图像处理之《基于端到端哈希生成模型的鲁棒无覆盖图像隐写》论文精读
一、文章摘要
近年来,无覆盖隐写算法因其完全抵抗隐写分析算法的能力而引起了越来越多的研究关注。然而,现有的算法在面对几何攻击和非几何攻击时,无法达到同样的鲁棒性平衡。此外,现有的方法大多需要在隐写图像的同时传输一些辅助信息,这增加了隐写信息的成本。提出了一种基于哈希生成模型的鲁棒无覆盖图像隐写算法。与现有方法不同的是,哈希序列是由端到端的CNN模型生成的,输入是原始图像,输出是相应的哈希序列。因此,隐藏秘密信息时不需要传输辅助信息。此外,还引入了注意力机制和对抗训练来提高模型的鲁棒性。损失函数被重新设计以适应这些操作。最后,通过建立索引结构来提高映射效率。实验结果表明,与现有的无覆盖图像隐写算法相比,该方法具有更好的鲁棒性和安全性。

二、动机
2.1 抵抗几何和非几何攻击的不平衡
如第1节所述,现有的无覆盖图像隐写算法通常需要两个单独的步骤来生成哈希序列,这使得很难对生成的哈希序列添加约束。因此,对几何和非几何攻击的鲁棒性不能保持在较高的水平。为了解释这一现象,我们分别在Zhang的[35]、Liu的[36]和Karim的[39]中计算了在一些几何攻击和非几何攻击下提取的特征变化的分布。特征的变化率定义如下:

其中Vori和Vatt分别表示从原始图像和被攻击图像中提取的特征值,即Zhang[35]中的DCT, Liu[36]中的DWT, Karim[39]中的LL子带的平均值。具体来说,几何攻击包括边缘裁剪、旋转和平移,非几何攻击包括中值滤波器、颜色直方图均衡化和伽马校正。因此,对于每种算法,可以得到6条分布曲线。从图1 (a)、图1 (b)和图1 ©可以看出,这三种算法在不同攻击下的分布曲线是不同的,非几何攻击下的分布接近正态分布,而几何攻击下的分布更为复杂。

图1 Zhang[35]、Liu[36]和Karim[39]的比率分布
造成这种分配不平衡的原因有两个方面。第一个原因来自攻击本身的特点。几何攻击和非几何攻击会从不同方面破坏原始图像的内容。对于几何攻击,即旋转、平移和裁剪,它们通常破坏图像内部的相对关系。例如,在某个坐标上相邻的两个像素之间的关系在旋转后可能会发生明显的变化。然而,对于非几何攻击,即添加噪声、滤波,往往会改变图像的绝对值。一个简单的例子是均值过滤攻击。在一定的滑动窗口下,整个图像的像素将遭受平均操作。因此,图像中相邻像素或块之间的相对关系不会发生太大变化。实际上,生成哈希序列的过程就是通过提取图像的鲁棒特征来表示图像中的一些稳定特征。因此,由于这两种攻击的不同,如果我们不对生成哈希序列的过程添加约束,就很难同时抵御这两种攻击。另一个原因是现有方法中的特征提取和哈希生成方式是人为设计和固定的,面对不同类型的攻击时无法调整。但是这两种攻击引起的图像特征变化有很大的不同,所以现有的方法往往不能同时抵抗几何攻击和非几何攻击。例如,Zhang[35]的方法首先将图像分成块,然后对每个块进行离散余弦变换(DCT),提取鲁棒特征。通过比较相邻区块的DC系数生成哈希序列。该方法对非几何攻击具有较强的鲁棒性。然而,几何攻击会破坏相邻块之间的关系,因此其鲁棒性较差。因此,现有方法的缺陷促使我们寻找新的哈希序列生成方法。我们注意到,深度学习网络可以自动学习高维特征,当目标不同时,它可以通过设置适当的损失函数来达到两者之间的平衡,因为它具有不断更新和学习的特性,正好满足我们的需要。因此,这就是我们使用端到端散列生成网络来完成无覆盖隐写的原因,详细设计将在下一节中展示。
2.2 辅助信息的长度
许多现有的无覆盖图像隐写算法都是基于块的,例如[33]-[36]。在他们的方法中,首先需要将图像分成块,每个块对应一个哈希序列。因此,位置信息,即坐标(rx,ry),图像中块的一部分需要传输到接收方。假设图像的分辨率为P × Q,将其划分为P × Q块。则rx和ry的极差值分别为1 ~ p和1 ~ q。因此,每张图像需要[log2(pq)]位辅助信息。即辅助信息的长度为:
考虑到与“修改”方法相比,无覆盖图像隐写算法的容量并不大,例如Zhang的[35],Liu的[36]和Liu的[38]中的15位/图像。如果p和q的值较大,即Zhang[35]和Liu[36]中p = q = 16的最大值,则辅助信息La的长度将达到8位,传输成本较高。

