准备数据
!wget --no-check-certificate \
https://storage.googleapis.com/laurencemoroney-blog.appspot.com/horse-or-human.zip \
-O /tmp/horse-or-human.zip
该目录下又分别包含horses和humans子目录。
简而言之:训练集就是用来告诉神经网络模型"这就是马的样子"、"这就是人的样子"等数据。
这里需要注意的是,我们并没有明确地将图像标注为马或人。如果还记得之前的手写数字例子,它的训练数据已经标注了"这是一个1","这是一个7"等等。 稍后,我们使用一个叫做ImageGenerator的类--用它从子目录中读取图像,并根据子目录的名称自动给图像贴上标签。所以,会有一个"训练"目录,其中包含一个"马匹"目录和一个"人类"目录。ImageGenerator将为你适当地标注图片,从而减少一个编码步骤。(不仅编程上更方便,而且可以避免一次性把所有训练数据载入内存,而导致内存不够等问题。)
让我们分别定义这些目录。
# Directory with our training horse pictures
train_horse_dir = os.path.join('/tmp/horse-or-human/horses')
# Directory with our training human pictures
train_human_dir = os.path.join('/tmp/horse-or-human/humans')建模
像前面的例子一样添加卷积层CNN,并将最终结果扁平化,以输送到全连接的层去。
最后我们添加全连接层。
需要注意的是,由于我们面对的是一个两类分类问题,即二类分类问题,所以我们会用sigmoid激活函数作为模型的最后一层,这样我们网络的输出将是一个介于0和1之间的有理数,即当前图像是1类(而不是0类)的概率。

BTW, 如果是是多个分类,比如前面提到的0~9个分类用的softmax激活函数。
import tensorflow as tf
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(150, 150,3)),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
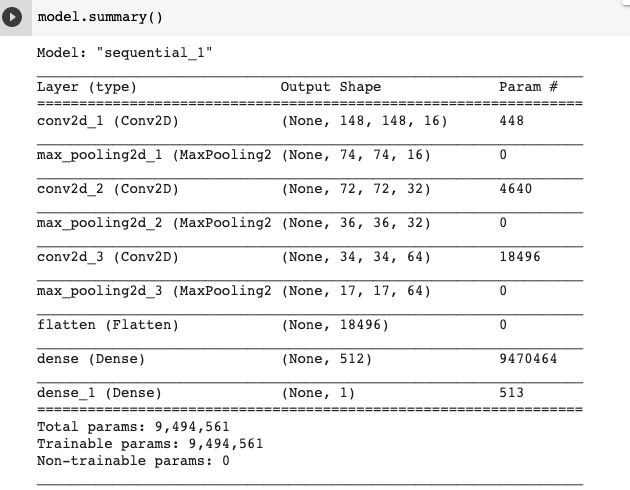
])调用model.summary()方法打印出神经元网络模型的结构信息
接下来,我们将配置模型训练的参数。我们将用 "binary_crossentropy(二元交叉熵)"衡量损失,因为这是一个二元分类问题,最终的激活函数是一个sigmoid。关于损失度量的复习,请参见机器学习速成班。我们将使用rmsprop作为优化器,学习率为0.001。在训练过程中,我们将希望监控分类精度。
NOTE.我们将使用学习率为0.001的rmsprop优化器。在这种情况下,使用RMSprop优化算法比随机梯度下降(SGD)更可取,因为RMSprop可以为我们自动调整学习率。(其他优化器,如Adam和Adagrad,也会在训练过程中自动调整学习率,在这里也同样有效。)
from tensorflow.keras.optimizers import RMSprop
model.compile(loss=tf.keras.losses.BinaryCrossentropy(),
optimizer=tf.keras.optimizers.RMSprop(lr=0.001),
metrics=['acc'])数据预处理
让我们设置训练数据生成器(ImageDataGenerator),它将读取源文件夹中的图片,将它们转换为float32多维数组,并将图像数据(连同它们的标签)反馈给神经元网络。总共需要两个生成器,有用于产生训练图像,一个用于产生验证图像。生成器将产生一批大小为300x300的图像及其标签(0或1)。
前面的课中我们已经知道如何对训练数据做归一化,进入神经网络的数据通常应该以某种方式进行归一化,以使其更容易被网络处理。在这个例子中,我们将通过将像素值归一化到[0, 1]范围内(最初所有的值都在[0, 255]范围内)来对图像进行预处理。
在Keras中,可以通过keras.preprocessing.image.ImageDataGenerator类使用rescale参数来实现归一化。通过ImageDataGenerator类的.flow(data, labels)或.flow_from_directory(directory),可以创建生成器。然后,这些生成器可以作为输入Keras方法的参数,如fit_generator、evaluate_generator和predict_generator都可接收生成器实例为参数。
from tensorflow.keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1/255)
train_generator = train_datagen.flow_from_directory(
'/tmp/horse-or-human/',
target_size=(150, 150),
batch_size=32,
class_mode='binary'
)训练
history = model.fit(
train_generator,
steps_per_epoch=10,
epochs=10,
verbose=1
)
调参
构造神经元网络模型时,
- 一定会考虑
需要几个卷积层? 过滤器应该几个?全连接层需要几个神经元?
