深度解析源码,Spring 如何使用三级缓存解决循环依赖
目录
一. 前言
二. 基础知识
2.1. 什么是循环依赖?
2.2. 三级缓存
2.3. 原理执行流程
三. 源码解读
3.1. 代码入口
3.2. 第一层
3.3. 第二层
3.4. 第三层
3.5. 返回第二层
3.6. 返回第一层
四. 原理深度解读
4.1. 什么要有三级缓存?
4.2. 为什么三级缓存不直接存半成品的 A,而是要存一个代理工厂呢 ?
4.3. 能干掉第二级缓存么?
4.4. Spring 为什么不能解决构造器的循环依赖?
4.5. Spring 为什么不能解决 prototype 作用域循环依赖?
4.6. Spring 为什么不能解决多例的循环依赖?
五. 总结
一. 前言
首先我们需要说明,Spring 只是解决了单例模式下属性依赖的循环问题。Spring 为了解决单例的循环依赖问题,使用了三级缓存。在创建 Bean 过程中贯穿着循环依赖问题,Spring 使用三级缓存解决循环依赖,这也是一个重要的知识点,所以我们下面就来看看 Spring 是如何使用三级缓存解决循环依赖的。
二. 基础知识
2.1. 什么是循环依赖?
一个或多个对象之间存在直接或间接的依赖关系,这种依赖关系构成一个环形调用,有下面 3 种方式:

我们看一个简单的 Demo,对标“情况 2”:
@Service
public class Louzai1 {
@Autowired
private Louzai2 louzai2;
public void test1() {
}
}
@Service
public class Louzai2 {
@Autowired
private Louzai1 louzai1;
public void test2() {
}
}这是一个经典的循环依赖,它能正常运行,后面我们会通过源码的角度,解读整体的执行流程。
2.2. 三级缓存
/** Cache of singleton objects: bean name --> bean instance */
private final Map singletonObjects = new ConcurrentHashMap(256);
/** Cache of early singleton objects: bean name --> bean instance */
private final Map earlySingletonObjects = new HashMap(16);
/** Cache of singleton factories: bean name --> ObjectFactory */
private final Map> singletonFactories = new HashMap>(16); - 第一层缓存(singletonObjects):单例对象缓存池,已经实例化并且属性赋值,这里的对象是成熟对象;
- 第二层缓存(earlySingletonObjects):单例对象缓存池,已经实例化但尚未属性赋值,这里的对象是半成品对象;
- 第三层缓存(singletonFactories):单例工厂的缓存,以便后面有机会创建代理对象。
这是最核心,我们直接上源码:
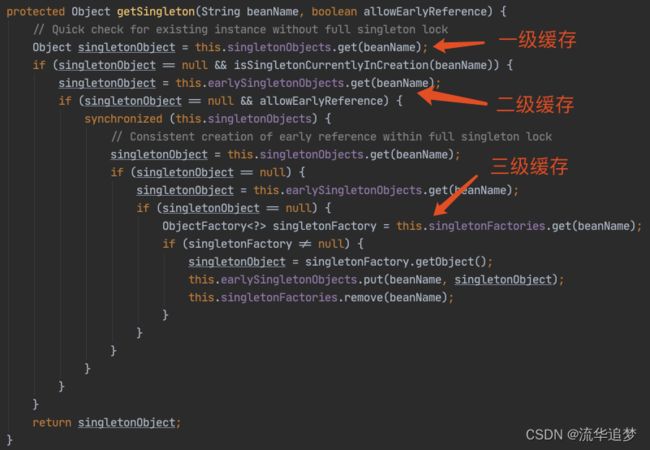
执行逻辑:
- 先从“第一级缓存”找对象,有就返回,没有就找“二级缓存”;
- 找“二级缓存”,有就返回,没有就找“三级缓存”;
- 找“三级缓存”,找到了,就获取对象,放到“二级缓存”,从“三级缓存”移除。
2.3. 原理执行流程
把“情况 2”执行的流程分解为下面 3 步,是不是和“套娃”很像 ?
