达内教育Django全套教程
Django
1.Django 介绍
1.1 组件
Django 包含的组件如下:
- 基本配置文件/路由系统
- 模型层(M)/模板层(T)/视图层(V)
Cookies和Session- 分页及分发邮件
Admin管理后台
1.2 用途
Django 能够实现所有 HTTP 请求处理。
- 网站/微信公众号/小程序后端开发
- 人工智能平台融合
1.3 版本
Django官网:The web framework for perfectionists with deadlines | Django (djangoproject.com)Django中文文档参考网站:一译 (yiyibooks.cn)- 版本:
- 教程版本:2.2.12
1.4 安装
1.4.1 在线安装
pip install django==2.2.12
1.4.2 离线安装
# 将安装包下载到本地
# 解压缩并进入到解压缩后的目录
# 执行如下命令进行安装
python setup.py install
# 执行如下命令检查是否安装成功
pip freeze | grep -i 'Django'
2.Django 的项目结构
2.1 创建项目
-
成功安装
Django后,虚拟机终端会有django-admin命令 -
执行
django-admin startproject [项目名]即可创建出对应项目的文件夹# 创建 mysite1 项目 django-admin startproject mysite1
2.2 启动服务
- 启动[测试开发阶段]
-
终端 cd 进入到项目文件夹
-
进入到项目文件夹后,执行
python manage.py runserver [端口]启动django服务,端口不指定即为8000。
-
浏览器访问
http://127.0.0.1:8000可看到django的启动页面。
-
2.3 关闭服务
-
关闭服务[测试开发阶段]
-
方式一[在runserver启动终端下]:
执行
ctrl + c可退出Django服务。 -
方式二[在其他终端下]:
执行
sudo lsof -i:8000查询出Django的进程id。执行
kill -9Django进程的id。
-
2.4 项目结构解析

mysite
├── db.sqlite3 [Django默认的数据库,sqlite]
├── manage.py
└── mysite
├── __init__.py
├── __pycache__
│ ├── __init__.cpython-310.pyc
│ ├── settings.cpython-310.pyc
│ ├── urls.cpython-310.pyc
│ └── wsgi.cpython-310.pyc
├── settings.py
├── urls.py
└── wsgi.py
manage.py
包含项目管理的子命令,如:
# 启动服务
python manage.py runserver
# 创建应用
python manage.py startapp
# 生成迁移文件
python manage.py makemigrations
# 数据迁移
python manage.py migrate
...
# 直接执行 python manage.py 会列出所有Django的子命令

项目同名文件夹 - mysite/mysite
__init__:Python包的初始化文件。wsgi.py:web服务网关配置文件,Django正式启动时,需要用到。urls.py: 项目的主路由配置,Http请求进入Django时,优先调用该文件。settings.py: 项目的配置文件,包含项目启动时需要的配置。
项目配置文件 - settings.py
-
settings.py 包含了 Django 项目启动时所有的配置项。
-
配置项分为公有配置和自定义配置。
-
配置项格式:BASE_DIR = ‘xxxx’。
-
公有配置,Django官方提供的基础配置,可到如下网站查询。
https://docs.djangoproject.com/en/2.2/ref/settings/ALLOWED_HOSTS
设置允许访问到本项目的
host头值。-
示例:如果要在局域网其他主机也能访问此主机的Django服务,启动方式如下:
(1) python3 manage.py runserver 0.0.0.0:5000
(2) 指定网络设备如果内网环境下其他主机想正常访问该站点,需要添加 ALLOWED_HOSTS = [‘内网IP’]

在 windows 主机访问虚拟机启动的 Django 项目,显示主机ip应该添加到 ALLOWED_HOSTS,在 settings.py 添加后,再次访问,页面能够被正常文件。

LANGUAGE_CODE
设置项目的页面展示语言,简体中文设置为:
zh-Hans。TIME_ZONE
用于指定当前服务端时区,默认为格林威治时间(UTC),中国地区设置为
Asia/Shanghai。BASE_DIR
用于绑定当前项目的绝对路径(动态计算出来的),所有文件夹都可以依赖此路径。
DEBUG
用于配置
Django项目的启动模式,取值:True,表示开发环境中使用;False,表示当前项目运行在生产环境中。INSTALLED_APPS
指定当前项目中安装的应用列表。
MIDDLEWARE
用于注册中间件。
TEMPLATES
用于指定模板的配置信息。
DATABASES
用于指定数据库的配置信息。
ROOT_URLCONF
用于配置主
url配置,ROOT_URLCONF = 'mysite.urls'。 -
3.URL 和 视图函数
3.1 URL
定义:即统一资源定位符 Uniform Resource Locator
作用:用来表示互联网上某个资源的地址
URL的一般语法为:
# portocol:协议(http、https、file)
# hostname:主机名
# port:端口
# path:路由地址
# query:查询的参数,可有多个参数,用 & 隔开,每个参数的名和值用 = 隔开。
# fragment:信息片段,字符串,用于指定网络资源中的片段。例如一个网页中有多个名词解释,可使用fragment直接定位到某一名词解释。
protocol://hostname[:port]/path[?query][#fragment]
例如:
# 直接定位到页面指定信息片段的位置
https://docs.djangoproject.com/en/4.2/#how-the-documentation-is-organized
3.2 处理 URL 请求
以URL(http://127.0.0.1:8000/page/2003)为例。
Django从配置文件中根据ROOT_URLCONF找到主路由文件;默认情况下,该文件为项目同名目录下的urls.py。Django加载主路由文件中的urlpatterns变量[包含很多路由的数组]。- 依次匹配
urlpatterns中的path,匹配到第一个合适的中断后续匹配。 - 匹配成功-调用对应的视图函数处理请求,返回响应。
- 匹配失败-返回
404响应。
主路由 - urls.py
from django.contrib import admin
from django.urls import path
from . import views
urlpatterns = [
path('admin/', admin.site.urls),
path('page/2023', views.page_2023),
path('page/2024', views.page_2024)
]
3.3 视图函数
定义:视图函数是用于接收一个浏览器请求(HttpRequest对象)并通过HttpResponse对象返回响应的函数,此函数可以接收浏览器请求并根据业务逻辑返回响应的响应内容给浏览器。
语法:
def xxx_view(request[,其他参数]):
return HttpResponse 对象
样例:
from django.http import HttpResponse
def page_2023(request):
html = "这是第一个页面
"
return HttpResponse(html)