综上所述,一方面,现有算法在抵抗几何攻击和非几何攻击方面表现不平衡。另一方面,辅助信息的传递增加了安全风险和成本。因此,我们引入端到端CNN模型来完成生成哈希序列的过程。因为它的输入是整个图像,输出是对应的哈希序列,所以不需要再传输辅助信息。与现有方法的分离不同,它将特征提取和哈希序列生成过程合并到一个网络中,因此更容易在模型中添加约束,可以平衡几何攻击和非几何攻击的鲁棒性。
三、文章提出的方法
3.1 提出的方法框架
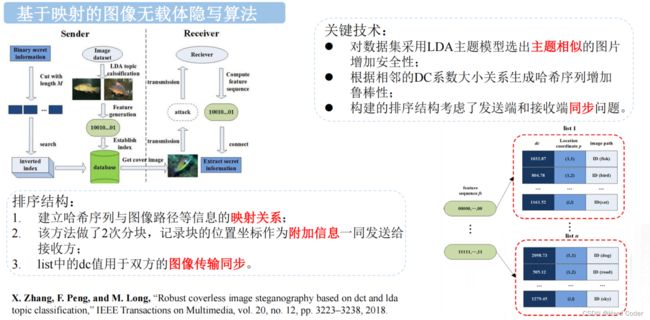
本文提出的无覆盖图像隐写框架如图2所示,主要由哈希序列的生成、图像索引数据库的建立、秘密信息的隐藏与提取四个部分组成。
对于发送方,首先训练提出的哈希生成模型。然后,建立图像索引数据库的结构。在信息隐藏过程中,将秘密信息分成长度为1的num个段,通过搜索已建立的图像索引数据库,找到与秘密信息段哈希序列相同的对应图像。最后,将所有选定的隐写图像发送到接收方。

图2 提出方法的框架
在接收端,对于每个接收到的隐写图像,由所提出的模型生成一个二进制哈希序列。然后,将被分割的序列连接起来,恢复原始的秘密信息。
3.2 生成哈希序列
1)网络架构:在生成哈希序列的过程中,使用端到端的CNN。所提出模型的流程图如图3所示。当我们将图像输入模型时,可以生成相应的哈希序列。模型的结构主要由四个模块组成,即主干模块、注意力模块、扁平化模块和哈希生成模块。其中,前三个模块,即主干模块、注意力模块和扁平化模块的功能是提取图像的鲁棒特征,因此将在“2)特征提取模块”部分一起进行说明。最后一个模块将连续特征映射到离散哈希序列,在“3)哈希生成模块”部分进行了描述。

图3 网络架构
2)特征提取模块:在主干模块中,采用DenseNet-161[40]的特征提取结构,由7×7卷积层、3×3最大池化层和4个密集块组成。该模块具体参数如表1所示。与直接连接的VGG网络相比,DenseNet的密集连接可以帮助网络更好地学习图像的表示。扁平化模块由一个扁平化层和两个完全连接的层组成。扁平化层可以在不影响批量大小的情况下将CNN特征扁平化化为一维特征。通过两个完全连接层后,可以得到形状等于哈希序列长度l的特征。流程可以构造为