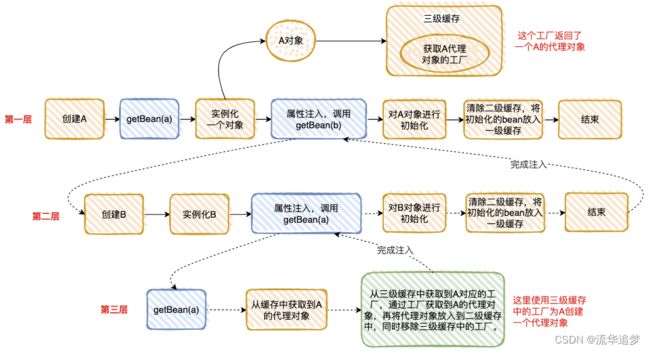
整个执行逻辑如下:
- 在第一层中,先去获取 A 的 Bean,发现没有就准备去创建一个,然后将 A 的代理工厂放入“三级缓存”(这个 A 其实是一个半成品,还没有对里面的属性进行注入),但是 A 依赖 B 的创建,就必须先去创建 B;
- 在第二层中,准备创建 B,发现 B 又依赖 A,需要先去创建 A;
- 在第三层中,去创建 A,因为第一层已经创建了 A 的代理工厂,直接从“三级缓存”中拿到 A 的代理工厂,获取 A 的代理对象,放入“二级缓存”,并清除“三级缓存”;
- 回到第二层,现在有了 A 的代理对象,对 A 的依赖完美解决(这里的 A 仍然是个半成品),B 初始化成功;
- 回到第一层,现在 B 初始化成功,完成 A 对象的属性注入,然后再填充 A 的其它属性,以及 A 的其它步骤(包括 AOP),完成对 A 完整的初始化功能(这里的 A 才是完整的 Bean)。
- 将 A 放入“一级缓存”。
为什么要用三级缓存?我们先看源码执行流程,后面会给出答案。
三. 源码解读
注意:Spring 的版本是 5.2.15.RELEASE,否则代码可能不一样!