4.路由配置
settings.py 中的 ROOT_URLCONF 指定了主路由配置列表 urlpatterns 的文件位置。
urlpatterns = [
path('admin/', admin.site.urls),
path('page/2023/', views.page_2023),
path('page/2024/', views.page_2024),
... # 配置URL和视图函数
]
4.1 path 函数
path函数定义
# 导入
from django.urls import path
# 语法
path(route,views,[name=])
# 参数
route:字符串类型,匹配请求路径
views:指定路径所对应视图函数的名称
name:为路由地址起别名,在模板中地址反向解析时使用
4.2 path 转换器
# 语法
<转换器类型:自定义名>
# 作用
如果转换器类型匹配到对应类型的数据,则将数据按照关键字传参的方式传递给视图函数
# 例如
path('page/\',views.xxx)
转换器列表
| 转换器类型 | 作用 | 样例 |
|---|---|---|
| str | 匹配除了’/‘之外的非空字符串 | v1/users/匹配 /v1/users/guoxiaonao |
| int | 匹配0或者任意正整数,返回一个int | page/ 匹配 /page/100 |
| slug | 匹配任意由 ASCII字母或数字以及连字符和下划线组成的短标签 | detail/ 匹配 /detail/this-is-django |
| path | 匹配非空字段,包括路径分隔符’/’ | v1/users/ 匹配 /v1/goods/a/b/c |
转换器测试
int 转换器测试
# URL
urlpatterns = [
...
path('page/', views.page_n)
]
# 视图函数
def page_n(request,number):
html = "这是第{number}个页面
".format(number=number)
return HttpResponse(html)

str 转换器测试
# URL
urlpatterns = [
...
path('page/', views.page_welcome),
]
# 视图函数
def page_welcome(request, name):
html = "hello {name}!
".format(name=name)
return HttpResponse(html)

slug 转换器测试
# URL
urlpatterns = [
...
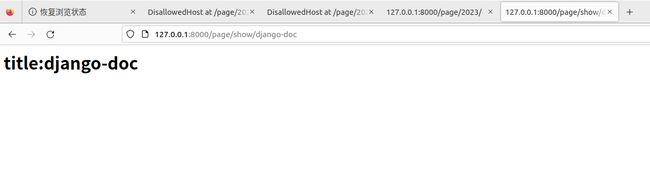
path('page/show/', views.page_show)
]
# 视图函数
def page_show(request, slug):
print('2')
html = "title:{slug}
".format(slug=slug)
return HttpResponse(html)
# 注意
使用slug时,如果前方存在str的匹配,会进入str的视图函数,因为slug也是字符串
path 转换器测试
# URL
urlpatterns = [
...
path('page/path/', views.path_mate)
]
# 视图函数
def path_mate(request, path):
html = "path:{path}".format(path=path)
return HttpResponse(html)

转换器练习
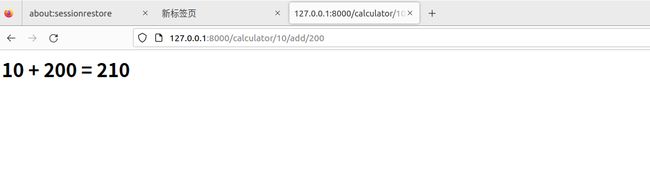
# 定义一个路由器的格式为: http:127.0.0.1:8000/整数/操作字符串[add/sub/mul]/整数,从路由中提取数据,做相应的操作后返回给浏览器
# 代码如下:
## URL
urlpatterns = [
...
path('calculator///', views.calculator)
]
## 视图函数
def calculator(request, number1, method, number2):
if method not in ['add', 'sub', 'mul']:
return HttpResponse("method {method} is not support!
".format(method=method))
if method == 'add':
html = "{number1} + {number2} = {result}
".format(number1=number1, number2=number2, result=number1 + number2)
elif method == 'sub':
html = "{number1} - {number2} = {result}
".format(number1=number1, number2=number2, result=number1 - number2)
else:
html = "{number1} * {number2} = {result}
".format(number1=number1, number2=number2, result=number1 * number2)
return HttpResponse(html)

