据集执行某些操作。
内存映射文件
内存映射文件是一种与磁盘上的二进制数据交互的方法,就好像它存储在内存中的数组中一样。NumPy 实现了一个类似 ndarray 的memmap对象,使得可以在不将整个数组读入内存的情况下读取和写入大文件的小段。此外,memmap具有与内存中数组相同的方法,因此可以替换许多算法中预期的 ndarray 的地方。
要创建新的内存映射,请使用函数np.memmap并传递文件路径、数据类型、形状和文件模式:
In [217]: mmap = np.memmap('mymmap', dtype='float64', mode='w+',
.....: shape=(10000, 10000))
In [218]: mmap
Out[218]:
memmap([[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]])
对memmap进行切片会返回磁盘上数据的视图:
In [219]: section = mmap[:5]
如果将数据分配给这些对象,它将被缓冲在内存中,这意味着如果您在不同的应用程序中读取文件,更改将不会立即反映在磁盘文件中。可以通过调用flush将任何修改同步到磁盘:
In [220]: section[:] = rng.standard_normal((5, 10000))
In [221]: mmap.flush()
In [222]: mmap
Out[222]:
memmap([[-0.9074, -1.0954, 0.0071, ..., 0.2753, -1.1641, 0.8521],
[-0.0103, -0.0646, -1.0615, ..., -1.1003, 0.2505, 0.5832],
[ 0.4583, 1.2992, 1.7137, ..., 0.8691, -0.7889, -0.2431],
...,
[ 0. , 0. , 0. , ..., 0. , 0. , 0. ],
[ 0. , 0. , 0. , ..., 0. , 0. , 0. ],
[ 0. , 0. , 0. , ..., 0. , 0. , 0. ]])
In [223]: del mmap
当内存映射超出范围并被垃圾回收时,任何更改也将刷新到磁盘。打开现有内存映射时,仍然必须指定数据类型和形状,因为文件只是一个没有任何数据类型信息、形状或步幅的二进制数据块:
In [224]: mmap = np.memmap('mymmap', dtype='float64', shape=(10000, 10000))
In [225]: mmap
Out[225]:
memmap([[-0.9074, -1.0954, 0.0071, ..., 0.2753, -1.1641, 0.8521],
[-0.0103, -0.0646, -1.0615, ..., -1.1003, 0.2505, 0.5832],
[ 0.4583, 1.2992, 1.7137, ..., 0.8691, -0.7889, -0.2431],
...,
[ 0. , 0. , 0. , ..., 0. , 0. , 0. ],
[ 0. , 0. , 0. , ..., 0. , 0. , 0. ],
[ 0. , 0. , 0. , ..., 0. , 0. , 0. ]])
内存映射也适用于结构化或嵌套数据类型,如结构化和记录数组中所述。
如果您在计算机上运行此示例,可能希望删除我们上面创建的大文件:
In [226]: %xdel mmap
In [227]: !rm mymmap
HDF5 和其他数组存储选项
PyTables 和 h5py 是两个 Python 项目,提供了与 NumPy 兼容的接口,用于以高效和可压缩的 HDF5 格式(HDF 代表分层数据格式)存储数组数据。您可以安全地将数百吉字节甚至数千吉字节的数据存储在 HDF5 格式中。要了解如何在 Python 中使用 HDF5,我建议阅读pandas 在线文档。
性能提示
将数据处理代码调整为使用 NumPy 通常会使事情变得更快,因为数组操作通常会取代否则相对极慢的纯 Python 循环。以下是一些提示,可帮助您从库中获得最佳性能:
-
将 Python 循环和条件逻辑转换为数组操作和布尔数组操作。
-
尽可能使用广播。
-
使用数组视图(切片)来避免复制数据。
-
利用 ufuncs 和 ufunc 方法。
如果仅使用 NumPy 无法获得所需的性能,请考虑在 C、FORTRAN 或 Cython 中编写代码。我经常在自己的工作中使用Cython作为一种获得类似 C 性能的方法,通常开发时间更短。
连续内存的重要性
虽然这个主题的全部范围有点超出了本书的范围,在一些应用中,数组的内存布局可以显著影响计算速度。这部分基于 CPU 的缓存层次结构的性能差异;访问连续内存块的操作(例如,对 C 顺序数组的行求和)通常是最快的,因为内存子系统将适当的内存块缓冲到低延迟的 L1 或 L2 CPU 缓存中。此外,NumPy 的 C 代码库中的某些代码路径已经针对连续情况进行了优化,可以避免通用的跨步内存访问。
说一个数组的内存布局是连续的意味着元素按照它们在数组中出现的顺序存储在内存中,关于 FORTRAN(列主序)或 C(行主序)排序。默认情况下,NumPy 数组被创建为 C 连续或者简单连续。一个列主序数组,比如一个 C 连续数组的转置,因此被称为 FORTRAN 连续。这些属性可以通过flags属性在 ndarray 上显式检查:
In [228]: arr_c = np.ones((100, 10000), order='C')
In [229]: arr_f = np.ones((100, 10000), order='F')
In [230]: arr_c.flags
Out[230]:
C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
In [231]: arr_f.flags
Out[231]:
C_CONTIGUOUS : False
F_CONTIGUOUS : True
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
In [232]: arr_f.flags.f_contiguous
Out[232]: True
在这个例子中,理论上,对这些数组的行求和对于arr_c应该比arr_f更快,因为行在内存中是连续的。在这里,我使用 IPython 中的%timeit进行检查(这些结果可能在你的机器上有所不同):
In [233]: %timeit arr_c.sum(1)
199 us +- 1.18 us per loop (mean +- std. dev. of 7 runs, 1000 loops each)
In [234]: %timeit arr_f.sum(1)
371 us +- 6.77 us per loop (mean +- std. dev. of 7 runs, 1000 loops each)
当你想要从 NumPy 中挤出更多性能时,这通常是一个值得投入一些努力的地方。如果你有一个数组,它没有所需的内存顺序,你可以使用copy并传递'C'或'F':
In [235]: arr_f.copy('C').flags
Out[235]:
C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
在构建一个数组的视图时,要记住结果不一定是连续的:
In [236]: arr_c[:50].flags.contiguous
Out[236]: True
In [237]: arr_c[:, :50].flags
Out[237]:
C_CONTIGUOUS : False
F_CONTIGUOUS : False
OWNDATA : False
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
- 一些数据类型的名称中有下划线。这是为了避免 NumPy 特定类型和 Python 内置类型之间的变量名冲突。
附录 B:关于 IPython 系统的更多内容
原文:
wesmckinney.com/book/ipython译者:飞龙
