Diffusion Models
DDPM
x 0 ∼ q ( x 0 ) x_0 \sim q(x_0) x0∼q(x0)是真实数据分布,扩散模型学习一个分布 p θ ( x 0 ) p_\theta(x_0) pθ(x0)去逼近真实数据分布。
p θ ( x 0 ) : = ∫ p θ ( x 0 : T ) d x 1 : T (1) p_\theta(x_0) := \int p_\theta(x_{0:T})dx_{1:T} \tag{1} pθ(x0):=∫pθ(x0:T)dx1:T(1)
x 1 , . . . , x T x_1,...,x_T x1,...,xT是和数据 x 0 ∼ q ( x 0 ) x_0 \sim q(x_0) x0∼q(x0)相同维度的隐变量。联合概率分布 p θ ( x 0 : T ) p_\theta(x_{0:T}) pθ(x0:T)称为reverse process,逆过程,去噪过程。被定义为从 p ( x T ) = N ( x T ; 0 , I ) p(x_T)=N(x_T;\bold0,\bold I) p(xT)=N(xT;0,I)开始的马尔可夫链,转移矩阵为高斯分布。
p θ ( x 0 : T ) : = p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) (2) p_\theta(x_{0:T}) :=p(x_T)\prod_{t=1}^T p_\theta(x_{t-1}|x_t) \tag{2} pθ(x0:T):=p(xT)t=1∏Tpθ(xt−1∣xt)(2)
p θ ( x t − 1 ∣ x t ) : = N ( x t − 1 ; μ θ ( x t , t ) , Σ θ ( x t , t ) ) (3) p_\theta(x_{t-1}|x_t) :=N(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t)) \tag{3} pθ(xt−1∣xt):=N(xt−1;μθ(xt,t),Σθ(xt,t))(3)
均值和方差是 x t , t x_t, t xt,t的函数,标准高斯分布有了均值和方差,就可以从 x t x_t xt中采样出 x t − 1 x_{t-1} xt−1。
diffusion模型不同于其他隐变量模型的地方在于,近似后验分布 q ( x 1 : T ∣ x 0 ) q(x_{1:T}|x_0) q(x1:T∣x0),一般也被称为前向过程或者diffusion过程,是一个马尔可夫链。可以根据方差调度值 β 1 , . . . , β T \beta_1,..., \beta_T β1,...,βT逐步对数据 x 0 x_0 x0加噪声。
q ( x 1 : T ∣ x 0 ) : = ∏ t = 1 T q ( x t ∣ x t − 1 ) (4) q(x_{1:T}|x_0) := \prod_{t=1}^Tq(x_t|x_{t-1}) \tag{4} q(x1:T∣x0):=t=1∏Tq(xt∣xt−1)(4)
q ( x t ∣ x t − 1 ) : = N ( x t ; , 1 − β t x t − 1 , β t I ) (5) q(x_t|x_{t-1}) := N(x_t;, \sqrt{1-\beta_t}x_{t-1}, \beta_t\bold I) \tag{5} q(xt∣xt−1):=N(xt;,1−βtxt−1,βtI)(5)
我们定义:
a t : = 1 − β t , a ˉ t : = ∏ s = 1 t α s (6) a_t := 1 - \beta_t, \quad \bar{a}_t := \prod_{s=1}^{t} \alpha_s \tag{6} at:=1−βt,aˉt:=s=1∏tαs(6)
x t = α t x t − 1 + 1 − α t ϵ t , ϵ t ∼ N ( 0 , I ) (7) x_t = \sqrt{\alpha_t}x_{t-1} + \sqrt{1-\alpha_t}\epsilon_t, \quad \epsilon_t \sim N(\bold0, \bold I) \tag{7} xt=αtxt−1+1−αtϵt,ϵt∼N(0,I)(7)