3.1. 代码入口
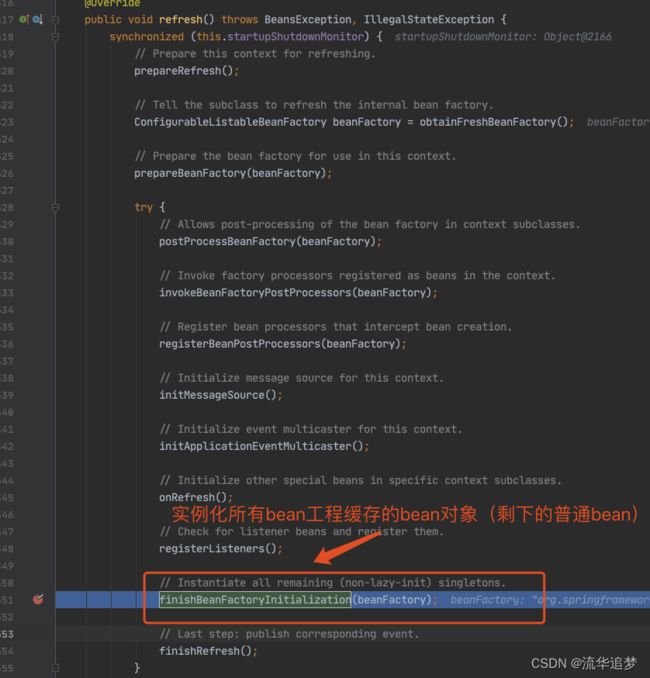
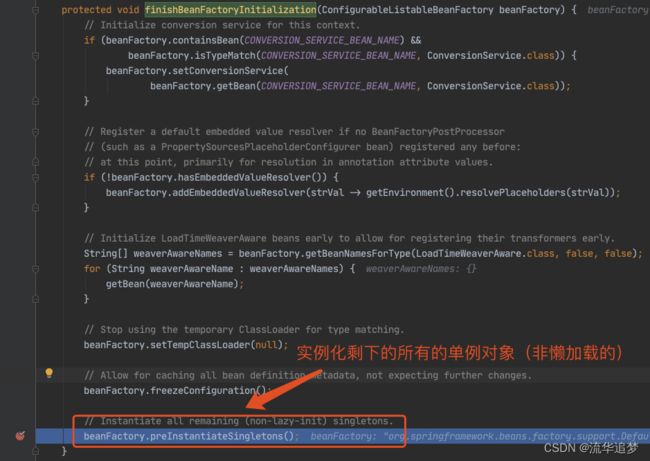
这里需要多跑几次,把前面的 beanName 跳过去,只看 louzai1。

3.2. 第一层

进入 doGetBean(),从 getSingleton() 没有找到对象,进入创建 Bean 的逻辑。
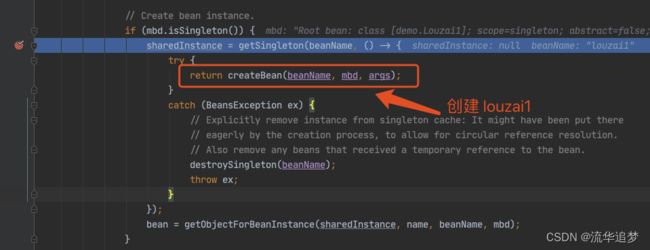

进入 doCreateBean() 后,调用 addSingletonFactory()。
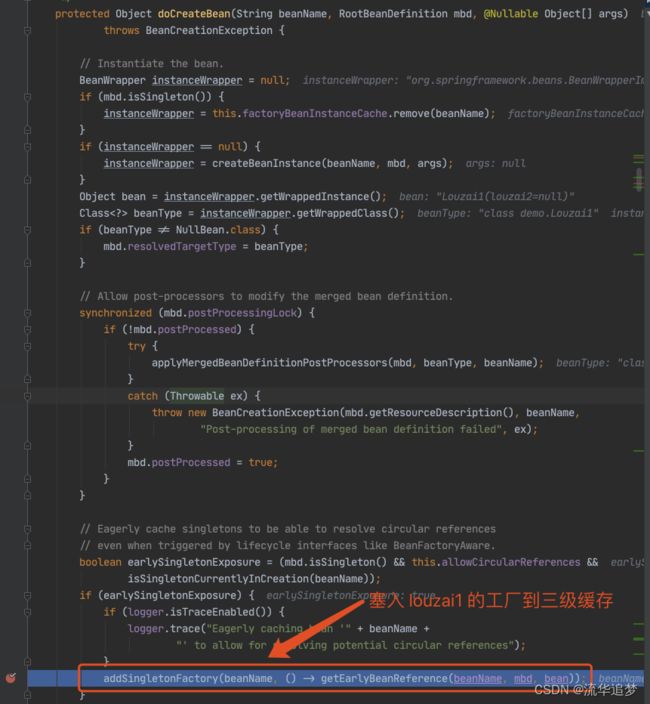
往三级缓存 singletonFactories 塞入 louzai1 的工厂对象。

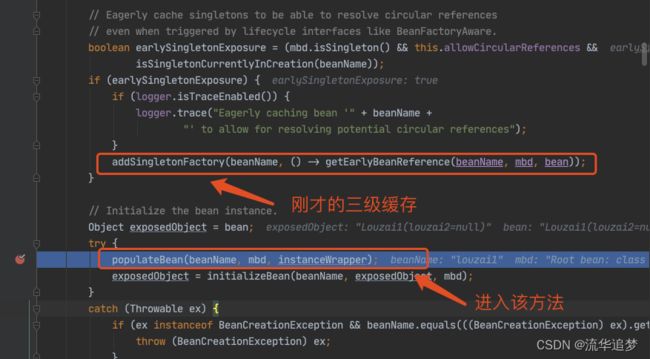
进入到 populateBean(),执行 postProcessProperties(),这里是一个策略模式,找到下图的策略对象。
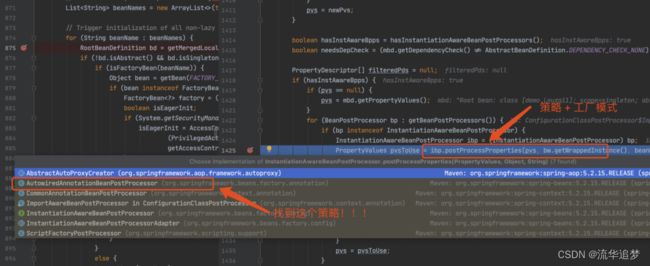