其中,FCl和FC1000分别代表有1个和1000个神经元的全连接层。

注意力机制的目的是确保网络更多地关注数据的重要部分。在我们的模型中,注意力模块被用来提高网络的鲁棒性。特别地,采用了[41]的结构。可进一步分为空间注意力模块(spatial)和通道注意力模块(channel)。总体结构可以描述

其中⊗表示逐元素的乘法。F表示空间注意力模块的输出和通道注意力模块的输入。空间注意力集中于学习像素的权重,即不考虑不同通道的权重分布。具体来说,它首先利用了两个池化操作,即平均池化和最大池化。然后用卷积层对得到的特征进行串联和卷积。这个过程可以描述如下

其中σ和conv分别表示sigmoid函数和卷积层。
对于通道注意力,利用特征的通道间关系生成通道注意力映射。特征映射首先被输入到平均池化层和最大池化层中,以生成空间上下文描述符。然后,两个描述符被转发到一个共享网络,以产生通道注意力映射。共享网络由一个卷积层、一个ReLU函数和另一个卷积层组成。最后,通过元素求和运算对输出的特征向量进行合并。这个过程可以表示如下

式中σ为sigmoid函数,fN为共享网络。本模块的进一步结果将在第四节中讨论。
3)哈希生成模块:由于特征提取模块的输出是连续的,我们需要将其离散化以获得哈希序列。一个简单的想法是利用sign(.)函数。然而,有两个问题。首先,它没有连续导数,不能通过梯度下降直接优化。另一个问题是,它无法控制输出的分布。如果我们把从连续变量到二进制变量的转换看作是有损通信信道,则该信道的容量最大,因为输出0和1是对半分布。因此,可以使用双半层[42]来控制输出的分布。主要思想是首先对输出特征进行排序。然后,它将特征的上半部分映射为1,其余特征映射为0。因此,可以得到输入图像所对应的哈希序列。
4)损失函数的约束:损失函数的约束由三部分组成。第一部分与双半层一致[42],记为lossbi-half。假设在数据集X = {xi}中随机抽样M个样本的小批,i = 1;2,…,M分为X1 = {xm}, M = 1,2,…,M/2, X2 = {xn}, n = M/2 + 1,…,M。模型的输出,即对应的哈希序列B = f(X) = {bi}, i = 1,2,…,M也分为B1 = {bm}, M = 1,2,…,M /2, B2 = {bn},n = M/2 + 1,…,M。同样地,将双半层前的特征映射表示为H = {hi}为H1 = {bm},m = 1,2,…,M/2, H2 = {bn},n = M/2 + 1,…,M。则双半层的损失函数可计算为

其中||.||2表示欧氏范数,cos(.)表示余弦相似度。
约束的第二部分旨在最小化攻击图像生成的哈希序列与原始图像之间的距离,以增强鲁棒性。在我们的模型中,同时选择几何攻击和非几何攻击来生成被攻击的图像。考虑到旋转后的图像和滤波后的图像在视觉上与原始图像相似,实验中选择了几何攻击时的旋转和非几何攻击时的高斯滤波。这部分的总约束可以描述为
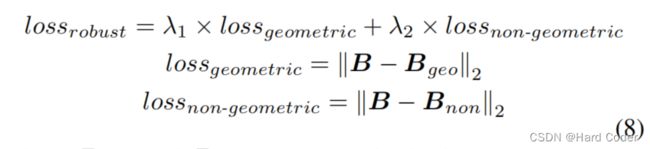
其中Bgeo和Bnon分别表示几何攻击图像和非几何攻击图像生成的哈希序列。λ1和λ2表示超参数。
约束的最后一部分引入了对抗训练,以进一步提高网络的性能。具体来说,使用了虚拟对抗训练(VAT)[43]方法。主要思想是找到一个微小的扰动,它可以最大限度地增加损失。具体过程如下
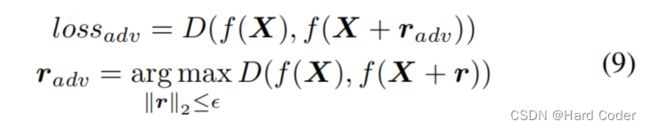
其中,D(a,b)表示测量距离的非负函数。考虑到我们的目的是生成哈希序列而不是分类,我们使用欧几里得范数来评估相似性而不是K-L散度,即D(a,b) = ||a−b||2。比较结果将载于第四节(C.1)。
根据以上分析,整个损失函数可以表示为