4.3 re_path 函数
re_path 函数定义
在 url 的匹配过程中可以使用正则表达式进行精确匹配。
# 导入
from django.urls import re_path
# 语法
re_path(reg,view,[name=])
# 说明
正则表达式为命名分组模式(?Ppattern);匹配提取参数后用关键字传参方式传递给视图函数
# 注意
使用正则表达式时,需要尽量精准,因此在正则表达式的末尾一定要添加 $ ,否则会导致出现不想要的匹配效果
re_path 函数示例
# 实现效果:使用 re_path 路由函数匹配数字和字符串,定义路由为 http:127.0.0.1:8000/整数/操作字符串[add/sub/mul]/整数,匹配整数均为两位数的操作
# URL
from django.urls import path,re_path
urlpatterns = [
...
re_path(r'calculator/(?P\d{1,2})/(?P\w+)/(?P\d{1,2})$', views.calculator_reg),
path('calculator///', views.calculator),
]
# 视图函数
def calculator(request, number1, method, number2):
if method not in ['add', 'sub', 'mul']:
return HttpResponse("method {method} is not support!
".format(method=method))
if method == 'add':
html = "{number1} + {number2} = {result}
".format(number1=number1, number2=number2, result=number1 + number2)
elif method == 'sub':
html = "{number1} - {number2} = {result}
".format(number1=number1, number2=number2, result=number1 - number2)
else:
html = "{number1} * {number2} = {result}
".format(number1=number1, number2=number2, result=number1 * number2)
return HttpResponse(html)
def calculator_reg(request, number1, method, number2):
html = "正则匹配
"
return HttpResponse(html)

re_path 练习
# 实现:
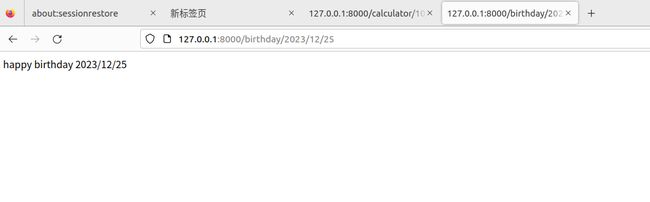
# 1.访问地址:http://127.0.0.1:8000/birthday/四位数字/一到两位数字/一到两位数字
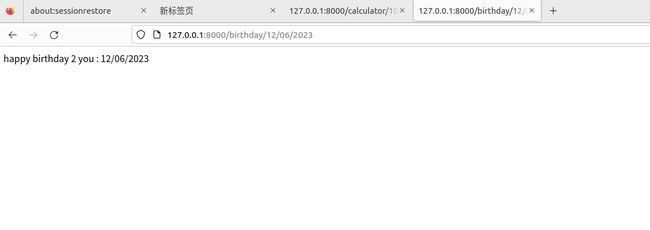
# 2.访问地址:http://127.0.0.1:8000/birthday/一到两位数字/一到两位数字/四位数字
# 访问路由页面展示:生日是 xxxx年 xx月 xx日
# URL
urlpatterns = [
...
# http://127.0.0.1:8000/birthday/四位数字/一到两位数字/一到两位数字
re_path('birthday/(?P\d{4})/(?P\d{1,2})/(?P\d{1,2})$', views.happy_birthday),
# http://127.0.0.1:8000/birthday/一到两位数字/一到两位数字/四位数字
re_path('birthday/(?P\d{1,2})/(?P\d{1,2})/(?P\d{4})$', views.happy_birthday_2),
]
# 视图函数
def happy_birthday(request, year, month, day):
html = "happy birthday {year}/{month}/{day}".format(year=year, month=month, day=day)
return HttpResponse(html)
def happy_birthday_2(request, day, month, year):
html = "happy birthday 2 you : {day}/{month}/{year}".format(day=day, month=month, year=year)
return HttpResponse(html)
5.请求和响应
5.1 HTTP 协议的请求和响应
- 请求是指浏览器端通过 HTTP 协议发送给服务器端的数据。
- 响应是指服务器端接收到请求后做相应的处理后再回复给浏览器端的数据。
请求中的方法
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | GET | 请求指定的页面信息,并返回实体主体。 |
| 2 | HEAD | 类似于GET请求,只不过返回的响应中没有具体的内容,用于获取报头。 |
| 3 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件),数据被包含在请求体中,POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档内的内容。 |
| 5 | DELETE | 请求服务器删除指定的页面。 |
| 6 | CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 |
| 7 | OPTIONS | 允许客户端查看服务器的性能。 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测或判断。 |
5.2 Django中的请求
- 请求在Django中实则就是视图函数的第一个参数,即HttpRequest对象。
- Django接收到http协议的请求后,会根据请求数据报文创建HttpRequest对象。
- HttpRequest对象通过属性描述了请求的所有相关信息。
- path_info:url字符串。
- methods:字符串,表示HTTP请求方法,常用值:
GET、POST。 - COOKIES:Python字典,包含所有的cookie,键和值都为字符串。
- session:类似于字典的对接,表示当前的会话。
- body:字符串,请求体的内容(POST或PUT)。
- scheme:请求协议(‘http/https’)。
- request.get_full_path():请求的完整路径。
- request.META:请求中的元数据(消息头)。
- request.META[‘REMOTE_ADDR’]:客户端IP地址。