x t − 1 = α t − 1 x t − 2 + 1 − α t − 1 ϵ t − 1 , ϵ t − 1 ∼ N ( 0 , I ) (8) x_{t-1} = \sqrt{\alpha_{t-1}}x_{t-2} + \sqrt{1-\alpha_{t-1}}\epsilon_{t-1}, \quad \epsilon_{t-1} \sim N(\bold0, \bold I) \tag{8} xt−1=αt−1xt−2+1−αt−1ϵt−1,ϵt−1∼N(0,I)(8)
x t = α t ( α t − 1 x t − 2 + 1 − α t − 1 ϵ t − 1 ) + 1 − α t ϵ t = α t α t − 1 x t − 2 + α t − α t α t − 1 ϵ t − 1 + 1 − α t ϵ t = N ( x t ; α t α t − 1 x t − 2 , 1 − α t α t − 1 I ) = α t α t − 1 x t − 2 + 1 − α t α t − 1 ϵ ~ t . . . . . . = N ( x t ; α ˉ t x 0 , 1 − α ˉ t I ) (9) \begin{aligned} x_t &= \sqrt{\alpha_t}(\sqrt{\alpha_{t-1}}x_{t-2} + \sqrt{1-\alpha_{t-1}}\epsilon_{t-1}) + \sqrt{1-\alpha_t}\epsilon_t \\ &= \sqrt{\alpha_t\alpha_{t-1}}x_{t-2} + \sqrt{\alpha_t - \alpha_t\alpha_{t-1}}\epsilon_{t-1} + \sqrt{1-\alpha_t}\epsilon_t \\ &=N(x_t; \sqrt{\alpha_t\alpha_{t-1}}x_{t-2}, \sqrt{1-\alpha_t\alpha_{t-1}}\bold I) \\ &=\sqrt{\alpha_t\alpha_{t-1}}x_{t-2} + \sqrt{1-\alpha_t\alpha_{t-1}}\tilde{\epsilon}_t \\ & ...... \\ &= N(x_t; \sqrt{\bar{\alpha}_t}x_0, \sqrt{1 - \bar{\alpha}_t} \bold I) \tag{9} \end{aligned} xt=αt(αt−1xt−2+1−αt−1ϵt−1)+1−αtϵt=αtαt−1xt−2+αt−αtαt−1ϵt−1+1−αtϵt=N(xt;αtαt−1xt−2,1−αtαt−1I)=αtαt−1xt−2+1−αtαt−1ϵ~t......=N(xt;αˉtx0,1−αˉtI)(9)
这个性质很重要,意味着可以不需要迭代过程,直接获得任意时间t的加噪数据。正常来说T都比较大,DDPM设为1000, a t = 1 − β t ∈ [ 0 , 1 ] a_t = 1 - \beta_t \in [0, 1] at=1−βt∈[0,1], 根据极限可知,随着t越来越大,最终加噪后的数据分布趋近于各向同性的标准高斯分布。也为reverse process从一个标准高斯分布采样开始逐步去噪得到最终sample的过程,两相契合。
forward process是加噪过程,也是训练过程,从数据集中采样 x 0 ∼ q ( x 0 ) x_0 \sim q(x_0) x0∼q(x0),随机选取timestep t, 根据式(9)得到 x t x_t xt, x t x_t xt和 t t t做为网络输入,估算后验分布 q ( x t − 1 ∣ x t , x 0 ) q(x_{t-1}|x_t, x_0) q(xt−1∣xt,x0),假设后验分布为高斯分布,则估算的就是高斯分布的均值和方差,式(11)和(12)就是网络学习时,均值和方差的gt。DDPM这篇工作假设方差是预定义好的,不需要网络学习。只需要学习均值即可。
q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ ~ t ( x t , x 0 ) , β t ~ I ) (10) q(x_{t-1}|x_t, x_0) = N(x_{t-1}; \tilde{\mu}_t(x_t, x_0), \tilde{\beta_t}\bold I) \tag{10} q(xt−1∣xt,x0)=N(xt−1;μ~t(xt,x0),βt~I)(10)
where
