【数模百科】一文快速讲清楚层次分析法AHP(附python代码和参考美赛论文)
本文摘录自 层次分析法原理 - 数模百科,如果你想了解更多关于层次分析法的知识,请移步数模百科。
层次分析法(Analytic Hierarchy Process,简称AHP)是一种解决复杂决策问题的方法。这个方法是由美国运筹学家托马斯·萨蒂(Thomas L. Saaty)在上世纪70年代发明的。
那时候,萨蒂教授想要找到一个既科学又实用的方法,帮助人们在面对很多难以直接比较的选择项时,能够做出最合适的决策。比如说,假如你要买房子,可能会考虑房子的价格、位置、大小、环境等多个因素。这些因素之间怎么比较,哪个更重要?单靠直觉或者简单的加减乘除很难做出满意的决定。
这时候,层次分析法就派上用场了。它的核心思想就是把复杂的问题分解成多个层次和因素,然后通过一种系统的方式来评估这些因素的重要性,最后综合这些信息帮助决策者做出选择。
层次分析法适用的场景非常广泛。它不仅可以用在个人决策,比如选择学校、工作或者买车,也能用在企业决策,比如产品规划、市场选择或者资源分配等。此外,政府部门在制定政策、评估项目优劣时也经常使用这个方法。
简单来说,只要是需要从多个角度考虑,涉及多个因素,而且这些因素之间不好直接比较的情况,层次分析法都能派上用场。通过分解问题、评估因素重要性,它帮助人们在复杂的选项中找到最合适的答案。
白话文
沈墨宸身着剪裁精致的学士服,肩挂流苏,在春风中跳跃。他脸上挂着释然的笑容,刚步出大学生活的重要里程碑。毕业典礼上,校长的话语如激昂的乐章,激励着每个青春的心。朋友间的欢笑与拥抱,都洋溢着离别的情愫。可在这个分水岭的时刻,沈墨宸的心却五味杂陈,他要面临着未来职业的选择。在经过秋招春招的激烈筛选之后,靠着自身扎实的技术功底,他赢得了三家公司的青睐,手握三份offer。
第一个是声名显赫的大型企业,拥有一线城市的繁华与标准化的培训,职业晋升的路径一目了然。然而,公司所在远离沈墨宸的住所,每想到公司的高强度工作和漫长的通勤,沈墨宸不禁背脊生寒。面试时,那冷漠的面试官与他机械的提问,尽管顺利通过,心底却有一丝莫名的异样。
第二个是规模适中且富有人文情怀的公司,薪酬福利在业界也挺令人满意。在此,沈墨宸能感受到团队的温馨与被重视的喜悦。面试之日,宜人的办公环境和面试官的和蔼笑容,让他紧张的神经得以放松,心头荡漾着归属的温暖。
第三个是充满活力的初创企业,给予沈墨宸管理岗位的机遇。尽管缺乏大企业的资源和小公司的稳定薪酬,但这家企业让他看到了无限的潜力。创始人眼中的热忱与未来的憧憬,使他蠢蠢欲动。
在沈墨宸犹豫不决时,一位曾经的校友出现在他的面前,这位曾在大企业打拼多年的前辈选择了创业,他的话语令沈墨宸顿悟:“选择适合自己的道路,远胜于看似完美的道路。你的青春既能承担风险,也能享受稳定,要看你内心的真正指向。”
沈墨宸开始深入思考个人的职业规划与生活愿景。在他彷徨时,多年挚友赵煜城决定助他一臂之力,不是推荐他选择接受哪份offer,而是帮他寻找内心最满足的归宿。
赵煜城首先列举了工作选择的关键要素:薪资水平、职业成长、公司稳定性、工作地点与环境。他引导沈墨宸根据个人职业规划与生活需求,对这些要素进行排序与评分。例如,沈墨宸认为职业成长为首要,其次是薪资水平,公司稳定性次之,而工作地点与环境在他心中的分量相对较轻。
然后,赵煜城让沈墨宸对每个选项,基于这些要素进行细致评估。例如,大公司提供更多职业发展机会,但地点遥远,通勤不便;小公司虽薪福优渥,但职业成长的空间有限;初创企业稳定性欠佳,却能够提供快速成长的舞台。
最终,赵煜城与沈墨宸共同利用层次分析法,完成了评分和排序,计算出每个工作选项的综合得分。结果表明,尽管大公司名气响亮,但通勤的辛劳和对职业成长的渴望使其得分并非最高。经过慎重考量,沈墨宸发现,初创企业虽风险稍大,却契合了他对职业挑战和成长空间的渴求。于是,他决定加入初创企业,担任管理岗位。
沈墨宸借助层次分析法,不仅梳理了思路,也做出了一个符合职业规划并让自己心满意足的选择。赵煜城的建议与分析法的辅助,让沈墨宸在人生道路的交叉点,做出了明智的抉择。
定义与详解
定义
层次分析法是指将一个复杂的多目标决策问题作为一个系统,将目标分解为多个目标或准则,进而分解为多指标(或准则、约束)的若干层次,通过定性指标模糊量化方法算出层次单排序(权数)和总排序,以作为目标(多指标)、多方案优化决策的系统方法。
原理
层次分析法的原理,层次分析法根据问题的性质和要达到的总目标,将问题分解为不同的组成因素,并按照因素间的相互关联影响以及隶属关系将因素按不同的层次聚集组合,形成一个多层次的分析结构模型,从而最终使问题归结为最低层(供决策的方案、措施等)相对于最高层(总目标)的相对重要权值的确定或相对优劣次序的排定。

