SqlServer 数据库进行表分区
- 在数据库中添加文件组
选择数据库→属性→文件组→添加

- 在文件组中添加新的文件
选择数据库→属性→文件→添加
- 定义分区函数
存储-分区函数 目录下可以查看当前数据库中包含哪些分区函数
创建方式查看后面【定义分区表】部分
- 定义分区架构
存储-分区方案 目录下可以查看当前数据库中包含哪些分区架构
创建方式查看后面【定义分区表】部分

定义分区表
右键选择你要进行分区的表,选择存储-创建分区
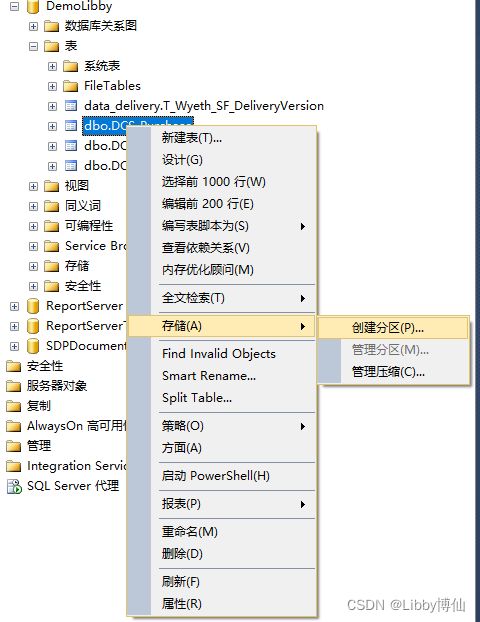
起始页直接下一步。
一般分区会按照时间或者流水号编码进行拆分,举例:这个采购流向数据通常只操作最近6个月的,历史的很少操作,这时可以按照业务日期,6个月为一组进行拆分,这里我选择采购日期。

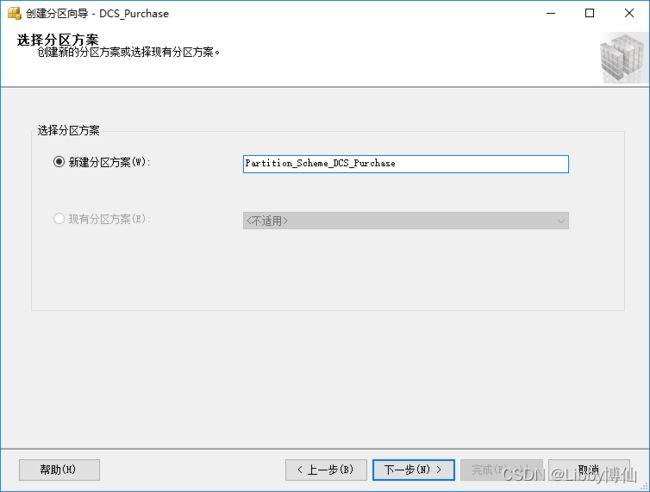
设置名称,注意增加标识符,避免和其他表名视图名等其他对象名称冲突,具体的函数内容在后面设置。

设置名称,注意增加标识符,避免和其他表名视图名等他对象名称冲突,具体的分区架构内容在下一步设置。
开始设置分区规则,也就是设置分区函数和分区架构(分区方案),最后一行数据的分组,一定要空着边界那列,来存储不满足分区函数规则的数据,否则提示报错,不予通过。
当设置完文件组和边界两列的值之后,可以点击【预计存储空间】,查看具体的数据分配计划。
也可以通过设置边界,快速拆分,前提你要创建了足够多的文件组。