协议:CC BY-NC-SA 4.0
此开放访问网络版本的《Python 数据分析第三版》现已作为印刷版和数字版的伴侣提供。如果您发现任何勘误,请在此处报告。请注意,由 Quarto 生成的本站点的某些方面与 O’Reilly 的印刷版和电子书版本的格式不同。
如果您发现本书的在线版本有用,请考虑订购纸质版或无 DRM 的电子书以支持作者。本网站的内容不得复制或再生产。代码示例采用 MIT 许可,可在 GitHub 或 Gitee 上找到。
在第二章:Python 语言基础,IPython 和 Jupyter 笔记本中,我们讨论了使用 IPython shell 和 Jupyter 笔记本的基础知识。在本附录中,我们探索了 IPython 系统中的一些更深层次功能,可以从控制台或 Jupyter 中使用。
B.1 终端键盘快捷键
IPython 有许多用于导航提示的键盘快捷键(这些快捷键对于 Emacs 文本编辑器或 Unix bash shell 的用户来说是熟悉的),并与 shell 的命令历史交互。表 B.1 总结了一些最常用的快捷键。请参阅图 B.1 以查看其中一些示例,如光标移动。
表 B.1:标准 IPython 键盘快捷键
| 键盘快捷键 | 描述 |
|---|---|
| Ctrl-P 或向上箭头 | 在命令历史中向后搜索以当前输入文本开头的命令 |
| Ctrl-N 或向下箭头 | 在命令历史中向前搜索以当前输入文本开头的命令 |
| Ctrl-R | Readline 风格的反向历史搜索(部分匹配) |
| Ctrl-Shift-V | 从剪贴板粘贴文本 |
| Ctrl-C | 中断当前正在执行的代码 |
| Ctrl-A | 将光标移动到行首 |
| Ctrl-E | 将光标移动到行尾 |
| Ctrl-K | 从光标处删除文本直到行尾 |
| Ctrl-U | 放弃当前行上的所有文本 |
| Ctrl-F | 将光标向前移动一个字符 |
| Ctrl-B | 将光标向后移动一个字符 |
| Ctrl-L | 清屏 |

图 B.1:IPython shell 中一些键盘快捷键的示例
请注意,Jupyter 笔记本有一个完全独立的键盘快捷键集用于导航和编辑。由于这些快捷键的发展速度比 IPython 中的快捷键更快,我鼓励您探索 Jupyter 笔记本菜单中的集成帮助系统。
B.2 关于魔术命令
IPython 中的特殊命令(这些命令不是 Python 本身的一部分)被称为魔术命令。这些命令旨在简化常见任务,并使您能够轻松控制 IPython 系统的行为。魔术命令是以百分号 % 为前缀的任何命令。例如,您可以使用 %timeit 魔术函数检查任何 Python 语句(如矩阵乘法)的执行时间:
In [20]: a = np.random.standard_normal((100, 100))
In [20]: %timeit np.dot(a, a)
92.5 µs ± 3.43 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
魔术命令可以被视为在 IPython 系统中运行的命令行程序。其中许多具有额外的“命令行”选项,所有这些选项都可以使用 ? 查看(正如您可能期望的那样):
In [21]: %debug?
Docstring:
::
%debug [--breakpoint FILE:LINE] [statement [statement ...]]
Activate the interactive debugger.
This magic command support two ways of activating debugger.
One is to activate debugger before executing code. This way, you
can set a break point, to step through the code from the point.
You can use this mode by giving statements to execute and optionally
a breakpoint.
The other one is to activate debugger in post-mortem mode. You can
activate this mode simply running %debug without any argument.
If an exception has just occurred, this lets you inspect its stack
frames interactively. Note that this will always work only on the last
traceback that occurred, so you must call this quickly after an
exception that you wish to inspect has fired, because if another one
occurs, it clobbers the previous one.
If you want IPython to automatically do this on every exception, see
the %pdb magic for more details.
.. versionchanged:: 7.3
When running code, user variables are no longer expanded,
the magic line is always left unmodified.
positional arguments:
statement Code to run in debugger. You can omit this in cell
magic mode.
optional arguments:
--breakpoint <FILE:LINE>, -b <FILE:LINE>
Set break point at LINE in FILE.
魔术函数可以默认使用,无需百分号,只要没有定义与所讨论的魔术函数同名的变量。这个功能称为自动魔术,可以通过 %automagic 启用或禁用。
一些魔术函数的行为类似于 Python 函数,它们的输出可以分配给一个变量:
In [22]: %pwd
Out[22]: '/home/wesm/code/pydata-book'
In [23]: foo = %pwd
In [24]: foo
Out[24]: '/home/wesm/code/pydata-book'
由于 IPython 的文档可以从系统内部访问,我鼓励您使用%quickref或%magic来探索所有可用的特殊命令。此信息显示在控制台分页器中,因此您需要按q键退出分页器。表 B.2 突出显示了在 IPython 中进行交互式计算和 Python 开发时最关键的一些命令。
表 B.2:一些经常使用的 IPython 魔术命令
| 命令 | 描述 |
|---|---|
%quickref |
显示 IPython 快速参考卡 |
%magic |
显示所有可用魔术命令的详细文档 |
%debug |
进入最后一个异常回溯底部的交互式调试器 |
%hist |
打印命令输入(和可选输出)历史记录 |
%pdb |
在任何异常后自动进入调试器 |
%paste |
从剪贴板执行预格式化的 Python 代码 |
%cpaste |
打开一个特殊提示,用于手动粘贴要执行的 Python 代码 |
%reset |
删除交互式命名空间中定义的所有变量/名称 |
%page |
对对象进行漂亮打印并通过分页器显示 |
%run |
在 IPython 内部运行 Python 脚本 |
%prun |
使用cProfile执行并报告分析器输出 |
%time |
报告单个语句的执行时间 |
%timeit |
多次运行语句以计算集合平均执行时间;用于计时执行时间非常短的代码 |
%who, %who_ls, %whos |
显示交互式命名空间中定义的变量,具有不同级别的信息/详细程度 |
%xdel |