重要概念
成对比较矩阵
在层次分析法中,成对比较矩阵(Pairwise Comparison Matrix)是一种用于将决策元素进行对比,以确定其优先级或相对重要性的工具。
在层次分析法中,首先将决策问题分解为一个层次结构,包括目标层(即决策的目标)、准则层(即决策的标准或指标)和策略或方案层。在每一层,都通过两两比较的方式,确定各元素的重要性并进行排序。
一个典型的成对比较矩阵如下:
假设在一个层面中,有 n 个因素需要比较,它们是  ,那么成对比较矩阵 A 可以表示为:
,那么成对比较矩阵 A 可以表示为:
|
|
|
… |
|
|
|---|---|---|---|---|
|
|
1 |
|
… |
|
|
|
|
1 |
… |
|
| … |
… |
… |
… |
… |
|
|
|
|
… |
1 |



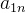
在这个矩阵中,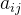 代表了元素 A_i 相对于元素 A_j 的重要性或优先级。对角线元素都为1,表示元素自身对比自身,优先级相同。矩阵的对称元素为倒数关系,表示决策的互逆性,如
代表了元素 A_i 相对于元素 A_j 的重要性或优先级。对角线元素都为1,表示元素自身对比自身,优先级相同。矩阵的对称元素为倒数关系,表示决策的互逆性,如  。
。
元素的值使用的是1-9标度方法。
| 标度 |
含义 |
|---|---|
| 1 |
表示两个因素相比,具有同样重要性 |
| 3 |
表示两个因素相比,一个因素比另一个因素稍微重要 |
| 5 |
表示两个因素相比,一个因素比另一个因素明显重要 |
| 7 |
表示两个因素相比,一个因素比另一个因素强烈重要 |
| 9 |
表示两个因素相比,一个因素比另一个因素极端重要 |
| 2,4,6,8 |
上述两相邻判断的中值 |
| 倒数 |
因素 i 与 j 的判断 |

建立成对比较矩阵是层次分析法中非常重要的一步,通常需要通过专家评估或者数据分析来进行。成对比较矩阵的一致性反映了决策者进行成对比较时判断的一致性,因此对成对比较矩阵需要进行一致性测试,以检验其有效性和可信度。
成对比较矩阵有两个特点,即:
-
不把所有因素放在一起比较,而是两两比较;
-
对此时采用相对尺度,以尽可能减少性质不同的诸因素相互比较的困难,以提高准确性。
一致矩阵法
一致性矩阵在层次分析法中是一种非常重要的概念,它用于判断决策者在做配对比较时的一致性程度。
一致矩阵(Consistent Matrix)的定义:对于一个 n 阶的正互反矩阵 A ,如果它满足
![]()
其中 w 是一个正向量, 代表这个矩阵的最大特征值,等于 n,那么就称这个矩阵 A 为一致矩阵。在理想情况下,AHP过程中的判断矩阵就是一致矩阵,但在实际应用中,由于各种原因,如主观判断的误差等,往往不能实现完全一致性,即所构造出的判断矩阵为近似一致矩阵。
代表这个矩阵的最大特征值,等于 n,那么就称这个矩阵 A 为一致矩阵。在理想情况下,AHP过程中的判断矩阵就是一致矩阵,但在实际应用中,由于各种原因,如主观判断的误差等,往往不能实现完全一致性,即所构造出的判断矩阵为近似一致矩阵。
一致性比率
为了测量判断矩阵的一致性程度,可以通过计算一致性比率(Consistency Ratio,CR)的方式进行。
首先,需要求出一致性指标(Consistency Index,CI)