其中λ3是一个超参数。
3.3 建立图像索引数据库
在无覆盖隐写方案中,通常需要将秘密信息分成若干段。事实上,为所有的秘密片段寻找载体会浪费大量的时间,尤其是当图像数据库非常庞大的时候。为了提高图像搜索的效率,我们建立了图像索引数据库,如图4所示。该结构包含三部分:哈希序列、平均像素值和图像路径。第一部分是哈希序列,它是整个图像索引数据库的入口。它按二进制升序排序,从’ 000,…,000’到’111,……111’。由于接收到的图像顺序可能发生变化,中间部分pix存储了图像的平均像素值,用于记录图像顺序,计算方法如下:

其中Pnum表示图像的像素号,pixi表示第i个像素的像素值。最后一部分是图像路径,显示了图像的路径。在信息隐藏的过程中,所选图像的像素值要大于原图像的像素值。特别是,第一个选定图像的像素应该是整个列表的最小值。然后,在接收端,如果由于网络路由而改变了隐写图像的顺序,则可以通过该参数恢复正确的顺序。假设当前秘密段为’00000000’,其像素为87.9,图像路径对应为’/VOC2012/cat.jpg’。如果下一个秘密段为’11111111’,则选中的图像可以为’/VOC2012/rose.jpg’,因为其pix = 269.0大于87.9,但不能为’/VOC2012/dog .jpg’,因为pix = 58.6。
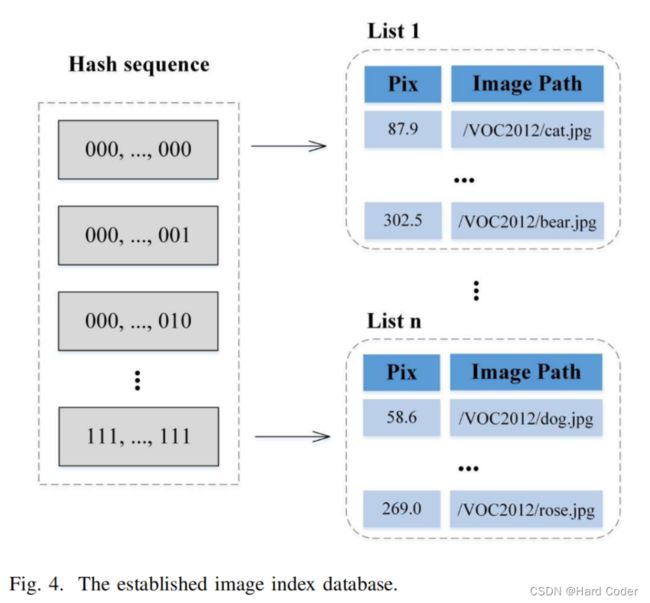
图4 建立图像索引数据
3.4 秘密信息隐藏与提取
在建立了图像索引数据库之后,下一步是通过将秘密信息映射到图像索引来隐藏秘密信息。具体过程可以总结如下。
步骤1。假设秘密信息S的长度为L,并将其分成num个段

如果L不能被L整除,则在最后一段补零,形成一个完整序列,并记录补零个数。
步骤2。对于机密信息段Si,i = 1,2,…,num,选取哈希序列等于Si的隐写图像SIi,如下所示

其中HSj表示所选图像的哈希序列。Ij表示图像数据库中的第j张图像,Num表示图像的个数。
步骤3。重复步骤2,直到获得所有的隐写图像。填充零的数量(如果存在)被转换为二进制并映射到最后一个隐写图像。

