手撕JavaWeb服务器02——静态资源的访问与解析
前言
上期文章,我们做了一个简单的 web 服务器,实现了对一个请求的简单响应。这篇文章我们会在之前的基础上,实现对服务器中静态资源的访问,包括 HTML、以及HTML中包含的 css、js 和图片。

如何返回一个HTML格式的响应
HTML 的全称为超文本标记语言,我们可以理解为按照某种规则对多媒体资源进行排版显示的文本格式,浏览器访问的各种页面也是基于 HTML 。那么我们如何返回一个 HTML 格式的响应呢?
蓝色的 Hello World
我们还是从 Hello World 开始,这次我们返回给浏览器一个蓝色的 Hello World(因为我们地球就是蓝色星球,哈哈)。
在这之前我们需要先准备一个 HTML 文件,内容如下:
DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Hello Worldtitle>
<style>
body {
text-align: center;
}
h1 {
font-size: 72px;
color: blue;
}
style>
head>
<body>
<h1>Hello, World!h1>
body>
html>
在浏览器中打开之后的效果如下:

HTTP响应和蓝色的 Hello World
浏览器和我们的 Web 服务器依赖 http 协议进行数据传输。如果我们要给浏览器返回上面的 html 文件,还需要将这个文件弄成 HTTP 格式的信息,再返回给我们的浏览器。那么 HTTP 协议是什么格式的呢?
HTTP 的报文分两种,一种是客户端向服务端发送的请请求报文,另一种则是服务端向客户端返回的响应报文。由于我们的“蓝色Hello World”是作为响应信息返回给浏览器(即客户端),所以这里我们先分析响应报文。以下是一个响应报文的示例:
HTTP/1.1 200 OK
Date: Sat, 16 Jan 2024 14:36:19 GMT
Server: Apache/2.4.6 (CentOS)
Content-Length: 44
Content-Type: text/html; charset=utf-8
Sample Page
Hello, World!
下面我们对报文进行简单的解析:
- 响应信息的第一行叫做状态行,包含了 HTTP 协议的版本信息,HTTP/1.1 表示的是当前使用的 HTTP1.1版本的协议。200 是状态码,后面紧跟着的是状态码代表的信息,这里表示请求成功。
- 从第二行开始是 key-value 格式的响应头,用于传输与响应相关的一些信息:
- Date: Sat, 16 Jan 2024 14:36:19 GMT:指明了响应的日期和时间。
- Server: Apache/2.4.6 (CentOS):表示服务器的信息,这里显示了使用的服务器软件及版本。
- Content-Length: 44:指定了响应正文的长度,单位为字节。
- Content-Type: text/html; charset=utf-8:表示响应正文的类型是text/html,字符集为utf-8。
- 在响应头之后的是一行空行,这行空行的含义是为了区分响应头和后面的响应主体
- 响应空行之后就是响应的主体,即实际的数据内容,可以是HTML文件、文本、图片等具体的资源内容。
我们将“蓝色 Hello World”处理成一个 HTTP 响应报文:
HTTP/1.1 200 OK
Content-Length: 408
Content-Type: text/html; charset=utf-8
Hello World
Hello, World!
响应蓝色的 Hello World
现在我们结合前面的文章中的代码,将响应信息直接返回给请求该服务器的浏览器。
public static void main(String[] args) throws IOException {
ServerSocket serverSocket = new ServerSocket(8080);
Socket accept = serverSocket.accept();
InputStream inputStream = accept.getInputStream();
byte[] bytes = new byte[1024];
int i;
//输出请求信息
while((i=inputStream.read(bytes,0,bytes.length))!=-1){
System.out.println(new String(bytes,0,i,StandardCharsets.UTF_8));
if (i<1024){
break;
}
}
//响应内容
String responseContext = "HTTP/1.1 200 OK\n" +
"Content-Length: 408\n" +
"Content-Type: text/html; charset=utf-8\n" +
"\n" +
"\n" +
"\n" +
"\n" +
" \n" +
" \n" +
" Hello World \n" +
" \n" +
"\n" +
"\n" +
" Hello, World!