μ ~ t ( x t , x 0 ) : = α ˉ t − 1 β t 1 − α ˉ t x 0 + α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t (11) \tilde{\mu}_t(x_t, x_0) :=\frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1-\bar{\alpha}_t}x_0 + \frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})} {1-\bar{\alpha}_t} x_t \tag{11} μ~t(xt,x0):=1−αˉtαˉt−1βtx0+1−αˉtαt(1−αˉt−1)xt(11)
and
β ~ t : = 1 − α ˉ t − 1 1 − α ˉ t β t (12) \tilde{\beta}_t := \frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_t} \beta_t \tag{12} β~t:=1−αˉt1−αˉt−1βt(12)
具体推导如下:
q ( x t − 1 ∣ x t , x 0 ) = q ( x t ∣ x t − 1 , x 0 ) q ( x t − 1 ∣ x 0 ) q ( x t ∣ x 0 ) ∝ e x p ( − 1 2 ( ( x t − α t x t − 1 ) 2 β t + ( x t − 1 − α ˉ t − 1 x 0 ) 2 1 − α ˉ t − 1 + ( x t − α ˉ t x 0 ) 2 1 − α ˉ t ) ) = e x p ( − 1 2 ( ( α t β t + 1 1 − α ˉ t − 1 ) x t − 1 2 + ( 2 α t β t + 2 α ˉ t − 1 x 0 1 − α ˉ t − 1 ) x t − 1 + C ( x 0 , x t ) ) ) (13) \begin{aligned} q(x_{t-1}|x_t, x_0) &=q(x_t|x_{t-1}, x_0)\frac{q(x_{t-1}|x_0)}{q(x_{t}|x_0)} \\ & \propto exp(-\frac{1}{2}(\frac{(x_t - \sqrt{\alpha_t}x_{t-1})^2}{\beta_t} + \frac{(x_{t-1}-\sqrt{\bar{\alpha}_{t-1}}x_0)^2}{1-\bar{\alpha}_{t-1}} + \frac{(x_{t}-\sqrt{\bar{\alpha}_{t}}x_0)^2}{1-\bar{\alpha}_{t}}))\\ &= exp(-\frac{1}{2}((\frac{\alpha_t}{\beta_t} + \frac{1}{1-\bar{\alpha}_{t-1}})x^2_{t-1} + (\frac{2\sqrt{\alpha_t}}{\beta_t} + \frac{2\sqrt{\bar{\alpha}_{t-1}}x_0}{1-\bar{\alpha}_{t-1}})x_{t-1} + C(x_0, x_t))) \tag{13}\\ \end{aligned} q(xt−1∣xt,x0)=q(xt∣xt−1,x0)q(xt∣x0)q(xt−1∣x0)∝exp(−21(βt(xt−αtxt−1)2+1−αˉt−1(xt−1−αˉt−1x0)2+1−αˉt(xt−αˉtx0)2))=exp(−21((βtαt+1−αˉt−11)xt−12+(βt2αt+1−αˉt−12αˉt−1x0)xt−1+C(x0,xt)))(13)
将上式整理为高斯分布形式,可得:
β ~ t = 1 α t β t + 1 1 − α ˉ t − 1 = 1 − α ˉ t − 1 1 − α ˉ t β t (14) \tilde{\beta}_t = \frac{1}{\frac{\alpha_t}{\beta_t} + \frac{1}{1-\bar{\alpha}_{t-1}}}=\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_{t}}\beta_t \tag{14} β~t=βtαt+1−αˉt−111=1−αˉt1−αˉt−1βt(14)