删除变量并尝试清除 IPython 内部对该对象的任何引用 |
%run 命令
您可以使用%run命令在 IPython 会话的环境中运行任何文件作为 Python 程序。假设您在script.py中存储了以下简单脚本:
def f(x, y, z):
return (x + y) / z
a = 5
b = 6
c = 7.5
result = f(a, b, c)
您可以通过将文件名传递给%run来执行此操作:
In [14]: %run script.py
脚本在空命名空间中运行(没有导入或其他变量定义),因此行为应与在命令行上使用python script.py运行程序相同。然后,文件中定义的所有变量(导入、函数和全局变量)(直到引发异常(如果有))将在 IPython shell 中可访问:
In [15]: c
Out [15]: 7.5
In [16]: result
Out[16]: 1.4666666666666666
如果 Python 脚本需要命令行参数(可以在sys.argv中找到),这些参数可以在文件路径之后传递,就像在命令行上运行一样。
注意
如果要让脚本访问已在交互式 IPython 命名空间中定义的变量,请使用%run -i而不是普通的%run。
在 Jupyter 笔记本中,您还可以使用相关的%load魔术函数,它将脚本导入到代码单元格中:
In [16]: %load script.py
def f(x, y, z):
return (x + y) / z
a = 5
b = 6
c = 7.5
result = f(a, b, c)
中断运行的代码
在运行任何代码时按下 Ctrl-C,无论是通过%run运行脚本还是长时间运行的命令,都会引发KeyboardInterrupt。这将导致几乎所有 Python 程序立即停止,除非在某些不寻常的情况下。
警告:
当一段 Python 代码调用了一些编译的扩展模块时,按下 Ctrl-C 并不总是会立即停止程序执行。在这种情况下,您要么等待控制返回到 Python 解释器,要么在更严重的情况下,在您的操作系统中强制终止 Python 进程(例如在 Windows 上使用任务管理器或在 Linux 上使用kill命令)。
从剪贴板执行代码
如果您正在使用 Jupyter 笔记本,您可以将代码复制粘贴到任何代码单元格中并执行。还可以在 IPython shell 中从剪贴板运行代码。假设您在其他应用程序中有以下代码:
x = 5
y = 7
if x > 5:
x += 1
y = 8
最可靠的方法是%paste和%cpaste魔术函数(请注意,这些在 Jupyter 中不起作用,因为您可以将文本复制并粘贴到 Jupyter 代码单元格中)。%paste获取剪贴板中的文本并将其作为单个块在 shell 中执行:
In [17]: %paste
x = 5
y = 7
if x > 5:
x += 1
y = 8
## -- End pasted text --
%cpaste类似,只是它为您提供了一个特殊的提示符,用于粘贴代码:
In [18]: %cpaste
Pasting code; enter '--' alone on the line to stop or use Ctrl-D.
:x = 5
:y = 7
:if x > 5:
: x += 1
:
: y = 8
:--
使用%cpaste块,您可以在执行代码之前粘贴尽可能多的代码。您可能决定使用%cpaste在执行代码之前查看粘贴的代码。如果您意外粘贴了错误的代码,可以通过按 Ctrl-C 键来退出%cpaste提示符。
B.3 使用命令历史
IPython 维护一个小型的磁盘数据库,其中包含您执行的每个命令的文本。这有各种用途:
-
使用最少的键入搜索、完成和执行先前执行的命令
-
在会话之间保留命令历史
-
将输入/输出历史记录记录到文件中
这些功能在 shell 中比在笔记本中更有用,因为笔记本通过设计在每个代码单元格中保留输入和输出的日志。
搜索和重用命令历史记录
IPython shell 允许您搜索和执行以前的代码或其他命令。这很有用,因为您经常会发现自己重复执行相同的命令,例如%run命令或其他代码片段。假设您已运行:
In[7]: %run first/second/third/data_script.py
然后探索脚本的结果(假设它成功运行),只发现您进行了错误的计算。找出问题并修改data_script.py后,您可以开始键入%run命令的几个字母,然后按下 Ctrl-P 键组合或向上箭头键。这将搜索命令历史记录,找到与您键入的字母匹配的第一个先前命令。多次按下 Ctrl-P 或向上箭头键将继续搜索历史记录。如果您错过了要执行的命令,不要担心。您可以通过按下 Ctrl-N 或向下箭头键来向前浏览命令历史记录。几次这样做后,您可能会开始在不经思考的情况下按下这些键!
使用 Ctrl-R 会为您提供与 Unix 风格 shell 中使用的readline相同的部分增量搜索功能,例如 bash shell。在 Windows 上,IPython 通过模拟readline功能来实现。要使用此功能,请按 Ctrl-R,然后键入要搜索的输入行中包含的几个字符:
In [1]: a_command = foo(x, y, z)
(reverse-i-search)`com': a_command = foo(x, y, z)
按下 Ctrl-R 将循环遍历每行的历史记录,匹配您键入的字符。
输入和输出变量
忘记将函数调用的结果分配给变量可能非常恼人。IPython 会将输入命令和输出 Python 对象的引用存储在特殊变量中。前两个输出分别存储在_(一个下划线)和__(两个下划线)变量中:
In [18]: 'input1'
Out[18]: 'input1'
In [19]: 'input2'
Out[19]: 'input2'
In [20]: __
Out[20]: 'input1'
In [21]: 'input3'
Out[21]: 'input3'
In [22]: _
Out[22]: 'input3'
输入变量存储在名为_iX的变量中,其中X是输入行号。
对于每个输入变量,都有一个相应的输出变量_X。因此,在输入行 27 之后,将有两个新变量,_27(用于输出)和_i27(用于输入):
In [26]: foo = 'bar'
In [27]: foo
Out[27]: 'bar'
In [28]: _i27
Out[28]: u'foo'
In [29]: _27
Out[29]: 'bar'
由于输入变量是字符串,因此可以使用 Python 的eval关键字再次执行它们:
In [30]: eval(_i27)
Out[30]: 'bar'
在这里,_i27指的是In [27]中输入的代码。
几个魔术函数允许您使用输入和输出历史记录。%hist打印全部或部分输入历史记录,带或不带行号。%reset清除交互式命名空间,可选地清除输入和输出缓存。%xdel魔术函数从 IPython 机制中删除对特定对象的所有引用。有关这些魔术的更多详细信息,请参阅文档。
警告:
在处理非常大的数据集时,请记住 IPython 的输入和输出历史可能导致其中引用的对象不会被垃圾回收(释放内存),即使您使用del关键字从交互式命名空间中删除变量。在这种情况下,谨慎使用%xdel和%reset可以帮助您避免遇到内存问题。
B.4 与操作系统交互
IPython 的另一个特性是它允许您访问文件系统和操作系统 shell。这意味着,您可以像在 Windows 或 Unix(Linux,macOS)shell 中一样执行大多数标准命令行操作,而无需退出 IPython。这包括 shell 命令、更改目录以及将命令的结果存储在 Python 对象(列表或字符串)中。还有命令别名和目录标记功能。
查看表 B.3 以获取调用 shell 命令的魔术函数和语法摘要。我将在接下来的几节中简要介绍这些功能。
表 B.3:IPython 与系统相关的命令
| 命令 | 描述 |
|---|---|
!cmd |
在系统 shell 中执行cmd |
output = !cmd args |
运行cmd并将 stdout 存储在output中 |
%alias alias_name cmd |
为系统(shell)命令定义别名 |