其中 n 为矩阵的阶数, 为最大特征值。
然后通过随机一致性指标(Random Consistency Index,RI),求出一致性比率CR,
CR = CI / RI.
对于随机判断矩阵,CI的平均值即为RI。如果 CR < 0.1 ,那么一般认为这个矩阵的一致性是可以接受的。
总的来说,在层次分析法中,一致性的判断是为了保证决策者的判断具有合理性,这是一个重要的步骤,也是AHP与其他决策方法的一个重要区别。
层次单排序
层次单排序是一种计算步骤,用于确定每个选项(例如决策方案)在单个准则下的优先级或权重。
进行层次单排序的步骤如下:
-
创建判断矩阵:首先,在给定准则的情况下,为每对选项创建一个判断矩阵,其中每个矩阵元素代表了一对选项的相对重要性。
-
计算特征向量:然后,计算判断矩阵的最大特征值(
)对应的特征向量。特征向量中的每个元素分别对应了每个选项的相对优先级。 -
归一化特征向量:将特征向量的各元素规范化,即除以所有元素的和。这样得到的就是归一化特征向量。
在这个过程结束后,我们就得到了每个选项在给定准则下的权重。这就是层次单排序的过程。
然后,我们可以结合所有准则的层次单排序,通过加权平均的方式,得到每个选项的全局权重,也就是进行层次总排序。
层次总排序
层次总排序是确定各决策方案最终优先级或权重的步骤。
在进行层次总排序之前,我们需要先进行层次单排序,确定每个决策方案在各单个准则下的优先级或权重。然后,根据各准则的重要性(权重),将单准则下的方案权重进行加权平均,得到各方案的全局优先级或权重。
具体步骤如下:
-
确定各准则权重:根据决策者的判断创建准则层的判断矩阵,计算出各准则的权重。
-
确定各方案在单个准则下的权重:对每个准则,根据决策者的判断创建方案层的判断矩阵,计算出各方案在单个准则下的权重,这就是层次单排序。
-
加权平均:对每个方案,将其在各准则下的权重与对应的准则权重相乘,然后求和,得到各方案的全局优先级或权重。全局优先级最高的方案通常就是最佳决策方案。
步骤
-
定义问题和确定目标。
-
建立层次结构模型。将决策问题进行分解,成为目标、准则(或指标)和方案三个层次。其中目标位于顶层,方案位于底层,准则位于中间层。
-
最高层(目标层):决策的目的、要解决的问题;
-
中间层(准则层或指标层):考虑的因素、决策的准则;
-
最低层(方案层):决策时的备选方案;
以选择旅游地进行分析,我们想要从三个地点中选择旅游地,通过景色、费用、居住、饮食、旅途这五个因素构建了层次结构模型。
-
-
进行配对比较,并创建比较矩阵。对于每一层中的元素,两两进行配对比较,在相对的目标(或准则)下,确定其相对的重要性。
那在确定各层次各因素之间的权重时,如果只是定性的结果(就是我认为景色占80%,费用10%等等),则常常不容易被别人接受,这里采用一致矩阵法。同时,这里的成对比较矩阵是表示本层所有因素针对上一层某一个因素(准侧或目标)的相对重要性的比较。
在本例中,依据以上原则,我们可以构建比较矩阵:
A_1
A_2
A_3
A_4
A_5
A_1
1
1/2
4
3
3
A_2
2
1
7
5
5
A_3
1/4
1/7
1
1/2
1/3
A_4
1/3
1/5
2
1
1
A_5
1/3
1/5
2
1
1
比如 a_{14}=3 表示的是景色因素比居住因素对于选择旅游地来说稍微重要。
同理构建其它矩阵,
-
进行层次单排序和一致性检验
W 的元素为同一层次因素对于上一层次因素某因素相对重要性的排序权值,这一过程称为层次单排序,那能否确认层次单排序,需要进行一致性检验,所谓一致性检验是指对成对比较矩阵确定不一致的允许范围。
A层 m 个因素对总目标 Z 的排序为
 。B层 n 个因素对A层中因素 A_j 的层次单排序为 b_{1j},b_{2j},…b_{nj}。
。B层 n 个因素对A层中因素 A_j 的层次单排序为 b_{1j},b_{2j},…b_{nj}。在本例中,经过计算可以得到:
-
A_1A_2A_3A_4A_5 对 Z 的权重为 [0.2636, 0.4758, 0.0538, 0.0981, 0.1087]
-
B_1B_2B_3 对A_1 的权重为 [0.5954, 0.2764, 0.1283]
-
B_1B_2B_3 对A_2 的权重为 [0.0819, 0.2363, 0.6817]
-
B_1B_2B_3 对A_3 的权重为 [0.4286, 0.4286, 0.1429]
-
B_1B_2B_3 对A_4 的权重为 [0.6337, 0.1919, 0.1744]
-
B_1B_2B_3 对A_5 的权重为 [0.1667, 0.1667, 0.6667]
针对矩阵 A 做一致性检验:
-
最大特征根
 = 5.073
= 5.073 -
权向量(特征向量)

-
一致性指标 CI = (5.073-5)/(5-1) = 0.018
-
随机一致性指标 RI=1.12 (查表)
-
一致性比率 CR = 0.018/1.12 = 0.016 \lt 0.1
所以通过一致性检验。
-
-
进行层次总排序和一致性检验
即计算最下层对最上层总排序的权向量。
B层的层次总排序,即B层第 i 个因素对总目标的权值为