μ ~ t ( x t , x 0 ) = ( α t β t + α ˉ t − 1 x 0 1 − α ˉ t − 1 ) / ( α t β t + 1 1 − α ˉ t − 1 ) = ( α t β t + α ˉ t − 1 x 0 1 − α ˉ t − 1 ) ⋅ ( 1 − α ˉ t − 1 1 − α ˉ t β t ) = α t ( 1 − α ˉ t − 1 ) 1 − α t x t + α ˉ t − 1 β t 1 − α ˉ t x 0 (15) \begin{aligned} \tilde{\mu}_t(x_t, x_0) &=(\frac{\sqrt{\alpha_t}}{\beta_t} + \frac{\sqrt{\bar{\alpha}_{t-1}}x_0}{1-\bar{\alpha}_{t-1}}) / (\frac{\alpha_t}{\beta_t} + \frac{1}{1-\bar{\alpha}_{t-1}}) \\ &= (\frac{\sqrt{\alpha_t}}{\beta_t} + \frac{\sqrt{\bar{\alpha}_{t-1}}x_0}{1-\bar{\alpha}_{t-1}}) \cdot(\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_{t}}\beta_t)\\ &=\frac{\sqrt{\alpha_t}(1-\bar{\alpha}_{t-1})}{1-\alpha_t}x_t + \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1-\bar{\alpha}_t}x_0 \\ \tag{15} \end{aligned} μ~t(xt,x0)=(βtαt+1−αˉt−1αˉt−1x0)/(βtαt+1−αˉt−11)=(βtαt+1−αˉt−1αˉt−1x0)⋅(1−αˉt1−αˉt−1βt)=1−αtαt(1−αˉt−1)xt+1−αˉtαˉt−1βtx0(15)
一般DDPM的代码中会提前算好 x t x_t xt和 x 0 x_0 x0之前的系数。
根据式(9)可得:
x 0 = 1 α t ( x t − 1 − α ˉ t Z t ) (16) x_0 = \frac{1}{\sqrt{\alpha}_t}(x_t - \sqrt{1-\bar{\alpha}_t}Z_t) \tag{16} x0=αt1(xt−1−αˉtZt)(16)
代入式(15)进一步化简可得:
μ ~ t ( x t , x 0 ) = 1 α t ( x t − β t 1 − α ˉ t Z t ) \tilde{\mu}_t(x_t, x_0) = \frac{1}{\sqrt{\alpha}_t}(x_t - \frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}Z_t) μ~t(xt,x0)=αt1(xt−1−αˉtβtZt)
这里的 Z t Z_t Zt为t时刻的高斯噪声。
网络收敛后,就可以从 x T ∼ N ( 0 , I ) x_T\sim N(\bold 0, \bold I) xT∼N(0,I)采样开始。逐步去噪,得到最终的样本。
(这个还要补个VLB的推导)
最大化log likelihood, 也即最小化negative log likelihood,
L = E q [ − l o g p θ ( x 0 : T ) q ( x 1 : T ∣ x 0 ) ] = E q [ ] \begin{aligned} L &=E_q[-log\frac{p_\theta(x_{0:T})}{q(x_{1:T}|x_0)}] \\ &= E_q[] \\ \end{aligned} L=Eq[−logq(x1:T∣x0)pθ(x0:T)]=Eq[]
网络学习和输出的是t时刻的噪声。根据下式得到均值:
μ θ ( x t , t ) = 1 α t ( x t − β t 1 − α ˉ t ϵ θ ( x t , t ) ) \mu_\theta(x_t, t) = \frac{1}{\sqrt{\alpha}_t}(x_t - \frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon_\theta(x_t, t)) μθ(xt,t)=αt1(xt−1−αˉtβtϵθ(xt,t))