正式进入该策略对应的方法。
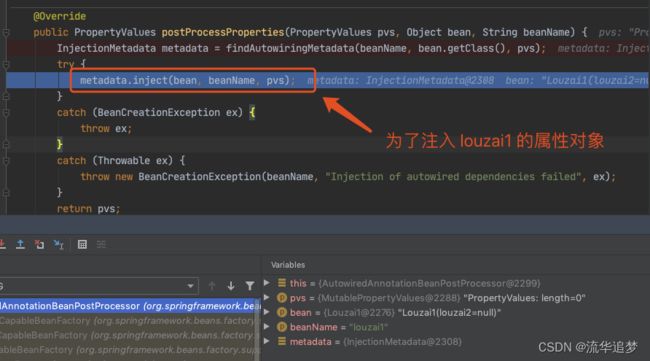
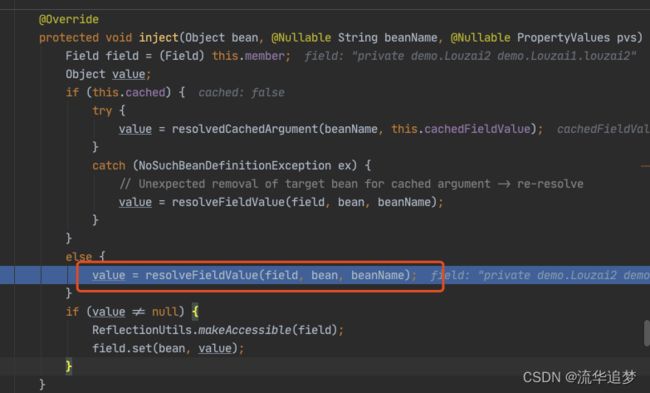
下面都是为了获取 louzai1 的成员对象,然后进行注入。


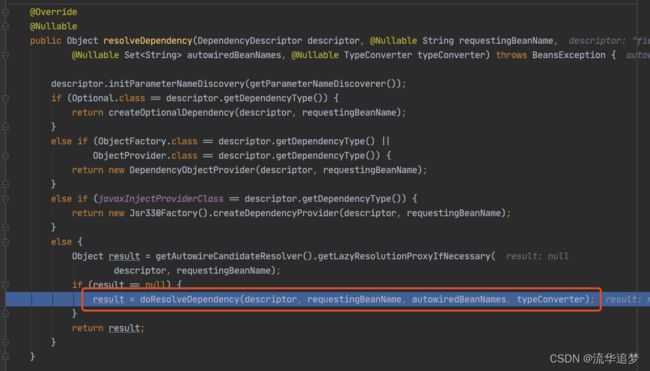
进入 doResolveDependency(),找到 louzai1 依赖的对象名 louzai2。
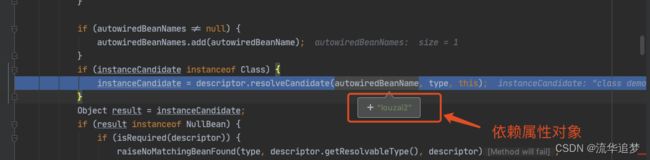
需要获取 louzai2 的 Bean,是 AbstractBeanFactory 的方法。
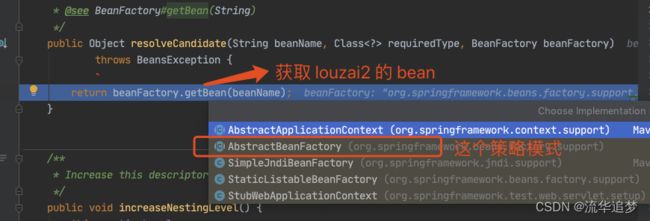
正式获取 louzai2 的 Bean。

到这里,第一层套娃基本结束,因为 louzai1 依赖 louzai2,下面我们进入第二层套娃。
3.3. 第二层

获取 louzai2 的 Bean,从 doGetBean(),到 doResolveDependency(),和第一层的逻辑完全一样,找到 louzai2 依赖的对象名 louzai1。
