Python实战:爬取小红书
有读者在公众号后台询问爬取小红书,今天他来了。
本文可以根据关键词,在小红书搜索相关笔记,并保存为excel表格。
爬取的字段包括笔记标题、作者、笔记链接、作者主页地址、作者头像、点赞量。
一、先看效果
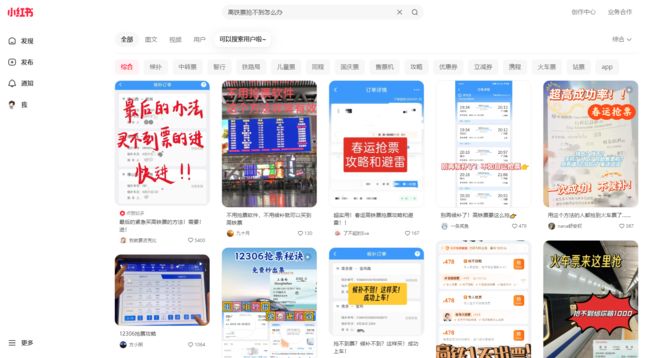
1、爬取搜索页
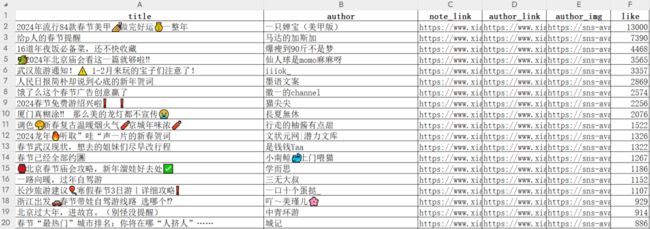
2、爬取结果保存到本地excel表格
运行我写的爬虫,实验了几十次,都可以顺利爬到数据,每次大概可以爬取到 200 条笔记保存到 excel 表格。
遇到的坑都在实验过程中解决了,可以说,这个爬虫很好用。

3、每个excel表格的详情
以“繁花”为关键词,去搜索小红书相关笔记,保存到本地 excel 文件。打开 excel 查看详情如下,笔记是根据点赞量降序排列的。

以“上海旅游”为关键词,去搜索小红书相关笔记,保存到本地 excel 文件。打开 excel 查看详情如下,笔记是根据点赞量降序排列的。

以“春节”为关键词,去搜索小红书相关笔记,保存到本地 excel 文件。打开 excel 查看详情如下,笔记是根据点赞量降序排列的。
二、分析思路
由于小红书反爬机制很严格,很难批量获取小红书的大量数据。用爬虫去爬小红书数据,还有被小红书封号的风险。
但是我这个方法是纯模拟人的操作,以人的操作习惯去搜索和刷新数据,不会触发小红书的反爬机制。
分析爬虫思路,概括如下:
1、打开小红书主页
2、登录
3、根据关键词搜索笔记
4、提取页面数据
5、循环刷新页面,循环获取数据
6、处理获取到的数据,去重,排序
7、保存到本地 excel 文件
三、开始写代码
1、登录
使用 DrissionPage 库,打开小红书主页https://www.xiaohongshu.com,设置 20 秒延时,这时可以使用手机扫码登录账号。
from DrissionPage import ChromiumPage
def sign_in():
sign_in_page = ChromiumPage()
sign_in_page.get('https://www.xiaohongshu.com')
print("请扫码登录")
# 第一次运行需要扫码登录
time.sleep(20)
只有第 1 次运行代码需要登录,浏览器会保存登录状态信息。第 2 次之后再运行代码,就免登录了,可以把 sign_in()步骤注释掉。
2、设置搜索关键词
设置关键词 keyword,并通过 urllib 库,将关键词转为 url 编码
from urllib.parse import quote
# 搜索关键词
keyword = "繁花"
# 关键词转为 url 编码
keyword_temp_code = quote(keyword.encode('utf-8'))
keyword_encode = quote(keyword_temp_code.encode('gb2312'))
3、搜索结果
根据设置的关键词,打开搜索页面,搜索相关笔记
def search(keyword):
global page
page = ChromiumPage()
page.get(f'https://www.xiaohongshu.com/search_result?keyword={keyword}&source=web_search_result_notes')
4、定位信息
使用 DrissionPage 库定位元素方法,定位到包含笔记信息的 sections、 定位标题、作者、点赞等信息。
# 定位包含笔记信息的sections
container = page.ele('.feeds-page')
sections = container.eles('.note-item')
# 定位文章链接
note_link = section.ele('tag:a', timeout=0).link
# 定位标题、作者、点赞
footer = section.ele('.footer', timeout=0)
# 定位标题
title = footer.ele('.title', timeout=0).text
# 定位作者
author_wrapper = footer.ele('.author-wrapper')
author = author_wrapper.ele('.author').text
# 定位作者主页地址
author_link = author_wrapper.ele('tag:a', timeout=0).link
# 定位作者头像
author_img = author_wrapper.ele('tag:img', timeout=0).link
# 定位点赞
like = footer.ele('.like-wrapper like-active').text
5、向下滑动页面刷新数据
为了防止被检测到,每次下滑页面设置一个 0.5,秒至 1.5 秒之前的随机睡眠时间。使用 DrissionPage 库 scroll.to_bottom()操作页面方法,将页面划到底部,小红书会刷新出新的数据。
import time
import random
def page_scroll_down():
print("********下滑页面********")
# 生成一个随机时间
random_time = random.uniform(0.5, 1.5)
# 暂停
time.sleep(random_time)
# time.sleep(1)
# page.scroll.down(5000)
page.scroll.to_bottom()
6、循环下滑页面获取数据
调用 get_info()函数自动提取页面数据,调用 page_scroll_down()函数自动下滑页面。设置向下滑动 20 次页面,就可以自动刷新数据、提取数据了。
# 设置向下翻页爬取次数
times = 20
def craw(times):
for i in tqdm(range(1, times + 1)):
get_info()
page_scroll_down()
7、保存数据
创建一个 contents 列表,用来存放所有爬取到的信息。
# contents列表用来存放所有爬取到的信息
contents = []
contents.append([title, author, note_link, author_link, author_img, like])
8、保存到excel
使用 pandas 库,将 contents 列表转为 DataFrame 数据类型,保存为 excel 文件。
# 保存到excel文件
name = ['title', 'author', 'note_link', 'author_link', 'author_img', 'like']
df = pd.DataFrame(columns=name, data=data)
这里可以进行细节处理,比如删除重复数据。数据类型转换,将点赞量字符串类型转为 int 类型。根据点赞量降序排序,方便查看热门笔记。
df['like'] = df['like'].astype(int)
# 删除重复行
df = df.drop_duplicates()
# 按点赞 降序排序
df = df.sort_values(by='like', ascending=False)
9、自动调整excel表格列宽
由于笔记标题和作者名称包含的字数较多,可以自动调整这 2 列宽度满足数据在 excel 表格中不被遮挡,可以全部展示出来。
笔记链接、作者主页链接、作者头像链接全是链接,也很长,但是不需要全部展示,可以将这几列设置固定列宽。