%bookmark |
使用 IPython 的目录标记系统 |
%cd |
将系统工作目录更改为传递的目录 |
%pwd |
返回当前系统工作目录 |
%pushd |
将当前目录放入堆栈并切换到目标目录 |
%popd |
切换到堆栈顶部弹出的目录 |
%dirs |
返回包含当前目录堆栈的列表 |
%dhist |
打印访问过的目录的历史记录 |
%env |
将系统环境变量作为字典返回 |
%matplotlib |
配置 matplotlib 集成选项 |
Shell 命令和别名
在 IPython 中以感叹号!开头的行告诉 IPython 在感叹号后执行系统 shell 中的所有内容。这意味着您可以删除文件(使用rm或del,取决于您的操作系统)、更改目录或执行任何其他进程。
您可以通过将用!转义的表达式分配给变量来存储 shell 命令的控制台输出。例如,在我连接到以太网上网的基于 Linux 的机器上,我可以将我的 IP 地址作为 Python 变量获取:
In [1]: ip_info = !ifconfig wlan0 | grep "inet "
In [2]: ip_info[0].strip()
Out[2]: 'inet addr:10.0.0.11 Bcast:10.0.0.255 Mask:255.255.255.0'
返回的 Python 对象ip_info实际上是一个包含各种控制台输出版本的自定义列表类型。
在使用!时,IPython 还可以在当前环境中定义的 Python 值进行替换。要做到这一点,请在变量名前加上美元符号$:
In [3]: foo = 'test*'
In [4]: !ls $foo
test4.py test.py test.xml
%alias魔术函数可以为 shell 命令定义自定义快捷方式。例如:
In [1]: %alias ll ls -l
In [2]: ll /usr
total 332
drwxr-xr-x 2 root root 69632 2012-01-29 20:36 bin/
drwxr-xr-x 2 root root 4096 2010-08-23 12:05 games/
drwxr-xr-x 123 root root 20480 2011-12-26 18:08 include/
drwxr-xr-x 265 root root 126976 2012-01-29 20:36 lib/
drwxr-xr-x 44 root root 69632 2011-12-26 18:08 lib32/
lrwxrwxrwx 1 root root 3 2010-08-23 16:02 lib64 -> lib/
drwxr-xr-x 15 root root 4096 2011-10-13 19:03 local/
drwxr-xr-x 2 root root 12288 2012-01-12 09:32 sbin/
drwxr-xr-x 387 root root 12288 2011-11-04 22:53 share/
drwxrwsr-x 24 root src 4096 2011-07-17 18:38 src/
您可以通过使用分号将它们分隔来像在命令行上一样执行多个命令:
In [558]: %alias test_alias (cd examples; ls; cd ..)
In [559]: test_alias
macrodata.csv spx.csv tips.csv
您会注意到,IPython 在会话关闭后会“忘记”您交互定义的任何别名。要创建永久别名,您需要使用配置系统。
目录标记系统
IPython 具有目录标记系统,使您可以保存常见目录的别名,以便您可以轻松跳转。例如,假设您想要创建一个指向本书补充材料的书签:
In [6]: %bookmark py4da /home/wesm/code/pydata-book
完成此操作后,当您使用%cd魔术时,您可以使用您定义的任何书签:
In [7]: cd py4da
(bookmark:py4da) -> /home/wesm/code/pydata-book
/home/wesm/code/pydata-book
如果书签名称与当前工作目录中的目录名称冲突,您可以使用-b标志来覆盖并使用书签位置。使用%bookmark的-l选项列出所有书签:
In [8]: %bookmark -l
Current bookmarks:
py4da -> /home/wesm/code/pydata-book-source
与别名不同,书签在 IPython 会话之间自动保留。
B.5 软件开发工具
除了作为交互式计算和数据探索的舒适环境外,IPython 还可以成为一般 Python 软件开发的有用伴侣。在数据分析应用中,首先重要的是拥有正确的代码。幸运的是,IPython 已经紧密集成并增强了内置的 Python pdb调试器。其次,您希望您的代码快速。为此,IPython 具有方便的集成代码计时和性能分析工具。我将在这里详细介绍这些工具。
交互式调试器
IPython 的调试器通过制表符补全、语法高亮显示和异常跟踪中每行的上下文增强了pdb。调试代码的最佳时机之一是在发生错误后立即进行调试。在异常发生后立即输入%debug命令会调用“事后”调试器,并将您放入引发异常的堆栈帧中:
In [2]: run examples/ipython_bug.py
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
/home/wesm/code/pydata-book/examples/ipython_bug.py in <module>()
13 throws_an_exception()
14
---> 15 calling_things()
/home/wesm/code/pydata-book/examples/ipython_bug.py in calling_things()
11 def calling_things():
12 works_fine()
---> 13 throws_an_exception()
14
15 calling_things()
/home/wesm/code/pydata-book/examples/ipython_bug.py in throws_an_exception()
7 a = 5
8 b = 6
----> 9 assert(a + b == 10)
10
11 def calling_things():
AssertionError:
In [3]: %debug
> /home/wesm/code/pydata-book/examples/ipython_bug.py(9)throws_an_exception()
8 b = 6
----> 9 assert(a + b == 10)
10
ipdb>
进入调试器后,您可以执行任意 Python 代码并探索每个堆栈帧中的所有对象和数据(这些对象和数据由解释器“保持活动”)。默认情况下,您从发生错误的最低级别开始。通过输入u(向上)和d(向下),您可以在堆栈跟踪的级别之间切换:
ipdb> u
> /home/wesm/code/pydata-book/examples/ipython_bug.py(13)calling_things()
12 works_fine()
---> 13 throws_an_exception()
14
执行%pdb命令会使 IPython 在任何异常发生后自动调用调试器,这是许多用户会发现有用的模式。
在开发代码时使用调试器也很有帮助,特别是当您需要设置断点或逐步执行函数或脚本以检查每个步骤的行为时。有几种方法可以实现这一点。第一种方法是使用带有-d标志的%run,在执行传递的脚本中的任何代码之前调用调试器。您必须立即输入s(步进)以进入脚本:
In [5]: run -d examples/ipython_bug.py
Breakpoint 1 at /home/wesm/code/pydata-book/examples/ipython_bug.py:1
NOTE: Enter 'c' at the ipdb> prompt to start your script.
