Oracle中ROW_NUMBER() OVER()函数用法
Oracle中ROW_NUMBER() OVER()函数用法
1. 说明:ROW_NUMBER() OVER() 函数的作用:分组排序
2. 原理:
row_number() over() 函数,over() 里的分组以及排序的执行晚于 where、group by、order by 的执行。
3.语法:
row_number() over( partition by 分组列 order by 排序列 desc )
- 示例一:
查询表:SELECT * FROM SCOTT.EMP ;
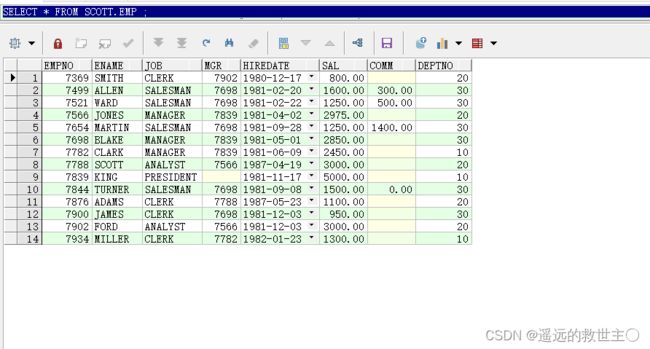
使用Row_number() over() 函数,排序
SELECT EMPNO,ENAME,SAL,DEPTNO,Row_number() over( order by sal) rs FROM
SCOTT.EMP ;
根据工资排序并添加序号

5. 示例二
- 建立测试学生数据表
create table Students
(
id int,
name varchar2(100),
classid int,
score int
);
insert into Students values(1, '学生1', 1, 88);
insert into Students values(2, '学生2', 3, 68);
insert into Students values(3, '学生3', 1, 78);
insert into Students values(4, '学生4', 2, 87);
insert into Students values(5, '学生5', 1, 89);
insert into Students values(6, '学生6', 2, 91);
insert into Students values(7, '学生7', 3, 67);
insert into Students values(8, '学生8', 1, 77);
insert into Students values(9, '学生9', 3, 77);
commit;
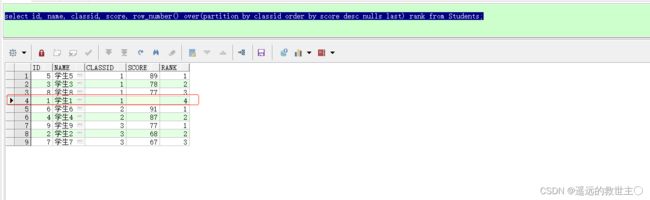
- 查学生数据根据班级分组,再根据分数排名。获取到每个班级的学生分数排名
select id, name, classid, score, row_number() over(partition by classid order by score desc) rank from Students;

3. 获取到每个班级分数排名第一的学生
select * from (select id, name, classid, score, row_number() over(partition by classid order by score desc) rank from Students) where rank = 1;

重点说明:
- parttion by 是 Oracle 中分析性函数的一部分,用于给结果集进行分区,它和聚合函数 group by
不同的地方在于它只是将原始数据进行名次排列,能够返回一个分组中的多条记录(记录数不变),而 group by
是对原始数据进行聚合统计,一般只有一条反映统计值的结果(每组返回一条)。 - over() 必须有 ORDER BY 语句
- 分组内从 1开始排序
- over() 中的排序字段为空,会被排到第一
例如:
将学生1的分数设置为 null,再获取到分组班级的学生分数排名
select id, name, classid, score, row_number() over(partition by classid order by score desc) rank from Students;