前面的流程全部省略,直接到 doResolveDependency()。
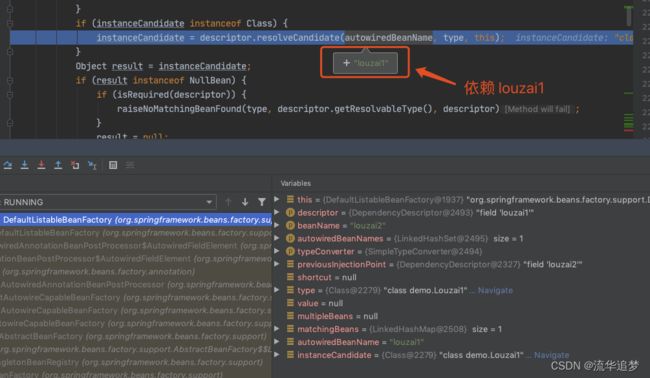
正式获取 louzai1 的 Bean。

到这里,第二层套娃结束,因为 louzai2 依赖 louzai1,所以我们进入第三层套娃。
3.4. 第三层

获取 louzai1 的 Bean,在第一层和第二层中,我们每次都会从 getSingleton() 获取对象,但是由于之前没有初始化 louzai1 和 louzai2 的三级缓存,所以获取对象为空。
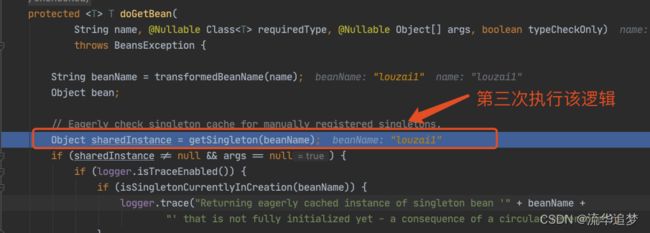

到了第三层,由于第三级缓存有 louzai1 数据,这里使用三级缓存中的工厂,为 louzai1 创建一个代理对象,塞入二级缓存。
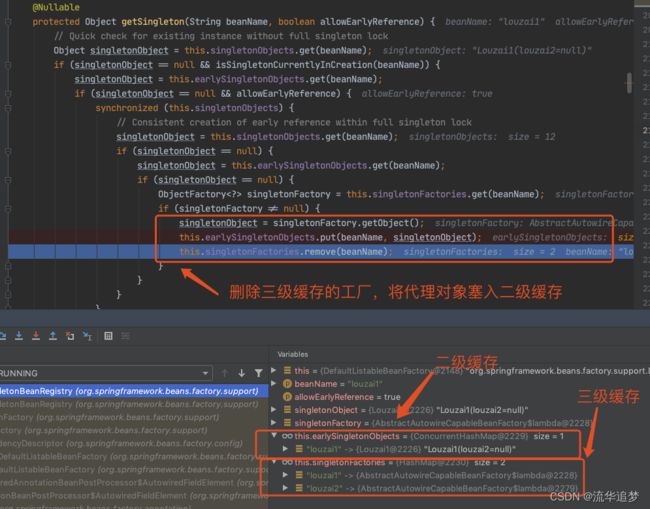
这里就拿到了 louzai1 的代理对象,解决了 louzai2 的依赖关系,返回到第二层。
3.5. 返回第二层
返回第二层后,louzai2 初始化结束,这里就结束了么?二级缓存的数据,啥时候会给到一级呢?