层次总排序的一致性检验使用的方法是加权平均法。具体的计算公式为:

其中,
 是全局一致性指标,w_i 是第 i 个准则的权重,CI_i 是第 i 个准则的一致性指标,n 是准则的数量。
是全局一致性指标,w_i 是第 i 个准则的权重,CI_i 是第 i 个准则的一致性指标,n 是准则的数量。然后,使用全局一致性指标计算全局一致性比率(CR):

其中,CR_{global} 是全局一致性比率,RI 是适当阶数的随机矩阵的平均随机一致性指标。如果 CR_{global} 小于或等于0.1,那么一致性被认为是可接受的。
在本例中,B_1 对目标的总权值等于

同理,B_2,B_3也这样计算。最后得到决策层对总目标的权向量为 {0.3, 0.245, 0.455}。即各方案的权重排序为
 ,所以应当选择去桂林旅游。
,所以应当选择去桂林旅游。
代码
将上述实例用Python代码编写得到:
import numpy as np
# 计算权重向量和最大特征值
def calculate_weights_and_max_eigenvalue(matrix):
eigenvalues, eigenvectors = np.linalg.eig(matrix)
max_eigenvalue = np.max(eigenvalues)
max_eigenvector = eigenvectors[:, eigenvalues.argmax()]
weights = max_eigenvector / np.sum(max_eigenvector)
return weights.real, max_eigenvalue.real
# 一致性检验
def consistency_check(matrix, max_eigenvalue):
# 详见数模百科
# 构建比较矩阵
A = np.array([
[1, 1/2, 4, 3, 3],
[2, 1, 7, 5, 5],
[1/4, 1/7, 1, 1/2, 1/3],
[1/3, 1/5, 2, 1, 1],
[1/3, 1/5, 2, 1, 1]
])
B1 = np.array([
[1, 2, 5],
[1/2, 1, 2],
[1/5, 1/2, 1]
])
B2 = np.array([
[1, 1/3, 1/8],
[3, 1, 1/3],
[8, 3, 1]
])
B3 = np.array([
[1, 1, 3],
[1, 1, 3],
[1/3, 1/3, 1]
])
B4 = np.array([
[1, 3, 4],
[1/3, 1, 1],
[1/4, 1, 1]
])
B5 = np.array([
[1, 1, 1/4],
[1, 1, 1/4],
[4, 4, 1]
])
# 计算权重向量和最大特征值
weights_A, max_eigenvalue_A = calculate_weights_and_max_eigenvalue(A)
# 一致性检验
CR_A = consistency_check(A, max_eigenvalue_A)
if CR_A < 0.1:
print("通过一致性检验")
else:
print("未通过一致性检验")
# 计算准则层权重向量
weights_B_list = []
for B in [B1, B2, B3, B4, B5]:
weights_B, _ = calculate_weights_and_max_eigenvalue(B)
weights_B_list.append(weights_B)
# 计算总权重
total_weights = np.zeros(weights_B_list[0].shape) # 初始化总权重向量
for i, weights_B in enumerate(weights_B_list):
total_weights += weights_A[i] * weights_B
# 输出结果
print("准则层对目标层的权重:", weights_A)
print("方案层对准则层的权重:")
for i, weights_B in enumerate(weights_B_list, start=1):
print(f"B{i}: {weights_B}")
print("方案层对目标层的总权重:", total_weights)
# 选择最优方案
best_option_index = np.argmax(total_weights)
print(f"最优方案是B{best_option_index + 1}")应用
层次分析法用于以下几个方面的问题:
-
决策问题:层次分析法可用于制定决策方案,通过对关键准则的比较和评价来确定最佳的决策结果。
-
方案评估:层次分析法可用于比较和评估不同方案的优劣,以帮助选择最有利的方案。
-
资源分配和排名:层次分析法可用于资源的分配和排名,通过比较和评价不同方案或资源的重要性,做出合理的决策。
-
产品设计和优化:层次分析法可用于产品设计和优化,通过对不同特征和指标的比较和评价,确定最优的产品设计方案。
层次分析法和TOPSIS的区别
层次分析法(AHP)和技术评价方法中的一种技术,即逼近理想解排序法(TOPSIS),都是多准则决策分析(MCDM)的方法,用于在有多个备选方案和多个评估标准的情况下做出决策。具体区别请见数模百科。
可参考论文

本文摘录自 数模百科 —— 层次分析法AHP - 数模百科。
数模百科是供美赛参赛者的一站式数模学习平台,有关于每个数学模型详细的解释和代码。现在我们将2023年的美赛论文进行归类整理,供大家可以以模型为索引定位到论文进行参考。