5.3 响应
响应状态码的英文为HTTP Status Code,以下为常见的HTTP状态码:
- 200,请求成功。
- 301,永久重定向,资源(网页等)被永久转移到其他URL。
- 302,临时重定向。
- 404,请求的资源(网页等)不存在。
- 500,内部服务器错误。
HTTP状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用,HTTP状态码共分为五种五种类型:
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
5.4 Django中的响应对象
构造函数格式:
HttpResponse(content=响应体,content_type=响应体数据类型,status=状态码)
作用:
向客户端浏览器返回响应,同时携带响应体内容。
常用的 Content-Type 如下:
text/html(默认的,html文件)text/plain(纯文本)text/css(css文件)text/javascript(javascript文件)multipart/form-data(文件提交)application/json(json传输)application/xml(xml文件)
在编辑器中,使用不同的响应类即可。

5.5 GET请求和POST请求
定义:无论是 GET 还是 POST,统一都由视图函数接收请求,通过判断request.method 区分具体的请求动作。
样例
if request.method == 'GET':
处理GET请求时的业务逻辑
elif request.method == 'POST':
处理POST请求时的业务逻辑
else:
其他请求业务逻辑
5.5.1 GET处理
-
GET请求动作,一般用于向服务器获取数据。
-
能够产生GET请求的场景:
-
GET请求方式中,如果有数据需要传递给服务器,通常会用查询字符串(Query String)传递:
-
URL格式:xxx?参数名1=值1&参数名2=值2…
如:
http://127.0.0.1:8000/page1?a=100&b=200 -
服务器端接收参数,获取客户端请求GET请求提交的数据。
方法示例:
request.GET['参数名'] request.GET.get('参数名','默认值') # 适用于参数有多个值的情况 request.GET.getlist('参数名')

-
5.5.2 POST处理
-
POST请求动作,一般用于向服务器提交大量/隐私数据。
-
客户端通过表单等POST请求将数据传递给服务器端,如:
-
使用post方式接收客户端数据。
request.POST['参数名'] request.POST.get('参数名','') request.POST.getlist('参数名')POST请求需要取消CSRF验证,否则Django会拒绝客户端发来的POST请求,报403响应。
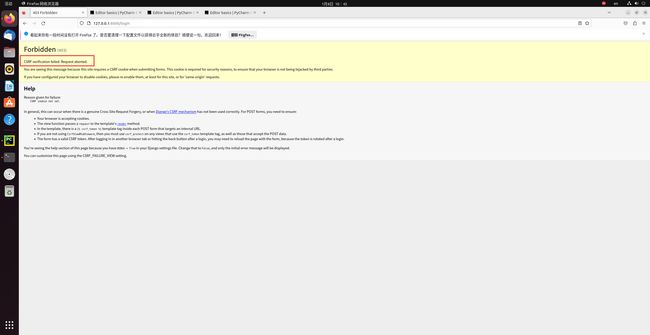
settings.py文件中,注释掉
django.middleware.csrf.CsrfViewMiddleware。