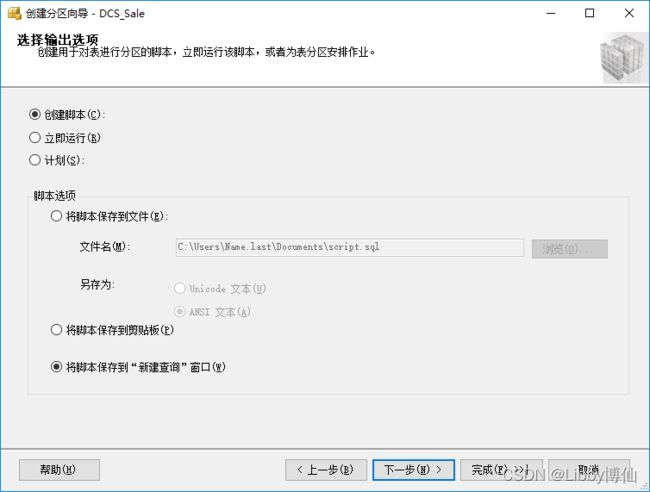
根据内容所需选择创建脚本还是立即执行,点击下一步,再点击完成,操作结束
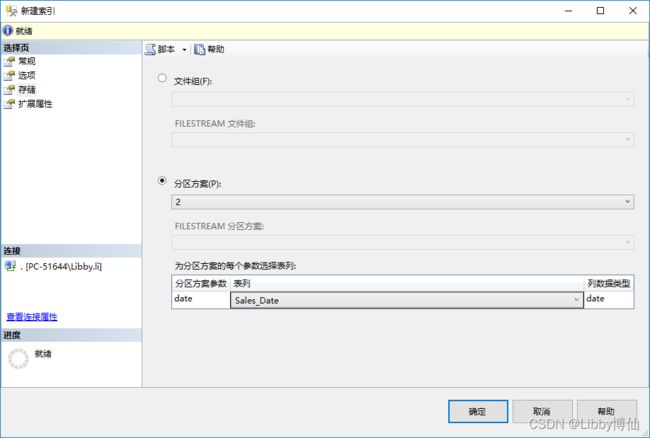
- 定义索引
其他设置和正常索引相同。
在左侧菜单选择存储,选择分区方案,选择你这个表分区对应的分区架构(分区方案)。
下方表列,选择分区函数对应的那个列头。
- 向分区表同步数据
右键选择数据库-任务-导入数据。
和正常未分区的导入导出无异,分区行为是在插入数据后根据分区规则判断具体存储到哪个分组,对于数据操作不影响,增删改查不需要因为分区而特殊处理。

起始页,直接下一步
选择数据源

选择数据目标
选择要传输的数据
选择要同步的表,编辑映射关系,这里我取消勾选自增长ID列
立即运行

执行成功,并且根据分组函数,不同的数据已经分配到不同的文件组进行保存

- 定义代理作业,自动添加分区分割点
不建议使用此操作,要避免分区操作和数据库使用同时进行,否则可能会损坏数据库,若必须使用,判断好分区时间
执行SQL内容:
DECLARE @maxValue DATETIME ,--最后一次分区函数的值, ※※
@secondMaxValue DATETIME ,--倒数第二次的分区函数的值※※
@differ INT , --最后两次分区函数的值,计算的差
@fileGroupName VARCHAR(200) ,--新增的文件组名
@fileNamePath VARCHAR(200) ,--文件路径 ※※
@fileName VARCHAR(200) ,--新增的文件名
@sql NVARCHAR(1000);--临时SQL脚本
--添加新文件组 需要修改【文件名前缀】
SET @fileGroupName = 'FileGroup' + REPLACE(REPLACE(REPLACE(CONVERT(VARCHAR, GETDATE(), 120), '-', ''), ' ', ''), ':', '');
SET @sql = 'ALTER DATABASE [DemoFileGroup] ADD FILEGROUP ' + @fileGroupName;
PRINT @sql;
EXEC(@sql);
--添加新文件 需要修改【文件路径,文件名前缀】
SET @fileNamePath = 'G:\DBFile\DemoFileGroup\DemoFileGroup' + REPLACE(REPLACE(REPLACE(CONVERT(VARCHAR, GETDATE(), 120), '-', ''), ' ', ''), ':', '') + '.NDF';
SET @fileName = N'DemoFileGroup' + REPLACE(REPLACE(REPLACE(CONVERT(VARCHAR, GETDATE(), 120), '-', ''), ' ', ''), ':', '');
SET @sql = 'ALTER DATABASE [DemoFileGroup] ADD FILE (NAME=''' + @fileName + ''',FILENAME=N''' + @fileNamePath + ''') TO FILEGROUP' + ' ' + @fileGroupName;
PRINT @sql;
EXEC(@sql);
--修改分区方案,用一个新的文件组用于存放下一新增的数据 需要修改【分区方案名称】
SET @sql = 'ALTER PARTITION SCHEME [Partition_Function_DCS_Purchase] NEXT USED' + ' ' + @fileGroupName;
EXEC(@sql);
--分区函数 找出分区架构最后两次的值
SELECT @maxValue = CONVERT(DATETIME, MAX(value))
FROM sys.partition_range_values PRV;
PRINT @maxValue
SELECT @secondMaxValue = CONVERT(DATETIME, MIN(value))
FROM ( SELECT TOP 2
*
FROM sys.partition_range_values
ORDER BY value DESC
) PRV;
PRINT @secondMaxValue
--计算出两个值的差
SET @differ = DATEDIFF(MONTH,@secondMaxValue,@maxValue)
PRINT @differ
--用最后一次的分区函数的值加上差,算出新的分区函数的值是多少,添加新的分区函数
PRINT CONVERT(NVARCHAR(100),DATEADD(MONTH,@differ,@maxValue),126)
ALTER PARTITION FUNCTION [Partition_Function_DCS_Purchase]() --分区函数 需要修改【分区函数名称】
SPLIT RANGE ( CONVERT(NVARCHAR(100),DATEADD(MONTH,@differ,@maxValue),126)); --这里注意类型,如果直接插入日期类型会出问题的,这个问题不一定是报错,可能会成功,但是值是什么不一定了,不知道应该插入什么类型或者什么格式,找到你要修改的分区函数,右键生成脚本,查看那个括号里面的值,是以什么形式和格式展示出来的,比如日期就是转换为CONVERT()函数126格式
最后创建执行计划,执行计划根据自己需求设定,执行上面的SQL