> <string>(1)<module>()
ipdb> s
--Call--
> /home/wesm/code/pydata-book/examples/ipython_bug.py(1)<module>()
1---> 1 def works_fine():
2 a = 5
3 b = 6
在此之后,您可以自行决定如何处理文件。例如,在前面的异常中,我们可以在调用works_fine函数之前设置断点,并通过输入c(继续)运行脚本直到达到断点:
ipdb> b 12
ipdb> c
> /home/wesm/code/pydata-book/examples/ipython_bug.py(12)calling_things()
11 def calling_things():
2--> 12 works_fine()
13 throws_an_exception()
此时,您可以通过输入n(下一步)进入works_fine()或执行works_fine()以前进到下一行:
ipdb> n
> /home/wesm/code/pydata-book/examples/ipython_bug.py(13)calling_things()
2 12 works_fine()
---> 13 throws_an_exception()
14
然后,我们可以步入throws_an_exception并前进到发生错误的行,并查看作用域中的变量。请注意,调试器命令优先于变量名称;在这种情况下,使用!作为前缀来检查它们的内容:
ipdb> s
--Call--
> /home/wesm/code/pydata-book/examples/ipython_bug.py(6)throws_an_exception()
5
----> 6 def throws_an_exception():
7 a = 5
ipdb> n
> /home/wesm/code/pydata-book/examples/ipython_bug.py(7)throws_an_exception()
6 def throws_an_exception():
----> 7 a = 5
8 b = 6
ipdb> n
> /home/wesm/code/pydata-book/examples/ipython_bug.py(8)throws_an_exception()
7 a = 5
----> 8 b = 6
9 assert(a + b == 10)
ipdb> n
> /home/wesm/code/pydata-book/examples/ipython_bug.py(9)throws_an_exception()
8 b = 6
----> 9 assert(a + b == 10)
10
ipdb> !a
5
ipdb> !b
6
根据我的经验,熟练掌握交互式调试器需要时间和实践。请参阅表 B.4 以获取调试器命令的完整目录。如果您习惯使用 IDE,您可能会发现基于终端的调试器一开始有点严格,但随着时间的推移会有所改善。一些 Python IDE 具有出色的 GUI 调试器,因此大多数用户都可以找到适合自己的工具。
表 B.4:Python 调试器命令
| 命令 | 动作 |
|---|---|
h(elp) |
显示命令列表 |
help |
显示的文档 |
c(ontinue) |
恢复程序执行 |
q(uit) |
在不执行任何其他代码的情况下退出调试器 |
b(reak) |
在当前文件的行设置断点 |
b |
在指定文件中的第行设置断点 |
s(tep) |
步入函数调用 |
n(ext) |
执行当前行并前进到当前级别的下一行 |
u(p)/d(own) |
在函数调用堆栈中向上/向下移动 |
a(rgs) |
显示当前函数的参数 |
debug |
在新的(递归)调试器中调用语句 |
l(ist) |
显示当前位置和堆栈当前级别的上下文 |
w(here) |
打印当前位置的完整堆栈跟踪上下文 |
调试器的其他用法
还有几种有用的调用调试器的方法。第一种是使用特殊的set_trace函数(以pdb.set_trace命名),基本上是一个“穷人的断点”。以下是两个您可能希望将其放在某处以供您一般使用的小技巧(可能将它们添加到您的 IPython 配置文件中,就像我做的那样):
from IPython.core.debugger import Pdb
def set_trace():
Pdb(.set_trace(sys._getframe().f_back)
def debug(f, *args, **kwargs):
pdb = Pdb()
return pdb.runcall(f, *args, **kwargs)
第一个函数set_trace提供了一个方便的方法,在代码的某个地方设置断点。您可以在代码的任何部分使用set_trace,以便在需要临时停止以更仔细地检查它时使用(例如,在异常发生之前):
In [7]: run examples/ipython_bug.py
> /home/wesm/code/pydata-book/examples/ipython_bug.py(16)calling_things()
15 set_trace()
---> 16 throws_an_exception()
17
键入c(继续)将使代码正常恢复,不会造成任何伤害。
我们刚刚看过的debug函数使您可以轻松地在任意函数调用上调用交互式调试器。假设我们编写了一个类似以下内容的函数,并且希望逐步执行其逻辑:
def f(x, y, z=1):
tmp = x + y
return tmp / z
通常使用f看起来像f(1, 2, z=3)。要代替进入f,请将f作为debug的第一个参数传递,然后是要传递给f的位置参数和关键字参数:
In [6]: debug(f, 1, 2, z=3)
> <ipython-input>(2)f()
1 def f(x, y, z):
----> 2 tmp = x + y
3 return tmp / z
ipdb>
这两个技巧多年来为我节省了很多时间。
最后,调试器可以与%run一起使用。通过使用%run -d运行脚本,您将直接进入调试器,准备设置任何断点并启动脚本:
In [1]: %run -d examples/ipython_bug.py
Breakpoint 1 at /home/wesm/code/pydata-book/examples/ipython_bug.py:1
NOTE: Enter 'c' at the ipdb> prompt to start your script.
> <string>(1)<module>()
ipdb>
添加带有行号的-b会启动已经设置了断点的调试器:
In [2]: %run -d -b2 examples/ipython_bug.py
Breakpoint 1 at /home/wesm/code/pydata-book/examples/ipython_bug.py:2
NOTE: Enter 'c' at the ipdb> prompt to start your script.