采样 x t − 1 ∼ p θ ( x t − 1 ∣ x t ) x_{t-1}\sim p_\theta(x_{t-1}|x_t) xt−1∼pθ(xt−1∣xt)可以通过 x t − 1 = μ θ ( x t , t ) + σ z x_{t-1}=\mu_\theta(x_t, t) + \sigma z xt−1=μθ(xt,t)+σz得到, z ∼ N ( 0 , I ) z\sim N(\bold 0, \bold I) z∼N(0,I)。

DDPM的优点就不说了,缺点主要有两个,推理过程步长太长,过于耗时。 β \beta β的设计导致加噪到T时刻,信噪比SNR不为0,加噪对原始数据分布破坏的不彻底,得到的不是真实的高斯分布噪声,原始数据分布中的一些低频信息泄露,导致文生图任务中,即便强prompt引导,生成的图片亮度也是围绕到0.5周围,无法产生过亮或者过暗的图片。
DDIM
解决DDPM的步长问题。
Progressive Distillation
进一步解决DDPM的步长问题。
Zero SNR
解决常规 β \beta β调度策略无法产生zero SNR的问题。
SDE
扰动核函数perturbation kernel如下,对x施加一个方差为 σ 2 I \sigma^2 \bold I σ2I的扰动:
p σ ( x ~ ∣ x ) : = N ( x ~ ; x , σ 2 I ) p_\sigma(\tilde{x}|x) := N(\tilde{x};x, \sigma^2 \bold I) pσ(x~∣x):=N(x~;x,σ2I)
我们考虑如下的噪声尺度序列:
σ m i n = σ 1 < σ 2 < . . . < σ N = σ m a x \sigma_{min} = \sigma_{1} < \sigma_2<...<\sigma_N = \sigma_{max} σmin=σ1<σ2<...<σN=σmax
σ m i n \sigma_{min} σmin足够小,以至于 p σ m i n ( x ) ≈ p d a t a ( x ) p_{\sigma_{min}}(x)\approx p_{data}(x) pσmin(x)≈pdata(x); σ m a x \sigma_{max} σmax足够大,以至于 p σ m a x ( x ) ≈ N ( x ; 0 , σ m a x 2 I ) p_{\sigma_{max}}(x)\approx N(x; \bold 0, \sigma^2_{max}\bold I) pσmax(x)≈N(x;0,σmax2I)。
我们用 S θ ( x , σ ) S_\theta(x, \sigma) Sθ(x,σ)表示Noise Condtional Score Network (NCSN), 该网络的目标函数如下,可以理解为找到最优参数 θ \theta θ,可以最小化denoising score matching,所有噪声尺度的加权和:
Stochastic Differential Equations

Forward SDE (data -> noise):
d x = f ( x , t ) d t + g ( t ) d w dx = f(x, t)dt + g(t)dw dx=f(x,t)dt+g(t)dw
Reverse SDE (noise -> data):
d x = [ f ( x , t ) − g 2 ( t ) ∇ x l o g p t ( x ) ] d t + g ( t ) d w ˉ dx = [f(x,t) - g^2(t)\nabla_xlogp_t(x)]dt + g(t)d\bar{w} dx=[f(x,t)−g2(t)∇xlogpt(x)]dt+g(t)dwˉ
这里面的 ∇ x l o g p t ( x ) \nabla_xlogp_t(x) ∇xlogpt(x)就是score function:the gradient of the log probability density with respect to data。
SD
vae + unet + clip encoder + noise scheduler
SDXL Turbo
文章:Adversarial Diffusion Distillation
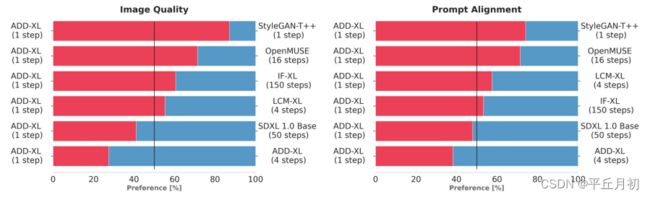
目标是用尽可能少的steps生成高保真样本,质量对标SOTA模型。
方法:引入两个训练目标函数的结合,1)adversatial loss:迫使模型每次的前向推理,生成的样本都在真实图片的流形上,避免产生模糊和其他典型的artifacts。2)distillation loss:用另外一个预训练好的DM模型做老师,学习教师模型的强大合成能力。