import openpyxl
def auto_resize_column(excel_path):
"""自适应列宽度"""
wb = openpyxl.load_workbook(excel_path)
worksheet = wb.active
# 循环遍历工作表中的1-2列
for col in worksheet.iter_cols(min_col=1, max_col=2):
max_length = 0
# 列名称
column = col[0].column_letter
# 循环遍历列中的所有单元格
for cell in col:
try:
# 如果当前单元格的值长度大于max_length,则更新 max_length 的值
if len(str(cell.value)) > max_length:
max_length = len(str(cell.value))
except:
pass
# 计算调整后的列宽度
adjusted_width = (max_length + 2) * 2
# 使用 worksheet.column_dimensions 属性设置列宽度
worksheet.column_dimensions[column].width = adjusted_width
# 循环遍历工作表中的3-5列
for col in worksheet.iter_cols(min_col=3, max_col=5):
max_length = 0
column = col[0].column_letter # Get the column name
# 使用 worksheet.column_dimensions 属性设置列宽度
worksheet.column_dimensions[column].width = 15
wb.save(excel_path)
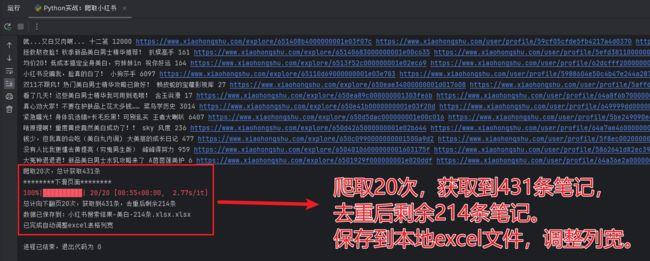
四、录屏
以一个爬取过程为例,录屏如下:
视频可以在我公众号同名文章查看。
五、全部代码
由于代码太长,在这里只给出主函数代码,有兴趣的读者可以根据上述信息自己补全代码。
if __name__ == '__main__':
# contents列表用来存放所有爬取到的信息
contents = []
# 搜索关键词
keyword = "繁花"
# 设置向下翻页爬取次数
times = 20
# 第1次运行需要登录,后面不用登录,可以注释掉
# sign_in()
# 关键词转为 url 编码
keyword_temp_code = quote(keyword.encode('utf-8'))
keyword_encode = quote(keyword_temp_code.encode('gb2312'))
# 根据关键词搜索小红书文章
search(keyword_encode)
# 根据设置的次数,开始爬取数据
craw(times)
# 爬到的数据保存到本地excel文件
save_to_excel(contents)
六、总结
小红书是商业化很成功的平台,我知道有很多小伙伴在小红书平台做副业,收入甚至超过主业。
我的这个代码,可以帮助你选题、找热点,找流量博主学习。
小红书的数据应该很有价值,特别有兴趣的小伙伴可以在公众号私聊我,以一杯瑞幸咖啡的价格获取全部代码(毕竟我写代码写了一下午~~~)。
我还会继续写小红书别的内容的爬虫,本次付费可以免费获得后续更新的代码。名额有限,仅限前5位小伙伴,先到先得。
每一份能满足他人需求的努力都值得被付费。
本文首发在“程序员coding”公众号,欢迎关注与我一起交流学习。