6.静态文件
-
静态文件配置 - settings.py 中
# 静态文件:CSS、JavaScript、Images ## 静态文件路由配置 STATIC_URL = '/static/' ## 静态文件存储路径配置 STATICFILES_DIRS = (os.path.join(BASE_DIR,"static"),) # 需要在指定的路径下创建static目录,存放静态文件进行访问
7.Django应用及分布式路由
- 应用在 Django 项目中是一个独立的业务模块,可以包含自己的路由、视图、模板、模型。
7.1 创建应用
- 用
manage.py中的子命令startapp创建应用文件夹。 - 在
settings.py中的INSTALLED_APPS列表中配置安装此应用。
7.2 分布式路由
Django 中,主路由配置文件(urls.py)可以不处理用户具体路由,主路由配置文件可以做请求的分发(分布式请求处理),具体的请求可以由各自的应用来处理。
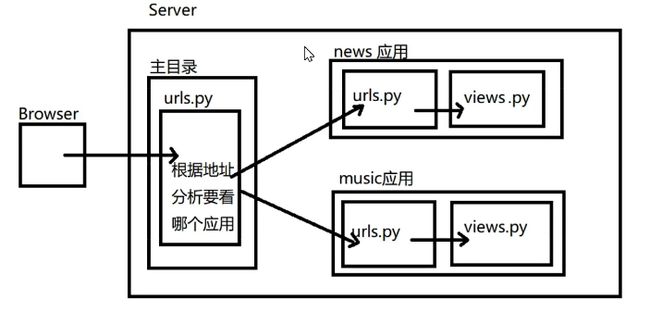
分布式路由配置步骤:
-
主路由中调用
include函数。# 语法:inclued('app名称.url模块名') # 作用:用于将当前路由转到各个应用的路由配置文件的 urlpatterns 进行分布式处理 # 示例如下: from django.urls import path, re_path, include urlpatterns = [ path('admin/', admin.site.urls), ... path('demo/', include('demo.urls')) ] -
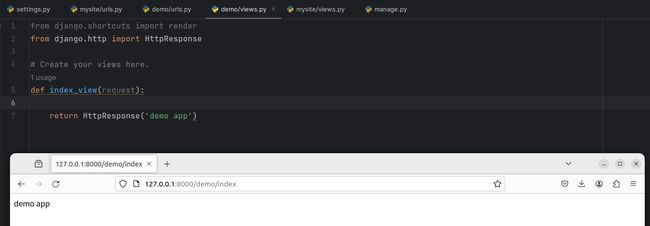
应用下配置
urls.py。# 应用下手动创建urls.py 文件,内容结构同主路由完全一致 from django.urls import path from . import views urlpatterns = [ path('index', views.index_view) ] -
访问页面路由。
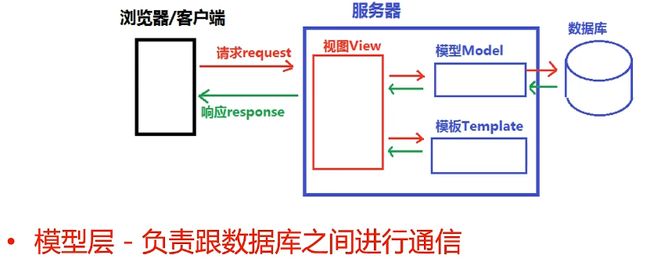
8.模型层及ORM介绍
Django 的 MTV 结构。
8.1 Django 配置 mysql
8.1.1 依赖安装
-
安装
mysqlclient[版本 mysqlclient 1.3.13以上] -
安装前需要确认
ubuntu是否已安装python3-dev和default-libmysqlclient-dev。python3-dev # 1.检查安装第三方包的情况 sudo apt list --installed | grep -E 'libmysqlclient-dev|python3-dev' # 2.未安装则进行安装 sudo apt install python3-dev default-libmysqlclient-dev -
安装
mysqlclient第三方包。sudo pip3 install mysqlclient
8.1.2 Django配置
-
修改settings.py文件中 DATABASES 配置。
DATABASES = { 'default':{ 'ENGINE':'django.db.backends.mysql', 'HOST':'host_ip', 'PORT':3306, 'USER':'username', 'password':'password', 'NAME':'datanabaseNmae' } } -
执行数据库的迁移操作。
python manage.py migrate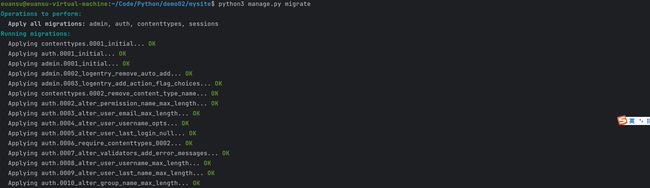
8.1.3 迁移中出现的报错
进行数据库迁移时,报错:SystemError: PY_SSIZE_T_CLEAN macro must be defined for ‘#’ formats,这个是Python3.10不兼容引起的,需要升级用到的 mysqlclient 包到最新版本。