SDXL Turbo推理时,没有使用classifier-free guidance,进一步降低了内存消耗。
ADD-student用预训练的UNet-DM权重 θ \theta θ进行初始化,判别器的可训练权重表示为 ϕ \phi ϕ,DM-teacher的冻结权重表示为 ψ \psi ψ。训练时,ADD学生模型从噪声数据 x s x_s xs生成样本 x ^ θ ( x s , s ) \hat{x}_\theta(x_s, s) x^θ(xs,s), x s = α s x 0 + σ s ϵ x_s = \alpha_s x_0 + \sigma_s\epsilon xs=αsx0+σsϵ
L = L a d v G ( x ^ θ ( x s , s ) , ϕ ) + λ L d i s t i l l ( x ^ θ ( x s , s ) , ψ ) L = L_{adv}^G(\hat{x}_\theta(x_s, s), \phi) + \lambda L_{distill}(\hat{x}_\theta(x_s, s), \psi) L=LadvG(x^θ(xs,s),ϕ)+λLdistill(x^θ(xs,s),ψ)
L d i s t i l l ( x ^ θ ( x s , s ) , ψ ) = E t , ϵ ′ [ c ( t ) d ( x ^ θ , x ^ ψ ( s g ( x ^ θ , t ) ; t ) ) ] L_{distill}(\hat{x}_\theta(x_s, s), \psi) = E_{t, \epsilon^{'}}[c(t)d(\hat{x}_\theta, \hat{x}_\psi(sg(\hat{x}_{\theta, t}); t))] Ldistill(x^θ(xs,s),ψ)=Et,ϵ′[c(t)d(x^θ,x^ψ(sg(x^θ,t);t))]
L a d v G ( x ^ θ ( x s , s ) , ϕ ) = E x 0 [ ∑ k ( m a x ( 0 , 1 − D ϕ , k ( F k ( x 0 ) ) ) + γ R 1 ( ϕ ) ] + E x ^ θ [ ∑ k ( m a x ( 0 , 1 + D ϕ , k ( F k ( x ^ θ ) ) ) ] L_{adv}^G(\hat{x}_\theta(x_s, s), \phi) = E_{x_0}[\sum_k(max(0, 1 - D_{\phi, k}(F_k(x_0))) + \gamma R_1(\phi)] + E_{\hat{x}_\theta}[\sum_k(max(0, 1 + D_{\phi, k}(F_k(\hat{x}_\theta)))] LadvG(x^θ(xs,s),ϕ)=Ex0[k∑(max(0,1−Dϕ,k(Fk(x0)))+γR1(ϕ)]+Ex^θ[k∑(max(0,1+Dϕ,k(Fk(x^θ)))]
x ^ θ \hat{x}_\theta x^θ: student sample
x ^ ψ ( x ^ θ , t , t ) \hat{x}_\psi(\hat{x}_{\theta, t}, t) x^ψ(x^θ,t,t): teacher’s denoising prediction, 做为蒸馏loss的重建目标。
λ \lambda λ: R 1 R_1 R1惩罚的强度,文章的经验值是2.5。
R 1 R_1 R1: 代表 R 1 R_1 R1梯度惩罚。
F F F: frozen pretrained feature network,这里用的是ViT, F k F_k Fk是特征网络不同层的输出特征。
s g sg sg: stop gradient operation。
d d d: distance metric, 用来衡量ADD-student生成样本 x θ x_\theta xθ和DM-teacher的输出之间的不匹配度。 d ( x , y ) : = ∣ ∣ x − y ∣ ∣ 2 2 d(x, y) := ||x - y||_2^2 d(x,y):=∣∣x−y∣∣22
c ( t ) c(t) c(t): weighting function。
实验阶段,训练了两个不同容量的模型,ADD-M 860M 参数量,继承SD 2.1 backbone的权重,ADD-XL 3.1B参数量,继承SDXL backbone的权重。所有实验在512x512分辨率上进行。