【Python爬虫】5行代码破解验证码+网页数据爬取全步骤详细记录
文章目录
- 前言
- 一、抓包分析
- 二、编写模块代码
-
- 1.引入库
- 2.获取验证码图片
- 3.识别验证码
- 4.爬取列表页
- 5.爬取详情页
- 6.完整代码
- 总结
-
- 1.TIPS
- 2.如需交流,可在代码头找到我,或者用base64解密:5b6u5L+h77yabGluZ2ppZTIwMTQ=
前言
提示:内容仅限学习交流使用,切勿用于非法用途
本文用到的网址:aHR0cDovL3d3dy5jaGljdHIub3JnLmNuLw==(base64解密查看)
破解验证码方法挺多,本文介绍的是其中一种比较轻便的解决方案,适合小白上手。
爬虫需求:遍历列表页爬取每个详情页内容,需求很简单,但很多新手会卡在验证码这步,下面我们来实操一下:
一、抓包分析
通过抓包看到并没有json数据包,直接请求asp网页的,看网页设计风格估计这个网站也挺老了,搜索条件里写了几个参数,在请求的时候带上需要的字段就好

前面3页都很友好,但是从第4页开始,就出现了验证码:
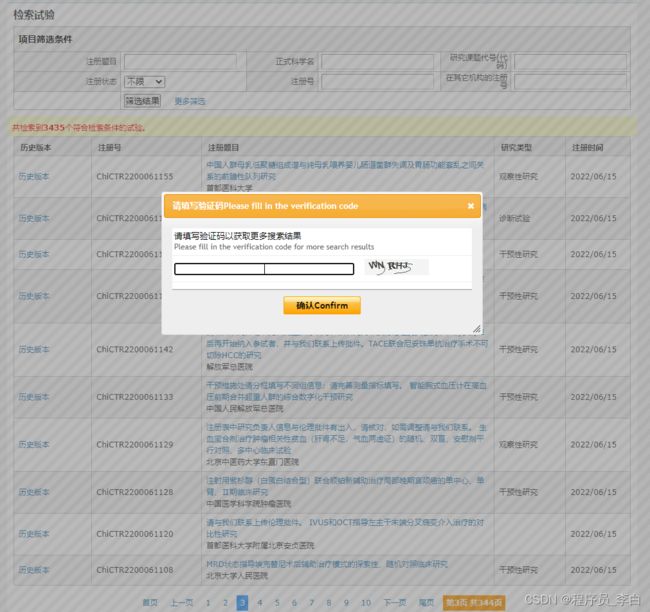
输入验证码,再次抓包看请求参数,发现是多了一个验证码的参数:verifycode

看到这里,思路也就出来了,直接对网页发请求,只要带上对应的验证码参数就能正确返回数据,所以我们要在网页请求前,先得到这个验证码,因为验证码是图片格式的,而且每次点击都会自动刷新,所以要怎么样才能保证刷新的这次验证码是正确的?我们来对验证码图片抓包分析看看:

经过几次查看验证码图片包,对比请求参数,发现只有time这个参数是每次会变的,其他参数都固定

在js里面可以看到这个time其实就是JAVA里的Math.random()方法生成出来的一个0-1的随机数,而在Python里,我们可以用random.uniform(0, 1)来生成
抓包分析完,到这所有问题其实都已经解决完了,整个步骤其实就是:获取验证码-识别验证码-请求列表页-请求内容页-数据提取-数据储存。
二、编写模块代码
1.引入库
import random
import requests
from lxml import etree
import ddddocr
import openpyxl
import logging
2.获取验证码图片
def getVerifyimagepage():
# 获取验证码图片
api = 'http://xxxxx.cn/Tools/verifyimagepage.aspx'
t = random.uniform(0, 1)
paramas = {
'textcolor': 2,
'bgcolor': 'F4F4F4',
'ut': 1,
'time': t,
}
try:
res = requests.get(api, headers=headers, params=paramas)
with open('img.jpg', 'wb') as img:
img.write(res.content)
except Exception as e:
print(e)
将获取到的验证码图片存储到本地目录
3.识别验证码
def imgRecognition(img):
# 识别验证码
try:
ocr = ddddocr.DdddOcr()
with open(img, 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
return res
except:
return None
识别验证码这里是引用了一个第三方库:ddddocr,对于这种大小写英文+数字的验证码足够满足需求了,识别正确率也很高,推荐新手使用。
4.爬取列表页
def getList(page, verifycode):
# 获取列表页上的url
api = 'http://xxxxx.cn/searchproj.aspx'
params = {
'minstudyexecutetime': '2020-07-01',
'province': '北京',
'btngo': 'btn',
'page': page,
'verifycode': verifycode,
}
try:
res = requests.get(api, headers=headers, params=params)
e = etree.HTML(res.text)
link_list = e.xpath('//table[@class="table_list"]/tbody/tr/td[3]/p/a/@href')
for link in link_list:
link = 'http://xxxxx.cn/' + link
f.write(str(page) + ',' + link + '\n')
print(page, link)
if link_list:
return 'ok'
else:
return None
except Exception as e:
print(e)
把页数和识别出来的验证码文本传进来,就可以直接请求出来列表页的数据
5.爬取详情页
def getDetailInfo(url):
# 提取详情页信息
try:
res = requests.get(url, headers=headers, timeout=10)
e = etree.HTML(res.text)
title = ''.join(e.xpath('//div[@class="ProjetInfo_ms"][1]//tr[10]/td[2]/p/text()')).strip()
item_info = e.xpath('//div[@class="ProjetInfo_ms"][2]')
left_name = ''.join(item_info[0].xpath('.//tr[1]/td[2]/p/text()')).strip()
right_name = ''.join(item_info[0].xpath('.//tr[1]/td[4]/p/text()')).strip()
left_phone = ''.join(item_info[0].xpath('.//tr[3]/td[2]/text()')).strip()
right_phone = ''.join(item_info[0].xpath('.//tr[3]/td[4]/text()')).strip()
unit = ''.join(item_info[0].xpath('.//tr[10]/td[2]/p/text()')).strip()
print(index, title, left_name, right_name, left_phone, right_phone, unit)
sh1.append([url, title, left_name, left_phone, right_name, right_phone, unit])
except Exception as e:
logging.error(f'{index}, {url}\n')
详情页就非常简单了,直接请求页面没有任何限制,用xpath提取内容,最后用openpyxl做数据存储,大功告成!
6.完整代码
# !/usr/bin/env python
# -*- coding:utf-8 -*-
# FileName :chictrSpider.py
# Time :2022/6/7 14:41
# Author :JACK
# VX :lingjie2014
import random
import requests
from lxml import etree
import ddddocr
import openpyxl
import logging
logging.basicConfig(filename='logging.log', level=logging.ERROR, format='%(asctime)s - %(levelname)s - %(message)s')
def getList(page, verifycode):
# 获取列表页的url
api = 'http://xxxxx.cn/searchproj.aspx'
params = {
'minstudyexecutetime': '2020-07-01',
'province': '北京',
'btngo': 'btn',
'page': page,
'verifycode': verifycode,
}
try:
res = requests.get(api, headers=headers, params=params)
e = etree.HTML(res.text)
link_list = e.xpath('//table[@class="table_list"]/tbody/tr/td[3]/p/a/@href')
for link in link_list:
link = 'http://xxxxx.cn/' + link
f.write(str(page) + ',' + link + '\n')
print(page, link)
if link_list:
return 'ok'
else:
return None
except Exception as e:
print(e)
def getVerifyimagepage():
# 获取验证码图片
api = 'http://xxxxx.cn/Tools/verifyimagepage.aspx'
t = random.uniform(0, 1)
paramas = {
'textcolor': 2,
'bgcolor': 'F4F4F4',
'ut': 1,
'time': t,
}
try:
res = requests.get(api, headers=headers, params=paramas)
with open('img.jpg', 'wb') as img:
img.write(res.content)
except Exception as e:
print(e)
def imgRecognition(img):
# 识别验证码
try:
ocr = ddddocr.DdddOcr()
with open(img, 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
return res
except:
return None
def getDetailInfo(url):
# 提取详情页信息
try:
res = requests.get(url, headers=headers, timeout=10)
e = etree.HTML(res.text)
title = ''.join(e.xpath('//div[@class="ProjetInfo_ms"][1]//tr[10]/td[2]/p/text()')).strip()
item_info = e.xpath('//div[@class="ProjetInfo_ms"][2]')
left_name = ''.join(item_info[0].xpath('.//tr[1]/td[2]/p/text()')).strip()
right_name = ''.join(item_info[0].xpath('.//tr[1]/td[4]/p/text()')).strip()
left_phone = ''.join(item_info[0].xpath('.//tr[3]/td[2]/text()')).strip()
right_phone = ''.join(item_info[0].xpath('.//tr[3]/td[4]/text()')).strip()
unit = ''.join(item_info[0].xpath('.//tr[10]/td[2]/p/text()')).strip()
print(index, title, left_name, right_name, left_phone, right_phone, unit)
sh1.append([url, title, left_name, left_phone, right_name, right_phone, unit])
except Exception as e:
logging.error(f'{index}, {url}\n')
if __name__ == "__main__":
headers = {
'Host': 'xxxxx.cn',
'Cookie': 'onlineusercount=1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36',
}
f = open('url.txt', 'a+', encoding='utf-8')
for page in range(1, 336):
# time.sleep(1)
while True:
print(f'正在采集第 {page} 页...')
getVerifyimagepage() # 获取验证码
verifycode = imgRecognition('img.jpg') # 识别验证码
result = getList(page, verifycode)
# 如果有返回数据,退出循环,否则重新获取识别验证码,重新请求
if result:
break
f.close()
wb = openpyxl.Workbook()
all_sheetnames = wb.sheetnames
sh1 = wb[all_sheetnames[0]]
sh1.append(['链接', '标题', '申请注册联系人', '申请注册联系人电话', '研究负责人', '研究负责人电话', '申请人所在单位'])
url_list = []
with open('url.txt', 'r') as fp:
for line in fp.readlines():
url_list.append(line.strip().split(',')[-1])
for index, url in enumerate(url_list):
getDetailInfo(url)
# break
wb.save('all_data.xlsx')
print('DONE!')
总结
1.TIPS
本案例实际上难度不大,唯一难点也只是验证码的获取与识别,在此再次推荐一下ddddocr这个包,方便快捷,几行代码即可准确识别验证码,但如果防识别较高的验证码估计就很吃力了,另外还可以试下百度云的api也挺好用。