解决方法:升级mysqlclient到最新版。

再次进行数据库迁移,正常无报错。

8.2 模型
8.2.1 模型
- 模型是一个Python类,它是由django.db.models.Model派生出的子类。
- 一个模型类代表数据库中的一张表。
- 模型类中每一个类属性都代表数据库中的一个字段。
- 模型是数据交互的接口,是表示和操作数据库的方法和方式。
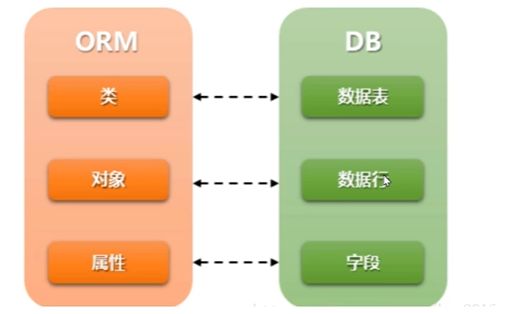
8.2.2 ORM框架
- 定义:ORM(Object Relational Mapping)即对象关系映射,它是一种程序技术,允许你使用类和对象对数据库进行操作,从而避免通过SQL语句操作数据库。
- 作用:
- 简历模型类和表之间的对应关系,允许我们通过面向对象的方式来操作数据库。
- 根据设计的模型类生成数据库中的表格。
- 通过简单的配置就可以进行数据库的切换。
- 优点:
- 只需要面向对象编程,不需要面向数据库编写代码。
- 实现了数据模型与数据库的解耦,屏蔽了不同数据库操作上的差异。
8.2.3 ORM框架使用
-
创建APP应用,创建的应用需要在settings.py中进行注册。
创建APP应用
python manage.py startapp bookstore注册应用
INSTALLED_APPS = [ ... 'bookstore' ] -
编写数据库ORM模型。
在 bookstore 应用的模型文件 models.py 中添加如下代码。
class Books(models.Model): title = models.CharField("书名", max_length=50, default='') price = models.DecimalField("定价", max_digits=7, decimal_places=2, default=0.0) -
数据库迁移。
# 生成迁移文件 python manage.py makemigrations # 执行迁移脚本,同步数据库 python manage.py migrate
8.2.4 ORM概念及操作
8.2.4.1 模型类定义
from django.db import models
class 模型类名(models.Model):
字段名 = models.字段类型(字段选项)
8.2.4.2 基础字段
- BooleanField()
- 数据库类型:tinyint(1)
- 编程语言中:使用 True 或者False 来表示值
- 在数据库中:使用1或0来表示具体的值
- CharFild()
- 数据库类型:varchar
- 注意:必须要指定 max_length 参数值
- DateField()
- 数据库类型:date
- 作用:表示日期
- 参数:
- auto_now:每次保存对象时,自动设置该字段为当前时间(取值:True/False)
- auto_now_add:当对象第一次被创建时,自动设置当前时间(取值:True/False)
- default:设置当前时间值(取值:字符串格式时间,如”2019-6-1“)
- 以上三个参数只能多选一。
- DateTimeField()
- 数据库类型:datetime(6)
- 作用:表示日期和时间
- 参数同 DateField
- FloatField()
- 数据库类型:double
- 编程语言和数据库中都是用小数表示值
- DecimalField()
- 数据库类型:decimal(x,y)
- 编程语言中:使用小数表示该列的值
- 在数据库中:使用小数
- 参数:
- max_digits:位数总数,包括小数点后的位数,该数必须大于等于decimal_palces
- decimal_places:小数点后的数字数量
- EmailField()
- 数据库类型:varchar
- 编程语言和数据库中使用字符串
- IntegerField()
- 数据库类型:int
- 编程语言和数据库中使用整数
- ImageField()
- 数据库类型:varchar(100)
- 作用:在数据库中为了保存图片的路径
- 编程语言和数据库中使用字符串
- TextField()
- 数据库类型:longtext
- 作用:表示不定长的字符数据
代码示例:
class Author(models.Model):
name = models.CharField("姓名", max_length=11, default='')
age = models.IntegerField("年龄")
emal = models.EmailField("邮箱")
8.2.4.3 字段选项
- 字段选项,指定创建的列的额外的信息
- 允许出现多个字段选项,多个选项之间使用
,隔开 - 注:字段选项的官方文档地址(https://docs.djangoproject.com/en/2.2/ref/models/fields/#field-options)
- primary_key
- 如果设置为 True,表示该列为主键,如果指定一个字段为主键,则此数据库表不会创建 id 字段。
- blank
- 设置为 True 时,字段可以为空,设置为 False 时,字段为必填项。
- null
- 如果设置为 True,表示该列值允许为空。
- 默认为 False,如果此选项为False,建议加入 default 选项来设置默认值。
- default
- 设置所在列的默认值,如果字段选项 null = False,建议添加此项。
- db_index
- 如果设置为 True,表示为该列增加索引
- unique
- 如果设置为 True,表示该字段在数据库中的值必须是独一无二的。
- db_column
- 指定列的名称,如果不指定的话则采用属性名作为列名。
- verbose_name
- 设置此字段在 admin 界面上显示的名称。
代码示例:
# 创建一个属性,表示用户名称,长度40个字符,必须是唯一的,不能为空,添加索引
name = models.CharField("用户名称", max_length=40, unique=True, null=False, default='', db_index=True)
8.2.4.4 Meta类
- 使用内部Meta类,来给模型赋予属性,Meta类下有很多内建的类属性,可对模型类做一些控制。
- db_table,修改当前模型对应的表名。
- unique_together,用于组合多个字段,这些字段组成的值,在数据表中是独一无二的。
- 注:Meta类官方文档(https://docs.djangoproject.com/zh-hans/2.2/ref/models/options/)
代码示例:
class Books(models.Model):
title = models.CharField("书名", max_length=50, default='')
price = models.DecimalField("定价", max_digits=7, decimal_places=2, default=0.0)
info = models.CharField("描述", max_length=100, default='')
class Meta:
db_table = 'book' # 可以改变当前模型类对应的表名

8.2.4.5 创建数据
Django ORM 使用一种直观的方式把数据库表中的数据表示成 Python 对象。
创建数据中每一条记录就是创建一个数据对象。
# 方法一
MyModel.objects.create(属性1=值1,属性2=值2,...)
# 成功:返回创建好的实体对象
# 失败:抛出异常
# 方法二
# 创建MyModel 实例对象,并调用 save() 进行保存
obj = MyModel(属性=值)
obj.属性 = 值
obj.save()
Django提供了一个交互式的操作项目叫 Django Shell,它能够在交互模式用项目工程的代码执行相应的操作。
注意:项目代码发生变化时,需要重新进入Django Shell。
启动方式:
python manage.py shell
代码示例:
from bookstore.models import Books
# 方式一
Books.objects.create(title='大江大河', price=53.00, info='大江大河', pub='东海工业出版社', market_price=55.00)
# 方式二
bookObj = Books(title='Django入门教程', price=53.00, info='大江大河', pub='清华大学出版社', market_price=55.00)
bookObj.info = 'Django入门教程'
bookObj.save()
数据库中对应出现两条记录。