> <string>(1)<module>()
ipdb> c
> /home/wesm/code/pydata-book/examples/ipython_bug.py(2)works_fine()
1 def works_fine():
1---> 2 a = 5
3 b = 6
ipdb>
计时代码:%time 和%timeit
对于规模较大或运行时间较长的数据分析应用程序,您可能希望测量各个组件或单个语句或函数调用的执行时间。您可能希望获得一个报告,其中列出了在复杂过程中占用最多时间的函数。幸运的是,IPython 使您能够在开发和测试代码时方便地获取这些信息。
手动使用内置的time模块及其函数time.clock和time.time来计时代码通常是乏味和重复的,因为您必须编写相同的无聊样板代码:
import time
start = time.time()
for i in range(iterations):
# some code to run here
elapsed_per = (time.time() - start) / iterations
由于这是一个常见操作,IPython 有两个魔术函数%time和%timeit,可以为您自动化这个过程。
%time运行一次语句,报告总执行时间。假设我们有一个大型字符串列表,并且我们想比较不同方法选择所有以特定前缀开头的字符串。这里是一个包含 600,000 个字符串和两种相同方法的列表,只选择以'foo'开头的字符串:
# a very large list of strings
In [11]: strings = ['foo', 'foobar', 'baz', 'qux',
....: 'python', 'Guido Van Rossum'] * 100000
In [12]: method1 = [x for x in strings if x.startswith('foo')]
In [13]: method2 = [x for x in strings if x[:3] == 'foo']
看起来它们在性能上应该是一样的,对吧?我们可以使用%time来确保:
In [14]: %time method1 = [x for x in strings if x.startswith('foo')]
CPU times: user 49.6 ms, sys: 676 us, total: 50.3 ms
Wall time: 50.1 ms
In [15]: %time method2 = [x for x in strings if x[:3] == 'foo']
CPU times: user 40.3 ms, sys: 603 us, total: 40.9 ms
Wall time: 40.6 ms
Wall time(“墙钟时间”的缩写)是主要关注的数字。从这些时间中,我们可以推断出存在一些性能差异,但这不是一个非常精确的测量。如果您尝试自己多次%time这些语句,您会发现结果有些变化。要获得更精确的测量结果,请使用%timeit魔术函数。给定一个任意语句,它有一个启发式方法多次运行语句以产生更准确的平均运行时间(这些结果在您的系统上可能有所不同):
In [563]: %timeit [x for x in strings if x.startswith('foo')]
10 loops, best of 3: 159 ms per loop
In [564]: %timeit [x for x in strings if x[:3] == 'foo']
10 loops, best of 3: 59.3 ms per loop
这个看似无害的例子说明了值得了解 Python 标准库、NumPy、pandas 和本书中使用的其他库的性能特征。在规模较大的数据分析应用程序中,这些毫秒将开始累积!
%timeit特别适用于分析具有非常短执行时间的语句和函数,甚至可以到微秒(百万分之一秒)或纳秒(十亿分之一秒)的级别。这些可能看起来是微不足道的时间,但当然,一个耗时 20 微秒的函数被调用 100 万次比一个耗时 5 微秒的函数多花费 15 秒。在前面的例子中,我们可以直接比较这两个字符串操作以了解它们的性能特征:
In [565]: x = 'foobar'
In [566]: y = 'foo'
In [567]: %timeit x.startswith(y)
1000000 loops, best of 3: 267 ns per loop
In [568]: %timeit x[:3] == y
10000000 loops, best of 3: 147 ns per loop
基本分析:%prun 和%run -p
代码剖析与计时代码密切相关,只是它关注于确定时间花费在哪里。主要的 Python 剖析工具是cProfile模块,它与 IPython 没有特定关联。cProfile执行程序或任意代码块,同时跟踪每个函数中花费的时间。
在命令行上常用的一种使用cProfile的方式是运行整个程序并输出每个函数的聚合时间。假设我们有一个脚本,在循环中执行一些线性代数运算(计算一系列 100×100 矩阵的最大绝对特征值):
import numpy as np
from numpy.linalg import eigvals
def run_experiment(niter=100):
K = 100
results = []
for _ in range(niter):
mat = np.random.standard_normal((K, K))
max_eigenvalue = np.abs(eigvals(mat)).max()
results.append(max_eigenvalue)
return results
some_results = run_experiment()
print('Largest one we saw: {0}'.format(np.max(some_results)))
您可以通过命令行运行以下脚本来使用cProfile:
python -m cProfile cprof_example.py
如果尝试这样做,您会发现输出按函数名称排序。这使得很难了解大部分时间花费在哪里,因此使用-s标志指定排序顺序很有用:
$ python -m cProfile -s cumulative cprof_example.py
Largest one we saw: 11.923204422
15116 function calls (14927 primitive calls) in 0.720 seconds
Ordered by: cumulative time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.001 0.001 0.721 0.721 cprof_example.py:1(<module>)
100 0.003 0.000 0.586 0.006 linalg.py:702(eigvals)
200 0.572 0.003 0.572 0.003 {numpy.linalg.lapack_lite.dgeev}
1 0.002 0.002 0.075 0.075 __init__.py:106(<module>)
100 0.059 0.001 0.059 0.001 {method 'randn')
1 0.000 0.000 0.044 0.044 add_newdocs.py:9(<module>)
2 0.001 0.001 0.037 0.019 __init__.py:1(<module>)
2 0.003 0.002 0.030 0.015 __init__.py:2(<module>)
1 0.000 0.000 0.030 0.030 type_check.py:3(<module>)
1 0.001 0.001 0.021 0.021 __init__.py:15(<module>)
1 0.013 0.013 0.013 0.013 numeric.py:1(<module>)
1 0.000 0.000 0.009 0.009 __init__.py:6(<module>)
1 0.001 0.001 0.008 0.008 __init__.py:45(<module>)
262 0.005 0.000 0.007 0.000 function_base.py:3178(add_newdoc)
100 0.003 0.000 0.005 0.000 linalg.py:162(_assertFinite)
...