甭着急,看这里,还记得在 doGetBean() 中,我们会通过 createBean() 创建一个 louzai2 的 Bean,当 louzai2 的 Bean 创建成功后,我们会执行 getSingleton(),它会对 louzai2 的结果进行处理。
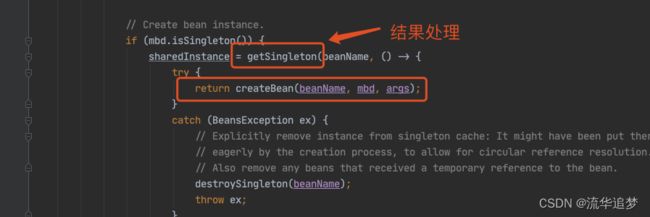
我们进入 getSingleton(),会看到下面这个方法。
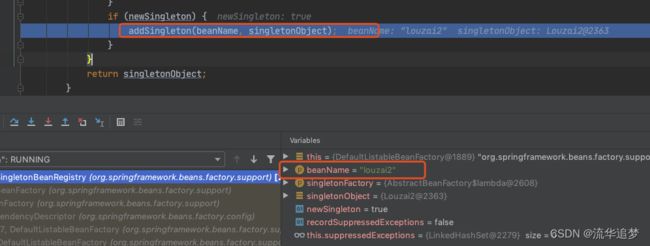
这里就是处理 louzai2 的一、二级缓存的逻辑,将二级缓存清除,放入一级缓存。
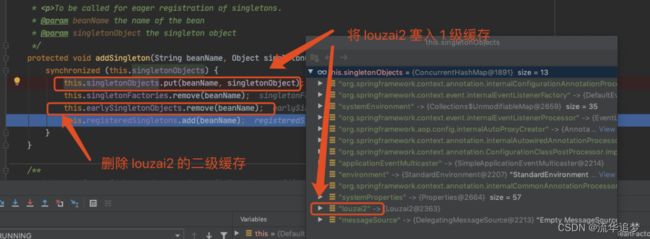
3.6. 返回第一层
同 3.5,louzai1 初始化完毕后,会把 louzai1 的二级缓存清除,将对象放入一级缓存。

到这里,所有的流程结束,我们返回 louzai1 对象。
四. 原理深度解读
4.1. 什么要有三级缓存?
我们先说“一级缓存”的作用,变量命名为 singletonObjects,结构是 Map
“二级缓存”先放放,我们直接看“三级缓存”的作用,变量命名为 singletonFactories,结构是 Map
那这个对象的代理工厂有什么作用呢,我先给出答案,它的主要作用是存放半成品的单例 Bean,目的是为了“打破循环”,可能大家还是不太懂,这里我再稍微解释一下。
我们回到文章开头的例子,创建 A 对象时,会把实例化的 A 对象存入“三级缓存”,这个 A 其实是个半成品,因为没有完成 A 的依赖属性 B 的注入,所以后面当初始化 B 时,B 又要去找 A,这时就需要从“三级缓存”中拿到这个半成品的 A(这里描述,其实也不完全准确,因为不是直接拿,为了让大家好理解,我就先这样描述),打破循环。
4.2. 为什么三级缓存不直接存半成品的 A,而是要存一个代理工厂呢 ?