修改学生一在该班级的排序,分数最低排最后即可修正这个问题
select id, name, classid, score, row_number() over(partition by classid order by score desc nulls last) rank from Students;
2. 分析函数的例子二:
2.1 分析函数的形式:
分析函数带有一个开窗函数over(),包含三个分析子句:分组(partition by),排序(order by), 窗口(rows),他们的使用形式如下:
over(partition by xxx order by yyy rows between zzz)
– 例如在scott.emp表中:xxx为deptno, yyy为sal,
– zzz为unbounded preceding and unbounded following
分析函数的例子:
显示各部门员工的工资,并附带显示该部分的最高工资。
SQL如下:
SELECT DEPTNO, EMPNO, ENAME, SAL, LAST_VALUE(SAL) OVER (PARTITION BY DEPTNO
ORDER BY SAL ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) MAX_SAL
FROM EMP;
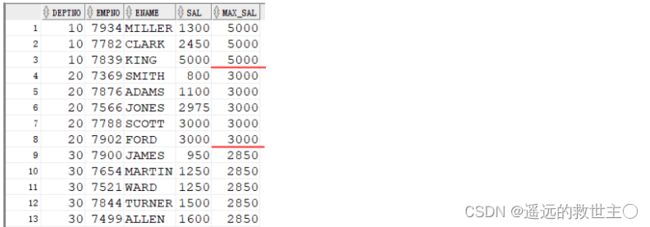
注: current row 表示当前行
unbounded preceding 表示第一行
unbounded following 表示最后一行
last_value(sal) 的结果与 order by sal 排序有关。如果排序为order by sal desc, 则最终的结果为分组排序后sal的最小值(分组排序后的最后一个值), 当deptno为10时,max_sal为1300
2.2 两个order by 的执行机制
分析函数是在整个SQL查询结束后(SQL语句中的order by 的执行比较特殊)再进行的操作,也就是说SQL语句中的order by也会影响分析函数的执行结果:
两者一致:如果SQL语句中的order by 满足分析函数分析时要求的排序,那么SQL语句中的排序将先执行,分析函数在分析时就不必再排序。
两者不一致:如果SQL语句中的order by 不满足分析函数分析时要求的排序,那么SQL语句中的排序将最后在分析函数分析结束后执行排序。
2.3 分析函数中的分组、排序、窗口
分析函数包含三个分析子句:分组(partition by)、排序(order by)、窗口(rows)。
窗口就是分析函数分析时要处理的数据范围,就拿sum来说,它是sum窗口中的记录而不是整个分组中的记录。因此我们在想得到某个栏位的累计值时,我们需要把窗口指定到该分组中的第一行数据到当前行,如果你指定该窗口从该分组中的第一行到最后一行,那么该组中的每一个sum值都会一样,即整个组的总和。
窗口子句中我们经常用到指定第一行,当前行,最后一行这样的三个属性:
第一行是 unbounded preceding
当前行是 current row
最后一行是 unbounded following
窗口子句不能单独出现,必须有order by 子句时才能出现,如:
LAST_VALUE(SAL) OVER (PARTITION BY DEPTNO ORDER BY SAL ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING )
以上示例指定窗口为整个分组.
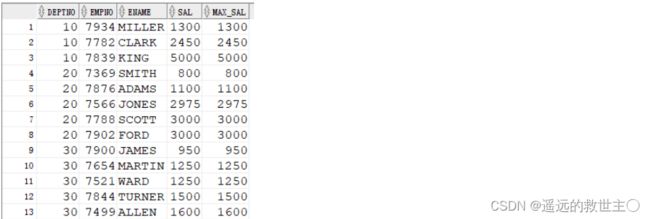
而出现order by 子句的时候,不一定要有窗口子句,但效果会不一样,此时窗口默认是当前组的第一行到当前行!
SQL语句为:
SELECT DEPTNO, EMPNO, ENAME, SAL,
last_value(SAL) OVER(PARTITION BY DEPTNO ORDER BY SAL) MAX_SAL FROM EMP;
等价于:
SELECT DEPTNO, EMPNO, ENAME, SAL,last_value(SAL) OVER(PARTITION BY DEPTNO
ORDER BY SAL ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) MAX_SAL FROM EMP;
结果如下图:
当省略窗口子句时:
- 如果存在order by, 则默认的窗口是 unbounded preceding and current row.
- 如果同时省略order by, 则默认的窗口是 unbounded preceding and unbounded following.
如果省略分组,则把全部记录当成一个组:
- 如果存在order by 则默认窗口是unbounded preceding and current row
- 如果这时省略order by 则窗口默认为 unbounded preceding and unbounded following
可参考:https://blog.csdn.net/poyue8754/article/details/123718482