最先想到的肯定是手动修改那些参数,然后观察训练的效果(损失和准确度),从而判断参数的设置是否合理。但是那样很繁琐,因为参数组合会有很多,训练时间很长。再进一步,可以手动编写一些循环,通过遍历来搜索合适的参数。但是最好利用专门的框架来搜索参数,不太容易出错,效果也比前两种方法更好。
Kerastuner就是一个可以自动搜索模型训练参数的库。它的基本思路是在需要调整参数的地方插入一个特殊的对象(可指定参数范围),然后调用类似训练那样的search方法即可。
接下来首先准备训练数据和需要加载的库。
如果没有这个库先安装
pip3 install -U keras-tuner,不然会提示错误。ModuleNotFoundError: No module named 'kerastuner
import os
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import RMSprop
train_datagen = ImageDataGenerator(rescale=1/255)
validation_datagen = ImageDataGenerator(rescale=1/255)
train_generator = train_datagen.flow_from_directory('/tmp/horse-or-human/',
target_size=(150, 150),batch_size=32,class_mode='binary')
# validation_generator = validation_datagen.flow_from_directory('/tmp/validation-horse-or-human/',
# target_size=(150, 150), batch_size=32,class_mode='binary')
from kerastuner.tuners import Hyperband
from kerastuner.engine.hyperparameters import HyperParameters
import tensorflow as tf接着创建HyperParameters对象,然后在模型中插入Choice、Int等调参用的对象。
hp=HyperParameters()
def build_model(hp):
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2D(hp.Choice('num_filters_top_layer',values=[16,64],default=16), (3,3),
activation='relu', input_shape=(150, 150, 3)))
model.add(tf.keras.layers.MaxPooling2D(2, 2))
for i in range(hp.Int("num_conv_layers",1,3)):
model.add(tf.keras.layers.Conv2D(hp.Choice(f'num_filters_layer{i}',values=[16,64],default=16), (3,3), activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(2,2))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(hp.Int("hidden_units",128,512,step=32), activation='relu'))
model.add(tf.keras.layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',optimizer=RMSprop(lr=0.001),metrics=['acc'])
return model- 第一个参数Choice是CNN的过滤器,范围是16~64,最好是32的倍数,默认是16
- 第二个参数是Int,设置几个CNN,13个,且每个CNN卷积神经网络的过滤器个数为1664,默认16
- 第三个全连接需要几个神经元,128~512,步长为32。即:128、128+32....
他们的第一个参数是name,随意命名,最好知道且表达出来即可。
然后创建Hyperband对象,这是Kerastuner支持的四种方法的其中一种,可以轻易的限定搜索空间去优化部分参数。具体资料可以到Kerastuner的网站获取。关于其他三种tuner:RandomSearch、 BayesianOptimization 和 Sklearn
最后调用search方法。
tuner=Hyperband(
build_model,
objective='val_acc',
max_epochs=10,
directory='horse_human_params',
hyperparameters=hp,
project_name='my_horse_human_project'
)
tuner.search(train_generator,epochs=10,validation_data=validation_generator)
搜索到最优参数后,可以通过下面的程序,用tuner对象提取最优参数构建神经元网络模型。并调用summary方法观察优化后的网络结构。
best_hps=tuner.get_best_hyperparameters(1)[0]
print(best_hps.values)
model=tuner.hypermodel.build(best_hps)
model.summary()