仅显示输出的前 15 行。通过扫描cumtime列向下阅读,可以最轻松地看出每个函数内部花费了多少总时间。请注意,如果一个函数调用另一个函数,时钟不会停止。cProfile记录每个函数调用的开始和结束时间,并使用这些时间来生成时间。
除了命令行用法外,cProfile还可以以编程方式用于剖析任意代码块,而无需运行新进程。IPython 具有方便的接口,可以使用%prun命令和-p选项来%run。%prun接受与cProfile相同的“命令行选项”,但会剖析一个任意的 Python 语句,而不是整个*.py*文件:
In [4]: %prun -l 7 -s cumulative run_experiment()
4203 function calls in 0.643 seconds
Ordered by: cumulative time
List reduced from 32 to 7 due to restriction <7>
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.643 0.643 <string>:1(<module>)
1 0.001 0.001 0.643 0.643 cprof_example.py:4(run_experiment)
100 0.003 0.000 0.583 0.006 linalg.py:702(eigvals)
200 0.569 0.003 0.569 0.003 {numpy.linalg.lapack_lite.dgeev}
100 0.058 0.001 0.058 0.001 {method 'randn'}
100 0.003 0.000 0.005 0.000 linalg.py:162(_assertFinite)
200 0.002 0.000 0.002 0.000 {method 'all' of 'numpy.ndarray'}
类似地,调用%run -p -s cumulative cprof_example.py具有与命令行方法相同的效果,只是您无需离开 IPython。
在 Jupyter 笔记本中,您可以使用%%prun魔术(两个%符号)来剖析整个代码块。这会弹出一个单独的窗口,显示剖析输出。这在获取可能快速答案的情况下很有用,比如“为什么那个代码块运行时间如此之长?”
在使用 IPython 或 Jupyter 时,还有其他可用的工具可帮助使剖析更易于理解。其中之一是SnakeViz,它使用 D3.js 生成剖析结果的交互式可视化。
逐行剖析函数
在某些情况下,您从%prun(或其他基于cProfile的剖析方法)获得的信息可能无法完全说明函数的执行时间,或者可能非常复杂,以至于按函数名称汇总的结果难以解释。对于这种情况,有一个名为line_profiler的小型库(可通过 PyPI 或其中一个软件包管理工具获取)。它包含一个 IPython 扩展,可以启用一个新的魔术函数%lprun,用于计算一个或多个函数的逐行剖析。您可以通过修改 IPython 配置(请参阅 IPython 文档或附录后面的配置部分)来启用此扩展,包括以下行:
# A list of dotted module names of IPython extensions to load.
c.InteractiveShellApp.extensions = ['line_profiler']
您还可以运行以下命令:
%load_ext line_profiler
line_profiler可以以编程方式使用(请参阅完整文档),但在 IPython 中交互使用时可能效果最好。假设您有一个名为prof_mod的模块,其中包含执行一些 NumPy 数组操作的以下代码(如果要重现此示例,请将此代码放入一个新文件prof_mod.py中):
from numpy.random import randn
def add_and_sum(x, y):
added = x + y
summed = added.sum(axis=1)
return summed
def call_function():
x = randn(1000, 1000)
y = randn(1000, 1000)
return add_and_sum(x, y)
如果我们想了解add_and_sum函数的性能,%prun给出以下结果:
In [569]: %run prof_mod
In [570]: x = randn(3000, 3000)
In [571]: y = randn(3000, 3000)
In [572]: %prun add_and_sum(x, y)
4 function calls in 0.049 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.036 0.036 0.046 0.046 prof_mod.py:3(add_and_sum)
1 0.009 0.009 0.009 0.009 {method 'sum' of 'numpy.ndarray'}
1 0.003 0.003 0.049 0.049 <string>:1(<module>)
这并不特别启发人。启用line_profiler IPython 扩展后,将可用一个新命令%lprun。使用方式的唯一区别是我们必须指示%lprun要剖析哪个函数或函数。一般语法是:
%lprun -f func1 -f func2 statement_to_profile
在这种情况下,我们想要剖析add_and_sum,所以我们运行:
In [573]: %lprun -f add_and_sum add_and_sum(x, y)
Timer unit: 1e-06 s
File: prof_mod.py
Function: add_and_sum at line 3
Total time: 0.045936 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
3 def add_and_sum(x, y):
4 1 36510 36510.0 79.5 added = x + y
5 1 9425 9425.0 20.5 summed = added.sum(axis=1)
6 1 1 1.0 0.0 return summed
这可能更容易解释。在这种情况下,我们对我们在语句中使用的相同函数进行了分析。查看前面的模块代码,我们可以调用call_function并对其进行分析,以及add_and_sum,从而获得代码性能的完整图片:
In [574]: %lprun -f add_and_sum -f call_function call_function()
Timer unit: 1e-06 s
File: prof_mod.py
Function: add_and_sum at line 3
Total time: 0.005526 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
3 def add_and_sum(x, y):
4 1 4375 4375.0 79.2 added = x + y
5 1 1149 1149.0 20.8 summed = added.sum(axis=1)
6 1 2 2.0 0.0 return summed
File: prof_mod.py
Function: call_function at line 8
Total time: 0.121016 s
Line # Hits Time Per Hit % Time Line Contents
==============================================================
8 def call_function():
9 1 57169 57169.0 47.2 x = randn(1000, 1000)
10 1 58304 58304.0 48.2 y = randn(1000, 1000)
11 1 5543 5543.0 4.6 return add_and_sum(x, y)
作为一个一般准则,我倾向于使用%prun(cProfile)进行“宏”分析,以及%lprun(line_profiler)进行“微”分析。了解这两个工具是值得的。
注意
您必须明确指定要使用%lprun对其进行分析的函数名称的原因是“跟踪”每行的执行时间的开销很大。跟踪不感兴趣的函数可能会显著改变分析结果。
B.6 使用 IPython 进行高效代码开发的提示
以一种方便开发、调试和最终交互使用的方式编写代码可能对许多用户来说是一种范式转变。有一些程序性细节,比如代码重新加载可能需要一些调整,以及编码风格方面的考虑。
