《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第6章 逻辑斯谛回归与最大熵模型(2)6.2 最大熵模型
文章目录
-
- 6.2 最大熵模型
-
- 6.2.1 最大熵原理
- 6.2.3 最大熵模型的学习
- 6.2.4 极大似然估计
《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第3章 k邻近邻法
《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第1章 统计学习方法概论
《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第 2章感知机
《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第3章 k邻近邻法
《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第4章 朴素贝叶斯法
《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第5章 决策树
《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第6章 逻辑斯谛回归与最大熵模型(1)6.1 逻辑斯谛回归模型
我算是有点基础的(有过深度学习和机器学的项目经验),但也是半路出家,无论是学Python还是深度学习,都是从问题出发,边查边做,没有系统的学过相关的知识,这样的好处是入门快(如果想快速入门,大家也可以试试,直接上手项目,从小项目开始),但也存在一个严重的问题就是,很多东西一知半解,容易走进死胡同出不来(感觉有点像陷入局部最优解,找不到出路),所以打算系统的学习几本口碑比较不错的书籍。
书籍选择: 当然,机器学习相关的书籍有很多,很多英文版的神书,据说读英文版的书会更好,奈何英文不太好,比较难啃。国内也有很多书,周志华老师的“西瓜书”我也有了解过,看了前几章,个人感觉他肯能对初学者更友好一点,讲述的非常清楚,有很多描述性的内容。对比下来,更喜欢《统计学习方法》,毕竟能坚持看完才最重要。
笔记内容: 笔记内容尽量省去了公式推导的部分,一方面latex编辑太费时间了,另一方面,我觉得公式一定要自己推到一边才有用(最好是手写)。尽量保留所有标题,但内容会有删减,通过标黑和列表的形式突出重点内容,要特意说一下,标灰的部分大家最好读一下(这部分是我觉得比较繁琐,但又不想删掉的部分)。
代码实现: 最后是本章内容的实践,如果想要对应的.ipynb文件,可以留言
6.2 最大熵模型
最大熵模型(maximum entropy model)由最大熵原理推导实现。
这里首先叙述一般的最大熵原理,然后讲解最大熵模型的推导,最后给出最大熵模型学习的形式。
6.2.1 最大熵原理
最大熵原理是概率模型学习的一个准则。最大熵原理认为,学习概率模型时,在所有可能的概率模型(分布)中,熵最大的模型是最好的模型。
通常用约束条件来确定概率模型的集合,所以,最大熵原理也可以表述为在满足约束条件的模型集合中选取熵最大的模型。
假设离散随机变量 X X X的概率分布是 P ( X ) P(X) P(X),则其熵(参照5.2.2节)是
H ( P ) = − ∑ x p ( x ) l o g P ( x ) H(P)=-\sum_{x}p(x)logP(x) H(P)=−x∑p(x)logP(x)
熵满足下列不等式:
0 ≤ H ( P ) ≤ l o g ∣ X ∣ 0\leq H(P)\leq log|X| 0≤H(P)≤log∣X∣
式中, ∣ X ∣ |X| ∣X∣是 X X X的取值个数,当且仅当 X X X的分布是均匀分布时右边的等号成立。
这就是说,当 X X X服从均匀分布时,熵最大。
直观地,最大熵原理认为要选择的概率模型
- 首先必须满足已有的事实,即约束条件。
- 在没有更多信息的情况下,那些不确定的部分都是“等可能的”。
最大熵原理通过熵的最大化来表示等可能性。“等可能”不容易操作,而熵则是一个可优化的数值指标。
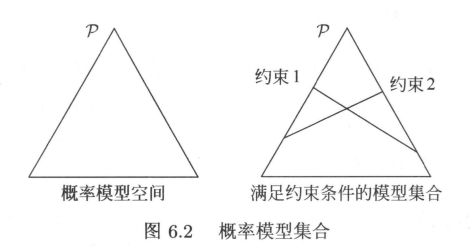
图6.2提供了用最大熵原理进行概率模型选择的几何解释。
概率模型集合 P P P可由欧氏空间中的单纯形(simplex)[2]表示,
- 如左图的三角形(2-单纯形)。一个点代表一个模型,整个单纯形代表模型集合。
- 右图上的一条直线对应于一个约束条件,直线的交集对应于满足所有约束条件的模型集合。
一般地,这样的模型仍有无穷多个。
学习的目的是在可能的模型集合中选择最优模型,而最大熵原理则给出最优模型选择的一个准则。
6.2.2 最大熵模型的定义
最大熵原理是统计学习的一般原理,将它应用到分类得到最大熵模型。
假设分类模型是一个条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X), X ∈ X ⊆ R n X\in \mathcal{X}⊆R^n X∈X⊆Rn表示输入, Y ∈ Y Y\in \mathcal{Y} Y∈Y表示输出, X \mathcal{X} X和 Y \mathcal{Y} Y分别是输入和输出的集合。
这个模型表示的是对于给定的输入 X X X,以条件概率 P ( Y ∣ X ) P(Y|X) P(Y∣X)输出 Y Y Y。
给定一个训练数据集
T = ( ( x 1 , x 1 ) , ( x 2 , x 2 ) 。。。, ( x N , x N ) ) T=((x_1,x_1),(x_2,x_2)。。。,(x_N,x_N)) T=((x1,x1),(x2,x2)。。。,(xN,xN))
学习的目标是用最大熵原理选择最好的分类模型。
首先考虑模型应该满足的条件。给定训练数据集,可以确定联合分布 P ( X , Y ) P(X,Y) P(X,Y)的经验分布和边缘分布 P ( X ) P(X) P(X)的经验分布,分别以 p ^ ( X , Y ) \hat{p}(X,Y) p^(X,Y)和 p ^ ( X ) \hat{p}(X) p^(X)表示。这里,
联合分布 P ( X , Y ) P(X,Y) P(X,Y)的经验分布:
p ^ ( X = x , Y = y ) = v ( X = x , Y = y ) N \hat{p}(X=x,Y=y)=\frac{\mathcal{v}(X=x,Y=y)}{N} p^(X=x,Y=y)=Nv(X=x,Y=y)
边缘分布 P ( X ) P(X) P(X)的经验分布:
p ^ ( X = x ) = v ( X = x ) N \hat{p}(X=x)=\frac{\mathcal{v}(X=x)}{N} p^(X=x)=Nv(X=x)
其中,
- v ( X = x , Y = y ) \mathcal{v}(X=x,Y=y) v(X=x,Y=y)表示训练数据中样本 ( x , y ) (x,y) (x,y)出现的频数,
- v ( X = x ) \mathcal{v}(X=x) v(X=x)表示训练数据中输入 x x x出现的频数,
- N N N表示训练样本容量。
用特征函数(feature function) f ( x , y ) f(x,y) f(x,y)描述输入 x x x和输出 y y y之间的某一个事实。
其定义是