\n" +
"\n" +
"";
OutputStream outputStream = accept.getOutputStream();
outputStream.write(responseContext.getBytes(StandardCharsets.UTF_8));
//清空缓存区,刷新到目的空间
outputStream.flush();
outputStream.close();
inputStream.close();
}
使用浏览器访问 http://localhost:8080/ 就能得到如下的效果

到这里,我们已经能够返回一个 HTML 格式的响应报文,并且浏览器也成功获取到报文,在页面显示了我们想要的效果。但是这就够了吗?不!我们还要根据请求路径去展示不同的页面,并且页面中还包含额外的资源,比如图片、js、css等等。
处理请求
在我们使用浏览器访问一个网站的时候,网页中往往包含各种按钮或者是链接,当我们点击的时候,就会进入到各种各样的页面。如果这个时候我们去观察浏览器的网址栏,就会发现,我们点击按钮或者链接进入的各种网页本质上是在切换不同的 URL,去请求对应的网页资源。这里我们模仿这个操作,去处理 HTTP 请求,以实现静态资源的切换。
HTTP请求格式
HTTP 请求和响应格式类似,但是又有一些不同。以下是一个请求报文的示例:
POST /submit-form HTTP/1.1
Host: www.example.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 25
username=example&password=123
下面我们对报文进行简单的解析:
-
报文的第一行是请求行,其中有三个部分,用空格区分:
- POST 是第一部分,代表请求方法,我们常用的请求方法是 GET 和 POST
- /submit-form 是第二部分,代表请求的 URL,用于区分请求的资源
- HTTP/1.1 是第三部分,代表请求的协议版本
-
请求行后面的就是类似于响应头的请求头,同样是 k-v 结构,描述请求相关的内容
-
请求头之后是请求空行,用于区分请求头部和请求主体
-
请求空行之后是请求主体,携带请求主体信息。GET 请求通常不包含请求体,而 POST 请求则可能包含请求体,用来传递需要提交到服务器的数据。
获取请求 URL
根据对请求报文的分析,我们知道,请求报文的第一行的第二部分是请求 URL。因此我们只需要处理请求报文的第一行,并且获取第二部分的请求信息,然后根据请求信息去获取到对应的静态资源。所以我们需要对程序进行一定的修改。
inputStream = accept.getInputStream(); BufferedReader bfr = new BufferedReader(new InputStreamReader(inputStream)); String firstLine = bfr.readLine(); if (firstLine==null||"".equals(firstLine)){ return; } String httpPath = firstLine.split(" ")[1];解释一下上面的代码:
-
首先我们先通过 accept 对象获取到 InputStream 对象
-
然后将获取到的 InputStream 包装成一个 BufferedReader 对象目的是为了方便按行读取数据
-
接着我们读取请求报文的第一行
-
判断请求报文是否有内容,没有内容的话就直接结束
-
然后按照空格去分隔请求行,拿到请求 URL(ps:这里写的有点粗糙,可能为空,也可能分割有问题,由于不是重点,我们就简单处理一下)
到这里,我们就拿到了请求 URL。
设置静态资源路径
通过上面的步骤,我们顺利地拿到了请求 URL,但是我们怎么根据 URL 去拿到对应的资源呢?一种非常暴力的思路就是 if-else,通过预先设定好的几种 URL 去响应指定的字符串对象。优点是实现简单,但是缺点也很明显,代码可读性和可扩展性都极差。
使用 tomcat 部署过项目的同学应该知道,只要把静态文件放到指定的目录下,然后我们通过与文件对应的 URL 就可以访问到指定的文件。因此我在想是不是也可以预先指定一个目录,然后根据请求的 URL 去访问指定目录下的文件。
- 首先我们先定义一个常量,用于表示静态文件所在的目录:
private static final String STATIC_RESOURCE_PATH = "src/main/resources/static/";
- 然后将获取到的 URL 拼接在后面,并且创建对应的 File 对象
//读取文件
String path = STATIC_RESOURCE_PATH+httpPath;
//创建文件对象
File file = new File(path);
- 在使用它之前,我们需要先判断文件是否存在,如果不存在怎么办呢?当然是返回404咯,所以我们再增加一个成员变量代表404报文所在的路径,并且将 404.txt 保存至指定的目录下。
private static final String PAGE_NOT_FOUND_404_PATH = "404.txt";
404.txt 文件内容如下:
HTTP/1.1 404 Not Found
Content-Type: text/html; charset=utf-8
404 Not Found
Sorry, the page you are looking for could not be found.