因此,实现本节中描述的大多数策略更多地是一种艺术而不是科学,需要您进行一些实验来确定一种对您有效的编写 Python 代码的方式。最终,您希望以一种方便的方式构建代码,以便进行迭代使用,并能够尽可能轻松地探索运行程序或函数的结果。我发现,专为 IPython 设计的软件比仅用作独立命令行应用程序运行的代码更容易使用。当出现问题并且您必须诊断您或其他人可能在几个月或几年前编写的代码中的错误时,这变得尤为重要。
重新加载模块依赖项
在 Python 中,当您键入import some_lib时,将执行some_lib中的代码,并将在新创建的some_lib模块命名空间中存储定义的所有变量、函数和导入。下次使用import some_lib时,您将获得对现有模块命名空间的引用。在交互式 IPython 代码开发中可能出现困难的潜在问题是,当您运行依赖于其他模块的脚本时,您可能已经进行了更改。假设我在test_script.py中有以下代码:
import some_lib
x = 5
y = [1, 2, 3, 4]
result = some_lib.get_answer(x, y)
如果您执行%run test_script.py然后修改some_lib.py,下次执行%run test_script.py时,您仍将获得some_lib.py的旧版本,因为 Python 的“一次加载”模块系统。这种行为与其他一些数据分析环境(如 MATLAB)不同,后者会自动传播代码更改。¹ 为了应对这种情况,您有几种选择。第一种方法是使用标准库中的importlib模块中的reload函数:
import some_lib
import importlib
importlib.reload(some_lib)
这尝试在每次运行test_script.py时为您提供some_lib.py的新副本(但也有一些情况下不会)。显然,如果依赖关系更深入,可能会在各个地方插入reload的用法有点棘手。对于这个问题,IPython 有一个特殊的dreload函数(不是一个魔术函数)用于对模块进行“深”(递归)重新加载。如果我运行some_lib.py然后使用dreload(some_lib),它将尝试重新加载some_lib以及其所有依赖项。不幸的是,这并不适用于所有情况,但当适用时,它比不得不重新启动 IPython 要好。
代码设计提示
这没有简单的配方,但以下是我在自己的工作中发现有效的一些高级原则。
保持相关对象和数据活动
看到一个为命令行编写的程序的结构有点像下面这样并不罕见:
from my_functions import g
def f(x, y):
return g(x + y)
def main():
x = 6
y = 7.5
result = x + y
if __name__ == '__main__':
main()
如果我们在 IPython 中运行这个程序,你能看出可能出现什么问题吗?完成后,main函数中定义的结果或对象将无法在 IPython shell 中访问。更好的方法是让main中的任何代码直接在模块的全局命名空间中执行(或者在if __name__ == '__main__':块中执行,如果你希望该模块也可以被导入)。这样,当你%run代码时,你将能够查看main中定义的所有变量。这相当于在 Jupyter 笔记本中的单元格中定义顶级变量。
扁平比嵌套更好
深度嵌套的代码让我想到洋葱的许多层。在测试或调试一个函数时,你必须剥开多少层洋葱才能到达感兴趣的代码?“扁平比嵌套更好”的想法是 Python 之禅的一部分,它也适用于为交互式使用开发代码。尽可能使函数和类解耦和模块化使它们更容易进行测试(如果你正在编写单元测试)、调试和交互使用。
克服对更长文件的恐惧
如果你来自 Java(或其他类似语言)背景,可能会被告知保持文件短小。在许多语言中,这是一个明智的建议;长长度通常是一个不好的“代码异味”,表明可能需要重构或重新组织。然而,在使用 IPython 开发代码时,处理 10 个小但相互关联的文件(每个文件不超过 100 行)通常会给你带来更多的头痛,而不是 2 或 3 个较长的文件。较少的文件意味着较少的模块需要重新加载,编辑时也减少了文件之间的跳转。我发现维护较大的模块,每个模块具有高度的内部内聚性(代码都涉及解决相同类型的问题),更加有用和符合 Python 风格。当朝着一个解决方案迭代时,当然有时将较大的文件重构为较小的文件是有意义的。
显然,我不支持将这个论点推向极端,即将所有代码放在一个庞大的文件中。为大型代码库找到一个明智和直观的模块和包结构通常需要一些工作,但在团队中正确地完成这一点尤为重要。每个模块应该在内部具有内聚性,并且应该尽可能明显地找到负责每个功能区域的函数和类。
B.7 高级 IPython 功能
充分利用 IPython 系统可能会导致你以稍微不同的方式编写代码,或者深入了解配置。
配置文件和配置
IPython 和 Jupyter 环境的外观(颜色、提示、行之间的间距等)和行为的大部分方面都可以通过一个广泛的配置系统进行配置。以下是一些可以通过配置完成的事项:
-
更改颜色方案
-
更改输入和输出提示的外观,或者在
Out之后和下一个In提示之前删除空行 -
执行一系列 Python 语句(例如,你经常使用的导入或任何其他你希望每次启动 IPython 时发生的事情)
-
启用始终开启的 IPython 扩展,比如
line_profiler中的%lprun魔术 -
启用 Jupyter 扩展
-
定义你自己的魔术或系统别名
IPython shell 的配置在特殊的ipython_config.py文件中指定,这些文件通常位于用户主目录中的*.ipython/目录中。配置是基于特定的profile执行的。当您正常启动 IPython 时,默认情况下会加载default profile*,存储在profile_default目录中。因此,在我的 Linux 操作系统上,我的默认 IPython 配置文件的完整路径是:
/home/wesm/.ipython/profile_default/ipython_config.py
要在您的系统上初始化此文件,请在终端中运行:
ipython profile create default
我将不会详细介绍此文件的内容。幸运的是,它有注释描述每个配置选项的用途,因此我将让读者自行调整和自定义。另一个有用的功能是可以拥有多个配置文件。假设您想要为特定应用程序或项目定制一个备用 IPython 配置。创建新配置涉及键入以下内容:
ipython profile create secret_project
完成后,编辑新创建的profile_secret_project目录中的配置文件,然后启动 IPython,如下所示:
$ ipython --profile=secret_project
Python 3.8.0 | packaged by conda-forge | (default, Nov 22 2019, 19:11:19)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.22.0 -- An enhanced Interactive Python. Type '?' for help.
IPython profile: secret_project
与以往一样,在线 IPython 文档是了解更多有关配置文件和配置的绝佳资源。
Jupyter 的配置略有不同,因为您可以将其笔记本与 Python 以外的语言一起使用。要创建类似的 Jupyter 配置文件,请运行:
jupyter notebook --generate-config
这将在您的主目录中的*.jupyter/jupyter_notebook_config.py*目录中写入一个默认配置文件。编辑后,您可以将其重命名为不同的文件,例如:
$ mv ~/.jupyter/jupyter_notebook_config.py ~/.jupyter/my_custom_config.py
在启动 Jupyter 时,您可以添加--config参数:
jupyter notebook --config=~/.jupyter/my_custom_config.py
B.8 结论
当您在本书中逐步学习代码示例并提高自己作为 Python 程序员的技能时,我鼓励您继续了解 IPython 和 Jupyter 生态系统。由于这些项目旨在帮助用户提高生产力,您可能会发现一些工具,使您比仅使用 Python 语言及其计算库更轻松地完成工作。
您还可以在nbviewer 网站上找到大量有趣的 Jupyter 笔记本。
- 由于模块或包可能在特定程序的许多不同位置导入,Python 在第一次导入模块时缓存模块的代码,而不是每次执行模块中的代码。否则,模块化和良好的代码组织可能会导致应用程序效率低下。