答案是因为 AOP。在解释这个问题前,我们看一下这个代理工厂的源码,让大家有一个更清晰的认识。
直接找到创建 A 对象时,把实例化的 A 对象存入“三级缓存”的代码,直接用前面的两幅截图:
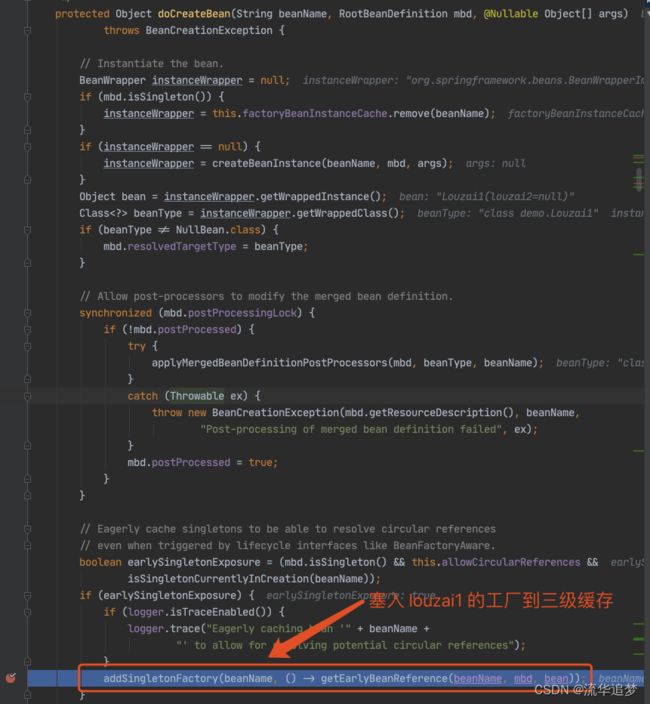
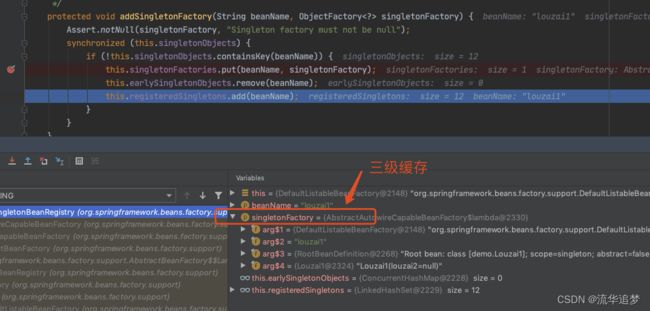
下面我们主要看这个对象工厂是如何得到的,进入 getEarlyBeanReference() 方法。
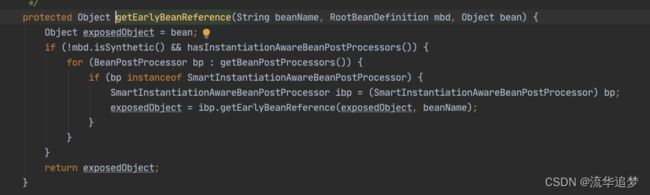
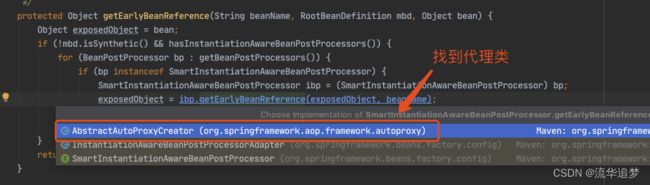

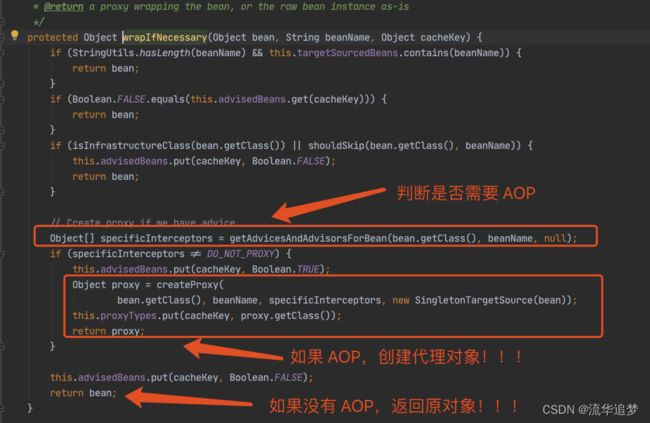
最后一幅图太重要了,我们知道这个对象工厂的作用:
- 如果 A 有 AOP,就创建一个代理对象;
- 如果 A 没有 AOP,就返回原对象。
那二级缓存的作用就清楚了,就是用来存放对象工厂生成的对象,这个对象可能是原对象,也可能是个代理对象。
4.3. 能干掉第二级缓存么?