8.2.4.6 查询方法
-
数据库的查询需要使用管理器对象进行。
-
通过 MyModel.objects 管理器方法调用查询方法。
方法 说明 all() 查询全部记录,返回QuerySet查询对象 get() 查询符合条件的单一记录 filter() 查询符合条件的多条记录 exclude() 查询符合条件之外的全部记录 -
all()方法
用法:MyModel.objects.all()
作用:查询 MyModel 实体中所有的数据,等同于 select * from table
返回值:QuerySet 容器对象,内部存放 MyModel 实例
代码示例:
from bookstore.models import Books books = Books.objects.all() for book in books: print("书名",book.title, "出版社", book.pub)
也可以在 ORM 模型中定义
__str__方法,直接返回表中的信息。class Books(models.Model): title = models.CharField("书名", max_length=50, default='', unique=True) price = models.DecimalField("定价", max_digits=7, decimal_places=2, default=0.0) info = models.CharField("描述", max_length=100, default='') pub = models.CharField("出版社", max_length=100, null=False, default='') market_price = models.DecimalField("图书零售价", max_digits=7, decimal_places=2, default=0.0) class Meta: # 可以改变当前模型类对应的表名 db_table = 'book' def __str__(self): return '%s_%s_%s_%s' % (self.title, self.info, self.pub, self.market_price)
-
values(‘列1’,‘列2’)
用法:MyModel.objects.values(…)
作用:查询部分列的数据并返回,等同于 select 列1,列2 from table
返回值:QuerySet,返回查询结果容器,容器内存字典,每个字典代表一条数据,格式为:{‘列1’:‘值1’,‘列2’:‘值2’}
代码示例:
from bookstore.models import Books books = Books.objects.values('title','pub') print(books)
-
values_list(‘列1’,‘列2’)
用法:MyModel.objects.values_list(…)
作用:返回元组形式的查询结果,等同于select 列1,列2 from table
返回值:QuerySet 容器对象,内存存放元组。
会将查询出来的数据封装到元组中,再封装到查询集合 QuerySet 中。
代码示例:
books = Books.objects.values_list('title','pub') print(books)
-
order_by()
用法:MyModel.objects.order_by(’-列’,‘列’)
作用:与 all() 方法不同,它会用 SQL 语句的 ORDER BY 子句对查询结果进行根据某个字段选择性的进行排序。
说明:默认是按照升序排序,降序排序则需要在列前增加
-表示。代码示例:
from bookstore.models import Books books = Books.objects.order_by('title') print(books) books = Books.objects.order_by('-title') print(books)
-
filter(条件)
语法:MyModel.objects.filter(属性1=值1,属性2=值2)
作用:返回包含此条件的全部数据集
返回值:QuerySet 容器对象,内部存放 MyModel 示例
说明:当多个属性在一起时为 “与” 关系
代码示例:
# 查询书中出版社为"清华大学出版社"的图书 from bookstore.models import Books books = Books.objects.filter(pub='清华大学出版社') print(books) # 查询Author实体中name为王老师并且年龄为28岁的 from bookstore.models import Author authores = Author.objects.all() print(authores) authores = Author.objects.filter(name='王老师',age=28) print(authores)

-
exclude(条件)
语法:MyModel.objects.exclude(条件)
作用:返回不包含此条件的全部数据集
代码示例:
from bookstore.models import Author,Books books = Books.objects.exclude(pub='清华大学出版社') print(books)
-
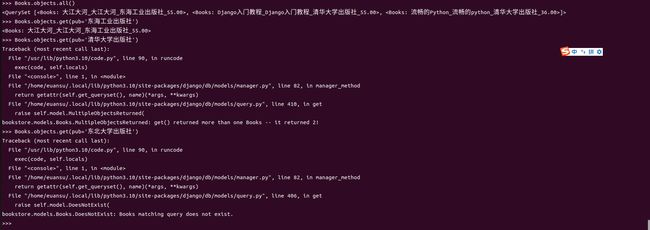
get(条件)
语法:MyModel.objects.get(条件)
作用:返回满足条件的唯一数据
说明:该方法只能返回一条数据,查询结果多于一条数据则抛出
Model.MultipleObjectsReturned异常,查询结果如果没有数据则抛出Model.DoesNotExist异常代码示例:
8.2.4.7 查询谓词
定义:做更灵活的条件查询时需要使用查询谓词。
说明:每一个查询谓词是一个独立的查询功能。
-
__exact,等值匹配
代码示例
Books.objects.filter(id__exact=1) # 等同于 select * from author where id = 1 -
__contains,包含指定值
Books.objects.filter(name__contains='Python') # 等同于 select * from books where name link '%Python%' -
__startswith,以 xxx 开始
-
__endswith,以 xxx 结束
-
__gt,大于指定值
Author.objects.filter(age__gt=50) # 等同于 select * from author where age > 50 -
__gte,大于等于
-
__lt,小于
-
__lte,小于等于
-
__in,查找数据是否在指定范围内
Author.objects.filter(country__in=['中国','日本','韩国']) # 等同于 select * from author where country in ('中国','日本','韩国') -
__range,查找数据是否在指定的区间范围内
# 查找年龄在某一区间内的所有作者 Author.objects.filter(age__range=(35,50)) # 等同于 select * from author where age between 35 and 50
8.2.4.8 更新操作
-
修改单个实体的某些字段值的步骤:
- 查,通过 get() 得到要修改的实体对象。
- 改,通过 对象.属性 的方式修改数据。
- 保存,通过 对象.save() 保存数据。
代码示例:

-
批量更新数据
- 直接调用 QuerySet 的 update(属性=值) 实现批量修改
代码示例:

8.2.4.9 删除操作
-
单个数据删除的步骤:
- 查找查询结果对应的一个数据对象
- 调用这个数据对象的 delete() 方法实现删除。
代码示例:

-
批量删除的步骤:
- 查找查询结果集中满足条件的全部 QuerySet 查询集合对象
- 调用查询集合对象的 delete() 方法实现删除
代码示例:

-
伪查询
- 通常不会轻易在业务里把数据真正删掉,取而代之的是做伪删除,即在表中添加一个布尔型字段(is_active),默认是True,执行删除时,将欲删除数据的 is_active 字段设置为 False。
- 注意:用伪删除时,确保显示数据的地方,均添加了 is_active = True 的过滤查询。
8.2.4.10 F对象和Q对象
F对象
-
一个F对象代表数据库中某条记录的字段的信息
-
作用:
- 通常是对数据库中的字段值在不获取的情况下进行操作
- 用于类属性(字段)之间的比较
-
语法
from django.db.models import F F('列名') -
代码示例:
# 示例1:更新Book示例中所有的零售价涨10元 from django.db.models import F from bookstore.models import Book Book.objects.all().update(market_price=F('market_price')+10)
# 示例2:对数据库中两个字段的值进行比较,列出那些书的零售价高于定价 from django.db.models import F from bookstore.models import Book Book.objects.filter(market_price__gt=F('price'))
Q对象
-
当在获取查询结果集使用复杂的逻辑或|、逻辑非 ~ 等操作时可以借助Q对象进行操作
-
作用:在条件中用来实现除 and(&) 以外的 or(|) 或 not(~) 操作
-
语法:
from django.db.models import Q Q(条件1)|(Q条件2) # 条件1成立或条件2成立 Q(条件1)&Q(条件2) # 条件1和条件2同时成立 Q(条件1)&~Q(条件2) # 条件1成立且条件2不成立 -
代码示例:
# 示例1:查找清华大学出版社的书或价格低于50的书 Book.objects.filter(Q(pub='清华大学出版社')|Q(price__lt=50)) # 示例2:查找不··· 是机械出版社且价格低于50的书 Book.objects.filter(Q(price__lt=50)|~Q(pub='清华大学出版社'))
8.2.4.11 聚合查询和原生数据库操作
聚合查询
聚合查询是指对一个数据表中的一个字段的数据进行部分或全部进行统计查询,查 bookstore 数据表中的全部书的平均价格,查询所有书的总个数等,都要使用聚合查询。
聚合查询分为:整表聚合、分组聚合
聚合查询 - 整表聚合
不带分组的聚合查询是指将全部数据进行集中统计查询。
聚合函数[需要导入]:
# 导入方法
from django.db.models import *
# 聚合函数:Sum、Avg、Count、Max、Min
语法:MyModel.objects.aggregate(结果变量名=聚合函数(‘列’))
返回结果:结果变量名和值组成的字典,格式为:{‘结果变量名’:值}
代码示例:

聚合查询 - 分组聚合
分组聚合是指通过计算查询结果中每一个对象所关联的对象集合,从而得出总计值(也可以是平均值或总和),即为查询集的每一项生成聚合。
语法:QuerySet.annotate(结果变量名=聚合函数(‘列’))
返回值:QuerySet
代码示例:

原生数据库操作
Django 页可以支持直接使用SQL语句的方式通信数据库。
查询:使用 MyModel.objects.raw() 进行数据库的查询操作。
语法:MyModel.objects.raw(sql语句,拼接参数)
返回值:RawQuery 集合对象,只支持基础的操作,比如循环
代码示例:

原生数据库操作 - SQL注入
使用原生语句时小心SQL注入。
定义:用户通过数据上传,将恶意的SQL语句提交给服务器,从而达到攻击效果。
案例1:用户在搜索图表的SQL传入 1 or 1=1,可以查询出所有的图书数据。


SQL注入防范
错误 -> s1 = Book.objects.raw(‘select * from book where id = %s’%(‘1 or 1=1’))
正确 -> s1 = Book.objects.raw(‘select * from book where id = %s’,[‘1 or 1=1’])
![]()
原生数据库操作 - cursor
完全跨过模型类操作数据库 - 查询/更新/删除
-
导入
cursor所在的包。from django.db import connection -
用创建
cursor类的构造函数创建cursor对象,再使用cursor对象,为保证在出现异常时能释放cursor资源,通常使用with语句进行创建操作。from django.db import connection with connection.cursor() as cur: cur.excute('执行SQL语句','拼接参数')
代码示例:
![]()


原生SQL查询防止SQL注入