- 文件备份、还原、压缩
先进行完整备份,右键选择数据库,任务-备份

完整备份,点击确定,备份完成
还原,右键点击数据库,选择还原数据库

选择设备,找到备份的bak文件,选择目标数据库,勾选备份集

点击左侧菜单栏的文件,这里可以看到bak文件中的所有备份的文件,还原时,同时会还原所有分区函数和分区架构,点击确定,还原数据库完成
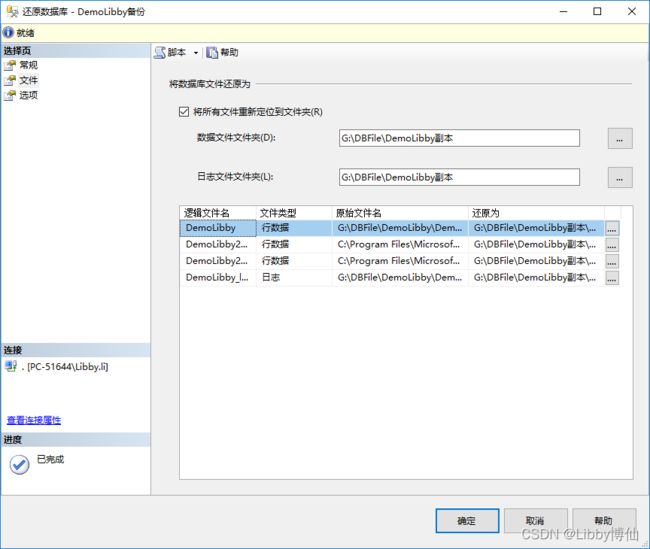
查看数据库属性,查看左侧文件,可以看到文件已经还原成功

查看左侧文件组,可以看到文件组已经还原成功

第二种备份方式,文件和文件组
不建议此种方式进行备份还原,因为单独还原文件组的时候会有很多问题,且很难解决。
使用完整备份就好了,最常见问题,还原后,文件状态为还原中,然后就变成无法使用
查看文件状态: Select * from sys.master_files
收缩分两种,一种是数据库,一种是文件
第一种,数据库和未分区数据库无异,正常操作即可
第二种,收缩文件
右键选择数据库,任务-收缩-数据库
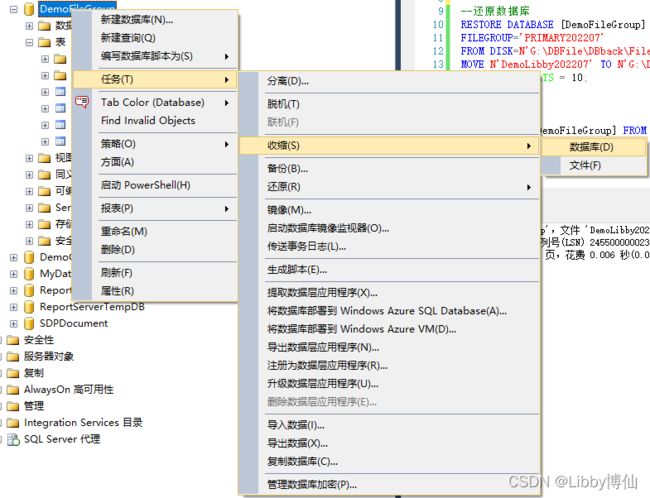
在下面选择你要收缩的文件组和文件,点击确定即可

- 测试数据
SELECT CONVERT(VARCHAR(50), ps.name) AS partition_scheme ,
p.partition_number ,
CONVERT(VARCHAR(10), ds2.name) AS filegroup ,
CONVERT(VARCHAR(19), ISNULL(v.value, ''), 120) AS range_boundary ,
STR(p.rows, 9) AS rows
FROM sys.indexes i
JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
JOIN sys.destination_data_spaces dds ON ps.data_space_id = dds.partition_scheme_id
JOIN sys.data_spaces ds2 ON dds.data_space_id = ds2.data_space_id
JOIN sys.partitions p ON dds.destination_id = p.partition_number
AND p.object_id = i.object_id
AND p.index_id = i.index_id
JOIN sys.partition_functions pf ON ps.function_id = pf.function_id
LEFT JOIN sys.Partition_Range_values v ON pf.function_id = v.function_id
AND v.boundary_id = p.partition_number
- pf.boundary_value_on_right
WHERE i.object_id = OBJECT_ID('DataS')--分区表名
AND i.index_id IN ( 0, 1 )
ORDER BY p.partition_number