```- 判断文件是否存在,如果不存在返回 404,如果存在则返回对应的文件内容
//判断文件是否存在,不存在直接返回 404
if (!file.exists()){
fileInputStream = new FileInputStream(STATIC_RESOURCE_PATH+PAGE_NOT_FOUND_404_PATH);
int b = 0;
byte[] bytes = new byte[1024];
while((b=fileInputStream.read(bytes))!=-1){
outputStream.write(bytes,0,b);
}
}else{
fileInputStream = new FileInputStream(file);
//写文件
//响应行
outputStream.write("HTTP/1.1 200 OK\r\n".getBytes(StandardCharsets.UTF_8));
//响应头
outputStream.write(("Content-Length:"+file.length()+"\r\n").getBytes(StandardCharsets.UTF_8));
//响应空行
outputStream.write("\r\n".getBytes(StandardCharsets.UTF_8));
//响应内容
int b = 0;
byte[] bytes = new byte[1024];
while((b=fileInputStream.read(bytes))!=-1){
outputStream.write(bytes,0,b);
}
}
outputStream.flush();
- 最后释放资源
//释放资源
if (outputStream!=null){
outputStream.close();
}
if (bfr!=null){
bfr.close();
}
if (fileInputStream!=null){
fileInputStream.close();
}
if (inputStream!=null){
inputStream.close();
}
最终代码
public class HttpServer {
private static final String STATIC_RESOURCE_PATH = "src/main/resources/static/";
private static final String PAGE_NOT_FOUND_404_PATH = "404.txt";
public static void main(String[] args) throws IOException {
ServerSocket server = new ServerSocket(8080);
while(true){
InputStream inputStream = null;
FileInputStream fileInputStream = null;
OutputStream outputStream = null;
BufferedReader bfr = null;
try{
//获取输入流
Socket accept = server.accept();
//获取输出流
outputStream = accept.getOutputStream();
inputStream = accept.getInputStream();
//对流进行包装
bfr = new BufferedReader(new InputStreamReader(inputStream));
String firstLine = bfr.readLine();
if (firstLine==null||"".equals(firstLine)){
return;
}
String httpPath = firstLine.split(" ")[1];
//读取文件
String path = STATIC_RESOURCE_PATH+httpPath;
//创建文件对象
File file = new File(path);
//判断文件是否存在,不存在直接返回 404
if (!file.exists()){
fileInputStream = new FileInputStream(STATIC_RESOURCE_PATH+PAGE_NOT_FOUND_404_PATH);
int b = 0;
byte[] bytes = new byte[1024];
while((b=fileInputStream.read(bytes))!=-1){
outputStream.write(bytes,0,b);
}
}else{
fileInputStream = new FileInputStream(file);
//写文件
//响应行
outputStream.write("HTTP/1.1 200 OK\r\n".getBytes(StandardCharsets.UTF_8));
//响应头
outputStream.write(("Content-Length:"+file.length()+"\r\n").getBytes(StandardCharsets.UTF_8));
//响应空行
outputStream.write("\r\n".getBytes(StandardCharsets.UTF_8));
//响应内容
int b = 0;
byte[] bytes = new byte[1024];
while((b=fileInputStream.read(bytes))!=-1){
outputStream.write(bytes,0,b);
}
}
outputStream.flush();
}catch (Exception e){
e.printStackTrace();
}finally{
//释放资源
if (outputStream!=null){
outputStream.close();
}
if (bfr!=null){
bfr.close();
}
if (fileInputStream!=null){
fileInputStream.close();
}
if (inputStream!=null){
inputStream.close();
}
}
}
}
}
测试效果
- 我们先在静态资源目录下存放多个 HTML 文件,然后使用浏览器分别去访问,以下是我的文件目录,是常规的 maven 目录结构。

- 接着我们启动项目
- 最后使用浏览器切换不同地 URL 访问,效果如下:
http://localhost:8080/hello.html

http://localhost:8080/hello2.html

http://localhost:8080/hello3.html

http://localhost:8080/hello4.html
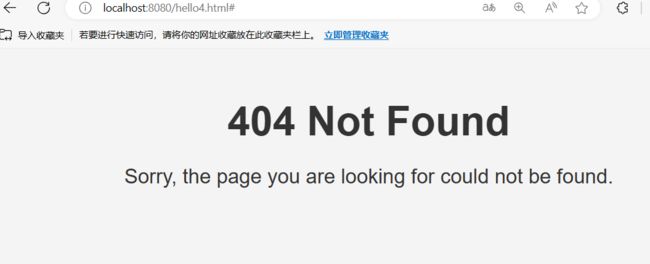
多媒体资源
在 HTML 中可能会链接外部的 js 文件、css 文件、图片等等。做的过程中我就在思考,这一部分该怎么去实现。那时候我在坐地铁,正好没啥事,所以针对这个问题我就开始在脑子里面去模拟了,首先我想到的是服务端的解决方案。
服务端设计
想要知道一个 HTML 是否包含其他的资源,我们就需要去解析 HTML 文件,然后针对其中的某些标签,比如
首先我们必须要遵循 HTTP 响应报文的格式,并且响应主体中是 HTML ,然后还要携带 HTML 中包含的其他资源文件,在我对于 HTTP 协议的认知里面,好像没有办法在一次传输 HTML 本体的同时还要携带它所包含的多媒体资源。所以我就想,是不是应该分多次请求?