它是一个二值函数[3],当 x x x和 y y y满足这个事实时取值为1,否则取值为0。
特征函数 f ( x , y ) f(x,y) f(x,y)关于经验分布 p ^ ( X , Y ) \hat{p}(X,Y) p^(X,Y)的期望值,用 E p ^ ( f ) E_{\hat{p}}(f) Ep^(f)表示。

特征函数 f ( x , y ) f(x,y) f(x,y)关于模型 P ( Y ∣ X ) P(Y|X) P(Y∣X)与经验分布$ \hat{p}(X) 的期望值,用 的期望值,用 的期望值,用E_{p}(f)$表示。

如果模型能够获取训练数据中的信息,那么就可以假设这两个期望值相等,即

我们将式(6.10)或式(6.11)作为模型学习的约束条件。假如有n个特征函数 f i ( x , y ) , i = 1 , 2 , … , n f_i(x,y),i=1,2,…,n fi(x,y),i=1,2,…,n,那么就有 n n n个约束条件。

6.2.3 最大熵模型的学习
最大熵模型的学习过程就是求解最大熵模型的过程。最大熵模型的学习可以形式化为约束最优化问题。
对于给定的训练数据集 T = ( ( x 1 , x 1 ) , ( x 2 , x 2 ) 。。。, ( x N , x N ) ) T=((x_1,x_1),(x_2,x_2)。。。,(x_N,x_N)) T=((x1,x1),(x2,x2)。。。,(xN,xN))以及特征函数 f i ( x , y ) f_i(x,y) fi(x,y),i=1,2,…,n,最大熵模型的学习等价于约束最优化问题:

按照最优化问题的习惯,将求最大值问题改写为等价的求最小值问题:

求解约束最优化问题(6.14)~(6.16),所得出的解,就是最大熵模型学习的解。
(推到过程详见书 P 99 P_{99} P99)
6.2.4 极大似然估计
从以上最大熵模型学习中可以看出,最大熵模型是由式(6.22)、式(6.23)表示的条件概率分布。
下面证明对偶函数的极大化等价于最大熵模型的极大似然估计。
已知训练数据的经验概率分布 p ^ ( X , Y ) \hat{p}(X,Y) p^(X,Y),条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)的对数似然函数表示为:

当条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)是最大熵模型(6.22)和(6.23)时,对数似然函数 L P ^ ( P w ) L_{\hat{P}}(P_w) LP^(Pw)为:

再看对偶函数$ \Psi(w)$。由式(6.17)及式(6.20)可得

比较式(6.26)和式(6.27),可得
Ψ ( w ) = L p ^ ( P w ) \Psi(w)=L_{\hat{p}}(P_w) Ψ(w)=Lp^(Pw)
既然对偶函数 Ψ ( w ) \Psi(w) Ψ(w)等价于对数似然函数 L p ^ ( P w ) L_{\hat{p}}(P_w) Lp^(Pw),于是证明了最大熵模型学习中的对偶函数极大化等价于最大熵模型的极大似然估计这一事实。
这样,最大熵模型的学习问题就转换为具体求解对数似然函数极大化或对偶函数极大化的问题。
可以将最大熵模型写成更一般的形式。

最大熵模型与逻辑斯谛回归模型有类似的形式,它们又称为对数线性模型(log linear model)。模型学习就是在给定的训练数据条件下对模型进行极大似然估计或正则化的极大似然估计。