@Service
public class A {
@Autowired
private B b;
@Autowired
private C c;
public void test1() {
}
}
@Service
public class B {
@Autowired
private A a;
public void test2() {
}
}
@Service
public class C {
@Autowired
private A a;
public void test3() {
}
}根据上面的套娃逻辑,A 需要找 B 和 C,但是 B 需要找 A,C 也需要找 A。
假如 A 需要进行 AOP,因为代理对象每次都是生成不同的对象,如果干掉第二级缓存,只有第一、三级缓存:
- B 找到 A 时,直接通过三级缓存的工厂的代理对象,生成对象 A1。
- C 找到 A 时,直接通过三级缓存的工厂的代理对象,生成对象 A2。
看到问题没?你通过 A 的工厂的代理对象,生成了两个不同的对象 A1 和 A2,所以为了避免这种问题的出现,我们搞个二级缓存,把 A1 存下来,下次再获取时,直接从二级缓存获取,无需再生成新的代理对象。
所以,二级缓存的目的是为了避免因为 AOP 创建多个对象,其中存储的是半成品的 AOP 的单例 Bean。
如果没有 AOP 的话,我们其实只要 一、三级缓存,就可以满足要求。
4.4. Spring 为什么不能解决构造器的循环依赖?
构造器注入形成的循环依赖:也就是 beanB 需要在 beanA 的构造函数中完成初始化,beanA 也需要在 beanB 的构造函数中完成初始化,这种情况的结果就是两个 Bean 都不能完成初始化,循环依赖难以解决。
Spring 解决循环依赖主要是依赖三级缓存,但是的在调用构造方法之前还未将其放入三级缓存之中,因此后续的依赖调用构造方法的时候并不能从三级缓存中获取到依赖的 Bean,因此不能解决。
4.5. Spring 为什么不能解决 prototype 作用域循环依赖?
这种循环依赖同样无法解决,因为 Spring 不会缓存 prototype 作用域的 Bean,而 Spring 中循环依赖的解决正是通过缓存来实现的。
4.6. Spring 为什么不能解决多例的循环依赖?
多实例 Bean 是每次调用一次 getBean 都会执行一次构造方法并且给属性赋值,根本没有三级缓存,因此不能解决循环依赖。
五. 总结
我们再回顾一下三级缓存的作用:
- 一级缓存:为“Spring 的单例属性”而生,就是个单例池,用来存放已经初始化完成的单例 Bean;
- 二级缓存:为“解决 AOP”而生,存放的是半成品的 AOP 的单例 Bean;
- 三级缓存:为“打破循环”而生,存放的是生成半成品单例 Bean 的工厂方法。
生成代理对象产生的循环依赖解决方法,主要有:
- 使用 @Lazy 注解,延迟加载;
- 使用 @DependsOn 注解,指定加载先后关系;
- 修改文件名称,改变循环依赖类的加载顺序。