客户端设计
想到多次,我突然意识到,HTTP 通信是按照一个请求对应一个响应进行的,如果分多次传输,那么客户端一定要发起多次请求。发送既然是客户端去做的,那么客户端就一定明确的知道它需要请求哪些资源,因此我猜想:
- 客户但会在解析 HTML 文件的时候会对 HTML 文件中包含的其他文件进行处理
- 根据标签中的 src 属性去找到源文件相对于主体文件在服务器位置
- 对每一个文件发起一次请求
如果是这样的话,实现起来肯定会比在服务器端去处理资源要更为简单,而且客户端本来也需要解析 HTML 文件去渲染效果,让客户端去请求多个资源也更合理。同样,服务器端的职责也更加清晰——返回符合请求的响应即可,不需要做额外的事情。
接下来我们就来验证一下是不是如我们猜想的一样,是客户端去解析和请求多个资源。
验证
首先我们需要一个包含众多资源的 HTML 文件,包括 js、css、图片。HTML内容如下
DOCTYPE html>
<html>
<head>
<title>望岳title>
<link rel="stylesheet" type="text/css" href="styles.css">
<script src="script.js" defer>script>
head>
<body>
<div id="background">
<h1 id="poem">望岳h1>
<p id="poem">作者:杜甫p>
<p id="poem">朝代:唐p>
<p id="poem">全文如下:p>
<p id="poem">岱宗夫如何?齐鲁青末了。造化钟神秀,阴阳割昏晓。荡胸生曾云,决眦入归鸟。会当凌绝顶,一览众山小。p>
div>
body>
html>
其中包含了 css 和 js ,然后在又在包含的 css 文件中引用了一张背景图片,项目目录如下:
我们通过浏览器去访问 http://localhost:8080/wangyue.html,看看效果
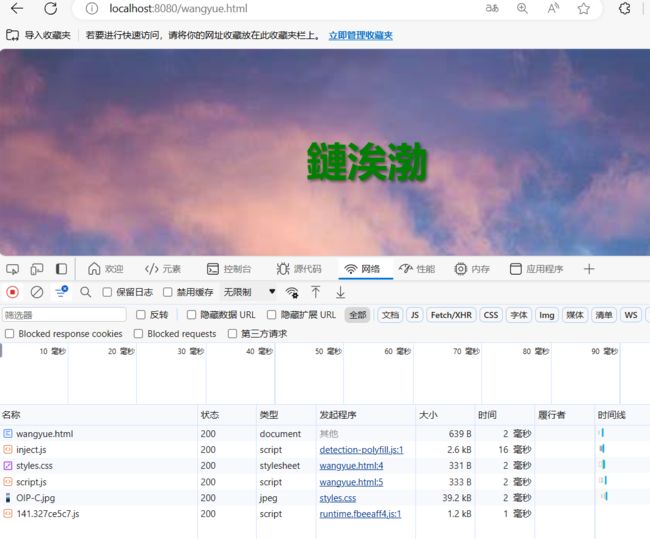
虽然乱码了了,但是我们可以看到确实是浏览器去请求HTML包含的所有多媒体文件,而服务器只负责根据请求的url 返回相应的文件。
总结
到这里我们这篇文章也要跟大家说再见了,这篇文章我们完成了这样几件事情:
- 首先我们通过对 HTTP 响应报文的分析,拼接了一个标准的 HTTP 响应返回给浏览器,在浏览器上面显示了一个蓝色的 ”Hello,World“。
- 然后我们通过解析 HTTP 请求报文,根据 URL 去对应上我们静态资源的文件,然后按照 HTTP 响应报文的格式将相应的文件内容返回给浏览器。
- 最后我们在 HTML 文件中包含了多个外部资源,验证了客户端对于多个资源的获取方式。
最后希望大家多多点赞评论支持,你的支持是我持续更新的最大动力,那,让我们下一期再见吧!