步骤4。所有选定的隐写图像被发送到接收方。
信息隐藏过程的伪代码如算法1所示。

对于接收方,可以通过以下步骤提取秘密信息。
步骤1。接收到的隐写图像的顺序首先由参数pix检查并重新组织(如果需要的话),以防图像的顺序由于网络路由而改变。
步骤2。对于接收到的前num个隐写图像, Stego = {SI1,SI2,…,SInum},则可以通过提出的CNN模型生成相应的哈希序列。
步骤3。重复上述步骤,直到提取出所有哈希序列。按顺序连接所有哈希序列。
步骤4。提取最后一个图像SIpadding的哈希序列,它对应于填充零的数量。
第5步。从最后一个序列(如果存在)中减去填充零,即可获得恢复的秘密信息S。
算法2描述了秘密信息的提取过程。

四、实现细节
在实验中,采用了四个广泛使用的数据集,分别是PASCAL VOC2012、MS COCO2014、INRIA Holidays和Caltech-256。前两个数据集与Luo的[37]一致,其余两个数据集采用Liu的[38]方法。这些数据集的具体描述如下。
(1)PASCAL VOC2012数据集[44]。PASCAL VOC是一个世界级的计算机视觉挑战,它为对象类识别提供了标准化的图像数据集。PASCAL VOC2012数据集可分为20个子类,包含11540张图像。
(2)MS COCO2014数据集[45]。MS COCO数据集是一个大规模的目标检测、分割和字幕数据集。2014年版本有82783张训练图像,分为80个类别。
(3)INRIA节假日数据集[46]。假期数据集是一组图像,主要包含我们的一些个人假期照片。该数据集共包含1491幅图像,图像的分辨率很高。
(4)Caltech-256数据集[47]。Caltech-256数据集是通过选择一组对象类别,从Google Images下载示例,然后手动筛选出所有不适合该类别的图像来收集的。它包含30608张图片和257个类别。
在实验中,使用PASCAL VOC2012和MS COCO2014训练集对CNN模型进行训练。在测试阶段,我们随机选择了来自PASCAL VOC 2012的500张图像,MS COCO 2014的500张图像,Caltech-256的500张图像和INRIA Holidays的500张图像进行实验。对比实验中的参数设置如下:将哈希序列l的长度设为8,与Zhang[35]、Liu[36]、Liu[38]、Karim[39]一致。所有的图像都被调整为256×256的实验。超参数λ1、λ2、λ3分别设置为0.3、0.7、1.2。
为了验证本文方法的有效性,我们将本文方法与Zhang[35]、Liu[36]、Luo[37]、Liu[38]、Karim[39]等现有方法进行了比较。对于Zhang的[35]、Liu的[36]、Luo的[37]和Karim的[39]方法,我们复制了他们的实验。对于Liu的[38],没有解释所选择的随机种子。因此,我们采用Liu[38]的原始数据。
五、汇报PPT(作者本人)





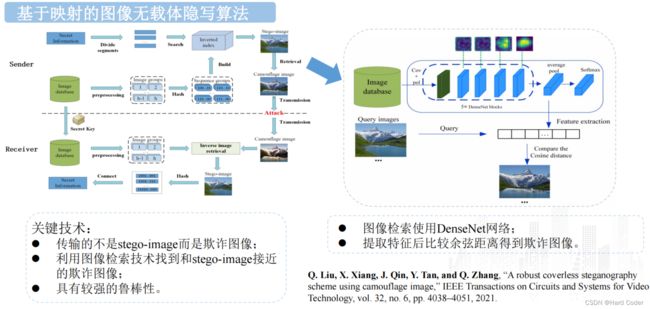













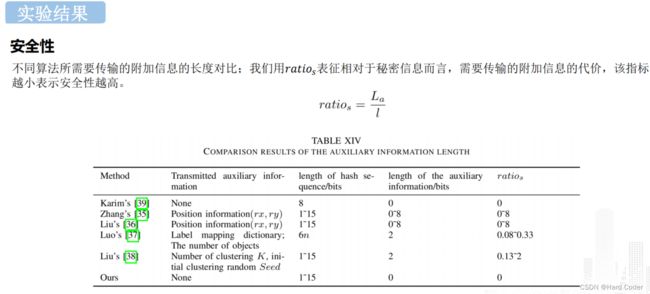

论文地址:A Robust Coverless Image Steganography Based on an End-to-End Hash Generation Model
没有公布源码